อ่าน 5 นาที
อัลกอริทึมโลภ
อั ลกอริทึมแบบโลภ (greedy algorithm) คือ อัลกอริทึม ที่ในแต่ละขั้นตอนจะเลือกสิ่งที่ดีที่สุดในระดับท้องถิ่น และหลังจากนั้นจะไม่พิจารณาตัวเลือกในอดีตอีก...
อัลกอริทึมโลภ
อัลกอริทึมแบบโลภ (greedy algorithm)คืออัลกอริทึมที่ในแต่ละขั้นตอนจะเลือกสิ่งที่ดีที่สุดในระดับท้องถิ่น และหลังจากนั้นจะไม่พิจารณาตัวเลือกในอดีตอีก อัลกอริทึมแบบโลภมักใช้ในการแก้ ปัญหา การเพิ่มประสิทธิภาพเชิงการจัดเรียงหากปัญหาการเพิ่มประสิทธิภาพขึ้นอยู่กับวิธีแก้ปัญหาเพียงบางส่วนของการแก้ปัญหาย่อยหนึ่งปัญหา เราสามารถแก้ปัญหานี้ได้โดยการพิจารณาเฉพาะปัญหาย่อยที่ดีที่สุดในระดับท้องถิ่นแบบ "โลภ" ในแง่นี้ อัลกอริทึมแบบโลภจึงเป็นกรณีพิเศษของอัลกอริทึมการเขียนโปรแกรมแบบไดนามิกUriel Feige [ 1 ]ตั้งข้อสังเกตว่า:
[อัลกอริทึมแบบโลภ] อาจมองได้ว่าเป็นรูปแบบขั้นสูงสุดของการเขียนโปรแกรมเชิงพลวัต ซึ่งจะคงไว้เพียงวิธีแก้ปัญหาบางส่วนเพียงวิธีเดียวเท่านั้น ปัญหาจำเป็นต้องมีโครงสร้างที่ชัดเจนกว่านี้เพื่อให้วิธีการนี้ได้ผล
ในหลายกรณี อัลกอริทึมแบบโลภไม่สามารถสร้างคำตอบที่แน่นอนได้ แต่สามารถสร้างคำตอบที่ใกล้เคียงกับคำตอบที่แน่นอนได้ภายในระยะเวลาที่เหมาะสม[ 2 ]
ตัวอย่างหนึ่งของปัญหาที่ยอมรับวิธีแก้ปัญหาแบบโลภ (greedy solution) ที่แม่นยำได้ คือปัญหาการเลือกกิจกรรม (activity selection problem ) โดยกำหนดให้มีชุดงานที่สามารถทำได้ระหว่างช่วงเวลาที่กำหนดไว้ ปัญหาคือการหาจำนวนงานสูงสุดที่สามารถทำได้ อัลกอริทึมแบบโลภที่ใช้แก้ปัญหานี้จะเรียงลำดับงานตามเวลาสิ้นสุด แล้วเลือกงานแรกที่เริ่มต้นหลังจากงานสุดท้ายสิ้นสุดลงซ้ำๆ

อัลกอริทึมคลาสสิกจำนวนมากในวิทยาศาสตร์คอมพิวเตอร์ เช่นอัลกอริทึมการเข้ารหัส Huffman , อัลกอริทึม Prim , อัลกอริทึม Kruskalและอัลกอริทึม Dijkstraล้วนใช้คุณสมบัติแบบโลภในการออกแบบ นักคณิตศาสตร์มักใช้กลยุทธ์แบบโลภในการพิสูจน์เช่นกัน ตัวอย่างคลาสสิกคือสิ่งที่Raphael Yusterเรียกว่าการพิสูจน์แบบโลภ[ 3 ]ที่ว่าทัวร์นาเมนต์ทุกรายการในกราฟมีเส้นทางแฮมิลโทเนียน
ลักษณะเฉพาะ
เนื่องจากไม่มีคำจำกัดความอย่างเป็นทางการของอัลกอริทึมแบบโลภ[ 4 ]จึงไม่ทราบลักษณะเฉพาะที่สมบูรณ์ของปัญหาที่ยอมรับอัลกอริทึมแบบโลภเป็นวิธีแก้ปัญหา อย่างไรก็ตาม ได้มีการระบุกรณีพิเศษไว้แล้วJack Edmondsแสดงให้เห็นว่าสามารถใช้อัลกอริทึมแบบโลภเพื่อแก้ปัญหาการเพิ่มประสิทธิภาพเชิงรวมเชิงเส้นประเภทหนึ่งที่มีโครงสร้างเมทริกซ์ ได้ [ 5 ]
ต่อมาBernhard KorteและLászló Lovászได้จำแนกประเภทของปัญหาการหาค่าเหมาะสมที่สุดที่กว้างขึ้น โดยนำเสนอแนวคิดของ " greedoid"ซึ่ง ทำให้สามารถพิสูจน์ได้ว่าอัลกอริทึมของ Prim นั้น เป็นอัลกอริทึมที่เหมาะสมที่สุด
อัลกอริทึมที่ย้อนกลับขั้นตอนที่ผ่านมาไม่ใช่แบบโลภ (greedy algorithm) ตัวอย่างเช่น อัลกอริทึม Gale-Shapleyไม่ใช่แบบโลภ เนื่องจากถึงแม้จะสร้างคำตอบโดยการเลือกคู่ที่ดีที่สุดในปัจจุบัน แต่ในกระบวนการนั้น คำตอบที่มีอยู่แล้วอาจถูกแก้ไขได้
ความถูกต้อง
เทคนิคหนึ่งที่ใช้ในการพิสูจน์ความเหมาะสมที่สุดของอัลกอริทึมแบบโลภคือการโต้แย้งแบบแลกเปลี่ยน[ 6 ]การโต้แย้งแบบแลกเปลี่ยนแสดงให้เห็นว่าวิธีแก้ปัญหาใดๆ ที่แตกต่างจากวิธีแก้ปัญหาแบบโลภนั้นดีได้มากที่สุดเท่ากับวิธีแก้ปัญหาแบบโลภ รูปแบบการพิสูจน์นี้โดยทั่วไปจะทำตามขั้นตอนเหล่านี้:
- สมมติว่ามีคำตอบที่เหมาะสมที่สุดซึ่งแตกต่างจากคำตอบแบบโลภ
- พิจารณาจุดแรกที่คำตอบที่เหมาะสมที่สุดและคำตอบแบบโลภแตกต่างกัน
- พิสูจน์ว่าการเปลี่ยนตัวเลือกที่ดีที่สุดไปเป็นตัวเลือกแบบโลภ ณ จุดนี้ จะไม่ทำให้ผลลัพธ์แบบโลภแย่ลง
- สรุปโดยใช้การอนุมานว่า วิธีแก้ปัญหาแบบโลภ (greedy solution) เป็นวิธีที่ดีที่สุด

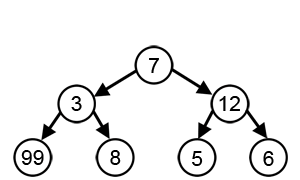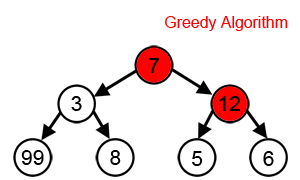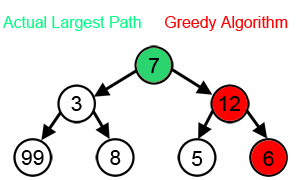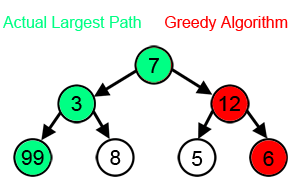
ตัวอย่างเพิ่มเติม
- ในปัญหาเป้สะพายหลังแบบเศษส่วน (Fractional Knapsack Problem ) เราจะได้รับรายการสิ่งของพร้อมน้ำหนักและมูลค่า เป้าหมายคือการเลือกจำนวนเศษส่วนของแต่ละรายการเพื่อให้มูลค่ารวมสูงสุด และน้ำหนักต้องต่ำกว่าข้อจำกัดที่กำหนดไว้ แตกต่างจากปัญหาเป้สะพายหลังทั่วไป (Knapsack Problem)ซึ่งเป็นที่ทราบกันดีว่าเป็น ปัญหา NP-hardปัญหาเป้สะพายหลังแบบเศษส่วนสามารถใช้ขั้นตอนวิธีแบบโลภ (Greedy Algorithm) ที่ใช้เวลาในการประมวลผลแบบพหุนามได้
- กรณีของปัญหาเหรียญ Frobeniusยอมรับวิธีแก้ปัญหาแบบโลภ อย่างไรก็ตาม ในบางกรณีอัลกอริทึมแบบโลภไม่ได้ให้คำตอบที่เหมาะสมที่สุด[ 7 ]
- การค้นหาแบบจับคู่ (Matching Pursuit)เป็นตัวอย่างหนึ่งของอัลกอริทึมแบบโลภ (Greedy Algorithm) ที่นำมาใช้ในการประมาณค่าสัญญาณ
- อัลกอริทึมแบบโลภ (greedy algorithm) ค้นหาคำตอบที่ดีที่สุดสำหรับปัญหาของ Malfattiในการค้นหาวงกลมสามวงที่ไม่ทับซ้อนกันภายในสามเหลี่ยมที่กำหนด ซึ่งทำให้พื้นที่รวมของวงกลมเหล่านั้นมีค่าสูงสุด มีการตั้งข้อสันนิษฐานว่าอัลกอริทึมแบบโลภเดียวกันนี้เหมาะสมที่สุดสำหรับจำนวนวงกลมใดๆ ก็ตาม
- ในการเรียนรู้ต้นไม้ตัดสินใจมักใช้อัลกอริทึมแบบโลภ (greedy algorithms) แต่ก็ไม่รับประกันว่าจะพบคำตอบที่ดีที่สุดเสมอไป
- อัลกอริทึมที่เป็นที่นิยมอย่างหนึ่งคืออัลกอริทึม ID3สำหรับการสร้างต้นไม้ตัดสินใจ
- อัลกอริทึม แบบโลภ (greedy algorithm) สร้างการแสดงผลแบบ Zeckendorf (หรือการเข้ารหัสแบบฟิโบนาชชี) ของจำนวนธรรมชาติ โดยการลบจำนวนฟิโบนาชชีที่มากที่สุดที่น้อยกว่าหรือเท่ากับจำนวนธรรมชาติซ้ำๆ จะได้การแสดงผลแบบ Zeckendorf อัลกอริทึมแบบโลภนี้ได้มาจากการพิสูจน์การมีอยู่ของการแสดงผลแบบ Zeckendorf ความเป็นเอกลักษณ์ของการแสดงผลแบบ Zeckendorf รับประกันว่าผลรวมฟิโบนาชชีที่ไม่ต่อเนื่องกันอื่นๆ จะไม่ให้ผลลัพธ์ที่แตกต่างกัน
- ฟิโบนาชชีได้อธิบาย อัลกอริทึมแบบโลภ (greedy algorithm ) สำหรับการคำนวณเศษส่วนของชาวอียิปต์
- อัลกอริทึมแบบโลภ (Greedy algorithms) ปรากฏในการกำหนดเส้นทางเครือข่ายโดยใช้การกำหนดเส้นทางแบบโลภ ข้อความจะถูกส่งต่อไปยังโหนดข้างเคียงที่ "ใกล้" กับปลายทางมากที่สุด แนวคิดเกี่ยวกับตำแหน่งของโหนด (และ "ความใกล้" จึงเป็นที่มาของแนวคิดนี้) อาจถูกกำหนดโดยตำแหน่งทางกายภาพ เช่น ในการกำหนดเส้นทางตามภูมิศาสตร์ที่ใช้ในเครือข่ายเฉพาะกิจ หรือตำแหน่งอาจเป็นสิ่งที่สร้างขึ้นมาอย่างสมบูรณ์ เช่น ในการกำหนดเส้นทางแบบโลกเล็ก (Small World Routing)และตารางแฮชแบบกระจาย (Distributed Hash Table )
อัลกอริทึมแบบโลภบนกราฟ
ทฤษฎีกราฟเป็นแหล่งที่มาอันอุดมสมบูรณ์ของอัลกอริธึมแบบโลภ (greedy algorithms) นักวิทยาศาสตร์คอมพิวเตอร์มักใช้อัลกอริธึมแบบโลภบ่อยครั้งในการคำนวณค่าคงที่ของกราฟ
- อัลกอริทึมของ Dijkstraและอัลกอริทึมการค้นหา A* ที่เกี่ยวข้อง เป็นอัลกอริทึมแบบโลภ (greedy algorithm) ที่เหมาะสมที่สุดที่สามารถตรวจสอบได้สำหรับการค้นหากราฟและการค้นหาเส้นทางที่สั้นที่สุด
- การค้นหาแบบ A* นั้นเหมาะสมที่สุดแบบมีเงื่อนไข โดยต้องใช้ " ฮิวริสติกที่ยอมรับได้ " ซึ่งจะไม่ประเมินต้นทุนเส้นทางสูงเกินไป
- อัลกอริทึมของ Kruskalและอัลกอริทึมของ Primเป็นอัลกอริทึมแบบโลภ (greedy algorithm) สำหรับการสร้างต้นไม้แผ่คลุมขั้นต่ำ (minimum spanning tree)ของกราฟเชื่อมต่อ ที่กำหนดให้ อัลกอริ ทึมเหล่านี้จะหาคำตอบที่ดีที่สุดได้เสมอ ซึ่งโดยทั่วไปแล้วอาจไม่ใช่คำตอบเดียว
- อัลกอริทึมแบบโลภ (greedy algorithm) สร้างต้นไม้ฮัฟฟ์แมน (Huffman tree) ในการเข้ารหัสฮัฟฟ์แมน (Huffman coding )
- อัลกอริ ทึม SequiturและLempel -Ziv-Welchเป็นอัลกอริทึมแบบโลภ (greedy algorithms) สำหรับการสร้างไวยากรณ์แบบอุปนัย (grammar induction )
- อัลกอริทึมแบบโลภ (greedy algorithm) ค้นหาเซตอิสระที่ใหญ่ที่สุดในโครงสร้างต้นไม้
อัลกอริทึมแบบโลภยังใช้เพื่อค้นหาขอบเขตบนสำหรับจำนวนสี[ 8 ]ตัวอย่างง่ายๆ คือขอบเขตที่ได้จากอัลกอริทึมแบบโลภ[ 9 ]เราเริ่มต้นด้วยการเลือกจุดยอดที่ยังไม่ได้ระบายสี เนื่องจากมีเพื่อนบ้านอย่างมากที่สุด สีจึงถูกใช้ในจุดยอดที่อยู่ติดกันอย่างมากที่สุดทำให้เหลือสีว่างสำหรับจุดยอดที่กำลังพิจารณา


อัลกอริทึมการประมาณค่าแบบโลภ
วิธีแก้ปัญหาพนักงานขายเดินทางที่เป็นปัญหาNP-complete สามารถประมาณได้โดยเริ่มจากเซตขอบที่ว่างเปล่า จากนั้นเพิ่มขอบที่ถูกที่สุดถัดไปซึ่งเป็นกราฟย่อยของเส้นทางที่สมบูรณ์ อัลกอริทึมโลภนี้ได้รับการพิสูจน์แล้วว่าให้ผลลัพธ์ที่ยาวกว่าเส้นทางที่เหมาะสมที่สุดไม่ เกิน [ 10 ]

อีกตัวอย่างหนึ่งคือ วิธีแก้ปัญหากระเป๋า 0-1สามารถประมาณได้โดยใช้อัลกอริทึมโลภสำหรับ ปัญหากระเป๋าเศษส่วน อัลกอริทึมโลภนี้ได้รับการพิสูจน์แล้วว่าให้ผลลัพธ์อย่างน้อยครึ่งหนึ่งของค่าของคำตอบที่เหมาะสมที่สุด[ 11 ]
วิธีแก้ปัญหาสำหรับการเพิ่มค่าสูงสุดของโมดูลาร์ย่อยจะถูกประมาณโดยใช้อัลกอริทึมแบบโลภซึ่งให้ผลลัพธ์อย่างน้อยครึ่งหนึ่งของค่าของวิธีแก้ปัญหาที่เหมาะสมที่สุด[ 12 ]
ปัญหาที่ใช้อัลกอริทึมแบบโลภเพื่อให้ได้อัลกอริทึมการประมาณค่า ได้แก่ปัญหา การครอบคลุมเซตการปรับสมดุลภาระต้นไม้สไตเนอร์และเซตอิสระ[ 13 ]
ดูเพิ่มเติม
ลิงก์ภายนอก
- "อัลกอริทึมโลภ" , สารานุกรมคณิตศาสตร์ , EMS Press , 2001 [1994]
- Gift, Noah. "ตัวอย่างการใช้กลยุทธ์เหรียญโลภใน Python" .
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ อัลกอริทึมโลภ
อั ลกอริทึมแบบโลภ (greedy algorithm) คือ อัลกอริทึม ที่ในแต่ละขั้นตอนจะเลือกสิ่งที่ดีที่สุดในระดับท้องถิ่น และหลังจากนั้นจะไม่พิจารณาตัวเลือกในอดีตอีก...
ลักษณะเฉพาะ
เนื่องจากไม่มีคำจำกัดความอย่างเป็นทางการของอัลกอริทึมแบบโลภ [ 4 ] จึงไม่ทราบลักษณะเฉพาะที่สมบูรณ์ของปัญหาที่ยอมรับอัลกอริทึมแบบโลภเป็นวิธีแก้ปัญหา อย่างไรก็ตาม ได้มีการระบุกรณีพิเศษไว้แล้ว Jack Edmonds...
ความถูกต้อง
เทคนิคหนึ่งที่ใช้ในการพิสูจน์ความเหมาะสมที่สุดของอัลกอริทึมแบบโลภคือการโต้แย้งแบบแลกเปลี่ยน [ 6 ] การโต้แย้งแบบแลกเปลี่ยนแสดงให้เห็นว่าวิธีแก้ปัญหาใดๆ ที่แตกต่างจากวิธีแก้ปัญหาแบบโลภนั้นดีได้มากที่สุดเท่ากับวิธีแก้ปัญหาแบบโลภ...
ตัวอย่างเพิ่มเติม
ใน ปัญหาเป้สะพายหลังแบบเศษส่วน (Fractional Knapsack Problem ) เราจะได้รับรายการสิ่งของพร้อมน้ำหนักและมูลค่า เป้าหมายคือการเลือกจำนวนเศษส่วนของแต่ละรายการเพื่อให้มูลค่ารวมสูงสุด และน้ำหนักต้องต่ำกว่าข้อจำกัดที่กำหนดไว้ แตกต่างจาก ปัญหาเป้สะพายหลังทั่วไป...