อ่าน 25 นาที
ความเป็นธรรม (การเรียนรู้ของเครื่องจักร)
ความเป็นธรรมในด้านการเรียนรู้ของเครื่อง (ML) หมายถึงความพยายามต่างๆ ในการแก้ไขอคติของอัลกอริทึมในกระบวนการตัดสินใจอัตโนมัติโดยใช้แบบจำลอง ML...
ความเป็นธรรม (การเรียนรู้ของเครื่องจักร)
ความเป็นธรรมในด้านการเรียนรู้ของเครื่อง (ML) หมายถึงความพยายามต่างๆ ในการแก้ไขอคติของอัลกอริทึมในกระบวนการตัดสินใจอัตโนมัติโดยใช้แบบจำลอง ML การตัดสินใจที่ทำโดยแบบจำลองดังกล่าวหลังจากกระบวนการเรียนรู้ อาจถือว่าไม่เป็นธรรมหากอิงจากตัวแปรที่ถือว่ามีความอ่อนไหว (เช่น เพศ เชื้อชาติ รสนิยมทางเพศ หรือความพิการ)
เช่นเดียวกับ แนวคิด ทางจริยธรรม หลายๆ เรื่อง นิยามของความยุติธรรมและความลำเอียงอาจเป็นเรื่องที่ถกเถียงกันได้ โดยทั่วไปแล้ว ความยุติธรรมและความลำเอียงถือว่ามีความเกี่ยวข้องเมื่อกระบวนการตัดสินใจส่งผลกระทบต่อชีวิตของผู้คน
เนื่องจากการตัดสินใจโดยเครื่องจักรอาจได้รับอิทธิพลจากปัจจัยหลายประการ จึงอาจถูกมองว่าไม่ยุติธรรมต่อกลุ่มหรือบุคคลบางกลุ่ม ตัวอย่างเช่น วิธีที่ เว็บไซต์ โซเชียลมีเดียส่งข่าวสารส่วนบุคคลให้กับผู้บริโภค
บริบท
การอภิปรายเกี่ยวกับความยุติธรรมในการเรียนรู้ของเครื่องจักรเป็นหัวข้อที่ค่อนข้างใหม่ ตั้งแต่ปี 2016 เป็นต้นมา มีการวิจัยในหัวข้อนี้เพิ่มขึ้นอย่างมาก[ 1 ]การเพิ่มขึ้นนี้อาจเป็นผลมาจากรายงานที่มีอิทธิพลของProPublicaที่อ้างว่า ซอฟต์แวร์ COMPASซึ่งใช้กันอย่างแพร่หลายในศาลสหรัฐฯ เพื่อทำนายการกระทำผิดซ้ำมีอคติทางเชื้อชาติ[ 2 ]หัวข้อหนึ่งของการวิจัยและการอภิปรายคือคำจำกัดความของความยุติธรรม เนื่องจากไม่มีคำจำกัดความที่เป็นสากล และคำจำกัดความที่แตกต่างกันอาจขัดแย้งกัน ทำให้ยากต่อการตัดสินแบบจำลองการเรียนรู้ของเครื่องจักร[ 3 ]หัวข้อการวิจัยอื่นๆ ได้แก่ ต้นกำเนิดของอคติ ประเภทของอคติ และวิธีการลดอคติ[ 4 ]
ในช่วงไม่กี่ปีที่ผ่านมา บริษัทเทคโนโลยีได้สร้างเครื่องมือและคู่มือเกี่ยวกับวิธีการตรวจจับและลดอคติในการเรียนรู้ของเครื่องIBMมีเครื่องมือสำหรับPythonและRพร้อมอัลกอริทึมหลายตัวเพื่อลดอคติของซอฟต์แวร์และเพิ่มความเป็นธรรม[ 5 ] [ 6 ] Google ได้เผยแพร่แนวทางและเครื่องมือเพื่อศึกษาและต่อสู้กับอคติในการเรียนรู้ของเครื่อง[ 7 ] [ 8 ] Facebook ได้รายงานการใช้เครื่องมือ Fairness Flow เพื่อตรวจจับอคติในAI ของ ตน[ 9 ]อย่างไรก็ตาม นักวิจารณ์โต้แย้งว่าความพยายามของบริษัทนั้นไม่เพียงพอ โดยรายงานว่าพนักงานใช้เครื่องมือนี้น้อยมาก เนื่องจากไม่สามารถใช้ได้กับทุกโปรแกรม และแม้ว่าจะใช้ได้ การใช้เครื่องมือก็เป็นทางเลือก[ 10 ]
สิ่งสำคัญที่ควรทราบคือ การอภิปรายเกี่ยวกับวิธีการเชิงปริมาณในการทดสอบความยุติธรรมและการเลือกปฏิบัติที่ไม่เป็นธรรมในการตัดสินใจนั้นมีมาก่อนการถกเถียงเรื่องความยุติธรรมในการเรียนรู้ของเครื่องจักรหลายทศวรรษ[ 11 ]อันที่จริง การอภิปรายอย่างเข้มข้นในหัวข้อนี้โดยชุมชนวิทยาศาสตร์เฟื่องฟูในช่วงกลางทศวรรษ 1960 และ 1970 ส่วนใหญ่เป็นผลมาจากการเคลื่อนไหวเพื่อสิทธิพลเมือง ของอเมริกา และโดยเฉพาะอย่างยิ่งการผ่านร่างพระราชบัญญัติสิทธิพลเมืองของสหรัฐอเมริกาในปี 1964อย่างไรก็ตาม เมื่อสิ้นสุดทศวรรษ 1970 การถกเถียงดังกล่าวก็หายไปเป็นส่วนใหญ่ เนื่องจากแนวคิดเรื่องความยุติธรรมที่แตกต่างกันและบางครั้งก็ขัดแย้งกัน ทำให้ไม่มีที่ว่างสำหรับความชัดเจนว่าเมื่อใดที่แนวคิดเรื่องความยุติธรรมแบบหนึ่งอาจเหมาะสมกว่าอีกแบบหนึ่ง
อคติทางภาษา
อคติทางภาษาหมายถึงอคติในการสุ่มตัวอย่างทางสถิติประเภทหนึ่งที่เชื่อมโยงกับภาษาของคำถาม ซึ่งนำไปสู่ "การเบี่ยงเบนอย่างเป็นระบบในการสุ่มตัวอย่างข้อมูลที่ป้องกันไม่ให้แสดงถึงความครอบคลุมที่แท้จริงของหัวข้อและมุมมองที่มีอยู่ในคลังข้อมูลได้อย่างแม่นยำ" [ 12 ] Luo et al. [ 12 ]แสดงให้เห็นว่าแบบจำลองภาษาขนาดใหญ่ในปัจจุบัน เนื่องจากส่วนใหญ่ได้รับการฝึกฝนด้วยข้อมูลภาษาอังกฤษ จึงมักนำเสนอมุมมองของชาวแองโกล-อเมริกันว่าเป็นความจริง ในขณะที่ลดทอนมุมมองที่ไม่ใช่ภาษาอังกฤษอย่างเป็นระบบว่าเป็นสิ่งที่ไม่เกี่ยวข้อง ผิด หรือเป็นสัญญาณรบกวน เมื่อถูกถามด้วยอุดมการณ์ทางการเมืองเช่น "ลัทธิเสรีนิยมคืออะไร?" ChatGPTเนื่องจากได้รับการฝึกฝนด้วยข้อมูลที่เน้นภาษาอังกฤษ จึงอธิบายลัทธิเสรีนิยมจากมุมมองของชาวแองโกล-อเมริกัน โดยเน้นด้านสิทธิมนุษยชนและความเท่าเทียมกัน ในขณะที่ด้านอื่นๆ ที่ถูกต้องเช่นกัน เช่น "ต่อต้านการแทรกแซงของรัฐในชีวิตส่วนตัวและเศรษฐกิจ" จากมุมมองของชาวเวียดนามที่โดดเด่น และ "การจำกัดอำนาจของรัฐบาล" จากมุมมองของชาวจีนที่แพร่หลาย กลับไม่มีอยู่ ในทำนองเดียวกัน มุมมองทางการเมืองอื่นๆ ที่ฝังอยู่ในคลังข้อมูลภาษาญี่ปุ่น เกาหลี ฝรั่งเศส และเยอรมันนั้นไม่มีอยู่ในคำตอบของ ChatGPT ChatGPT ซึ่งอ้างว่าเป็นแชทบอทหลายภาษา แท้จริงแล้วส่วนใหญ่ 'มองไม่เห็น' มุมมองที่ไม่ใช่ภาษาอังกฤษ[ 12 ]
อคติทางเพศ
อคติทางเพศหมายถึงแนวโน้มของแบบจำลองเหล่านี้ที่จะสร้างผลลัพธ์ที่มีอคติอย่างไม่เป็นธรรมต่อเพศหนึ่งมากกว่าอีกเพศหนึ่ง อคตินี้มักเกิดขึ้นจากข้อมูลที่ใช้ในการฝึกฝนแบบจำลองเหล่านี้ ตัวอย่างเช่น แบบจำลองภาษาขนาดใหญ่มักจะกำหนดบทบาทและลักษณะตามบรรทัดฐานทางเพศแบบดั้งเดิม อาจเชื่อมโยงพยาบาลหรือเลขานุการกับผู้หญิงเป็นหลัก และวิศวกรหรือซีอีโอกับผู้ชาย[ 13 ]อีกตัวอย่างหนึ่งคือ การใช้วิธีการที่ขับเคลื่อนด้วยข้อมูลเพื่อระบุอคติทางเพศใน โปรไฟล์ LinkedInการใช้งานระบบที่เปิดใช้งาน ML ที่เพิ่มมากขึ้นได้กลายเป็นองค์ประกอบสำคัญของการสรรหาบุคลากรในยุคปัจจุบัน โดยเฉพาะอย่างยิ่งผ่านเครือข่ายสังคมออนไลน์ เช่น LinkedIn และ Facebook อย่างไรก็ตาม ข้อมูลที่ล้นเกินในระบบการสรรหาบุคลากร ซึ่งอิงตาม วิธี การประมวลผลภาษาธรรมชาติ (NLP) ได้พิสูจน์แล้วว่าส่งผลให้เกิดอคติทางเพศ[ 14 ]
อคติทางการเมือง
อคติทางการเมืองหมายถึงแนวโน้มของอัลกอริทึมที่จะให้ความสำคัญกับมุมมอง อุดมการณ์ หรือผลลัพธ์ทางการเมืองบางอย่างมากกว่าอย่างอื่นอย่างเป็นระบบ โมเดลภาษาก็อาจแสดงอคติทางการเมืองได้เช่นกัน เนื่องจากข้อมูลการฝึกอบรมประกอบด้วยความคิดเห็นและการครอบคลุมทางการเมืองที่หลากหลาย โมเดลอาจสร้างการตอบสนองที่เอนเอียงไปทางอุดมการณ์หรือมุมมองทางการเมืองบางอย่าง ขึ้นอยู่กับความแพร่หลายของมุมมองเหล่านั้นในข้อมูล[ 15 ]
ประเด็นถกเถียง
การใช้การตัดสินใจด้วยอัลกอริทึมในระบบกฎหมายเป็นประเด็นสำคัญที่ถูกตรวจสอบ ในปี 2557 นาย เอริค โฮลเดอร์อัยการสูงสุดของสหรัฐฯ ในขณะนั้น ได้แสดงความกังวลว่าวิธีการ "ประเมินความเสี่ยง" อาจให้ความสำคัญกับปัจจัยที่อยู่นอกเหนือการควบคุมของจำเลยมากเกินไป เช่น ระดับการศึกษาหรือภูมิหลังทางเศรษฐกิจและสังคม[ 16 ]รายงานปี 2559 ของProPublicaเกี่ยวกับCOMPASระบุว่าจำเลยผิวดำมีโอกาสถูกระบุว่ามีความเสี่ยงสูงกว่าจำเลยผิวขาวเกือบสองเท่า ในขณะที่จำเลยผิวขาวกลับถูกระบุความเสี่ยงต่ำกว่า[ 2 ]บริษัท Northepointe Inc. ผู้สร้าง COMPAS ได้โต้แย้งรายงานดังกล่าว โดยอ้างว่าเครื่องมือของพวกเขามีความยุติธรรมและ ProPublica ทำผิดพลาดทางสถิติ[ 17 ]ซึ่งต่อมา ProPublica ก็ได้โต้แย้งอีกครั้ง[ 18 ]
อคติทางเชื้อชาติและเพศยังถูกสังเกตพบในอัลกอริทึมการจดจำภาพ การตรวจจับใบหน้าและการเคลื่อนไหวในกล้องพบว่าละเลยหรือติดป้ายกำกับผิดพลาดต่อการแสดงออกทางสีหน้าของบุคคลที่ไม่ใช่คนผิวขาว[ 19 ]ในปี 2015 Google ได้ขอโทษหลังจากที่Google Photosติดป้ายกำกับคู่รักผิวดำว่าเป็นกอริลลาโดยไม่ได้ตั้งใจ ในทำนองเดียวกันพบว่าฟีเจอร์ติดแท็กอัตโนมัติของ Flickr ติดป้ายกำกับคนผิวดำบางคนว่าเป็น "ลิง" และ "สัตว์" [ 20 ]การประกวดความงามระดับนานาชาติในปี 2016 ที่ตัดสินโดยอัลกอริทึม AIพบว่ามีอคติต่อบุคคลที่มีผิวขาวกว่า ซึ่งอาจเกิดจากอคติในข้อมูลการฝึกอบรม[ 21 ]การศึกษาเกี่ยวกับอัลกอริทึมการจำแนกเพศเชิงพาณิชย์สามรายการในปี 2018 พบว่าอัลกอริทึมทั้งสามโดยทั่วไปมีความแม่นยำที่สุดเมื่อจำแนกผู้ชายผิวขาว และแย่ที่สุดเมื่อจำแนกผู้หญิงผิวคล้ำ[ 22 ]ในปี 2020 พบว่าเครื่องมือตัดภาพจาก Twitter ชอบใบหน้าที่มีผิวขาวกว่า[ 23 ]ในปี 2022 ผู้สร้างโมเดลข้อความเป็นภาพDALL-E 2อธิบายว่าภาพที่สร้างขึ้นนั้นมีลักษณะเหมารวมอย่างมาก โดยอิงจากลักษณะต่างๆ เช่น เพศหรือเชื้อชาติ[ 24 ] [ 25 ]
พื้นที่อื่นๆ ที่มีการใช้อัลกอริธึมการเรียนรู้ของเครื่องซึ่งแสดงให้เห็นว่ามีอคติ ได้แก่ การสมัครงานและการขอสินเชื่อ ตัวอย่างเช่น Amazonใช้ซอฟต์แวร์ตรวจสอบใบสมัครงานที่มีอคติทางเพศ โดยลงโทษเรซูเม่ที่มีคำว่า "ผู้หญิง" [ 26 ]ในปี 2019 อัลกอริธึมของApple ในการกำหนดวงเงินบัตรเครดิตสำหรับ Apple Card ใหม่ ให้วงเงินที่สูงกว่าแก่ผู้ชายมากกว่าผู้หญิงอย่างมีนัยสำคัญ แม้แต่คู่รักที่ใช้เงินร่วมกัน[ 27 ] รายงานของ The Markupในปี 2021 แสดงให้เห็นว่าอัลกอริธึมการอนุมัติสินเชื่อบ้านที่ใช้ในสหรัฐอเมริกามีแนวโน้มที่จะปฏิเสธผู้สมัครที่ไม่ใช่คนผิวขาวมากกว่า[ 28 ]
ข้อจำกัด
งานวิจัยล่าสุดเน้นย้ำถึงข้อจำกัดหลายประการในภาพรวมของความยุติธรรมในการเรียนรู้ของเครื่อง โดยเฉพาะอย่างยิ่งในแง่ของสิ่งที่สามารถบรรลุได้จริงในแอปพลิเคชัน AI ในโลกแห่งความเป็นจริงที่เพิ่มขึ้นเรื่อยๆ[ 29 ] [ 30 ] [ 31 ] ตัวอย่างเช่น แนวทางทางคณิตศาสตร์และเชิงปริมาณในการกำหนดความยุติธรรมอย่างเป็นทางการ และแนวทาง "การลดอคติ" ที่เกี่ยวข้อง อาจอาศัยสมมติฐานที่ง่ายเกินไปและมองข้ามได้ง่าย เช่น การจัดกลุ่มบุคคลออกเป็นกลุ่มทางสังคมที่กำหนดไว้ล่วงหน้า ประเด็นที่ละเอียดอ่อนอื่นๆ ได้แก่ ปฏิสัมพันธ์ระหว่างลักษณะที่รับรู้ได้หลายประการ[ 22 ]และการขาดแนวคิดทางปรัชญาและ/หรือทางกฎหมายที่ชัดเจนและเป็นที่ยอมรับร่วมกันเกี่ยวกับการไม่เลือกปฏิบัติ
ในที่สุด แม้ว่าแบบจำลองการเรียนรู้ของเครื่องจะสามารถออกแบบให้สอดคล้องกับเกณฑ์ความยุติธรรมได้ แต่การตัดสินใจขั้นสุดท้ายที่ทำโดยผู้ปฏิบัติงานที่เป็นมนุษย์อาจยังคงได้รับอิทธิพลจากอคติของตนเอง ปรากฏการณ์นี้เกิดขึ้นเมื่อผู้ตัดสินใจยอมรับคำแนะนำของ AI ก็ต่อเมื่อสอดคล้องกับอคติที่มีอยู่ก่อนแล้วเท่านั้น ซึ่งเป็นการบั่นทอนความยุติธรรมที่ตั้งใจไว้ของระบบ[ 32 ]
เกณฑ์ความเป็นธรรมของกลุ่ม
ใน ปัญหา การจำแนกประเภทอัลกอริทึมจะเรียนรู้ฟังก์ชันเพื่อทำนายลักษณะเฉพาะแบบไม่ต่อเนื่อง ซึ่งก็คือตัวแปรเป้าหมาย จากลักษณะเฉพาะที่ทราบเราสร้างแบบจำลองเป็นตัวแปรสุ่ม แบบไม่ต่อเนื่อง ซึ่งเข้ารหัสลักษณะเฉพาะบางอย่างที่มีอยู่หรือเข้ารหัสโดยนัยซึ่งเราถือว่าเป็นลักษณะเฉพาะที่ละเอียดอ่อน (เพศ เชื้อชาติ รสนิยมทางเพศ ฯลฯ) ในที่สุดเราจะใช้สัญลักษณ์แทนการทำนายของตัวจำแนกประเภทตอนนี้เรามากำหนดเกณฑ์หลักสามข้อเพื่อประเมินว่าตัวจำแนกประเภทที่กำหนดนั้นยุติธรรมหรือไม่ นั่นคือการทำนายของมันไม่ได้รับอิทธิพลจากตัวแปรที่ละเอียดอ่อนเหล่านี้[ 33 ]




เอกราช
เรากล่าวว่าตัวแปรสุ่มเป็นไปตาม หลัก ความเป็นอิสระหากลักษณะที่ละเอียดอ่อนนั้นเป็นอิสระทางสถิติจากการทำนายและเราเขียนว่า เราสามารถแสดงแนวคิดนี้ด้วยสูตรต่อไปนี้ได้เช่นกัน: นี่หมายความว่าอัตราการจำแนกประเภทสำหรับแต่ละคลาสเป้าหมายนั้นเท่ากันสำหรับบุคคลที่อยู่ในกลุ่มต่างๆ กันโดย พิจารณา จากลักษณะที่ละเอียดอ่อน




นอกจากนี้ ยังสามารถแสดงนิยามที่เทียบเท่ากันอีกประการหนึ่งสำหรับความเป็นอิสระได้โดยใช้แนวคิดของข้อมูลร่วมกันระหว่างตัวแปรสุ่มซึ่งกำหนดโดย สูตร ในสูตรนี้คือเอนโทรปีของตัวแปรสุ่มดังนั้นจะมีความเป็นอิสระก็ต่อเมื่อ




การผ่อนปรน นิยามความเป็นอิสระ ที่เป็นไปได้ประการหนึ่ง ได้แก่ การนำค่าส่วนเกิน ที่เป็นบวกมา ใช้ ซึ่งกำหนดโดยสูตรดังนี้:


สุดท้ายนี้ อีกหนึ่งแนวทางผ่อนปรน ที่เป็นไปได้ คือ การกำหนดให้มีข้อกำหนดเพิ่มเติม

การแยกจากกัน
เรากล่าวว่าตัวแปรสุ่มเป็นไปตามหลักการแยกตัว หากลักษณะที่ละเอียดอ่อนนั้นเป็นอิสระทางสถิติจากการทำนายเมื่อกำหนดค่าเป้าหมายและเราเขียนว่า เราสามารถแสดงแนวคิดนี้ด้วยสูตรต่อไปนี้ได้เช่นกัน: นี่หมายความว่าการพึ่งพาของการตัดสินใจต่อคุณลักษณะที่ละเอียดอ่อน ทั้งหมด จะต้องได้รับการพิสูจน์โดยการพึ่งพาที่แท้จริงของตัวแปรเป้าหมายที่แท้จริง





อีกหนึ่งการแสดงออกที่เทียบเท่ากัน ในกรณีของอัตราเป้าหมายแบบไบนารี คือ อัตราผลบวกจริงและอัตราผลบวกเท็จจะเท่ากัน (และดังนั้น อัตราผลลบเท็จและอัตราผลลบจริงจึงเท่ากัน) สำหรับทุกค่าของลักษณะที่ไวต่อการเปลี่ยนแปลง:


แนวทางการผ่อนปรนที่เป็นไปได้สำหรับคำจำกัดความที่กำหนดไว้คือ การอนุญาตให้ค่าความแตกต่างระหว่างอัตราเป็นจำนวนบวกที่ต่ำกว่าค่าความยืดหยุ่นที่กำหนดไว้แทนที่จะเท่ากับศูนย์
ในบางสาขา การแยก (สัมประสิทธิ์การแยก) ในเมทริกซ์ความสับสนคือการวัดระยะห่าง (ที่ระดับคะแนนความน่าจะเป็นที่กำหนด) ระหว่างเปอร์เซ็นต์สะสมเชิงลบที่คาดการณ์ไว้ และ เปอร์เซ็นต์สะสมเชิงบวก ที่คาดการณ์ไว้
ยิ่งค่าสัมประสิทธิ์การแยกนี้มีค่ามากเท่าใด ณ ค่าคะแนนที่กำหนด โมเดลก็จะยิ่งมีประสิทธิภาพในการแยกแยะระหว่างชุดของค่าบวกและค่าลบ ณ จุดตัดความน่าจะเป็นที่เฉพาะเจาะจงมากขึ้นเท่านั้น ตามที่ Mayes กล่าวไว้ว่า: [ 34 ] "ในอุตสาหกรรมสินเชื่อ มักพบว่าการเลือกมาตรวัดการตรวจสอบความถูกต้องขึ้นอยู่กับวิธีการสร้างแบบจำลอง ตัวอย่างเช่น หากขั้นตอนการสร้างแบบจำลองเป็นแบบพาราเมตริกหรือกึ่งพาราเมตริก มักจะใช้ การทดสอบ KS สองตัวอย่างหากแบบจำลองได้มาจากการค้นหาแบบฮิวริสติกหรือแบบวนซ้ำ มาตรวัดประสิทธิภาพของแบบจำลองมักจะเป็น ค่า ความแตกต่างตัวเลือกที่สามคือค่าสัมประสิทธิ์การแยก...เมื่อเปรียบเทียบกับสองวิธีอื่น ค่าสัมประสิทธิ์การแยกดูเหมือนจะเป็นมาตรวัดประสิทธิภาพของแบบจำลองที่สมเหตุสมผลที่สุด เนื่องจากสะท้อนถึงรูปแบบการแยกของแบบจำลอง"
ความเพียงพอ
เรากล่าวว่าตัวแปรสุ่ม นั้น เพียงพอแล้ว หากลักษณะที่ไวต่อการเปลี่ยนแปลงนั้นเป็นอิสระทางสถิติจากค่าเป้าหมายเมื่อพิจารณาจากการทำนายและเราเขียนว่า เราสามารถแสดงแนวคิดนี้ด้วยสูตรต่อไปนี้ได้เช่นกัน: นี่หมายความว่าความน่าจะเป็นที่จะอยู่ในแต่ละกลุ่มนั้นเท่ากันสำหรับบุคคลสองคนที่มีลักษณะที่ไวต่อการเปลี่ยนแปลงแตกต่างกัน เมื่อพิจารณาว่าพวกเขาถูกทำนายว่าอยู่ในกลุ่มเดียวกัน


ความสัมพันธ์ระหว่างคำจำกัดความ
สุดท้ายนี้ เราจะสรุปผลลัพธ์หลักบางประการที่เกี่ยวข้องกับคำจำกัดความทั้งสามที่กล่าวมาข้างต้น:
- สมมติว่าเป็นตัวแปรไบนารี ถ้าและไม่เป็นอิสระทางสถิติ และและ ก็ไม่เป็นอิสระทางสถิติเช่นกัน ดังนั้น ความเป็นอิสระและการแยกออกจากกันจึงไม่สามารถเกิดขึ้นได้พร้อมกัน ยกเว้นในกรณีเชิงวาทศิลป์
- หากการแจกแจงร่วมมีค่าความน่าจะเป็นเป็นบวกสำหรับค่าที่เป็นไปได้ทั้งหมด และไม่ได้เป็นอิสระทางสถิติแล้ว การแยกและการเพียงพอจะไม่สามารถเกิดขึ้นได้พร้อมกัน ยกเว้นในกรณีเชิงวาทศิลป์
เรียกว่าความยุติธรรมโดยสมบูรณ์เมื่อความเป็นอิสระ การแยก และความเพียงพอได้รับการตอบสนองพร้อมกัน[ 35 ]อย่างไรก็ตาม ความยุติธรรมโดยสมบูรณ์นั้นไม่สามารถบรรลุได้ ยกเว้นในกรณีทางวาทศิลป์เฉพาะ[ 36 ]
การกำหนดนิยามความยุติธรรมของกลุ่มด้วยสูตรทางคณิตศาสตร์
คำจำกัดความเบื้องต้น
มาตรการทางสถิติส่วนใหญ่เกี่ยวกับความยุติธรรมอาศัยตัวชี้วัดที่แตกต่างกัน ดังนั้นเราจะเริ่มต้นด้วยการกำหนดตัวชี้วัดเหล่านั้น เมื่อทำงานกับ ตัวจำแนก แบบไบนารีทั้งคลาสที่คาดการณ์และคลาสจริงสามารถมีค่าได้สองค่า คือ บวกและลบ ตอนนี้เรามาเริ่มอธิบายความสัมพันธ์ที่เป็นไปได้ต่างๆ ระหว่างผลลัพธ์ที่คาดการณ์และผลลัพธ์จริงกัน: [ 37 ]

- ผลบวกจริง (TP): กรณีที่ทั้งผลลัพธ์ที่คาดการณ์และผลลัพธ์จริงอยู่ในกลุ่มบวก
- ผลลัพธ์เชิงลบที่แท้จริง (TN): กรณีที่ทั้งผลลัพธ์ที่คาดการณ์และผลลัพธ์ที่เกิดขึ้นจริงถูกจัดอยู่ในกลุ่มลบ
- ผลบวกเท็จ (FP): กรณีที่คาดการณ์ว่าจะอยู่ในกลุ่มผลบวก แต่ผลลัพธ์ที่แท้จริงกลับอยู่ในกลุ่มผลลบ
- ผลลบเท็จ (FN): กรณีที่คาดการณ์ว่าจะอยู่ในกลุ่มลบ แต่ผลลัพธ์ที่แท้จริงกลับอยู่ในกลุ่มบวก
ความสัมพันธ์เหล่านี้สามารถแสดงได้อย่างง่ายดายด้วยเมทริกซ์ความสับสนซึ่งเป็นตารางที่อธิบายความแม่นยำของแบบจำลองการจำแนกประเภท ในเมทริกซ์นี้ คอลัมน์และแถวแสดงถึงกรณีที่คาดการณ์และกรณีจริงตามลำดับ
โดยการใช้ความสัมพันธ์เหล่านี้ เราสามารถกำหนดตัวชี้วัดหลายประการ ซึ่งสามารถนำมาใช้วัดความยุติธรรมของอัลกอริทึมได้ในภายหลัง:
- ค่าทำนายเชิงบวก (PPV): สัดส่วนของกรณีที่เป็นบวกที่ได้รับการทำนายอย่างถูกต้องจากจำนวนการทำนายที่เป็นบวกทั้งหมด โดยทั่วไปเรียกว่าความแม่นยำและแสดงถึงความน่าจะเป็นของการทำนายที่เป็นบวกที่ถูกต้อง คำนวณได้จากสูตรต่อไปนี้:
- อัตราการค้นพบที่ผิดพลาด (FDR): สัดส่วนของการทำนายผลบวกที่ผิดพลาดซึ่งแท้จริงแล้วเป็นผลลบ จากจำนวนการทำนายผลบวกทั้งหมด แสดงถึงความน่าจะเป็นของการทำนายผลบวกที่ผิดพลาด และคำนวณได้จากสูตรต่อไปนี้:
- ค่าทำนายเชิงลบ (NPV): สัดส่วนของกรณีเชิงลบที่ได้รับการทำนายอย่างถูกต้องจากจำนวนการทำนายเชิงลบทั้งหมด ค่านี้แสดงถึงความน่าจะเป็นของการทำนายเชิงลบที่ถูกต้อง และคำนวณได้จากสูตรต่อไปนี้:
- อัตราการพลาดทำนายผิดพลาด (FOR): สัดส่วนของการทำนายเชิงลบที่ผิดพลาดซึ่งจริงๆ แล้วเป็นการทำนายเชิงบวก จากจำนวนการทำนายเชิงลบทั้งหมด แสดงถึงความน่าจะเป็นของการทำนายเชิงลบที่ผิดพลาด และคำนวณได้จากสูตรต่อไปนี้:
- อัตราผลบวกที่แท้จริง (TPR): สัดส่วนของกรณีที่เป็นผลบวกที่ได้รับการคาดการณ์อย่างถูกต้องจากกรณีที่เป็นผลบวกทั้งหมด โดยทั่วไปจะเรียกว่าความไวหรือความจำเพาะ และแสดงถึงความน่าจะเป็นที่ผู้ป่วยที่เป็นผลบวกจะถูกจำแนกอย่างถูกต้องว่าเป็นเช่นนั้น คำนวณได้จากสูตร:
- อัตราผลลบเท็จ (FNR): สัดส่วนของกรณีที่เป็นบวกที่ถูกทำนายผิดว่าเป็นลบ จากกรณีที่เป็นบวกทั้งหมด แสดงถึงความน่าจะเป็นที่ผู้ป่วยที่มีผลเป็นบวกจะถูกจัดประเภทผิดว่าเป็นลบ โดยคำนวณจากสูตร:
- อัตราผลลบที่ถูกต้อง (True negative rate หรือ TNR): สัดส่วนของกรณีที่เป็นผลลบซึ่งได้รับการทำนายอย่างถูกต้องจากกรณีที่เป็นผลลบทั้งหมด แสดงถึงความน่าจะเป็นที่ผู้ป่วยที่มีผลลบจะถูกจำแนกอย่างถูกต้องว่าเป็นเช่นนั้น โดยคำนวณจากสูตร:
- อัตราผลบวกเท็จ (FPR): สัดส่วนของกรณีที่เป็นลบซึ่งถูกทำนายผิดว่าเป็นบวก จากกรณีที่เป็นลบทั้งหมด แสดงถึงความน่าจะเป็นที่ผู้ป่วยที่เป็นลบจะถูกจัดประเภทผิดว่าเป็นบวก โดยคำนวณจากสูตร:








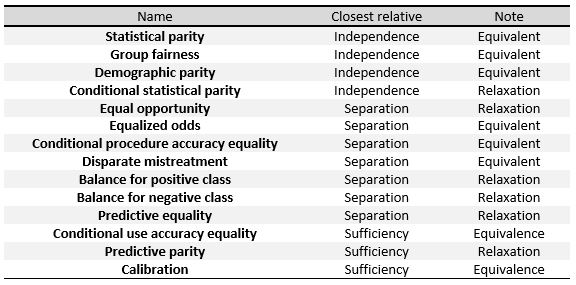
เกณฑ์ต่อไปนี้สามารถเข้าใจได้ว่าเป็นการวัดคำจำกัดความทั่วไปสามประการที่ระบุไว้ในตอนต้นของส่วนนี้ ได้แก่ ความเป็นอิสระ การแยก และความเพียงพอ ในตาราง[ 33 ]ทางด้านขวา เราสามารถเห็นความสัมพันธ์ระหว่างเกณฑ์เหล่านี้ได้
เพื่อกำหนดมาตรการเหล่านี้โดยเฉพาะ เราจะแบ่งมาตรการเหล่านี้ออกเป็นสามกลุ่มใหญ่ตามที่ทำใน Verma et al.: [ 37 ]คำจำกัดความที่อิงตามผลลัพธ์ที่คาดการณ์ไว้ ผลลัพธ์ที่คาดการณ์และผลลัพธ์จริง และคำจำกัดความที่อิงตามความน่าจะเป็นที่คาดการณ์ไว้และผลลัพธ์จริง
เราจะใช้ตัวจำแนกแบบไบนารีและสัญลักษณ์ต่อไปนี้: หมายถึงคะแนนที่ได้จากตัวจำแนก ซึ่งเป็นความน่าจะเป็นที่บุคคลใดบุคคลหนึ่งจะอยู่ในกลุ่มบวกหรือกลุ่มลบแทนการจำแนกขั้นสุดท้ายที่ทำนายโดยอัลกอริทึม และค่าของมันมักจะได้มาจากเช่น จะเป็นบวกเมื่อสูงกว่าเกณฑ์ที่กำหนดแทนผลลัพธ์ที่แท้จริง นั่นคือการจำแนกที่แท้จริงของแต่ละบุคคล และสุดท้ายแสดงถึงคุณลักษณะที่สำคัญของบุคคลนั้น ๆ

คำจำกัดความที่อิงตามผลลัพธ์ที่คาดการณ์ไว้
คำจำกัดความในส่วนนี้มุ่งเน้นไปที่ผลลัพธ์ที่คาดการณ์ไว้สำหรับการกระจายตัวของกลุ่มตัวอย่างต่างๆ ซึ่งเป็นแนวคิดเรื่องความยุติธรรมที่ง่ายที่สุดและเข้าใจง่ายที่สุด
- ความเท่าเทียมทางประชากรศาสตร์หรือที่เรียกว่าความเท่าเทียมทางสถิติ ความเท่าเทียม ของอัตราการยอมรับและการเปรียบเทียบมาตรฐาน ตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างในกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมีโอกาสเท่ากันที่จะถูกจัดให้อยู่ในกลุ่มที่คาดการณ์ไว้ในเชิงบวก กล่าวคือ หากสูตรต่อไปนี้เป็นจริง:
- ความเท่าเทียมทางสถิติแบบมีเงื่อนไขโดยพื้นฐานแล้วประกอบด้วยคำจำกัดความข้างต้น แต่จำกัดเฉพาะกลุ่มย่อยของตัวอย่างเท่านั้น ในสัญลักษณ์ทางคณิตศาสตร์จะเป็นดังนี้:


คำจำกัดความที่อิงตามผลลัพธ์ที่คาดการณ์และผลลัพธ์ที่เกิดขึ้นจริง
คำจำกัดความเหล่านี้ไม่เพียงพิจารณาผลลัพธ์ที่คาดการณ์ไว้เท่านั้นแต่ยังเปรียบเทียบกับผลลัพธ์ที่เกิดขึ้นจริงอีกด้วย
- ความเท่าเทียมกันในการ ทำนาย หรือที่เรียกว่าการทดสอบผลลัพธ์ ตัวจำแนกประเภทจะตรงตาม คำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างในกลุ่มที่ได้รับการปกป้องและกลุ่มที่ไม่ได้รับการปกป้องมีค่า PPV เท่ากัน กล่าวคือ หากสูตรต่อไปนี้เป็นไปตามเงื่อนไข:

- ในทางคณิตศาสตร์ หากตัวจำแนกมีค่า PPV เท่ากันสำหรับทั้งสองกลุ่ม ก็จะมีค่า FDR เท่ากันด้วย ซึ่งสอดคล้องกับสูตร:

- ความสมดุลของอัตราความผิดพลาดบวกเท็จหรือที่เรียกว่าความเท่าเทียมกันในการทำนาย ตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างในกลุ่มที่ได้รับการปกป้องและกลุ่มที่ไม่ได้รับการปกป้องมีอัตราความผิดพลาดบวกเท็จ (FPR) เท่ากัน กล่าวคือ หากสูตรต่อไปนี้เป็นไปตามเงื่อนไข:

- ในทางคณิตศาสตร์ หากตัวจำแนกมีอัตราการเกิดผลบวกเท็จ (FPR) เท่ากันสำหรับทั้งสองกลุ่ม ก็จะมีอัตราการเกิดผลลบเท็จ (TNR) เท่ากันด้วย ซึ่งสอดคล้องกับสูตร:

- ความสมดุลของอัตราความผิดพลาดเชิงลบเท็จหรือที่เรียกว่าโอกาสที่เท่าเทียมกันตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างในกลุ่มที่ได้รับการปกป้องและกลุ่มที่ไม่ได้รับการปกป้องมีอัตราความผิดพลาดเชิงลบเท็จ (FNR) เท่ากัน กล่าวคือ หากเป็นไปตามสูตรต่อไปนี้:

- ในทางคณิตศาสตร์ หากตัวจำแนกมี FNR เท่ากันสำหรับทั้งสองกลุ่ม ก็จะมีค่า TPR เท่ากันด้วย ซึ่งสอดคล้องกับสูตร:

- อัตราส่วนความน่าจะเป็นที่เท่าเทียมกันหรือเรียกอีกอย่างว่าความแม่นยำของกระบวนการแบบมีเงื่อนไข ความเท่าเทียม กัน และการปฏิบัติที่ไม่เป็นธรรมที่ไม่เท่าเทียมกันตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อผู้ถูกทดสอบในกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมี TPR และ FPR เท่ากัน โดยเป็นไปตามสูตร:
- ความเท่าเทียมกันของความแม่นยำในการใช้งานแบบมีเงื่อนไขตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างในกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมีค่า PPV และ NPV เท่ากัน โดยเป็นไปตามสูตร:
- ความเท่าเทียมกันของความแม่นยำโดยรวมตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อหัวข้อในกลุ่มที่ได้รับการปกป้องและกลุ่มที่ไม่ได้รับการปกป้องมีความแม่นยำในการทำนายเท่ากัน กล่าวคือ ความน่าจะเป็นที่หัวข้อจากคลาสหนึ่งจะถูกกำหนดให้เป็นคลาสนั้นเท่ากัน นั่นคือ หากเป็นไปตามสูตรต่อไปนี้:
- ความเท่าเทียมในการปฏิบัติตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมีอัตราส่วนของ FN และ FP เท่ากัน โดยเป็นไปตามสูตร:




คำจำกัดความที่อิงตามความน่าจะเป็นที่คาดการณ์ไว้และผลลัพธ์ที่เกิดขึ้นจริง
คำจำกัดความเหล่านี้อิงตามผลลัพธ์ที่เกิดขึ้นจริงและคะแนนความน่าจะเป็นที่คาดการณ์ไว้
- ความเป็นธรรมในการทดสอบหรือที่เรียกว่าการปรับเทียบหรือการจับคู่ความถี่ตามเงื่อนไข ตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ หากบุคคลที่มีคะแนนความน่าจะเป็นที่คาดการณ์ไว้เท่ากันมีความน่าจะเป็นที่จะถูกจัดอยู่ในกลุ่มบวกเท่ากัน ไม่ว่าพวกเขาจะอยู่ในกลุ่มที่ได้รับการคุ้มครองหรือกลุ่มที่ไม่ได้รับการคุ้มครองก็ตาม:
- การปรับเทียบที่ดีเป็นส่วนขยายของคำจำกัดความก่อนหน้านี้ โดยระบุว่าเมื่อบุคคลภายในหรือภายนอกกลุ่มที่ได้รับการคุ้มครองมีคะแนนความน่าจะเป็นที่คาดการณ์ไว้เท่ากัน พวกเขาจะต้องมีความน่าจะเป็นที่จะถูกจัดอยู่ในกลุ่มบวกเท่ากัน และความน่าจะเป็นนี้จะต้องเท่ากับ:
- ความสมดุลสำหรับกลุ่มที่มีผลลัพธ์เป็นบวกตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างที่ประกอบกันเป็นกลุ่มที่มีผลลัพธ์เป็นบวกจากทั้งกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมีคะแนนความน่าจะเป็นที่คาดการณ์เฉลี่ยเท่ากันซึ่งหมายความว่าค่าที่คาดหวังของคะแนนความน่าจะเป็นสำหรับกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองที่มีผลลัพธ์จริงเป็นบวกนั้นเท่ากัน โดยเป็นไปตามสูตร:
- ความสมดุลสำหรับกลุ่มผลลัพธ์เชิงลบตัวจำแนกประเภทจะตรงตามคำจำกัดความนี้ได้ก็ต่อเมื่อกลุ่มตัวอย่างที่ประกอบกันเป็นกลุ่มผลลัพธ์เชิงลบจากทั้งกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองมีคะแนนความน่าจะเป็นที่คาดการณ์เฉลี่ยเท่ากันซึ่งหมายความว่าค่าที่คาดหวังของคะแนนความน่าจะเป็นสำหรับกลุ่มที่ได้รับการคุ้มครองและกลุ่มที่ไม่ได้รับการคุ้มครองที่มีผลลัพธ์จริงเป็นลบนั้นเท่ากัน โดยเป็นไปตามสูตร:




ความสับสนที่เท่าเทียมกัน ความยุติธรรม
ในส่วนของเมทริกซ์ความสับสน ความเป็นอิสระ การแยก และความเพียงพอ กำหนดให้ปริมาณที่เกี่ยวข้องที่ระบุไว้ด้านล่างไม่มีความแตกต่างทางสถิติอย่างมีนัยสำคัญในลักษณะที่ละเอียดอ่อน[ 36 ]
- ความเป็นอิสระ: (TP + FP) / (TP + FP + FN + TN) (เช่น)
- การแยกแยะ: TN / (TN + FP) และ TP / (TP + FN) (เช่น ความจำเพาะและการเรียกคืนข้อมูล)
- ความเพียงพอ: TP / (TP + FP) และ TN / (TN + FN) (เช่น ความแม่นยำและค่าทำนายเชิงลบ )





แนวคิดเรื่องความยุติธรรมของความสับสนที่เท่าเทียมกัน[ 38 ]กำหนดให้เมทริกซ์ความสับสนของระบบการตัดสินใจที่กำหนดต้องมีการกระจายแบบเดียวกันเมื่อคำนวณแบบแบ่งชั้นตามลักษณะที่ละเอียดอ่อนทั้งหมด
หน้าที่ด้านสวัสดิการสังคม
นักวิชาการบางคนเสนอให้กำหนดความยุติธรรมของอัลกอริทึมในแง่ของฟังก์ชันสวัสดิการสังคมพวกเขาโต้แย้งว่าการใช้ฟังก์ชันสวัสดิการสังคมช่วยให้นักออกแบบอัลกอริทึมสามารถพิจารณาความยุติธรรมและความแม่นยำในการคาดการณ์ในแง่ของผลประโยชน์ต่อผู้คนที่ได้รับผลกระทบจากอัลกอริทึม นอกจากนี้ยังช่วยให้นักออกแบบสามารถแลกเปลี่ยนประสิทธิภาพและความเท่าเทียมกันในลักษณะที่มีหลักการ[ 39 ] Sendhil Mullainathanกล่าวว่านักออกแบบอัลกอริทึมควรใช้ฟังก์ชันสวัสดิการสังคมเพื่อรับรู้ถึงผลประโยชน์ที่แท้จริงสำหรับกลุ่มที่ด้อยโอกาส ตัวอย่างเช่น การศึกษาพบว่าการใช้อัลกอริทึมการตัดสินใจในการควบคุมตัวก่อนการพิจารณาคดีแทนการตัดสินของมนุษย์ล้วนๆ ช่วยลดอัตราการควบคุมตัวสำหรับคนผิวดำ ชาวฮิสแปนิก และชนกลุ่มน้อยทางเชื้อชาติโดยรวม แม้ว่าอัตราการก่ออาชญากรรมจะคงที่ก็ตาม[ 40 ]
เกณฑ์ความยุติธรรมเฉพาะบุคคล
ความแตกต่างที่สำคัญระหว่างคำจำกัดความของความยุติธรรมคือความแตกต่างระหว่างแนวคิดของกลุ่มและบุคคล[ 41 ] [ 42 ] [ 37 ] [ 43 ]โดยคร่าวๆ แล้ว เกณฑ์ความยุติธรรมของกลุ่มจะเปรียบเทียบปริมาณในระดับกลุ่ม ซึ่งโดยทั่วไปจะระบุโดยคุณลักษณะที่ละเอียดอ่อน (เช่น เพศ เชื้อชาติ อายุ ฯลฯ) ในขณะที่เกณฑ์ของบุคคลจะเปรียบเทียบระหว่างบุคคล กล่าวคือ ความยุติธรรมของบุคคลยึดหลักการที่ว่า "บุคคลที่คล้ายคลึงกันควรได้รับการปฏิบัติที่คล้ายคลึงกัน"
มีแนวทางที่เข้าใจง่ายอย่างหนึ่งเกี่ยวกับความยุติธรรม ซึ่งมักเรียกกันว่าความยุติธรรมผ่านการไม่รู้ตัว ( FTU ) หรือการมองข้ามซึ่งกำหนดไว้ว่าไม่ควรนำคุณลักษณะที่ละเอียดอ่อนมาใช้โดยตรงเมื่อทำการตัดสินใจ (โดยอัตโนมัติ) นี่เป็นแนวคิดเรื่องความยุติธรรมส่วนบุคคลอย่างแท้จริง เพราะบุคคลสองคนที่แตกต่างกันเพียงแค่คุณค่าของคุณลักษณะที่ละเอียดอ่อนก็จะได้รับผลลัพธ์เดียวกัน
อย่างไรก็ตาม โดยทั่วไปแล้ว FTU มีข้อเสียหลายประการ ข้อเสียหลักคือไม่ได้คำนึงถึงความสัมพันธ์ที่เป็นไปได้ระหว่างคุณลักษณะที่ละเอียดอ่อนและคุณลักษณะที่ไม่ละเอียดอ่อนที่ใช้ในกระบวนการตัดสินใจ ตัวอย่างเช่น ตัวแทนที่มีเจตนาร้ายที่จะเลือกปฏิบัติบนพื้นฐานของเพศ อาจนำตัวแปรแทนเพศ (เช่น ตัวแปรที่มีความสัมพันธ์สูงกับเพศ) มาใช้ในแบบจำลอง และใช้ข้อมูลเพศได้อย่างมีประสิทธิภาพในขณะเดียวกันก็ปฏิบัติตามข้อกำหนดของ FTU ได้
ปัญหาเกี่ยวกับตัวแปรที่สัมพันธ์กับตัวแปรที่ละเอียดอ่อนซึ่งสามารถนำมาใช้ในแบบจำลองเพื่อการตัดสินใจได้อย่างเหมาะสมนั้นเป็นปัญหาสำคัญ และมีความเกี่ยวข้องกับแนวคิดกลุ่มด้วยเช่นกัน: ตัวชี้วัดความเป็นอิสระจำเป็นต้องกำจัดข้อมูลที่ละเอียดอ่อนออกไปอย่างสมบูรณ์ ในขณะที่ตัวชี้วัดแบบแยกส่วนอนุญาตให้มีความสัมพันธ์ได้ แต่เฉพาะในขอบเขตที่ตัวแปรเป้าหมายที่ระบุไว้ "เหมาะสม" เท่านั้น
แนวคิดทั่วไปที่สุดของความยุติธรรมส่วนบุคคลได้รับการนำเสนอในงานบุกเบิกโดยCynthia Dworkและผู้ร่วมงานในปี 2012 [ 44 ]และสามารถคิดได้ว่าเป็นการแปลทางคณิตศาสตร์ของหลักการที่ว่าแผนที่การตัดสินใจที่รับคุณลักษณะเป็นอินพุตควรสร้างขึ้นเพื่อให้สามารถ "แมปบุคคลที่คล้ายคลึงกันในลักษณะเดียวกัน" ซึ่งแสดงเป็นเงื่อนไข Lipschitzบนแผนที่แบบจำลอง พวกเขาเรียกวิธีการนี้ว่าความยุติธรรมผ่านการรับรู้ ( FTA ) อย่างแม่นยำเพื่อเป็นจุดตรงข้ามกับ FTU เนื่องจากพวกเขาเน้นย้ำถึงความสำคัญของการเลือกเมตริกระยะทางที่เกี่ยวข้องกับเป้าหมายที่เหมาะสมเพื่อประเมินว่าบุคคลใดมีความคล้ายคลึงกันในสถานการณ์เฉพาะ อีกครั้ง ปัญหานี้มีความเกี่ยวข้องอย่างมากกับประเด็นที่ยกขึ้นข้างต้นเกี่ยวกับตัวแปรใดที่สามารถมองว่า "ถูกต้องตามกฎหมาย" ในบริบทเฉพาะ
แนวทางอื่นสำหรับความยุติธรรมของแต่ละบุคคลคือความยุติธรรมเชิงสมมติ[ 4 ]แนวคิดเบื้องหลังความยุติธรรมเชิงสมมติคือการตัดสินใจจะยุติธรรมต่อบุคคลก็ต่อเมื่อการตัดสินใจนั้นเหมือนกันทั้งในโลกแห่งความเป็นจริงและโลกสมมติที่บุคคลนั้นอยู่ในกลุ่มประชากรที่แตกต่างกัน[ 45 ]
ตัวชี้วัดตามหลักเหตุและผล
ความเป็นธรรมเชิงสาเหตุวัดความถี่ที่ผู้ใช้หรือแอปพลิเคชันสองรายที่เกือบจะเหมือนกันซึ่งแตกต่างกันเฉพาะในชุดลักษณะที่ต้องจัดสรรทรัพยากรอย่างเป็นธรรมได้รับการปฏิบัติอย่างเท่าเทียมกัน[ 46 ]
สาขาการวิจัยเชิงวิชาการทั้งหมดเกี่ยวกับเมตริกความยุติธรรมทุ่มเทให้กับการใช้แบบจำลองเชิงสาเหตุเพื่อประเมินอคติใน แบบจำลอง การเรียนรู้ของเครื่องแนวทางนี้มักได้รับการพิสูจน์โดยข้อเท็จจริงที่ว่าการกระจายข้อมูลการสังเกตเดียวกันอาจซ่อนความสัมพันธ์เชิงสาเหตุที่แตกต่างกันระหว่างตัวแปรที่เกี่ยวข้อง ซึ่งอาจมีการตีความที่แตกต่างกันว่าผลลัพธ์ได้รับผลกระทบจากอคติบางรูปแบบหรือไม่[ 33 ]
Kusner et al. [ 45 ]เสนอให้ใช้สถานการณ์สมมติและกำหนดกระบวนการตัดสินใจที่ยุติธรรมตามสถานการณ์สมมติหากผลลัพธ์ไม่เปลี่ยนแปลงสำหรับบุคคลใดๆ ในสถานการณ์สมมติที่คุณลักษณะที่ละเอียดอ่อนมีการเปลี่ยนแปลง โปรดทราบว่าสิ่งนี้ยังจัดอยู่ในหมวดหมู่ของการวัดความยุติธรรมของแต่ละบุคคลด้วย สูตรทางคณิตศาสตร์มีดังนี้:

กล่าวคือ: สุ่มเลือกบุคคลหนึ่งคนที่มีคุณลักษณะที่ละเอียดอ่อนและคุณสมบัติอื่นๆและบุคคลเดียวกันนั้น หากเธอมี คุณลักษณะอื่น โอกาสที่พวกเขาจะได้รับการยอมรับควรเท่ากัน สัญลักษณ์แทนตัวแปรสุ่มเชิงสมมติในสถานการณ์ที่คุณลักษณะที่ละเอียดอ่อนถูกกำหนดให้คงที่เงื่อนไขบนหมายความว่าข้อกำหนดนี้อยู่ในระดับบุคคล กล่าวคือเรากำลังพิจารณาเงื่อนไขจากตัวแปรทั้งหมดที่ระบุการสังเกตเพียงครั้งเดียว





แบบจำลองการเรียนรู้ของเครื่องมักได้รับการฝึกฝนจากข้อมูลที่ผลลัพธ์ขึ้นอยู่กับการตัดสินใจที่เกิดขึ้นในขณะนั้น[ 47 ]ตัวอย่างเช่น หากแบบจำลองการเรียนรู้ของเครื่องต้องพิจารณาว่าผู้ต้องขังจะกระทำผิดซ้ำหรือไม่ และจะพิจารณาว่าควรปล่อยตัวผู้ต้องขังก่อนกำหนดหรือไม่ ผลลัพธ์อาจขึ้นอยู่กับว่าผู้ต้องขังได้รับการปล่อยตัวก่อนกำหนดหรือไม่ Mishler et al. [ 48 ]เสนอสูตรสำหรับอัตราต่อรองที่เท่ากันแบบสมมติ:

โดยที่เป็นตัวแปรสุ่มแสดงถึงผลลัพธ์เมื่อมีการตัดสินใจ และเป็นคุณลักษณะที่ละเอียดอ่อน


Plecko และ Bareinboim [ 49 ]เสนอกรอบการทำงานที่เป็นเอกภาพเพื่อจัดการกับการวิเคราะห์เชิงสาเหตุของความยุติธรรม พวกเขาแนะนำให้ใช้แบบจำลองความยุติธรรมมาตรฐาน ซึ่งประกอบด้วยกราฟเชิงสาเหตุที่มีตัวแปร 4 ประเภท:
- คุณลักษณะที่ละเอียดอ่อน ( )
- ตัวแปรเป้าหมาย ( ),
- ตัวกลาง ( ) ระหว่างและซึ่งแสดงถึงผลกระทบทางอ้อมที่ เป็นไปได้ ของคุณลักษณะที่ละเอียดอ่อนต่อผลลัพธ์
- ตัวแปรที่อาจมีสาเหตุ ร่วมกัน กับ( ) ซึ่งแสดงถึง ผลกระทบ ที่ไม่แท้จริง (เช่น ไม่ใช่สาเหตุ) ของคุณลักษณะที่ละเอียดอ่อนต่อผลลัพธ์


ภายในกรอบนี้ Plecko และ Bareinboim [ 49 ]จึงสามารถจำแนกผลกระทบที่เป็นไปได้ที่คุณลักษณะที่ละเอียดอ่อนอาจมีต่อผลลัพธ์ได้ ยิ่งไปกว่านั้น ความละเอียดในการวัดผลกระทบเหล่านี้—กล่าวคือ ตัวแปรเงื่อนไขที่ใช้ในการหาค่าเฉลี่ยของผลกระทบ—เชื่อมโยงโดยตรงกับแง่มุม "รายบุคคลเทียบกับกลุ่ม" ของการประเมินความยุติธรรม
กลยุทธ์การลดอคติ
ความเป็นธรรมสามารถนำมาประยุกต์ใช้กับอัลกอริธึมการเรียนรู้ของเครื่องได้สามวิธี ได้แก่การประมวลผลข้อมูลเบื้องต้นการเพิ่มประสิทธิภาพระหว่างการฝึกซอฟต์แวร์ หรือการประมวลผลผลลัพธ์หลังการทำงานของอัลกอริธึม
การประมวลผลล่วงหน้า
โดยปกติแล้ว ปัญหาไม่ได้อยู่ที่ตัวจำแนกเพียงอย่างเดียวชุดข้อมูลก็อาจมีความลำเอียงด้วยเช่นกัน การจำแนกชุดข้อมูลตามกลุ่มสามารถกำหนดได้ดังนี้:



กล่าวคือ เป็นค่าประมาณของความแตกต่างระหว่างความน่าจะเป็นของการอยู่ในกลุ่มบวก โดยที่บุคคลนั้นมีลักษณะที่ได้รับการคุ้มครองซึ่งแตกต่างจากและ เท่ากับ

อัลกอริทึมที่แก้ไขความลำเอียงในขั้นตอนการประมวลผลเบื้องต้นจะลบข้อมูลเกี่ยวกับตัวแปรในชุดข้อมูลที่อาจส่งผลให้เกิดการตัดสินใจที่ไม่เป็นธรรม โดยพยายามเปลี่ยนแปลงให้น้อยที่สุดเท่าที่จะเป็นไปได้ นี่ไม่ใช่เรื่องง่ายเพียงแค่ลบตัวแปรที่ละเอียดอ่อนออกไป เพราะคุณลักษณะอื่นๆ อาจมีความสัมพันธ์กับตัวแปรที่ได้รับการปกป้องอยู่
วิธีหนึ่งในการทำเช่นนี้คือ การแปลงข้อมูลของแต่ละบุคคลในชุดข้อมูลเริ่มต้นไปเป็นข้อมูลระดับกลาง ซึ่งทำให้ไม่สามารถระบุได้ว่าบุคคลนั้นอยู่ในกลุ่มที่ได้รับการคุ้มครองกลุ่มใด ในขณะเดียวกันก็ยังคงรักษาข้อมูลหลักไว้ให้มากที่สุด จากนั้นจึงปรับข้อมูลรูปแบบใหม่นี้เพื่อให้ได้ความแม่นยำสูงสุดในอัลกอริทึม
ด้วยวิธีนี้ บุคคลแต่ละคนจะถูกแปลงเป็นรูปแบบการแสดงผลแบบหลายตัวแปรใหม่ โดยที่ความน่าจะเป็นที่สมาชิกคนใดคนหนึ่งในกลุ่มที่ได้รับการคุ้มครองจะถูกแปลงเป็นค่าใดค่าหนึ่งในรูปแบบการแสดงผลใหม่นั้น จะเท่ากับความน่าจะเป็นของบุคคลที่ไม่ใช่สมาชิกของกลุ่มที่ได้รับการคุ้มครอง จากนั้น รูปแบบการแสดงผลนี้จะถูกนำมาใช้เพื่อทำนายผลสำหรับบุคคลนั้น แทนที่จะใช้ข้อมูลเริ่มต้น เนื่องจากรูปแบบการแสดงผลระดับกลางที่สร้างขึ้นนั้นให้ความน่าจะเป็นเท่ากันแก่บุคคลทั้งภายในและภายนอกกลุ่มที่ได้รับการคุ้มครอง คุณลักษณะนี้จึงถูกซ่อนไว้จากตัวจำแนกประเภท
ตัวอย่างหนึ่งได้รับการอธิบายใน Zemel et al. [ 50 ]ซึ่งตัวแปรสุ่มแบบหลายนามถูกใช้เป็นตัวแทนระดับกลาง ในกระบวนการนี้ ระบบได้รับการสนับสนุนให้รักษาข้อมูลทั้งหมด ยกเว้นข้อมูลที่อาจนำไปสู่การตัดสินใจที่ลำเอียง และเพื่อให้ได้การคาดการณ์ที่แม่นยำที่สุดเท่าที่จะเป็นไปได้
ในด้านหนึ่ง วิธีการนี้มีข้อดีคือข้อมูลที่ผ่านการประมวลผลล่วงหน้าสามารถนำไปใช้กับงานเรียนรู้ของเครื่องใดๆ ก็ได้ นอกจากนี้ ตัวจำแนกไม่จำเป็นต้องได้รับการแก้ไข เนื่องจากมีการปรับแก้ชุดข้อมูลก่อนการประมวลผลแล้ว ในอีกด้านหนึ่ง วิธีการอื่นๆ ให้ผลลัพธ์ที่ดีกว่าในด้านความแม่นยำและความเป็นธรรม
การชั่งน้ำหนักใหม่
การชั่งน้ำหนักใหม่เป็นตัวอย่างของอัลกอริธึมการประมวลผลล่วงหน้า แนวคิดคือการกำหนดน้ำหนักให้กับจุดข้อมูลแต่ละจุดเพื่อให้การจำแนกน้ำหนักเป็น 0 เมื่อเทียบกับกลุ่มที่กำหนด[ 51 ]
หากชุดข้อมูลไม่มีอคติ ตัวแปรที่ไวต่อการเปลี่ยนแปลงและตัวแปรเป้าหมายจะเป็นอิสระต่อกันทางสถิติและความน่าจะเป็นของการแจกแจงร่วมจะเป็นผลคูณของความน่าจะเป็นดังต่อไปนี้:

แต่ในความเป็นจริง ชุดข้อมูลนั้นไม่ได้ปราศจากอคติ และตัวแปรต่างๆ ก็ไม่ได้เป็นอิสระทางสถิติ ดังนั้นความน่าจะเป็นที่สังเกตได้จึงเป็นดังนี้:

เพื่อชดเชยความลำเอียง ซอฟต์แวร์จะเพิ่มค่าน้ำหนัก โดยให้ค่าน้ำหนัก น้อยกว่าสำหรับวัตถุที่ชื่นชอบ และให้ค่าน้ำหนักมากกว่าสำหรับวัตถุที่ไม่ชื่นชอบ สำหรับแต่ละกรณีเราจะได้ผลลัพธ์ดังนี้:


เมื่อเรากำหนดค่าน้ำหนักให้กับแต่ละกลุ่มแล้วเราจะคำนวณค่าการจำแนกแบบถ่วงน้ำหนักโดยสัมพันธ์กับกลุ่มดังนี้:


สามารถแสดงได้ว่าหลังจากปรับน้ำหนักใหม่แล้ว ค่าการจำแนกแบบถ่วงน้ำหนักนี้จะเป็น 0
กระบวนการเข้า
แนวทางอื่นคือการแก้ไขอคติในระหว่างการฝึกอบรม ซึ่งสามารถทำได้โดยการเพิ่มข้อจำกัดให้กับวัตถุประสงค์การปรับให้เหมาะสมของอัลกอริทึม[ 52 ]ข้อจำกัดเหล่านี้บังคับให้อัลกอริทึมปรับปรุงความยุติธรรมโดยการรักษาอัตราเดียวกันของมาตรการบางอย่างสำหรับกลุ่มที่ได้รับการคุ้มครองและบุคคลอื่น ๆ ตัวอย่างเช่น เราสามารถเพิ่มเงื่อนไขให้กับวัตถุประสงค์ของอัลกอริทึมว่าอัตราการเกิดผลบวกเท็จจะต้องเท่ากันสำหรับบุคคลในกลุ่มที่ได้รับการคุ้มครองและบุคคลภายนอกกลุ่มที่ได้รับการคุ้มครอง
มาตรการหลักที่ใช้ในแนวทางนี้ ได้แก่ อัตราผลบวกเท็จ อัตราผลลบเท็จ และอัตราการจำแนกผิดโดยรวม สามารถเพิ่มข้อจำกัดเหล่านี้เพียงหนึ่งข้อหรือหลายข้อลงในเป้าหมายของอัลกอริทึมได้ โปรดทราบว่า ความเท่าเทียมกันของอัตราผลลบเท็จหมายถึงความเท่าเทียมกันของอัตราผลบวกจริง ดังนั้นจึงหมายถึงความเท่าเทียมกันของโอกาส หลังจากเพิ่มข้อจำกัดลงในปัญหาแล้ว ปัญหาอาจแก้ไขได้ยาก ดังนั้นอาจจำเป็นต้องผ่อนปรนข้อจำกัดเหล่านั้น
การลดอคติแบบต่อต้าน
เราฝึกตัวจำแนก สองตัว พร้อมกันโดยใช้วิธีการไล่ระดับ (เช่นการไล่ระดับแบบลดระดับ ) ตัวแรกคือตัวทำนายพยายามที่จะทำนายตัวแปรเป้าหมาย โดยกำหนดอินพุต โดยการปรับน้ำหนักเพื่อลดฟังก์ชันการสูญเสีย บาง อย่าง ตัวที่สองคือตัวโจมตีพยายามที่จะทำนายตัวแปรที่ไวต่อการเปลี่ยนแปลง โดยกำหนดอินพุต โดยการปรับน้ำหนักเพื่อลดฟังก์ชันการสูญเสียบางอย่าง[ 53 ] จุด สำคัญในที่นี้คือ เพื่อให้การแพร่กระจายถูกต้องข้างต้นต้องอ้างอิงถึงเอาต์พุตดิบของตัวจำแนก ไม่ใช่การทำนายแบบไม่ต่อเนื่อง ตัวอย่างเช่น สำหรับโครง ข่ายประสาทเทียมและปัญหาการจำแนกประเภทอาจอ้างอิงถึงเอาต์พุตของเลเยอร์ softmax





จากนั้นเราจะอัปเดตเพื่อลดค่าให้น้อยที่สุดในแต่ละขั้นตอนการฝึกอบรมตามเกรเดียนต์และเราจะปรับเปลี่ยนตามนิพจน์: โดยที่เป็นไฮเปอร์พารามิเตอร์ ที่ปรับได้ ซึ่งสามารถเปลี่ยนแปลงได้ในแต่ละช่วงเวลา




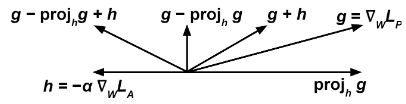
แนวคิดโดยสัญชาตญาณคือ เราต้องการให้ตัวทำนายพยายามลดค่า(ดังนั้นจึงใช้เทอม) ให้เหลือน้อยที่สุด ในขณะเดียวกันก็เพิ่มค่า(ดังนั้นจึงใช้เทอม) ให้มากที่สุด เพื่อให้ฝ่ายตรงข้ามไม่สามารถทำนายตัวแปรที่สำคัญจาก ได้



เงื่อนไขนี้ป้องกันไม่ให้ตัวทำนายเคลื่อนที่ไปในทิศทางที่ช่วยให้ฝ่ายตรงข้ามลดฟังก์ชันความสูญเสียลงได้

สามารถแสดงให้เห็นได้ว่า การฝึกโมเดล การจำแนกประเภท ตัวทำนายด้วยอัลกอริธึมนี้ ช่วยปรับปรุงความเท่าเทียมกันทางด้านประชากรศาสตร์เมื่อเทียบกับการฝึกโมเดลโดยไม่มีตัว ร้าย
การประมวลผลภายหลัง
วิธีสุดท้ายพยายามแก้ไขผลลัพธ์ของตัวจำแนกเพื่อให้เกิดความเป็นธรรม ในวิธีนี้ เรามีตัวจำแนกที่ให้คะแนนแก่แต่ละบุคคล และเราจำเป็นต้องทำนายผลแบบไบนารีสำหรับพวกเขา คะแนนสูงมีแนวโน้มที่จะได้ผลลัพธ์ที่เป็นบวก ในขณะที่คะแนนต่ำมีแนวโน้มที่จะได้ผลลัพธ์ที่เป็นลบ แต่เราสามารถปรับค่าเกณฑ์เพื่อกำหนดว่าจะตอบว่าใช่เมื่อใดตามที่ต้องการ โปรดทราบว่าการเปลี่ยนแปลงในค่าเกณฑ์จะส่งผลต่อความสมดุลระหว่างอัตราผลบวกที่แท้จริงและผลลบที่แท้จริง
หากฟังก์ชันคะแนนมีความเป็นธรรมในแง่ที่ว่าเป็นอิสระจากคุณลักษณะที่ได้รับการคุ้มครอง การเลือกเกณฑ์ใดๆ ก็จะมีความเป็นธรรมเช่นกัน แต่ตัวจำแนกประเภทนี้มักมีอคติ ดังนั้นอาจต้องใช้เกณฑ์ที่แตกต่างกันสำหรับแต่ละกลุ่มที่ได้รับการคุ้มครองเพื่อให้เกิดความเป็นธรรม[ 54 ]วิธีหนึ่งในการทำเช่นนี้คือการพล็อตอัตราการตรวจพบที่ถูกต้องเทียบกับอัตราการตรวจพบที่ผิดพลาดที่การตั้งค่าเกณฑ์ต่างๆ (เรียกว่าเส้นโค้ง ROC ) และหาเกณฑ์ที่อัตราสำหรับกลุ่มที่ได้รับการคุ้มครองและบุคคลอื่นๆ เท่ากัน[ 54 ]
การปฏิเสธการจำแนกประเภทตามตัวเลือก
เมื่อกำหนดตัวจำแนกแล้ว ให้เป็นความน่าจะเป็นที่คำนวณโดยตัวจำแนกเป็นความน่าจะเป็นที่อินสแตนซ์เป็นของคลาสบวก + เมื่อมีค่าใกล้เคียงกับ 1 หรือ 0 อินสแตนซ์จะถูกระบุด้วยความแน่นอนสูงว่าเป็นของคลาส + หรือ – ตามลำดับ อย่างไรก็ตาม เมื่อมีค่าใกล้เคียงกับ 0.5 การจำแนกประเภทจะไม่ชัดเจนมากขึ้น[ 55 ]

เรากล่าวว่าเป็น "กรณีที่ถูกปฏิเสธ" หากมีค่าบางอย่างที่ทำให้



อัลกอริทึมของ "ROC" ประกอบด้วยการจำแนกอินสแตนซ์ที่ไม่ถูกปฏิเสธตามกฎข้างต้น และอินสแตนซ์ที่ถูกปฏิเสธดังนี้: หากอินสแตนซ์เป็นตัวอย่างของกลุ่มที่ด้อยโอกาส ( ) ให้ติดป้ายกำกับว่าเป็นบวก มิเช่นนั้นให้ติดป้ายกำกับว่าเป็นลบ

เราสามารถปรับมาตรการการเลือกปฏิบัติที่แตกต่างกัน (ลิงก์) ให้เป็นฟังก์ชันของเพื่อค้นหาค่าที่เหมาะสมที่สุดสำหรับแต่ละปัญหา และหลีกเลี่ยงการเลือกปฏิบัติกับกลุ่มที่มีสิทธิพิเศษ[ 55 ]