อ่าน 11 นาที
นโยบายการแทนที่แคช
ในด้านการ คำนวณ นโยบายการแทนที่แคช (หรือที่เรียกว่า อัลกอริทึมการแทนที่แคช หรือ อัลกอริทึมแคช ) คือคำสั่งหรือ อัลกอริทึม การปรับให้เหมาะสม ซึ่ง โปรแกรมคอมพิวเตอร์...
นโยบายการแทนที่แคช
ในด้านการคำนวณนโยบายการแทนที่แคช (หรือที่เรียกว่าอัลกอริทึมการแทนที่แคชหรืออัลกอริทึมแคช ) คือคำสั่งหรืออัลกอริทึมการปรับให้เหมาะสมซึ่งโปรแกรมคอมพิวเตอร์หรือโครงสร้างที่ดูแลโดยฮาร์ดแวร์สามารถนำไปใช้ในการจัดการแคชของข้อมูลได้ การแคชช่วยเพิ่มประสิทธิภาพโดยการเก็บข้อมูลล่าสุดหรือข้อมูลที่ใช้บ่อยไว้ในตำแหน่งหน่วยความจำที่เข้าถึงได้เร็วกว่า หรือใช้ทรัพยากรการคำนวณน้อยกว่าหน่วยความจำปกติ เมื่อแคชเต็ม อัลกอริทึมจะต้องเลือกรายการที่จะทิ้งเพื่อสร้างพื้นที่สำหรับข้อมูลใหม่
ภาพรวม
เวลาอ้างอิงหน่วยความจำเฉลี่ยคือ[ 1 ]

ที่ไหน
- = อัตราพลาด = 1 - (อัตราถูก)
- = เวลาที่ใช้ในการเข้าถึงหน่วยความจำหลักเมื่อเกิดการพลาด (หรือ ในกรณีของแคชหลายระดับ เวลาอ้างอิงหน่วยความจำเฉลี่ยสำหรับแคชระดับถัดไป)
- = ความหน่วง: เวลาที่ใช้ในการอ้างอิงแคช (ควรเท่ากันทั้งกรณีที่เข้าถึงแคชได้และเข้าถึงแคชไม่ได้)
- = ผลกระทบรอง เช่น ผลกระทบจากการเข้าคิวในระบบมัลติโปรเซสเซอร์




แคชมีตัวชี้วัดประสิทธิภาพหลักสองประการ ได้แก่ ความหน่วงและอัตราการเข้าถึง นอกจากนี้ยังมีปัจจัยรองอีกหลายประการที่ส่งผลต่อประสิทธิภาพของแคช[ 1 ]
อัตราการเข้าถึงข้อมูล (Hit Rate) ของแคชอธิบายถึงความถี่ในการค้นพบรายการที่ค้นหา กลยุทธ์การแทนที่ที่มีประสิทธิภาพมากขึ้นจะติดตามข้อมูลการใช้งานมากขึ้นเพื่อปรับปรุงอัตราการเข้าถึงข้อมูลสำหรับขนาดแคชที่กำหนด ความหน่วง (Latency) ของแคชอธิบายถึงระยะเวลาหลังจากร้องขอรายการที่ต้องการแล้ว แคชจะสามารถส่งคืนรายการนั้นได้เมื่อพบข้อมูลที่ต้องการ กลยุทธ์การแทนที่ที่เร็วกว่ามักจะติดตามข้อมูลการใช้งานน้อยลง หรือในกรณีของแคชแบบ Direct-mapped จะไม่ติดตามข้อมูลใดๆ เพื่อลดเวลาที่จำเป็นในการอัปเดตข้อมูล กลยุทธ์การแทนที่แต่ละแบบเป็นการประนีประนอมระหว่างอัตราการเข้าถึงข้อมูลและความหน่วง
โดยทั่วไป การวัดอัตราการเข้าถึง (Hit-rate) จะดำเนินการกับ แอปพลิ เคชันมาตรฐานและอัตราการเข้าถึงจะแตกต่างกันไปตามแอ ปพลิเคชัน แอป พลิเคชันสตรีมมิ่ง วิดีโอและเสียง มักจะมีอัตราการเข้าถึงใกล้เคียงกับศูนย์ เนื่องจากข้อมูลแต่ละบิตในสตรีมจะถูกอ่านเพียงครั้งเดียว (พลาดโดยบังคับ) นำไปใช้ และจะไม่ถูกอ่านหรือเขียนอีกเลย อัลกอริทึมแคชจำนวนมาก (โดยเฉพาะLRU ) อนุญาตให้ข้อมูลสตรีมมิ่งเติมแคช ทำให้ข้อมูลที่จะถูกนำมาใช้อีกครั้งในไม่ช้าถูกผลักออกไป ( มลภาวะแคช ) [ 2 ]ปัจจัยอื่นๆ อาจได้แก่ ขนาด ระยะเวลาในการรับ และการหมดอายุ ขึ้นอยู่กับขนาดของแคช อาจไม่จำเป็นต้องมีอัลกอริทึมแคชเพิ่มเติมเพื่อทิ้งรายการ อัลกอริทึมยังรักษาความสอดคล้องของแคชเมื่อใช้แคชหลายตัวสำหรับข้อมูลเดียวกัน เช่น เซิร์ฟเวอร์ฐานข้อมูลหลายตัวที่อัปเดตไฟล์ข้อมูลที่ใช้ร่วมกัน
นโยบาย
อัลกอริทึมของเบลาดี
อัลกอริทึมการแคชที่มีประสิทธิภาพที่สุดคือการทิ้งข้อมูลที่ไม่จำเป็นต้องใช้เป็นเวลานานที่สุด ซึ่งรู้จักกันในชื่อ อัลกอริทึมที่เหมาะสมที่สุดของ เบลาดี (Bélády 's optimal algorithm) นโยบายการแทนที่ที่เหมาะสมที่สุด หรืออัลกอริทึมแบบหยั่งรู้เนื่องจากโดยทั่วไปแล้วเป็นไปไม่ได้ที่จะคาดการณ์ว่าข้อมูลจะมีความจำเป็นในอนาคตเมื่อใด วิธีนี้จึงไม่สามารถนำไปใช้ได้จริงในทางปฏิบัติ อย่างไรก็ตาม สามารถคำนวณค่าต่ำสุดที่ใช้งานได้จริงหลังจากทำการทดลอง และสามารถเปรียบเทียบประสิทธิภาพของอัลกอริทึมการแคชที่เลือกได้
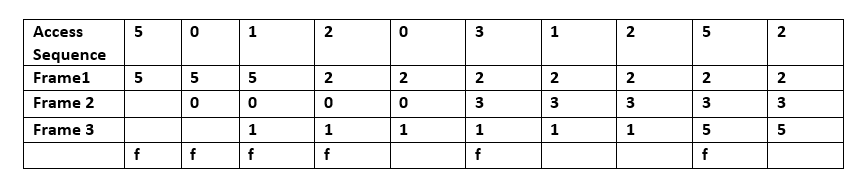
เมื่อ เกิด ข้อผิดพลาดในการเข้าถึงหน้าหน่วยความจำ (page fault) จะมีชุดของหน้าหน่วยความจำอยู่ในนั้น ในตัวอย่างนี้ ลำดับของ 5, 0, 1 จะถูกเข้าถึงโดยเฟรมที่ 1, เฟรมที่ 2 และเฟรมที่ 3 ตามลำดับ เมื่อมีการเข้าถึงค่า 2 ค่า 2 จะแทนที่ค่า 5 (ซึ่งอยู่ในเฟรมที่ 1) โดยคาดการณ์ว่าค่า 5 จะไม่ถูกเข้าถึงในอนาคตอันใกล้นี้ เนื่องจากระบบปฏิบัติการทั่วไปไม่สามารถคาดการณ์ได้ว่าค่า 5 จะถูกเข้าถึงเมื่อใด อัลกอริทึมของ Bélády จึงไม่สามารถนำไปใช้กับระบบปฏิบัติการเหล่านั้นได้
การทดแทนแบบสุ่ม (RR)
การแทนที่แบบสุ่มจะเลือกรายการหนึ่งรายการและทิ้งรายการนั้นเพื่อสร้างพื้นที่ว่างเมื่อจำเป็น อัลกอริทึมนี้ไม่จำเป็นต้องเก็บประวัติการเข้าถึงใดๆ มันถูกใช้ในโปรเซสเซอร์ ARMเนื่องจากความเรียบง่าย[ 3 ] และช่วยให้ การจำลองแบบสุ่มมีประสิทธิภาพ[ 4 ]
นโยบายแบบคิวที่เรียบง่าย
เข้าก่อนออกก่อน (FIFO)
ด้วยอัลกอริทึมนี้ แคชจะทำงานเหมือนคิวแบบ FIFOกล่าวคือ จะลบบล็อกตามลำดับที่เพิ่มเข้ามา โดยไม่คำนึงถึงความถี่หรือจำนวนครั้งที่เข้าถึงก่อนหน้านี้
เข้าหลังออกก่อน (LIFO) หรือ เข้าก่อนออกหลัง (FILO)
แคชทำงานคล้ายกับสแต็กและแตกต่างจากคิวแบบ FIFO แคชจะลบข้อมูลที่เพิ่มเข้ามาล่าสุดก่อน โดยไม่คำนึงถึงความถี่หรือจำนวนครั้งที่เข้าถึงข้อมูลนั้นมาก่อน
ตะแกรง
SIEVEเป็นอัลกอริทึมการลบข้อมูลแบบง่ายที่ออกแบบมาโดยเฉพาะสำหรับแคชเว็บ เช่น แคชแบบคีย์-ค่า และเครือข่ายการส่งเนื้อหา (Content Delivery Networks) โดยใช้แนวคิดของการเลื่อนระดับแบบขี้เกียจและการลดระดับอย่างรวดเร็ว[ 5 ]ดังนั้น SIEVE จึงไม่อัปเดตโครงสร้างข้อมูล ทั่วโลก เมื่อมีการเรียกใช้แคช และจะชะลอการอัปเดตจนกว่าจะถึงเวลาลบข้อมูล ในขณะเดียวกัน ก็จะลบวัตถุที่แทรกเข้ามาใหม่อย่างรวดเร็ว เนื่องจากภาระงานของแคชมักแสดงอัตราส่วนการเรียกใช้เพียงครั้งเดียวที่สูง และวัตถุใหม่ส่วนใหญ่ไม่คุ้มค่าที่จะเก็บไว้ในแคช SIEVE ใช้คิว FIFO เดียวและใช้มือที่เคลื่อนที่เพื่อเลือกวัตถุที่จะลบ วัตถุในแคชมีข้อมูลเมตาหนึ่งบิตที่ระบุว่าวัตถุนั้นได้รับการร้องขอหลังจากได้รับการยอมรับเข้าสู่แคชหรือไม่ มือที่ใช้ในการลบจะชี้ไปที่ท้ายคิวในตอนเริ่มต้นและเคลื่อนที่ไปยังหัวคิวเมื่อเวลาผ่านไป เมื่อเปรียบเทียบกับอัลกอริทึมการลบข้อมูล CLOCK วัตถุที่เก็บไว้ใน SIEVE จะยังคงอยู่ในตำแหน่งเดิม ดังนั้น วัตถุใหม่จึงอยู่ที่หัวคิวเสมอ และวัตถุเก่าจะอยู่ที่ท้ายคิวเสมอ เมื่อมือเคลื่อนไปทางศีรษะ วัตถุใหม่จะถูกขับไล่ออกไปอย่างรวดเร็ว (การลดตำแหน่งอย่างรวดเร็ว) [ 6 ]
นโยบายแบบง่ายที่อิงตามความใหม่
การใช้งานล่าสุดน้อยที่สุด (LRU)
ทิ้งรายการที่ใช้งานล่าสุดน้อยที่สุดก่อน อัลกอริทึมนี้ต้องติดตามว่าใช้อะไรและเมื่อใด ซึ่งยุ่งยาก ต้องใช้ "บิตอายุ" สำหรับแคชไลน์และติดตามแคชไลน์ที่ใช้งานล่าสุดน้อยที่สุดโดยอิงจากบิตอายุเหล่านี้ เมื่อแคชไลน์ถูกใช้งาน อายุของแคชไลน์อื่นๆ จะเปลี่ยนไป LRU เป็นตระกูลของอัลกอริทึมแคชซึ่งรวมถึง 2Q โดย Theodore Johnson และDennis Shasha [ 7 ]และ LRU/K โดย Pat O'Neil, Betty O'Neil และGerhard Weikum [ 8 ] ลำดับการเข้าถึงสำหรับตัวอย่างคือ ABCDEDF:

เมื่อ ABCD ถูกติดตั้งในบล็อกที่มีหมายเลขลำดับ (เพิ่มขึ้น 1 สำหรับการเข้าถึงใหม่แต่ละครั้ง) และมีการเข้าถึง E แสดงว่า E พลาดและต้องติดตั้งในบล็อก ด้วยอัลกอริทึม LRU E จะแทนที่ A เพราะ A มีลำดับต่ำที่สุด (A(0)) ในขั้นตอนก่อนสุดท้าย จะมีการเข้าถึง D และหมายเลขลำดับจะได้รับการอัปเดต จากนั้นจะมีการเข้าถึง F แทนที่ B ซึ่งมีลำดับต่ำที่สุด (B(1))
การใช้งานล่าสุดที่คำนึงถึงเวลา (TLRU)
TLRU (Time-aware, least recently used) [ 9 ]เป็นรูปแบบหนึ่งของ LRU ที่ออกแบบมาสำหรับกรณีที่เนื้อหาของแคชมีอายุการใช้งานที่ถูกต้อง อัลกอริทึมนี้เหมาะสำหรับแอปพลิเคชันแคชเครือข่าย เช่นเครือข่ายที่เน้นข้อมูลเป็นศูนย์กลาง (ICN) เครือข่ายการส่งมอบเนื้อหา (CDN) และเครือข่ายแบบกระจายโดยทั่วไป TLRU นำเสนอคำว่า TTU (time to use) ซึ่งเป็นการประทับเวลาของเนื้อหา (หรือหน้าเว็บ) ที่กำหนดเวลาการใช้งานสำหรับเนื้อหาตามตำแหน่งที่ตั้งและผู้เผยแพร่เนื้อหา TTU ช่วยให้ผู้ดูแลระบบในพื้นที่สามารถควบคุมการจัดเก็บข้อมูลเครือข่ายได้มากขึ้น
เมื่อเนื้อหาที่อยู่ภายใต้กฎ TLRU มาถึงโหนด แคช จะคำนวณค่า TTU ในพื้นที่โดยอิงจากค่า TTU ที่ผู้เผยแพร่เนื้อหากำหนด ค่า TTU ในพื้นที่คำนวณโดยใช้ฟังก์ชันที่กำหนดไว้ในพื้นที่ เมื่อคำนวณค่า TTU ในพื้นที่แล้ว การแทนที่เนื้อหาจะดำเนินการกับส่วนย่อยของเนื้อหาทั้งหมดในโหนดแคช TLRU ช่วยให้มั่นใจได้ว่าเนื้อหาที่ไม่ได้รับความนิยมและมีอายุสั้นจะถูกแทนที่ด้วยเนื้อหาที่เข้ามาใหม่
ใช้งานล่าสุด (MRU)
ต่างจาก LRU, MRU จะทิ้งรายการที่ใช้ล่าสุดก่อน ในการประชุม VLDB ครั้งที่ 11 Chou และ DeWitt กล่าวว่า "เมื่อไฟล์ถูกสแกนซ้ำๆ ในรูปแบบการอ้างอิงแบบวนซ้ำตามลำดับ MRU เป็นอัลกอริทึมการแทนที่ ที่ดีที่สุด " [ 10 ]นักวิจัยที่นำเสนอในการประชุม VLDB ครั้งที่ 22 ตั้งข้อสังเกตว่าสำหรับ รูปแบบ การเข้าถึงแบบสุ่มและการสแกนซ้ำๆ บนชุดข้อมูล ขนาดใหญ่ (หรือที่เรียกว่ารูปแบบการเข้าถึงแบบวนรอบ) อัลกอริทึมแคช MRU มีการเข้าถึงมากกว่า LRU เนื่องจากมีแนวโน้มที่จะเก็บข้อมูลที่เก่ากว่า[ 11 ]อัลกอริทึม MRU มีประโยชน์มากที่สุดในสถานการณ์ที่ยิ่งรายการเก่าเท่าไหร่ ก็ยิ่งมีโอกาสถูกเข้าถึงมากขึ้นเท่านั้น ลำดับการเข้าถึงสำหรับตัวอย่างคือ ABCDECDB:
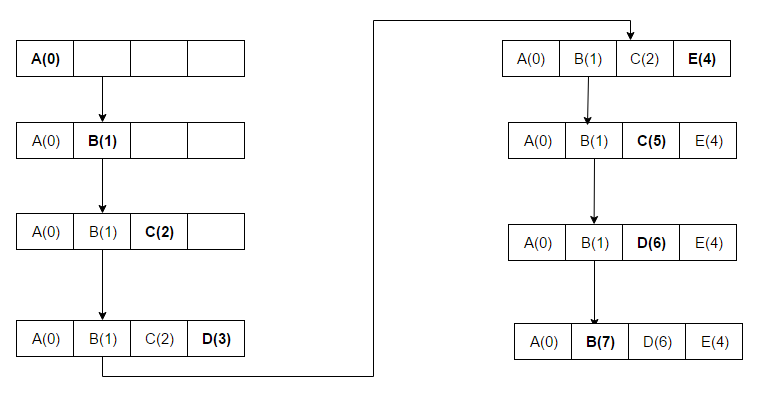
ข้อมูล ABCD ถูกจัดเก็บไว้ในแคช เนื่องจากมีพื้นที่ว่างอยู่ ในการเข้าถึงครั้งที่ห้า (E) บล็อกที่เคยเก็บค่า D จะถูกแทนที่ด้วย E เนื่องจากบล็อกนี้ถูกใช้งานล่าสุด ในการเข้าถึงครั้งถัดไป (ไปยัง D) บล็อก C จะถูกแทนที่ด้วย E เนื่องจากเป็นบล็อกที่ถูกเข้าถึงก่อนหน้า D
LRU แบบแบ่งส่วน (SLRU)
แคช SLRU แบ่งออกเป็นสองส่วน: ส่วนทดลองและส่วนป้องกัน บรรทัดในแต่ละส่วนจะเรียงลำดับจากที่เข้าถึงล่าสุดไปจนถึงที่เข้าถึงล่าสุดน้อยที่สุด ข้อมูลจากการพลาดจะถูกเพิ่มเข้าไปในแคชที่ปลายส่วนที่เข้าถึงล่าสุดของส่วนทดลอง การเข้าถึงสำเร็จจะถูกลบออกจากตำแหน่งเดิมและเพิ่มเข้าไปในปลายส่วนที่เข้าถึงล่าสุดของส่วนป้องกัน บรรทัดในส่วนป้องกันจะต้องถูกเข้าถึงอย่างน้อยสองครั้ง ส่วนป้องกันมีขนาดจำกัด การย้ายบรรทัดจากส่วนทดลองไปยังส่วนป้องกันอาจบังคับให้ย้ายบรรทัด LRU ในส่วนป้องกันไปยังปลายส่วนที่ใช้ล่าสุดที่สุดของส่วนทดลอง ทำให้บรรทัดนี้มีโอกาสถูกเข้าถึงอีกครั้งก่อนที่จะถูกแทนที่ ขีดจำกัดขนาดของส่วนป้องกันเป็นพารามิเตอร์ SLRU ซึ่งแตกต่างกันไปตาม รูปแบบภาระงาน I/Oเมื่อต้องทิ้งข้อมูลออกจากแคช บรรทัดจะถูกดึงมาจากปลาย LRU ของส่วนทดลอง[ 12 ]
การประมาณค่า LRU
LRU อาจมีค่าใช้จ่ายสูงในแคชที่มีระดับความสัมพันธ์ สูง ฮาร์ดแวร์ในทางปฏิบัติมักใช้วิธีการประมาณค่าเพื่อให้ได้ประสิทธิภาพที่ใกล้เคียงกันด้วยต้นทุนฮาร์ดแวร์ที่ต่ำกว่า
พсевдоль лура (PLRU)
สำหรับแคชของซีพียู ที่มี ความสัมพันธ์สูง(โดยทั่วไปมากกว่าสี่ทาง) ต้นทุนในการใช้งาน LRU จะสูงเกินไป ในแคชของซีพียูหลายๆ ตัว อัลกอริทึมที่มักจะทิ้งรายการที่ใช้งานน้อยที่สุดรายการใดรายการหนึ่งก็เพียงพอแล้ว นักออกแบบซีพียูหลายคนจึงเลือกใช้อัลกอริทึม PLRU ซึ่งต้องการเพียงหนึ่งบิตต่อรายการในแคชเท่านั้นในการทำงาน โดยทั่วไปแล้ว PLRU จะมีอัตราการพลาดที่แย่กว่าเล็กน้อย มีความหน่วง ที่ดีกว่าเล็กน้อย ใช้พลังงานน้อยกว่า LRU เล็กน้อย และมีโอเวอร์เฮด ต่ำ กว่า LRU
บิตทำงานเหมือนต้นไม้ไบนารีของตัวชี้หนึ่งบิตซึ่งชี้ไปยังต้นไม้ย่อยที่ใช้งานน้อยที่สุด การติดตามสายโซ่ของตัวชี้ไปยังโหนดใบจะระบุตัวเลือกทดแทน เมื่อมีการเข้าถึง ตัวชี้ทั้งหมดในสายโซ่จากโหนดใบของเส้นทางที่เข้าถึงไปยังโหนดรากจะถูกตั้งค่าให้ชี้ไปยังต้นไม้ย่อยที่ไม่มีเส้นทางที่เข้าถึง ลำดับการเข้าถึงในตัวอย่างคือ ABCDE:
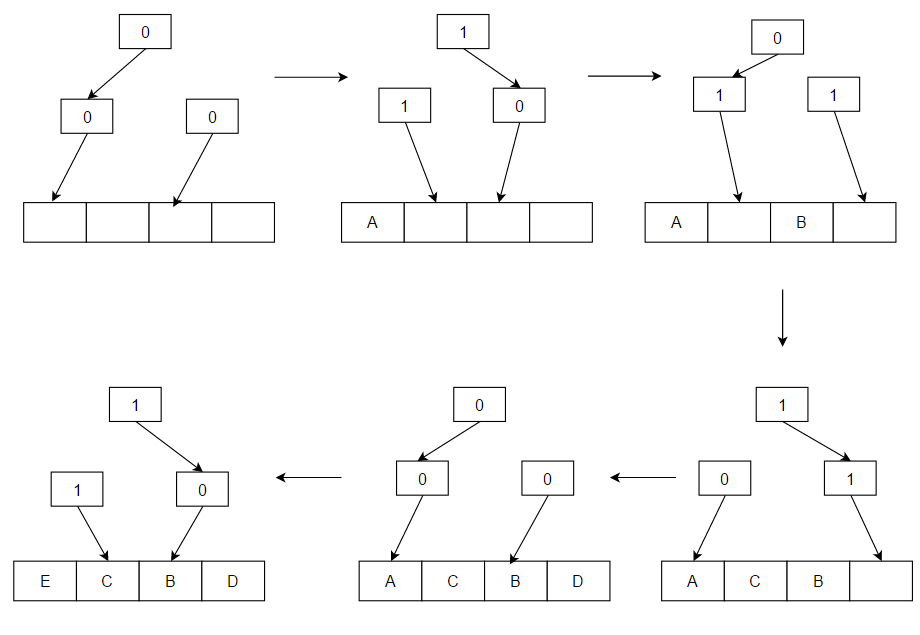
เมื่อมีการเข้าถึงค่า (เช่น A) และค่านั้นไม่อยู่ในแคช ระบบจะโหลดค่าดังกล่าวจากหน่วยความจำและวางไว้ในบล็อกที่ลูกศรชี้ในตัวอย่าง หลังจากวางบล็อกนั้นแล้ว ลูกศรจะเปลี่ยนทิศทางชี้ไปในทิศทางตรงกันข้าม A, B, C และ D ถูกวางลงไปแล้ว E จะเข้ามาแทนที่ A เมื่อแคชเต็ม เนื่องจากลูกศรเคยชี้ไปที่ E และลูกศรที่ชี้ไปยัง A จะเปลี่ยนทิศทางชี้ไปในทิศทางตรงกันข้าม (ไปยัง B ซึ่งเป็นบล็อกที่จะถูกแทนที่เมื่อแคชพลาดในครั้งถัดไป)
นาฬิกาโปร
อัลกอริทึม LRU ไม่สามารถนำไปใช้ในเส้นทางวิกฤตของระบบคอมพิวเตอร์ เช่นระบบปฏิบัติการได้ เนื่องจากมีค่าใช้จ่ายสูงClockซึ่งเป็นการประมาณค่าของ LRU จึงมักถูกนำมาใช้แทน Clock-Pro เป็นการประมาณค่าของLIRSสำหรับการใช้งานในระบบด้วยต้นทุนต่ำ[ 13 ] Clock-Pro มีโครงสร้างพื้นฐานของ Clock พร้อมข้อดีสามประการ คือ มี "เข็มนาฬิกา" สามเข็ม (ต่างจาก Clock ที่มี "เข็มนาฬิกา" เพียงเข็มเดียว) และสามารถวัดระยะการใช้ซ้ำของการเข้าถึงข้อมูลได้โดยประมาณ เช่นเดียวกับ LIRS มันสามารถกำจัดรายการข้อมูลที่เข้าถึงครั้งเดียวหรือ ข้อมูล ที่มีตำแหน่ง ต่ำได้อย่างรวดเร็ว Clock-Pro มีความซับซ้อนเท่ากับ Clock และง่ายต่อการใช้งานด้วยต้นทุนต่ำ การใช้งานการแทนที่บัฟเฟอร์แคชในLinux เวอร์ชัน 2017 ได้รวม LRU และ Clock-Pro เข้าด้วยกัน[ 14 ] [ 15 ]
นโยบายแบบง่ายที่อิงตามความถี่
ใช้งานน้อยที่สุด (LFU)
อัลกอริทึม LFU จะนับความถี่ในการเรียกใช้รายการนั้นๆ โดยรายการที่ใช้งานน้อยกว่าจะถูกลบออกก่อน หลักการทำงานคล้ายกับ LRU แต่จะเก็บจำนวนครั้งที่เข้าถึงบล็อกแทนที่จะเป็นความถี่ในการเข้าถึงล่าสุด ในระหว่างการประมวลผลลำดับการเข้าถึง บล็อกที่ใช้งานน้อยที่สุดจะถูกลบออกจากแคช
การใช้งานล่าสุดที่น้อยที่สุด (LFRU)
อัลกอริทึม Least Frequent Recently Used (LFRU) [ 16 ]ผสานข้อดีของ LFU และ LRU เข้าด้วยกัน LFRU เหมาะสำหรับแอปพลิเคชันแคชเครือข่าย เช่นICN , CDNและเครือข่ายแบบกระจายทั่วไป ใน LFRU แคชจะถูกแบ่งออกเป็นสองพาร์ติชัน: พาร์ติชันที่มีสิทธิ์และพาร์ติชันที่ไม่มีสิทธิ์ พาร์ติชันที่มีสิทธิ์ได้รับการปกป้อง หากเนื้อหาเป็นที่นิยม เนื้อหานั้นจะถูกผลักเข้าไปในพาร์ติชันที่มีสิทธิ์ ในการแทนที่พาร์ติชันที่มีสิทธิ์ LFRU จะขับไล่เนื้อหาออกจากพาร์ติชันที่ไม่มีสิทธิ์ ผลักเนื้อหาจากพาร์ติชันที่มีสิทธิ์ไปยังพาร์ติชันที่ไม่มีสิทธิ์ และแทรกเนื้อหาใหม่เข้าไปในพาร์ติชันที่มีสิทธิ์ LRU ใช้สำหรับพาร์ติชันที่มีสิทธิ์ และอัลกอริทึม LFU โดยประมาณ (ALFU) ใช้สำหรับพาร์ติชันที่ไม่มีสิทธิ์
LFU ที่มีการเสื่อมสภาพแบบไดนามิก (LFUDA)
LFU เวอร์ชันที่มีการจัดการอายุแบบไดนามิก (LFUDA) ใช้การจัดการอายุแบบไดนามิกเพื่อรองรับการเปลี่ยนแปลงในชุดของวัตถุยอดนิยม โดยจะเพิ่มปัจจัยอายุแคชให้กับจำนวนการอ้างอิงเมื่อมีการเพิ่มวัตถุใหม่ลงในแคชหรือมีการอ้างอิงวัตถุที่มีอยู่ซ้ำ LFUDA จะเพิ่มอายุแคชเมื่อลบบล็อกโดยตั้งค่าเป็นค่าคีย์ของวัตถุที่ถูกลบ และอายุแคชจะน้อยกว่าหรือเท่ากับค่าคีย์ต่ำสุดในแคชเสมอ[ 17 ]หากวัตถุใดถูกเข้าถึงบ่อยในอดีตและไม่เป็นที่นิยมอีกต่อไป วัตถุนั้นจะยังคงอยู่ในแคชเป็นเวลานาน (ป้องกันไม่ให้วัตถุใหม่หรือวัตถุที่ได้รับความนิยมน้อยกว่าเข้ามาแทนที่) การจัดการอายุแบบไดนามิกจะลดจำนวนวัตถุดังกล่าว ทำให้วัตถุเหล่านั้นมีสิทธิ์ได้รับการแทนที่ และ LFUDA จะลดมลภาวะของแคชที่เกิดจาก LFU เมื่อแคชมีขนาดเล็ก
S3-FIFO
นี่คืออัลกอริทึมการล้างแคชแบบใหม่ที่ออกแบบในปี 2023 เมื่อเทียบกับอัลกอริทึมที่มีอยู่เดิม ซึ่งส่วนใหญ่สร้างขึ้นจาก LRU (least-recently-used) S3-FIFO ใช้คิว FIFO เพียงสามคิวเท่านั้น ได้แก่ คิวขนาดเล็กที่ใช้พื้นที่แคช 10% คิวหลักที่ใช้พื้นที่แคช 90% และคิวเสมือน (ghost queue) ที่เก็บเฉพาะเมตาเดต้าของวัตถุ คิวขนาดเล็กใช้สำหรับกรองวัตถุที่ถูกเข้าถึงเพียงครั้งเดียวในช่วงเวลาสั้นๆ คิวหลักใช้สำหรับจัดเก็บวัตถุที่ได้รับความนิยมและใช้การแทรกซ้ำเพื่อเก็บไว้ในแคช และคิวเสมือนใช้สำหรับดักจับวัตถุที่อาจได้รับความนิยมซึ่งถูกล้างออกจากคิวขนาดเล็ก วัตถุจะถูกแทรกเข้าไปในคิวขนาดเล็กก่อน (หากไม่พบในคิวเสมือน มิฉะนั้นจะถูกแทรกเข้าไปในคิวหลัก) เมื่อถูกไล่ออกจากคิวเล็ก หากมีการร้องขอวัตถุ วัตถุนั้นจะถูกแทรกกลับเข้าไปในคิวหลัก มิฉะนั้น วัตถุนั้นจะถูกไล่ออก และเมตาเดต้าจะถูกติดตามในคิวผี[ 18 ]
นโยบายแบบ RRIP
นโยบายแบบ RRIP เป็นพื้นฐานสำหรับนโยบายการแทนที่แคชอื่นๆ รวมถึง Hawkeye [ 19 ]
การทำนายช่วงการอ้างอิงซ้ำ (RRIP)
RRIP [ 20 ]เป็นนโยบายที่ยืดหยุ่นซึ่งเสนอโดยIntelซึ่งพยายามให้ความต้านทานต่อการสแกนที่ดีในขณะที่อนุญาตให้แคชไลน์เก่าที่ไม่ได้นำกลับมาใช้ใหม่ถูกกำจัดออกไป แคชไลน์ทั้งหมดมีค่าการคาดการณ์ RRPV (ค่าการคาดการณ์การอ้างอิงซ้ำ) ซึ่งควรสัมพันธ์กับเวลาที่คาดว่าจะนำแคชไลน์นั้นกลับมาใช้ใหม่ โดยปกติ RRPV จะสูงเมื่อมีการแทรก หากแคชไลน์ไม่ถูกนำกลับมาใช้ใหม่ในเร็วๆ นี้ แคชไลน์นั้นจะถูกกำจัดออกไปเพื่อป้องกันการสแกน (ข้อมูลจำนวนมากที่ใช้เพียงครั้งเดียว) จากการเติมแคช เมื่อแคชไลน์ถูกนำกลับมาใช้ใหม่ RRPV จะถูกตั้งค่าเป็นศูนย์ ซึ่งบ่งชี้ว่าแคชไลน์นั้นถูกนำกลับมาใช้ใหม่แล้วหนึ่งครั้งและมีแนวโน้มที่จะถูกนำกลับมาใช้ใหม่อีกครั้ง
เมื่อแคชพลาด (cache miss) บรรทัดที่มีค่า RRPV เท่ากับค่า RRPV สูงสุดที่เป็นไปได้จะถูกลบออก สำหรับค่า 3 บิต บรรทัดที่มีค่า RRPV เท่ากับ 2³ - 1 = 7 จะถูกลบออก หากไม่มีบรรทัดใดมีค่านี้ ค่า RRPV ของทุกบรรทัดในชุดจะถูกเพิ่มขึ้นทีละ 1 จนกว่าจะพบบรรทัดที่มีค่าเท่ากับค่านี้ หากมีค่าเท่ากัน จะต้องมีการใช้บรรทัดแรกทางด้านซ้ายเป็นตัวตัดสิน การเพิ่มค่านี้จำเป็นเพื่อให้แน่ใจว่าบรรทัดเก่าได้รับการกำหนดอายุอย่างถูกต้องและจะถูกลบออกหากไม่ได้นำกลับมาใช้ใหม่
RRIP แบบคงที่ (SRRIP)
SRRIP จะแทรกบรรทัดที่มีค่า RRPV เท่ากับ maxRRPV; บรรทัดที่เพิ่งแทรกเข้าไปจะมีโอกาสถูกลบออกมากที่สุดเมื่อเกิดแคชพลาด
RRIP แบบสองโหมด (BRRIP)
โดยปกติแล้ว SRRIP ทำงานได้ดี แต่จะมีปัญหาเมื่อชุดข้อมูลที่ใช้งานอยู่มีขนาดใหญ่กว่าขนาดของแคชมาก และทำให้เกิดปัญหาแคชสแก็ด (cache thrashing ) ปัญหานี้แก้ไขได้โดยการแทรกบรรทัดที่มีค่า RRPV เท่ากับ maxRRPV ในส่วนใหญ่ และแทรกบรรทัดที่มีค่า RRPV เท่ากับ maxRRPV - 1 แบบสุ่มด้วยความน่าจะเป็นต่ำ วิธีนี้จะทำให้บางบรรทัด "ติด" อยู่ในแคช และช่วยป้องกันปัญหาแคชสแก็ด อย่างไรก็ตาม BRRIP จะทำให้ประสิทธิภาพลดลงในการเข้าถึงข้อมูลที่ไม่เกิดปัญหาแคชสแก็ด SRRIP ทำงานได้ดีที่สุดเมื่อชุดข้อมูลที่ใช้งานอยู่มีขนาดเล็กกว่าแคช และ BRRIP ทำงานได้ดีที่สุดเมื่อชุดข้อมูลที่ใช้งานอยู่มีขนาดใหญ่กว่าแคช
RRIP แบบไดนามิก (DRRIP)
DRRIP [ 20 ]ใช้ set dueling [ 21 ]เพื่อเลือกว่าจะใช้ SRRIP หรือ BRRIP โดยจะจัดสรรชุดข้อมูลจำนวนหนึ่ง (โดยทั่วไปคือ 32 ชุด) ให้ใช้ SRRIP และอีกจำนวนหนึ่งให้ใช้ BRRIP และใช้ตัวนับนโยบายที่ตรวจสอบประสิทธิภาพของชุดข้อมูลเพื่อพิจารณาว่านโยบายใดจะถูกใช้โดยแคชที่เหลือ
นโยบายที่ประมาณค่าตามอัลกอริทึมของเบลาดี
อัลกอริทึมของ Bélády เป็นนโยบายการแทนที่แคชที่เหมาะสมที่สุด แต่ต้องอาศัยความรู้เกี่ยวกับอนาคตเพื่อขับไล่บรรทัดที่จะถูกนำกลับมาใช้ใหม่ในอนาคตอันไกลโพ้น นโยบายการแทนที่จำนวนหนึ่งได้รับการเสนอขึ้นโดยพยายามทำนายระยะการนำกลับมาใช้ใหม่ในอนาคตจากรูปแบบการเข้าถึงในอดีต[ 22 ]ทำให้สามารถประมาณนโยบายการแทนที่ที่เหมาะสมที่สุดได้ นโยบายการแทนที่แคชที่มีประสิทธิภาพดีที่สุดบางส่วนพยายามเลียนแบบอัลกอริทึมของ Bélády
ฮอว์คอาย
Hawkeye [ 19 ]พยายามเลียนแบบอัลกอริทึมของ Bélády โดยใช้การเข้าถึงในอดีตของ PC เพื่อทำนายว่าการเข้าถึงที่เกิดขึ้นนั้นสร้างการเข้าถึงที่เป็นมิตรกับแคช (ใช้ในภายหลัง) หรือการเข้าถึงที่ไม่เป็นมิตรกับแคช (ไม่ใช้ในภายหลัง) โดยจะสุ่มตัวอย่างชุดแคชที่ไม่ตรงแนวจำนวนหนึ่ง ใช้ประวัติความยาวและเลียนแบบอัลกอริทึมของ Bélády ในการเข้าถึงเหล่านี้ ซึ่งช่วยให้นโยบายสามารถกำหนดได้ว่าบรรทัดใดควรแคชและบรรทัดใดไม่ควรแคช โดยทำนายว่าคำสั่งนั้นเป็นมิตรกับแคชหรือไม่เป็นมิตรกับแคช จากนั้นข้อมูลนี้จะถูกป้อนเข้าสู่ RRIP การเข้าถึงจากคำสั่งที่เป็นมิตรกับแคชจะมีค่า RRPV ต่ำกว่า (มีแนวโน้มที่จะถูกลบออกในภายหลัง) และการเข้าถึงจากคำสั่งที่ไม่เป็นมิตรกับแคชจะมีค่า RRPV สูงกว่า (มีแนวโน้มที่จะถูกลบออกเร็วกว่า) ส่วนหลังของ RRIP จะทำการตัดสินใจการลบออก แคชที่สุ่มตัวอย่างและ ตัวสร้าง OPTจะกำหนดค่า RRPV เริ่มต้นของบรรทัดแคชที่แทรกเข้าไป Hawkeye ชนะการแข่งขันแคช CRC2 ในปี 2017 [ 23 ]และ Harmony [ 24 ]เป็นส่วนขยายของ Hawkeye ซึ่งปรับปรุงประสิทธิภาพการดึงข้อมูลล่วงหน้า


นกม็อกกิ้งเจย์
Mockingjay [ 25 ]พยายามปรับปรุง Hawkeye ในหลาย ๆ ด้าน โดยยกเลิกการทำนายแบบไบนารี ทำให้สามารถตัดสินใจได้ละเอียดขึ้นเกี่ยวกับแคชไลน์ที่จะลบออก และปล่อยให้การตัดสินใจเกี่ยวกับแคชไลน์ที่จะลบออกเกิดขึ้นเมื่อมีข้อมูลเพิ่มเติม
Mockingjay เก็บแคชตัวอย่างของการเข้าถึงที่ไม่ซ้ำกัน พีซีที่สร้างการเข้าถึงเหล่านั้น และการประทับเวลา เมื่อมีการเข้าถึงบรรทัดในแคชตัวอย่างอีกครั้ง ความแตกต่างของเวลาจะถูกส่งไปยังตัวทำนายระยะการใช้ซ้ำ RDP ใช้การเรียนรู้ความแตกต่างเชิงเวลา[ 26 ]โดยที่ค่า RDP ใหม่จะเพิ่มขึ้นหรือลดลงด้วยจำนวนเล็กน้อยเพื่อชดเชยค่าผิดปกติ จำนวนนี้คำนวณได้จากหากค่าไม่ได้เริ่มต้น ระยะการใช้ซ้ำที่สังเกตได้จะถูกแทรกโดยตรง หากแคชตัวอย่างเต็มและจำเป็นต้องทิ้งบรรทัด RDP จะได้รับคำสั่งให้พีซีที่เข้าถึงครั้งสุดท้ายสร้างการเข้าถึงแบบสตรีมมิ่ง

เมื่อมีการเข้าถึงหรือแทรกข้อมูล เวลาโดยประมาณในการใช้ซ้ำ (ETR) สำหรับบรรทัดนี้จะได้รับการอัปเดตเพื่อสะท้อนระยะทางในการใช้ซ้ำที่คาดการณ์ไว้ ในกรณีที่แคชไม่พบข้อมูล บรรทัดที่มีค่า ETR สูงที่สุดจะถูกนำออกจากแคช ผลลัพธ์ของ Mockingjay ใกล้เคียงกับอัลกอริทึม Bélády ที่ดีที่สุด
นโยบายการเรียนรู้ของเครื่อง
นโยบายหลายฉบับได้พยายามใช้เพอร์เซปตรอนโซ่มาร์คอฟหรือการเรียนรู้ของเครื่อง ประเภทอื่น ๆ เพื่อทำนายว่าควรไล่สายใดออก[ 27 ] [ 28 ] นอกจากนี้ยังมี อัลกอริธึมเสริมการเรียนรู้สำหรับการแทนที่แคช [ 29 ] [ 30 ]
นโยบายอื่นๆ
ชุดความใหม่ระหว่างการอ้างอิงต่ำ (LIRS)
LIRS เป็นอัลกอริทึมการแทนที่หน้าเว็บที่มีประสิทธิภาพดีกว่า LRU และอัลกอริทึมการแทนที่อื่นๆ ที่ใหม่กว่า ระยะทางการใช้ซ้ำเป็นตัวชี้วัดสำหรับการจัดอันดับหน้าเว็บที่เข้าถึงแบบไดนามิกเพื่อตัดสินใจแทนที่[ 31 ] LIRS แก้ไขข้อจำกัดของ LRU โดยใช้ความใหม่เพื่อประเมินความใหม่ระหว่างการอ้างอิง (IRR) เพื่อตัดสินใจแทนที่

ในแผนภาพ X แสดงถึงการเข้าถึงบล็อก ณ เวลาใดเวลาหนึ่ง หากบล็อก A1 ถูกเข้าถึง ณ เวลา 1 ค่าความใหม่ของบล็อกจะเป็น 0 ซึ่งเป็นบล็อกที่ถูกเข้าถึงเป็นครั้งแรก และค่า IRR จะเป็น 1 เนื่องจากทำนายว่า A1 จะถูกเข้าถึงอีกครั้ง ณ เวลา 3 ณ เวลา 2 เนื่องจากมีการเข้าถึง A4 ค่าความใหม่ของ A4 จะเป็น 0 และค่าใหม่ของ A1 จะเป็น 1 ซึ่ง A4 เป็นวัตถุที่ถูกเข้าถึงล่าสุด และค่า IRR จะเป็น 4 ณ เวลา 10 อัลกอริทึม LIRS จะมีสองชุด ได้แก่ ชุด LIR = {A1, A2} และชุด HIR = {A3, A4, A5} ณ เวลา 10 หากมีการเข้าถึง A4 จะเกิดข้อผิดพลาด LIRS จะลบ A5 ออกแทน A2 เนื่องจากค่าความใหม่ที่มากกว่า
แคชทดแทนแบบปรับได้
แคชทดแทนแบบปรับได้ (ARC) จะปรับสมดุลระหว่าง LRU และ LFU อย่างต่อเนื่องเพื่อปรับปรุงผลลัพธ์โดยรวม[ 32 ]ปรับปรุง SLRU โดยใช้ข้อมูลเกี่ยวกับรายการแคชที่ถูกลบออกไปเมื่อเร็ว ๆ นี้เพื่อปรับขนาดของเซ็กเมนต์ที่ได้รับการป้องกันและเซ็กเมนต์ทดลองเพื่อให้ใช้พื้นที่แคชที่มีอยู่ให้เกิดประโยชน์สูงสุด[ 33 ]
นาฬิกาที่มีระบบเปลี่ยนทดแทนแบบปรับได้
ระบบนาฬิกาแบบปรับเปลี่ยนได้ (CAR) ผสานข้อดีของ ARC และClock เข้าด้วยกัน CAR มีประสิทธิภาพเทียบเท่ากับ ARC และมีประสิทธิภาพเหนือกว่า LRU และ Clock เช่นเดียวกับ ARC, CAR สามารถปรับแต่งตัวเองได้และไม่ต้องการพารามิเตอร์ที่ผู้ใช้กำหนด
คิวหลายคิว
อัลกอริทึมการแทนที่คิวหลายคิว (MQ) ได้รับการพัฒนาเพื่อปรับปรุงประสิทธิภาพของแคชบัฟเฟอร์ระดับที่สอง เช่น แคชบัฟเฟอร์เซิร์ฟเวอร์ และได้รับการแนะนำในเอกสารโดย Zhou, Philbin และ Li [ 34 ]แคช MQ ประกอบด้วย คิว LRU จำนวน mคิว ได้แก่ Q 0 , Q 1 , ..., Q m -1ค่าของmแสดงถึงลำดับชั้นตามอายุการใช้งานของบล็อกทั้งหมดในคิวนั้น[ 35 ]

แพนเนียร์
Pannier [ 36 ]เป็นกลไกแคชแฟลชแบบคอนเทนเนอร์ซึ่งระบุคอนเทนเนอร์ที่มีบล็อกที่มีรูปแบบการเข้าถึงที่แปรผัน Pannier มีโครงสร้างคิวการอยู่รอดตามลำดับความสำคัญเพื่อจัดอันดับคอนเทนเนอร์ตามเวลาการอยู่รอด ซึ่งเป็นสัดส่วนกับข้อมูลที่มีชีวิตในคอนเทนเนอร์
การวิเคราะห์สถิต
การวิเคราะห์แบบคงที่กำหนดว่าการเข้าถึงใดเป็นแคชฮิตหรือแคชมิส เพื่อระบุเวลาการทำงานที่เลวร้ายที่สุดของโปรแกรม[ 37 ]แนวทางในการวิเคราะห์คุณสมบัติของแคช LRU คือการกำหนด "อายุ" ให้กับแต่ละบล็อกในแคช (0 สำหรับบล็อกที่ใช้ล่าสุด) และคำนวณช่วงเวลาสำหรับอายุที่เป็นไปได้[ 38 ]การวิเคราะห์นี้สามารถปรับปรุงเพื่อแยกแยะกรณีที่จุดโปรแกรมเดียวกันสามารถเข้าถึงได้โดยเส้นทางที่ส่งผลให้เกิดแคชมิสหรือแคชฮิต[ 39 ]การวิเคราะห์ที่มีประสิทธิภาพอาจได้รับจากการสรุปชุดสถานะแคชโดยใช้แอนติเชนซึ่งแสดงด้วยไดอะแกรมการตัดสินใจแบบไบนารี ขนาดกะทัดรัด [ 40 ]
การวิเคราะห์แบบคงที่ของ LRU ไม่ขยายไปถึงนโยบาย pseudo-LRU ตามทฤษฎีความซับซ้อนของการคำนวณปัญหาการวิเคราะห์แบบคงที่ที่เกิดจาก pseudo-LRU และ FIFO อยู่ในระดับความซับซ้อน ที่สูง กว่าปัญหาของ LRU [ 41 ] [ 42 ]
ดูเพิ่มเติม
ลิงก์ภายนอก
- คำจำกัดความของอัลกอริธึมแคชประเภทต่างๆ
- อัลกอริทึมการแคชสำหรับแฟลช/SSD
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ นโยบายการแทนที่แคช
ในด้านการ คำนวณ นโยบายการแทนที่แคช (หรือที่เรียกว่า อัลกอริทึมการแทนที่แคช หรือ อัลกอริทึมแคช ) คือคำสั่งหรือ อัลกอริทึม การปรับให้เหมาะสม ซึ่ง โปรแกรมคอมพิวเตอร์...
อัลกอริทึมของเบลาดี
อัลกอริทึมการแคชที่มีประสิทธิภาพที่สุดคือการทิ้งข้อมูลที่ไม่จำเป็นต้องใช้เป็นเวลานานที่สุด ซึ่งรู้จักกันในชื่อ อัลกอริทึมที่เหมาะสมที่สุดของ เบลาดี (Bélády 's optimal algorithm) นโยบายการแทนที่ที่เหมาะสมที่สุด หรือ อัลกอริทึมแบบหยั่งรู้...
การทดแทนแบบสุ่ม (RR)
การแทนที่แบบสุ่มจะเลือกรายการหนึ่งรายการและทิ้งรายการนั้นเพื่อสร้างพื้นที่ว่างเมื่อจำเป็น อัลกอริทึมนี้ไม่จำเป็นต้องเก็บประวัติการเข้าถึงใดๆ มันถูกใช้ใน โปรเซสเซอร์ ARM เนื่องจากความเรียบง่าย [ 3 ] และช่วยให้ การจำลอง แบบสุ่ม มีประสิทธิภาพ [ 4 ]
นโยบายแบบคิวที่เรียบง่าย
ด้วยอัลกอริทึมนี้ แคชจะทำงานเหมือน คิวแบบ FIFO กล่าวคือ จะลบบล็อกตามลำดับที่เพิ่มเข้ามา โดยไม่คำนึงถึงความถี่หรือจำนวนครั้งที่เข้าถึงก่อนหน้านี้