อ่าน 17 นาที
เครื่องมือค้นหา
เครื่องมือ ค้นหาบนเว็บ หรือ เครื่องมือค้นหาบนอินเทอร์เน็ต คือ ระบบซอฟต์แวร์ ที่ให้ ไฮเปอร์ลิงก์ ไปยัง หน้าเว็บ และข้อมูลที่เกี่ยวข้องอื่นๆ บน เว็บ เพื่อตอบสนองต่อ คำค้นหา...
เครื่องมือค้นหา

เครื่องมือค้นหาบนเว็บหรือเครื่องมือค้นหาบนอินเทอร์เน็ตคือระบบซอฟต์แวร์ที่ให้ไฮเปอร์ลิงก์ไปยังหน้าเว็บและข้อมูลที่เกี่ยวข้องอื่นๆ บนเว็บเพื่อตอบสนองต่อคำค้นหา ของผู้ใช้ ผู้ใช้ส่งคำค้นหาผ่านเว็บเบราว์เซอร์หรือ แอปพลิเคชัน บน มือถือและหน้าผลลัพธ์ โดยทั่วไปจะแสดงไฮเปอร์ลิงก์จำนวน มากพร้อมคำอธิบายสั้นๆ และรูปภาพที่เกี่ยวข้อง ผู้ใช้ยังมีตัวเลือกในการจำกัดการค้นหาให้เหลือเฉพาะผลลัพธ์ประเภทต่างๆ เช่นรูปภาพวิดีโอหรือข่าวสาร
สำหรับผู้ให้บริการค้นหาระบบค้นหา ของพวกเขานั้น เป็นส่วนหนึ่งของ ระบบ ประมวลผลแบบกระจายศูนย์ซึ่งอาจครอบคลุมศูนย์ข้อมูล หลายแห่ง ทั่วโลก ความเร็วและความแม่นยำในการตอบสนองต่อคำค้นหาของระบบค้นหานั้นขึ้นอยู่กับระบบการจัดทำดัชนี ที่ซับซ้อน ซึ่งได้รับการอัปเดตอย่างต่อเนื่องโดยโปรแกรมรวบรวมข้อมูลเว็บ อัตโนมัติ ซึ่งอาจรวมถึงการขุดค้นข้อมูลจากไฟล์และฐานข้อมูลที่จัดเก็บไว้บนเว็บเซิร์ฟเวอร์แม้ว่าเนื้อหาบางส่วนจะไม่สามารถเข้าถึงได้โดยโปรแกรม รวบรวมข้อมูลก็ตาม
มีเครื่องมือค้นหามากมายนับตั้งแต่ยุคเริ่มต้นของเว็บในช่วงทศวรรษ 1990 อย่างไรก็ตามGoogle Searchกลายเป็นเครื่องมือที่โดดเด่นในช่วงทศวรรษ 2000 และยังคงเป็นเช่นนั้นมาจนถึงปัจจุบัน จากข้อมูลของ StatCounter ณ เดือนพฤษภาคม 2025 Google ครองส่วนแบ่งการค้นหาทั่วโลกประมาณ 89–90% โดยมีคู่แข่งตามมาห่างๆ ได้แก่Bing (~4%), Yandex (~2.5%), Yahoo! (~1.3%), DuckDuckGo (~0.8%) และBaidu (~0.7%) [ 1 ]ที่น่าสังเกตคือ นี่เป็นครั้งแรกในรอบกว่าทศวรรษที่ส่วนแบ่งของ Google ลดลงต่ำกว่า 90% ธุรกิจของเว็บไซต์ที่ปรับปรุงการมองเห็นในผลการค้นหาซึ่งรู้จักกันในชื่อการตลาดและการเพิ่มประสิทธิภาพจึงมุ่งเน้นไปที่ Google เป็นหลัก
ประวัติศาสตร์
| ปี | เครื่องยนต์ | สถานะปัจจุบัน |
|---|---|---|
| พ.ศ. 2536 | แคตตาล็อก W3 | ไม่ใช้งาน |
| อาลีเว็บ | ไม่ใช้งาน | |
| จัมป์สเตชั่น | ไม่ใช้งาน | |
| เวิร์ม WWW | ไม่ใช้งาน | |
| พ.ศ. 2537 | เว็บครอว์เลอร์ | คล่องแคล่ว |
| โก.คอม | ไม่ใช้งานแล้ว และจะเปลี่ยนเส้นทางไปยังเว็บไซต์ดิสนีย์ | |
| ไลคอส | คล่องแคล่ว | |
| อินโฟซีค | ไม่ใช้งานแล้ว และจะเปลี่ยนเส้นทางไปยังเว็บไซต์ดิสนีย์ | |
| พ.ศ. 2538 | Yahoo! ค้นหา | Active ซึ่งเดิมทีเป็นฟังก์ชันการค้นหาสำหรับYahoo! Directory |
| ดาอุม | คล่องแคล่ว | |
| ค้นหา.ch | คล่องแคล่ว | |
| แมเจลลัน | ไม่ใช้งาน | |
| ตื่นเต้น | คล่องแคล่ว | |
| เมตาครอว์เลอร์ | คล่องแคล่ว | |
| อัลตาวิสต้า | เว็บไซต์นี้ไม่ใช้งานแล้ว เนื่องจากถูก Yahoo! เข้าซื้อกิจการในปี 2003 และตั้งแต่ปี 2013 จะเปลี่ยนเส้นทางไปยัง Yahoo! | |
| ซาโป | คล่องแคล่ว | |
| พ.ศ. 2539 | แรงค์เดกซ์ | ไม่ได้ใช้งานแล้ว เนื่องจากถูกควบรวมเข้ากับบริษัท Baiduในปี 2000 |
| กองสุนัข | คล่องแคล่ว | |
| ฮอตบอท | ไม่ทำงาน (ใช้เทคโนโลยีการค้นหา Inktomi ) | |
| ถามจีฟส์ | ไม่ใช้งาน | |
| พ.ศ. 2540 | เอโอแอล เน็ตฟินด์ | Active (เปลี่ยนชื่อเป็นAOL Searchตั้งแต่ปี 1999) |
| goo.ne.jp | คล่องแคล่ว | |
| แสงเหนือ | ไม่ใช้งาน | |
| แยนเด็กซ์ | คล่องแคล่ว | |
| 1998 | คล่องแคล่ว | |
| อี้ควิก | ใช้งานในชื่อ Startpage.com | |
| การค้นหา MSN | ใช้งานในฐานะ Bing | |
| เอมปัส | ปิดใช้งานแล้ว (รวมเข้ากับ NATE แล้ว) | |
| 1999 | เว็บทั้งหมด | ไม่ใช้งาน (URL ถูกเปลี่ยนเส้นทางไปยัง Yahoo!) |
| GenieKnows | เว็บไซต์นี้ไม่ได้ใช้งานแล้ว และเปลี่ยนชื่อเป็น Yellowee (เดิมทีเปลี่ยนเส้นทางไปยัง justlocalbusiness.com) | |
| นาเวอร์ | คล่องแคล่ว | |
| ทีโอมา | ปิดใช้งานแล้ว (เปลี่ยนเส้นทางไปยัง Ask.com) | |
| 2000 | ไบดู | คล่องแคล่ว |
| เอ็กซาลีด | ไม่ใช้งาน | |
| กิกะบลาสต์ | ไม่ใช้งาน | |
| 2001 | คาร์ทู | ไม่ใช้งาน |
| 2003 | อินโฟ.คอม | คล่องแคล่ว |
| 2004 | เอ9.คอม | ไม่ใช้งาน |
| คลัสเตอร์ | Active, Yippy ซึ่งเดิมชื่อ Clusty ปัจจุบันเป็นเจ้าของ Togoda.com แล้ว | |
| โมจีค | คล่องแคล่ว | |
| โซกู | คล่องแคล่ว | |
| 2548 | ค้นหาฉัน | ไม่ใช้งาน |
| คิดส์เสิร์ช | แอคทีฟ, การค้นหาของ Google | |
| 2006 | โซโซ | เลิกใช้งานแล้ว เนื่องจากรวมเข้ากับSogou แล้ว |
| ควาเอโร | ไม่ใช้งาน | |
| เสิร์ช.คอม | คล่องแคล่ว | |
| ชาชา | ไม่ใช้งาน | |
| ถาม.com | ไม่ใช้งาน | |
| ค้นหาสด | ใช้งานในชื่อ Bing ซึ่งเปลี่ยนชื่อเป็น MSN Search | |
| 2007 | วิกิซีค | ไม่ใช้งาน |
| สปรูส | ไม่ใช้งาน | |
| ค้นหาวิกิ | ไม่ใช้งาน | |
| แบล็คเคิล.com | แอคทีฟ, การค้นหาของ Google | |
| 2008 | พาวเวอร์เซ็ต | ไม่ทำงาน (จะเปลี่ยนเส้นทางไปยัง Bing) |
| เครื่องนับเม็ด | ไม่ใช้งาน | |
| วิวซี่ | ไม่ใช้งาน | |
| ลีปฟิช | ไม่ใช้งาน | |
| ฟอเรสเทิล | ปิดใช้งานแล้ว (จะเปลี่ยนเส้นทางไปยัง Ecosia) | |
| ดั๊กดั๊กโก | คล่องแคล่ว | |
| ทินอาย | คล่องแคล่ว | |
| 2009 | บิง | การค้นหาแบบเรียลไทม์ (Live Search) ที่ปรับปรุงใหม่และใช้งานได้แล้ว |
| เยโบล | ไม่ใช้งาน | |
| สเกาท์ (โกบี้) | คล่องแคล่ว | |
| เนท | คล่องแคล่ว | |
| อีโคเซีย | คล่องแคล่ว | |
| สตาร์ทเพจ.com | Active คือโปรแกรมในเครือเดียวกับ Ixquick | |
| 2010 | เบล็กโก้ | เลิกกิจการแล้ว ขายให้กับ IBM |
| คูอิล | ไม่ใช้งาน | |
| Yandex (ภาษาอังกฤษ) | คล่องแคล่ว | |
| ปาร์ซิฮู | คล่องแคล่ว | |
| 2011 | ยาซี | แอคทีฟ, P2P |
| 2012 | โวลูเนีย | ไม่ใช้งาน |
| 2013 | คิววอนท์ | คล่องแคล่ว |
| 2014 | เอเกอริน | แอคทีฟ, เคิร์ด / โซรานี |
| วัวสวิส | คล่องแคล่ว | |
| เซียร์กซ์ | คล่องแคล่ว | |
| 2015 | ยูซ | ไม่ใช้งาน |
| คลิกซ์ | ไม่ใช้งาน | |
| 2016 | คิดเดิล | แอคทีฟ, การค้นหาของ Google |
| 2017 | การค้นหาล่วงหน้า | คล่องแคล่ว |
| 2018 | คากิ | คล่องแคล่ว |
| 2020 | กลีบดอกไม้ | คล่องแคล่ว |
| 2021 | การค้นหาแบบกล้าหาญ | คล่องแคล่ว |
| ยูคอม | คล่องแคล่ว | |
| 2022 | ความสับสน | คล่องแคล่ว |
ก่อนปี 1990
ในปี พ.ศ. 2488 Vannevar Bushได้อธิบายระบบการค้นหาข้อมูลที่จะช่วยให้ผู้ใช้สามารถเข้าถึงข้อมูลจำนวนมหาศาลได้ทั้งหมดจากโต๊ะทำงานเพียงโต๊ะเดียว ซึ่งเขาเรียกว่าmemex [ 2 ] เขาได้อธิบายระบบนี้ในบทความชื่อ " As We May Think " ในThe Atlantic Monthly [ 3 ] Memexมีจุดประสงค์เพื่อให้ผู้ใช้สามารถเอาชนะความยากลำบากที่เพิ่มขึ้นเรื่อยๆ ในการค้นหาข้อมูลในดัชนีส่วนกลางของงานวิจัยทางวิทยาศาสตร์ที่เติบโตขึ้นเรื่อยๆ Vannevar Bush จินตนาการถึงห้องสมุดงานวิจัยที่มีคำอธิบายประกอบที่เชื่อมโยงกัน ซึ่งคล้ายกับไฮเปอร์ลิงก์ ในปัจจุบัน [ 4 ]
การวิเคราะห์ลิงก์ ในที่สุดก็กลายเป็นองค์ประกอบสำคัญของเครื่องมือค้นหาผ่านอั ลกอริทึมต่างๆ เช่นHyperSearchและPageRank [ 5 ] [ 6 ]
ทศวรรษ 1990: กำเนิดของเครื่องมือค้นหา
เครื่องมือค้นหาอินเทอร์เน็ตเครื่องแรกมีมาก่อนการเปิดตัวเว็บในเดือนธันวาคม พ.ศ. 2533: การค้นหาผู้ใช้ WHOISมีมาตั้งแต่ปี พ.ศ. 2525 [ 7 ]และ การค้นหาผู้ใช้แบบหลายเครือข่าย Knowbot Information Serviceได้ถูกนำมาใช้ครั้งแรกในปี พ.ศ. 2532 [ 8 ]เครื่องมือค้นหาที่มีการบันทึกไว้อย่างดีเครื่องแรกที่ค้นหาไฟล์เนื้อหา โดยเฉพาะไฟล์FTP คือ Archieซึ่งเปิดตัวเมื่อวันที่ 10 กันยายน พ.ศ. 2533 [ 9 ]
ก่อนเดือนกันยายน พ.ศ. 2536 เครือข่ายเวิลด์ไวด์เว็บทั้งหมดถูกจัดทำดัชนีด้วยมือ มีรายการเว็บเซิร์ฟเวอร์ที่แก้ไขโดยTim Berners-Leeและโฮสต์อยู่บนเว็บเซิร์ฟเวอร์ของ CERN ภาพรวมของรายการในปี พ.ศ. 2535 ยังคงอยู่[ 10 ]แต่เนื่องจากมีเว็บเซิร์ฟเวอร์ออนไลน์เพิ่มมากขึ้นเรื่อยๆ รายการส่วนกลางจึงไม่สามารถอัปเดตได้ทัน บน เว็บไซต์ NCSAมีการประกาศเซิร์ฟเวอร์ใหม่ภายใต้หัวข้อ "มีอะไรใหม่บ้าง!" [ 11 ]
เครื่องมือแรกที่ใช้ในการค้นหาเนื้อหา (ตรงข้ามกับผู้ใช้) บนอินเทอร์เน็ตคือ Archie [ 12 ]ชื่อนี้มาจากคำว่า "archive" โดยไม่มี "v" [ 13 ]สร้างขึ้นโดยAlan Emtage [ 13 ] [ 14 ] [ 15 ] [ 16 ] นักศึกษาวิทยาการคอมพิวเตอร์ ที่ มหาวิทยาลัย McGillในมอนทรีออล รัฐควิเบก ประเทศแคนาดา โปรแกรม นี้ดาวน์โหลดรายการไดเร็กทอรีของไฟล์ทั้งหมดที่อยู่ในเว็บไซต์ FTP ( File Transfer Protocol ) สาธารณะที่ไม่ระบุตัวตน สร้างฐานข้อมูลชื่อไฟล์ที่สามารถค้นหาได้ อย่างไรก็ตาม เครื่องมือค้นหา Archie ไม่ได้จัดทำดัชนีเนื้อหาของเว็บไซต์เหล่านี้ เนื่องจากปริมาณข้อมูลมีจำกัดมากจนสามารถค้นหาได้ด้วยตนเองอย่างง่ายดาย
การเกิดขึ้นของGopher (สร้างขึ้นในปี 1991 โดยMark McCahillที่มหาวิทยาลัยมินนิโซตา ) นำไปสู่โปรแกรมค้นหาใหม่สองโปรแกรม คือVeronicaและJugheadเช่นเดียวกับ Archie โปรแกรมเหล่านี้ค้นหาชื่อไฟล์และชื่อเรื่องที่จัดเก็บไว้ในระบบดัชนีของ Gopher Veronica (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) ให้บริการค้นหาคำหลักสำหรับชื่อเมนูส่วนใหญ่ในรายการ Gopher ทั้งหมด Jughead (Jonzy's Universal Gopher Hierarchy Excavation And Display) เป็นเครื่องมือสำหรับดึงข้อมูลเมนูจากเซิร์ฟเวอร์ Gopher เฉพาะ แม้ว่าชื่อของเครื่องมือค้นหา " Archie Search Engine " จะไม่ได้อ้างอิงถึง ซีรี่ส์ การ์ตูน Archieแต่ " Veronica " และ " Jughead " เป็นตัวละครในซีรี่ส์ ดังนั้นจึงอ้างอิงถึงรุ่นก่อนหน้า
ในช่วงฤดูร้อนของปี 1993 ยังไม่มีเครื่องมือค้นหาบนเว็บ แม้ว่าจะมีแคตตาล็อกเฉพาะทางจำนวนมากที่ได้รับการดูแลด้วยมือก็ตามOscar Nierstraszจากมหาวิทยาลัยเจนีวา ได้เขียนสคริปต์ Perlชุดหนึ่งซึ่งจำลองหน้าเว็บเหล่านี้เป็นระยะและเขียนใหม่ให้เป็นรูปแบบมาตรฐาน นี่เป็นพื้นฐานสำหรับW3Catalogซึ่งเป็นเครื่องมือค้นหาแบบดั้งเดิมเครื่องแรกของเว็บ เปิดตัวเมื่อวันที่ 2 กันยายน 1993 [ 17 ]
ในเดือนมิถุนายน ปี 1993 แมทธิว เกรย์ ซึ่งขณะนั้นทำงานอยู่ที่MITได้สร้างสิ่งที่น่าจะเป็นเว็บโรบอต ตัวแรก นั่นคือWorld Wide Web Wandererที่เขียนด้วยภาษาPerlและใช้มันสร้างดัชนีที่เรียกว่า "Wandex" จุดประสงค์ของ Wanderer คือการวัดขนาดของเวิลด์ไวด์เว็บ ซึ่งมันทำได้จนถึงปลายปี 1995 เครื่องมือค้นหาเว็บตัวที่สองAliwebปรากฏขึ้นในเดือนพฤศจิกายน ปี 1993 Aliweb ไม่ได้ใช้เว็บโรบอต แต่พึ่งพาการแจ้งเตือนจากผู้ดูแลเว็บไซต์เกี่ยวกับการมีอยู่ของไฟล์ดัชนีในรูปแบบเฉพาะที่แต่ละเว็บไซต์
JumpStation (สร้างขึ้นในเดือนธันวาคม พ.ศ. 2536 [ 18 ]โดยJonathon Fletcher ) ใช้หุ่นยนต์เว็บเพื่อค้นหาเว็บเพจและสร้างดัชนี และใช้แบบฟอร์มเว็บเป็นอินเทอร์เฟซสำหรับโปรแกรมค้นหา ดังนั้นจึงเป็น เครื่องมือค้นหาทรัพยากร WWW ตัวแรก ที่รวมคุณสมบัติสำคัญสามประการของเครื่องมือค้นหาเว็บ (การรวบรวม การจัดทำดัชนี และการค้นหา) ดังที่อธิบายไว้ด้านล่าง เนื่องจากทรัพยากรที่มีจำกัดบนแพลตฟอร์มที่ใช้งาน การจัดทำดัชนีและการค้นหาจึงถูกจำกัดไว้เฉพาะชื่อเรื่องและหัวข้อที่พบในเว็บเพจที่ตัวรวบรวมข้อมูลพบเจอ
หนึ่งในเครื่องมือค้นหาแบบ "ค้นหาข้อความทั้งหมด" รุ่นแรกๆ คือWebCrawlerซึ่งเปิดตัวในปี 1994 แตกต่างจากเครื่องมือค้นหารุ่นก่อนๆ ตรงที่ WebCrawler อนุญาตให้ผู้ใช้ค้นหาคำใดๆ ก็ได้ในหน้าเว็บ ใดๆ ก็ได้ ซึ่งกลายเป็นมาตรฐานสำหรับเครื่องมือค้นหาหลักๆ ทุกเครื่องนับตั้งแต่นั้นเป็นต้นมา นอกจากนี้ WebCrawler ยังเป็นเครื่องมือค้นหาที่สาธารณชนรู้จักอย่างกว้างขวางอีกด้วย และในปีเดียวกันนั้นเองLycos (ซึ่งเริ่มต้นที่มหาวิทยาลัย Carnegie Mellon ) ก็ได้เปิดตัวและกลายเป็นธุรกิจเชิงพาณิชย์ขนาดใหญ่
เครื่องมือค้นหายอดนิยมเครื่องแรกบนเว็บคือYahoo! Search [ 19 ] ผลิตภัณฑ์แรกจากYahoo!ซึ่งก่อตั้งโดยJerry YangและDavid Filoในเดือนมกราคม 1994 คือไดเร็กทอรีเว็บที่เรียกว่าYahoo! Directoryในปี 1995 ได้มีการเพิ่มฟังก์ชันการค้นหา ทำให้ผู้ใช้สามารถค้นหาใน Yahoo! Directory ได้[ 20 ] [ 21 ]มันกลายเป็นหนึ่งในวิธีที่ได้รับความนิยมมากที่สุดสำหรับผู้คนในการค้นหาเว็บเพจที่สนใจ แต่ฟังก์ชันการค้นหาทำงานบนไดเร็กทอรีเว็บ ไม่ใช่สำเนาข้อความเต็มของเว็บเพจ
หลังจากนั้นไม่นาน ก็มีเครื่องมือค้นหาจำนวนมากปรากฏขึ้นและแข่งขันกันเพื่อแย่งชิงความนิยม ซึ่งรวมถึงMagellan , Excite , Infoseek , Inktomi , Northern LightและAltaVistaผู้ที่ต้องการค้นหาข้อมูลยังสามารถเรียกดูสารบัญแทนการค้นหาด้วยคำหลักได้อีกด้วย
ในปี 1996 Robin Liได้พัฒนาอัลกอริ ทึมการ ให้คะแนนเว็บไซต์RankDexสำหรับการจัดอันดับหน้าผลการค้นหาของเครื่องมือค้นหา[ 22 ] [ 23 ] [ 24 ]และได้รับสิทธิบัตรของสหรัฐอเมริกาสำหรับเทคโนโลยีนี้[ 25 ]นับเป็นเครื่องมือค้นหาแรกที่ใช้ไฮเปอร์ลิงก์ในการวัดคุณภาพของเว็บไซต์ที่กำลังจัดทำดัชนี[ 26 ]ซึ่งมาก่อนสิทธิบัตรอัลกอริทึมที่คล้ายกันมากซึ่งGoogle ยื่นจด ในอีกสองปีต่อมาในปี 1998 [ 27 ] Larry Pageได้อ้างอิงถึงงานของ Li ในสิทธิบัตรของสหรัฐอเมริกาบางฉบับสำหรับ PageRank [ 28 ]ต่อมา Li ได้ใช้เทคโนโลยี RankDex ของเขาสำหรับ เครื่องมือค้นหา Baiduซึ่งเขาก่อตั้งขึ้นในประเทศจีนและเปิดตัวในปี 2000
ในปี พ.ศ. 2539 Netscapeกำลังมองหาที่จะมอบข้อตกลงพิเศษให้กับเครื่องมือค้นหาเพียงเครื่องเดียวเพื่อใช้เป็นเครื่องมือค้นหาหลักบนเว็บเบราว์เซอร์ของ Netscape แต่เนื่องจากมีผู้สนใจจำนวนมาก Netscape จึงได้ทำข้อตกลงกับเครื่องมือค้นหาหลัก 5 เครื่องแทน โดยแต่ละเครื่องจะได้รับค่าตอบแทน 5 ล้านดอลลาร์สหรัฐต่อปี และหมุนเวียนกันแสดงบนหน้าเครื่องมือค้นหาของ Netscape เครื่องมือค้นหาทั้ง 5 เครื่องนั้นได้แก่ Yahoo!, Magellan, Lycos, Infoseek และ Excite [ 29 ] [ 30 ]
Googleนำแนวคิดการขายคำค้นหามาใช้ในปี 1998 จากบริษัทเครื่องมือค้นหาขนาดเล็กชื่อgoto.comการเคลื่อนไหวนี้ส่งผลกระทบอย่างมากต่อธุรกิจเครื่องมือค้นหา ซึ่งเปลี่ยนจากธุรกิจที่ประสบปัญหาไปเป็นหนึ่งในธุรกิจที่ทำกำไรได้มากที่สุดบนอินเทอร์เน็ต[ 31 ] [ 32 ]
เครื่องมือค้นหาดึงดูดการลงทุนจำนวนมากในช่วงปลายทศวรรษ 1990 [ 33 ]บริษัทหลายแห่งเข้าสู่ตลาดและได้รับผลกำไรเป็นประวัติการณ์ในช่วงการเสนอขายหุ้นต่อสาธารณะครั้งแรกบางบริษัทได้ปิดเครื่องมือค้นหาสาธารณะของตนและทำการตลาดเฉพาะรุ่นสำหรับองค์กรเท่านั้น เช่น Northern Light บริษัทเครื่องมือค้นหาหลายแห่งติดอยู่ในฟองสบู่ดอทคอมซึ่งเป็นตลาดบูมที่ขับเคลื่อนด้วยการเก็งกำไรซึ่งถึงจุดสูงสุดในเดือนมีนาคม พ.ศ. 2543
ทศวรรษ 2000 – ปัจจุบัน: หลังฟองสบู่ดอทคอมแตก
ประมาณปี 2000 เครื่องมือค้นหาของ Googleได้รับความนิยมอย่างมาก[ 34 ]บริษัทประสบความสำเร็จในการค้นหาหลายรายการด้วยอัลกอริทึมที่เรียกว่าPageRankดังที่อธิบายไว้ในเอกสารAnatomy of a Search Engineที่เขียนโดยSergey BrinและLarry Pageผู้ก่อตั้ง Google ในเวลาต่อมา[ 6 ]อัลกอริทึมแบบวนซ้ำนี้จะจัดอันดับเว็บเพจตามจำนวนและ PageRank ของเว็บไซต์และเพจอื่นๆ ที่เชื่อมโยงมายังเว็บเพจนั้น โดยมีสมมติฐานว่าเว็บเพจที่ดีหรือน่าสนใจจะถูกเชื่อมโยงมากกว่าเว็บเพจอื่นๆ สิทธิบัตร PageRank ของ Larry Page อ้างอิงถึง สิทธิบัตร RankDexของRobin Li ก่อนหน้านี้ เป็นแรงบันดาลใจ[ 28 ] [ 24 ] Google ยังคงรักษาอินเทอร์เฟซที่เรียบง่ายสำหรับเครื่องมือค้นหาของตน ในทางตรงกันข้าม คู่แข่งหลายรายฝังเครื่องมือค้นหาไว้ในพอร์ทัลเว็บอันที่จริง เครื่องมือค้นหาของ Google ได้รับความนิยมมากจนเกิดเครื่องมือปลอมขึ้นมา เช่นMystery Seeker
ในปี 2000 Yahoo!ให้บริการค้นหาโดยใช้เครื่องมือค้นหาของ Inktomi Yahoo! เข้าซื้อกิจการ Inktomi ในปี 2002 และOverture (ซึ่งเป็นเจ้าของAlltheWebและ AltaVista) ในปี 2003 Yahoo! เปลี่ยนไปใช้เครื่องมือค้นหาของ Google จนถึงปี 2004 เมื่อเปิดตัวเครื่องมือค้นหาของตนเองโดยใช้เทคโนโลยีจากบริษัทที่เข้าซื้อกิจการมารวมกัน
ไมโครซอฟต์เปิดตัว MSN Search ครั้งแรกในฤดูใบไม้ร่วงปี 1998 โดยใช้ผลการค้นหาจาก Inktomi ในช่วงต้นปี 1999 เว็บไซต์เริ่มแสดงรายการจากLooksmart ผสมผสานกับผลการค้นหาจาก Inktomi และในช่วงสั้นๆ ในปี 1999 MSN Search ก็ใช้ผลการค้นหาจาก AltaVista แทน ในปี 2004 ไมโครซอฟต์เริ่มเปลี่ยนไปใช้เทคโนโลยีการค้นหาของตนเอง ซึ่งขับเคลื่อนโดย เว็บครอว์เลอร์ของตนเอง(เรียกว่าmsnbot )
Bingซึ่งเป็นเครื่องมือค้นหาที่เปลี่ยนชื่อใหม่ของ Microsoft เปิดตัวเมื่อวันที่ 1 มิถุนายน 2552 และในวันที่ 29 กรกฎาคม 2552 Yahoo! และ Microsoft ได้บรรลุข้อตกลงขั้นสุดท้าย โดยYahoo! Searchจะใช้เทคโนโลยี Bing ของ Microsoft เป็นพลังขับเคลื่อน
ณ ปี 2019 โปรแกรมรวบรวมข้อมูลเครื่องมือค้นหาที่ใช้งานอยู่ ได้แก่Baidu , Bing, Brave , [ 35 ] Google, DuckDuckGo , Gigablast , Mojeek , SogouและYandex
ในช่วงทศวรรษ 2020 เครื่องมือค้นหาที่ขับเคลื่อนด้วย ปัญญาประดิษฐ์และ ผู้ช่วย AI ที่สร้างขึ้นได้ถูกรวมเข้ากับการค้นหาเว็บกระแสหลักมากขึ้น ระบบเหล่านี้ผสมผสานการจัดทำดัชนีเว็บแบบดั้งเดิมเข้ากับแบบจำลองภาษาขนาดใหญ่เพื่อให้การตอบสนองแบบสนทนา สรุป และคำแนะนำตามบริบท[ 36 ]
เข้าใกล้
เครื่องมือค้นหาจะรักษาขั้นตอนต่อไปนี้ในเวลาเกือบเรียลไทม์: [ 37 ]
เครื่องมือค้นหาบนเว็บได้รับข้อมูลโดยการรวบรวมข้อมูลจากเว็บไซต์หนึ่งไปยังอีกเว็บไซต์หนึ่ง "สไปเดอร์" จะตรวจสอบไฟล์ชื่อมาตรฐานrobots.txtที่ส่งถึงมัน ไฟล์ robots.txt ประกอบด้วยคำสั่งสำหรับสไปเดอร์ค้นหา โดยบอกว่าควรรวบรวมข้อมูลจากหน้าใดบ้าง และไม่ควรรวบรวมข้อมูลจากหน้าใดบ้าง หลังจากตรวจสอบ robots.txt แล้ว ไม่ว่าจะพบหรือไม่พบ สไปเดอร์จะส่งข้อมูลบางอย่างกลับไปเพื่อจัดทำดัชนีโดยขึ้นอยู่กับหลายปัจจัย เช่น ชื่อเรื่อง เนื้อหาหน้าเว็บJavaScript ไฟล์ CSS หัวข้อ หรือเมตาเดต้าในแท็ก meta ของ HTML หลังจากรวบรวมข้อมูลได้จำนวนหนึ่ง จัดทำดัชนีข้อมูลได้มากน้อยเพียงใด หรือใช้เวลาบนเว็บไซต์นานเท่าใด สไปเดอร์ก็จะหยุดการรวบรวมข้อมูลและไปยังเว็บไซต์อื่น "[ไม่มี] โปรแกรมรวบรวมข้อมูลบนเว็บใดที่สามารถรวบรวมข้อมูลบนเว็บได้ทั้งหมด เนื่องจากเว็บไซต์มีจำนวนมากมายมหาศาล กับดักของสไปเดอร์ สแปม และข้อจำกัดอื่นๆ ของเว็บจริง โปรแกรมรวบรวมข้อมูลจึงใช้ นโยบายการรวบรวมข้อมูล เพื่อกำหนดว่าเมื่อใดจึงจะถือว่าการรวบรวมข้อมูลของเว็บไซต์นั้นเพียงพอแล้ว บางเว็บไซต์จะถูกรวบรวมข้อมูลอย่างละเอียด ในขณะที่บางเว็บไซต์จะถูกรวบรวมข้อมูลเพียงบางส่วนเท่านั้น" [ 39 ]
การจัดทำดัชนีหมายถึงการเชื่อมโยงคำและโทเค็นอื่นๆ ที่สามารถระบุได้ซึ่งพบในหน้าเว็บกับชื่อโดเมนและ ฟิลด์ที่ใช้ HTMLการเชื่อมโยงเหล่านี้จะถูกจัดเก็บไว้ในฐานข้อมูลสาธารณะและสามารถเข้าถึงได้ผ่านการค้นหาเว็บ การค้นหาจากผู้ใช้สามารถเป็นคำเดียว หลายคำ หรือประโยคก็ได้ ดัชนีจะช่วยค้นหาข้อมูลที่เกี่ยวข้องกับการค้นหาได้อย่างรวดเร็วที่สุด[ 38 ]เทคนิคบางอย่างสำหรับการจัดทำดัชนีและการแคชเป็นความลับทางการค้า ในขณะที่การรวบรวมเว็บเป็นกระบวนการตรงไปตรงมาของการเยี่ยมชมเว็บไซต์ทั้งหมดอย่างเป็นระบบ
ระหว่างการเยี่ยมชมของส ไปเดอ ร์ เวอร์ชันแคชของหน้าเว็บ (เนื้อหาบางส่วนหรือทั้งหมดที่จำเป็นในการแสดงผล) ที่จัดเก็บไว้ในหน่วยความจำการทำงานของเครื่องมือค้นหาจะถูกส่งไปยังผู้สอบถามอย่างรวดเร็ว หากการเยี่ยมชมล่าช้า เครื่องมือค้นหาสามารถทำหน้าที่เป็นพร็อกซีเว็บแทนได้ ในกรณีนี้ หน้าเว็บอาจแตกต่างจากคำค้นหาที่จัดทำดัชนี[ 38 ]หน้าเว็บที่แคชไว้จะมีลักษณะเหมือนกับเวอร์ชันที่มีคำที่จัดทำดัชนีไว้ก่อนหน้านี้ ดังนั้นเวอร์ชันแคชของหน้าเว็บจึงมีประโยชน์ต่อเว็บไซต์เมื่อหน้าเว็บจริงหายไป แต่ปัญหานี้ก็ถือเป็นรูปแบบหนึ่งของลิงก์เน่าเช่น กัน
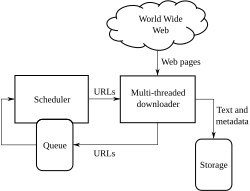
โดยทั่วไป เมื่อผู้ใช้ป้อนคำค้นหาลงในเครื่องมือค้นหา มักจะเป็นคำหลักเพียงไม่กี่คำ [ 40 ] ดัชนีมีชื่อของเว็บไซต์ที่มีคำหลักอยู่แล้ว และจะได้รับข้อมูลจากดัชนีทันที ภาระการประมวลผลที่แท้จริงอยู่ที่การสร้างหน้าเว็บที่เป็นรายการผลการค้นหา: ทุกหน้าในรายการทั้งหมดจะต้องได้รับการถ่วงน้ำหนักตามข้อมูลในดัชนี[ 38 ]จากนั้นรายการผลการค้นหาอันดับต้น ๆ จะต้องมีการค้นหา การสร้างใหม่ และการทำเครื่องหมายของส่วนย่อยที่แสดงบริบทของคำหลักที่ตรงกัน นี่เป็นเพียงส่วนหนึ่งของการประมวลผลที่หน้าเว็บผลการค้นหาแต่ละหน้าต้องการ และหน้าถัดไป (ถัดจากอันดับต้น ๆ) จะต้องมีการประมวลผลเพิ่มเติมอีก
นอกเหนือจากการค้นหาคำหลักแบบง่ายๆ แล้ว เครื่องมือค้นหายังมี GUIของตนเองหรือตัวดำเนินการที่ขับเคลื่อนด้วยคำสั่งและพารามิเตอร์การค้นหาเพื่อปรับปรุงผลการค้นหา สิ่งเหล่านี้ให้การควบคุมที่จำเป็นสำหรับผู้ใช้ที่เกี่ยวข้องในวงจรป้อนกลับที่ผู้ใช้สร้างขึ้นโดยการกรองและการให้น้ำหนักในขณะที่ปรับปรุงผลการค้นหา โดยพิจารณาจากหน้าแรกของผลการค้นหาครั้งแรก ตัวอย่างเช่น ตั้งแต่ปี 2007 เครื่องมือค้นหา Google.com อนุญาตให้กรองตามวันที่ได้โดยการคลิก "แสดงเครื่องมือค้นหา" ในคอลัมน์ซ้ายสุดของหน้าผลการค้นหาเริ่มต้น จากนั้นเลือกช่วงวันที่ที่ต้องการ[ 41 ]นอกจากนี้ยังสามารถให้น้ำหนักตามวันที่ได้ เนื่องจากแต่ละหน้ามีเวลาแก้ไข เครื่องมือค้นหาส่วนใหญ่รองรับการใช้ตัวดำเนินการบูลีน AND, OR และ NOT เพื่อช่วยให้ผู้ใช้ปรับปรุงคำค้นหา ตัวดำเนินการบูลีนใช้สำหรับการค้นหาตามตัวอักษรที่อนุญาตให้ผู้ใช้ปรับปรุงและขยายเงื่อนไขของการค้นหา เครื่องมือจะค้นหาคำหรือวลีตามที่ป้อนอย่างแม่นยำ เครื่องมือค้นหาบางตัวมีคุณสมบัติขั้นสูงที่เรียกว่าการค้นหาแบบใกล้เคียงซึ่งอนุญาตให้ผู้ใช้กำหนดระยะห่างระหว่างคำหลัก[ 38 ]นอกจากนี้ยังมีการค้นหาตามแนวคิดซึ่งการวิจัยเกี่ยวข้องกับการใช้การวิเคราะห์ทางสถิติในหน้าเว็บที่มีคำหรือวลีที่ผู้ใช้ค้นหา
ประโยชน์ของเครื่องมือค้นหาขึ้นอยู่กับความเกี่ยวข้องของชุดผลลัพธ์ที่ส่งคืน แม้ว่าจะมีเว็บเพจหลายล้านหน้าที่รวมคำหรือวลีเฉพาะ แต่บางหน้าอาจมีความเกี่ยวข้อง เป็นที่นิยม หรือมีอำนาจมากกว่าหน้าอื่นๆ เครื่องมือค้นหาส่วนใหญ่ใช้วิธีการจัดอันดับผลลัพธ์เพื่อให้ผลลัพธ์ "ที่ดีที่สุด" แสดงก่อน วิธีที่เครื่องมือค้นหาตัดสินใจว่าหน้าใดตรงกันที่สุด และควรแสดงผลลัพธ์ในลำดับใดนั้น แตกต่างกันไปในแต่ละเครื่องมือค้นหา[ 38 ]วิธีการเหล่านี้ยังเปลี่ยนแปลงไปตามกาลเวลาเมื่อการใช้งานอินเทอร์เน็ตเปลี่ยนแปลงไปและเทคนิคใหม่ๆ พัฒนาขึ้น มีเครื่องมือค้นหาหลักสองประเภทที่พัฒนาขึ้น: ประเภทหนึ่งคือระบบคำหลักที่กำหนดไว้ล่วงหน้าและจัดลำดับตามลำดับชั้นซึ่งมนุษย์ได้เขียนโปรแกรมไว้อย่างละเอียด อีกประเภทหนึ่งคือระบบที่สร้าง " ดัชนีผกผัน " โดยการวิเคราะห์ข้อความที่ค้นพบ รูปแบบแรกนี้พึ่งพาคอมพิวเตอร์เองในการทำงานส่วนใหญ่มากกว่า
เครื่องมือค้นหาบนเว็บส่วนใหญ่เป็นธุรกิจเชิงพาณิชย์ที่ได้รับการสนับสนุนจาก รายได้จาก การโฆษณาดังนั้นบางเครื่องมือค้นหาจึงอนุญาตให้ผู้โฆษณาจัดอันดับรายการของตนให้สูงขึ้นในผลการค้นหาโดยเสียค่าธรรมเนียม เครื่องมือค้นหาที่ไม่รับเงินสำหรับผลการค้นหาจะหารายได้จากการแสดงโฆษณาที่เกี่ยวข้องกับการค้นหาควบคู่ไปกับผลการค้นหาปกติ เครื่องมือค้นหาจะได้รับเงินทุกครั้งที่มีคนคลิกโฆษณาเหล่านี้[ 42 ]
การค้นหาในพื้นที่
การค้นหาในพื้นที่เป็นกระบวนการที่ช่วยเพิ่มประสิทธิภาพความพยายามของธุรกิจในท้องถิ่น โดยมุ่งเน้นที่การรับประกันผลการค้นหาที่สม่ำเสมอ ซึ่งมีความสำคัญเพราะผู้คนจำนวนมากตัดสินใจว่าจะไปที่ไหนและจะซื้ออะไรโดยอิงจากการค้นหา[ 43 ]
ส่วนแบ่งการตลาด
ณ เดือนมกราคม 2022 Googleเป็นเครื่องมือค้นหาที่มีผู้ใช้มากที่สุดในโลกอย่างเห็นได้ชัด โดยมีส่วนแบ่งการตลาด 90% และเครื่องมือค้นหาที่มีผู้ใช้มากเป็นอันดับสองของโลก ได้แก่Bingที่ 4%, Yandexที่ 2% และYahoo!ที่ 1% เครื่องมือค้นหาอื่นๆ ที่ไม่ได้ระบุไว้มีส่วนแบ่งการตลาดน้อยกว่า 3% [ 44 ]ในปี 2024 การครอบงำของ Google ถูกตัดสินว่าเป็นการผูกขาดที่ผิดกฎหมายในคดีที่กระทรวงยุติธรรมของสหรัฐอเมริกาเป็นผู้ฟ้องร้อง[ 45 ]
รัสเซีย
ณ ปลายปี 2023 ส่วนแบ่งการตลาดของเครื่องมือค้นหาในรัสเซียและเอเชียตะวันออกยังคงค่อนข้างคงที่ แต่มีการเปลี่ยนแปลงที่น่าสังเกตบางประการอันเนื่องมาจากการพัฒนาทางด้านภูมิรัฐศาสตร์และเทคโนโลยี
ในรัสเซีย Yandex ยังคงครองตลาดเครื่องมือค้นหาด้วยส่วนแบ่งประมาณ 73% ในขณะที่ Google มีส่วนแบ่งประมาณ 25% [ 46 ] Yandex ยังคงเป็นผู้เล่นหลักในบริการเฉพาะพื้นที่ รวมถึงการนำทาง การเรียกรถ และอีคอมเมิร์ซ ซึ่งช่วยเสริมสร้างระบบนิเวศของตน
เอเชียตะวันออก
ในประเทศจีน Baidu ยังคงเป็นเครื่องมือค้นหาชั้นนำ โดยมีส่วนแบ่งการตลาดประมาณ 59.3% ณ ต้นปี 2024 เครื่องมือค้นหาในประเทศอื่นๆ เช่น Sogou และ 360 Search มีส่วนแบ่งน้อยกว่า Google ยังคงไม่สามารถเข้าถึงได้ในจีนแผ่นดินใหญ่เนื่องจากปัญหาการเซ็นเซอร์ที่มีมายาวนาน โดยได้ถอนตัวออกจากตลาดจีนในปี 2010 หลังจากข้อพิพาทเกี่ยวกับการเซ็นเซอร์และความปลอดภัยทางไซเบอร์[ 47 ] [ 48 ]
Bing ซึ่งเป็นเครื่องมือค้นหาของ Microsoft ยังคงมีฐานลูกค้าเฉพาะกลุ่มในประเทศจีน โดยมีส่วนแบ่งการตลาดประมาณ 13.6% ทำให้เป็นหนึ่งในเครื่องมือค้นหาต่างประเทศไม่กี่แห่งที่ดำเนินการภายใต้ข้อจำกัดด้านกฎระเบียบในท้องถิ่น[ 49 ]
ในญี่ปุ่น ปัจจุบัน Google Japan ครองส่วนแบ่งการตลาดมากที่สุด (ประมาณ 76.2%) ในขณะที่ Yahoo! Japan ซึ่งดำเนินการโดย Z Holdings (บริษัทร่วมทุนระหว่าง SoftBank และ Naver) ยังคงมีส่วนแบ่งการตลาดประมาณ 15.8% [ 50 ]
นับตั้งแต่ การควบรวมกิจการของ Kakaoกับ Daum ในปี 2014 เครื่องมือค้นหาในประเทศได้ควบคุมตลาดเกาหลีใต้เกือบทั้งหมด Naver เป็นผู้นำด้วยส่วนแบ่งการตลาดส่วนใหญ่ ตามมาด้วย Daum [ 51 ]นับตั้งแต่การแยก Daum ออกจาก Kakao ในปี 2025 ส่วนแบ่งการตลาดของ Daum ในประเทศลดลงต่ำกว่า Google และ Bing แต่ Naver ยังคงครองส่วนแบ่งการตลาดส่วนใหญ่[ 52 ] Naver เป็นแหล่งรวบรวม "เนื้อหาที่ปรับแต่งเฉพาะท้องถิ่นจำนวนมาก" จากผู้ใช้ชาวเกาหลี[ 53 ]
ในไต้หวัน Google เป็นเครื่องมือค้นหาหลัก โดยครองส่วนแบ่งตลาดมากกว่า 93% โดยมี Yahoo! Taiwan และ Bing ตามหลังมาห่างๆ[ 54 ]
อคติของเครื่องมือค้นหา
แม้ว่าเครื่องมือค้นหาจะถูกตั้งโปรแกรมให้จัดอันดับเว็บไซต์โดยพิจารณาจากความนิยมและความเกี่ยวข้องบางส่วน แต่การศึกษาเชิงประจักษ์ชี้ให้เห็นถึงอคติทางการเมือง เศรษฐกิจ และสังคมต่างๆ ในข้อมูลที่เครื่องมือค้นหานำเสนอ[ 55 ] [ 56 ]และสมมติฐานพื้นฐานเกี่ยวกับเทคโนโลยี[ 57 ]อคติเหล่านี้อาจเป็นผลโดยตรงจากกระบวนการทางเศรษฐกิจและการค้า (เช่น บริษัทที่โฆษณาผ่านเครื่องมือค้นหาอาจได้รับความนิยมมากขึ้นใน ผล การค้นหาแบบออร์แกนิก ) และกระบวนการทางการเมือง (เช่น การลบผลการค้นหาเพื่อให้เป็นไปตามกฎหมายท้องถิ่น) [ 58 ]ตัวอย่างเช่น Google จะไม่แสดง เว็บไซต์ของ กลุ่มนีโอนาซี บางแห่ง ในฝรั่งเศสและเยอรมนี ซึ่งการปฏิเสธการฆ่าล้างเผ่าพันธุ์เป็นสิ่งผิดกฎหมาย
อคติอาจเป็นผลมาจากกระบวนการทางสังคมเช่นกัน เนื่องจากอัลกอริทึมของเครื่องมือค้นหามักถูกออกแบบมาเพื่อกีดกันมุมมองที่ไม่เป็นไปตามบรรทัดฐาน เพื่อให้ได้ผลลัพธ์ที่ "เป็นที่นิยม" มากกว่า[ 59 ]อัลกอริทึมการจัดทำดัชนีของเครื่องมือค้นหาหลักๆ มักจะเน้นไปที่การครอบคลุมเว็บไซต์ในสหรัฐอเมริกา มากกว่าเว็บไซต์จากประเทศอื่นๆ ที่ไม่ใช่สหรัฐอเมริกา[ 56 ]
Google Bombingเป็นตัวอย่างหนึ่งของความพยายามที่จะบิดเบือนผลการค้นหาเพื่อวัตถุประสงค์ทางการเมือง สังคม หรือเชิงพาณิชย์
นักวิชาการหลาย คนได้ศึกษาการเปลี่ยนแปลงทางวัฒนธรรมที่เกิดจากเครื่องมือค้นหา[ 60 ] และการนำเสนอหัวข้อที่เป็น ข้อถกเถียงบางเรื่องในผลลัพธ์ เช่นการก่อการร้ายในไอร์แลนด์ [ 61 ]การปฏิเสธการเปลี่ยนแปลงสภาพภูมิอากาศ [ 62 ]และทฤษฎีสมคบคิด[ 63 ]
ผลลัพธ์ที่ปรับแต่งเองและตัวกรองแบบฟองอากาศ
มีข้อกังวลเกิดขึ้นว่าเครื่องมือค้นหา เช่น Google และ Bing ให้ผลลัพธ์ที่ปรับแต่งตามประวัติกิจกรรมของผู้ใช้ ซึ่งนำไปสู่สิ่งที่Eli Pariserเรียก ว่าห้องสะท้อนเสียงหรือ ฟองสบู่กรองข้อมูลในปี 2011 [ 64 ]ข้อโต้แย้งคือเครื่องมือค้นหาและแพลตฟอร์มโซเชียลมีเดียใช้อัลกอริทึมเพื่อคาดเดาข้อมูลที่ผู้ใช้ต้องการเห็นโดยเลือกจากข้อมูลเกี่ยวกับผู้ใช้ (เช่น สถานที่ตั้ง พฤติกรรมการคลิกในอดีต และประวัติการค้นหา) ส่งผลให้เว็บไซต์มักแสดงเฉพาะข้อมูลที่สอดคล้องกับมุมมองในอดีตของผู้ใช้ ตามที่ Eli Pariser กล่าว ผู้ใช้จะได้รับมุมมองที่ขัดแย้งน้อยลงและถูกแยกออกจากกันทางปัญญาในฟองสบู่ข้อมูลของตนเอง นับตั้งแต่มีการระบุปัญหานี้ เครื่องมือค้นหาคู่แข่งได้เกิดขึ้นมาเพื่อหลีกเลี่ยงปัญหานี้โดยไม่ติดตามหรือ "สร้างฟองสบู่" ให้ผู้ใช้ เช่นDuckDuckGoอย่างไรก็ตาม นักวิชาการหลายคนตั้งคำถามถึงมุมมองของ Pariser โดยพบว่ามีหลักฐานเพียงเล็กน้อยสำหรับฟองสบู่กรองข้อมูล[ 65 ] [ 66 ] [ 67 ]ในทางตรงกันข้าม การศึกษาจำนวนหนึ่งที่พยายามตรวจสอบการมีอยู่ของฟิลเตอร์บับเบิลพบว่ามีการปรับแต่งส่วนบุคคลเพียงเล็กน้อยในการค้นหา[ 67 ]คนส่วนใหญ่พบเจอมุมมองที่หลากหลายเมื่อเรียกดูออนไลน์ และข่าวของ Google มีแนวโน้มที่จะส่งเสริมสำนักข่าวหลักที่ได้รับการยอมรับ[ 68 ] [ 66 ]
เครื่องมือค้นหาทางศาสนา
การเติบโตของอินเทอร์เน็ตและสื่ออิเล็กทรอนิกส์ทั่วโลกใน โลก อาหรับและมุสลิมในช่วงทศวรรษที่ผ่านมาได้กระตุ้นให้ผู้ที่นับถือศาสนาอิสลามในตะวันออกกลางและอนุทวีปเอเชียพยายามสร้างเครื่องมือค้นหาของตนเอง ซึ่งเป็นพอร์ทัลการค้นหาที่มีการกรองข้อมูลเพื่อให้ผู้ใช้สามารถทำการค้นหาได้อย่างปลอดภัย พอร์ทัลเว็บอิสลามเหล่านี้มีตัวกรอง การค้นหาที่ปลอดภัยมากกว่าปกติโดยจัดหมวดหมู่เว็บไซต์เป็น " ฮาลาล " หรือ " ฮาราม " ตามการตีความกฎหมายชารีอะห์ ImHalal เปิดตัวในเดือนกันยายน 2011 Halalgooglingเปิดตัวในเดือนกรกฎาคม 2013 พอร์ทัลเหล่านี้ใช้ตัวกรองฮารามกับคอลเลกชันจากGoogleและBing (และอื่นๆ) [ 69 ]
แม้ว่าการขาดการลงทุนและความล่าช้าของเทคโนโลยีในโลกมุสลิมจะขัดขวางความก้าวหน้าและขัดขวางความสำเร็จของเครื่องมือค้นหาอิสลาม โดยมุ่งเป้าไปที่ผู้บริโภคหลักคือผู้ที่นับถือศาสนาอิสลาม แต่โครงการต่างๆ เช่นMuxlim (เว็บไซต์ไลฟ์สไตล์มุสลิม) ได้รับเงินหลายล้านดอลลาร์จากนักลงทุนเช่น Rite Internet Ventures และก็ล้มเหลวเช่นกัน เครื่องมือค้นหาที่มุ่งเน้นศาสนาอื่นๆ ได้แก่ Jewogle ซึ่งเป็น Google เวอร์ชันของชาวยิว[ 70 ]และเครื่องมือค้นหาของชาวคริสต์ SeekFind.org SeekFind กรองเว็บไซต์ที่โจมตีหรือดูหมิ่นศาสนาของพวกเขา[ 71 ]
การส่งข้อมูลไปยังเครื่องมือค้นหา
การส่งเว็บไซต์ไปยังเครื่องมือค้นหาคือกระบวนการที่ผู้ดูแลเว็บไซต์ส่งเว็บไซต์ไปยังเครื่องมือค้นหาโดยตรง แม้ว่าบางครั้งการส่งเว็บไซต์ไปยังเครื่องมือค้นหาจะถูกนำเสนอว่าเป็นวิธีโปรโมตเว็บไซต์ แต่โดยทั่วไปแล้วไม่จำเป็น เพราะเครื่องมือค้นหาหลักๆ ใช้โปรแกรมรวบรวมข้อมูลเว็บ (web crawler) ที่จะค้นหาเว็บไซต์ส่วนใหญ่บนอินเทอร์เน็ตได้เองโดยไม่ต้องอาศัยความช่วยเหลือ พวกเขาสามารถส่งทีละหน้าเว็บ หรือส่งทั้งเว็บไซต์โดยใช้แผนผังเว็บไซต์ (sitemap)ก็ได้ แต่โดยปกติแล้วจำเป็นต้องส่งเฉพาะหน้าแรกของเว็บไซต์เท่านั้น เพราะเครื่องมือค้นหาสามารถรวบรวมข้อมูลเว็บไซต์ที่ออกแบบมาอย่างดีได้ มีเหตุผลอีกสองประการที่ต้องส่งเว็บไซต์หรือหน้าเว็บไปยังเครื่องมือค้นหา ได้แก่ การเพิ่มเว็บไซต์ใหม่ทั้งหมดโดยไม่ต้องรอให้เครื่องมือค้นหาค้นพบ และการอัปเดตข้อมูลเว็บไซต์หลังจากปรับปรุงการออกแบบครั้งใหญ่
ซอฟต์แวร์ส่งเว็บไซต์ไปยังเครื่องมือค้นหาบางตัวไม่เพียงแต่ส่งเว็บไซต์ไปยังเครื่องมือค้นหาหลายแห่งเท่านั้น แต่ยังเพิ่มลิงก์ไปยังเว็บไซต์จากหน้าเว็บของตนเองด้วย ซึ่งอาจดูเหมือนเป็นประโยชน์ในการเพิ่มอันดับ ของเว็บไซต์ เนื่องจากลิงก์ภายนอกเป็นหนึ่งในปัจจัยที่สำคัญที่สุดในการกำหนดอันดับของเว็บไซต์ อย่างไรก็ตาม จอห์น มุลเลอร์ จากGoogleได้กล่าวว่าสิ่งนี้ "อาจนำไปสู่ลิงก์ที่ไม่เป็นธรรมชาติจำนวนมากสำหรับเว็บไซต์ของคุณ" ซึ่งส่งผลเสียต่ออันดับของเว็บไซต์[ 72 ]
เปรียบเทียบกับการบุ๊กมาร์กทางสังคม
เมื่อเปรียบเทียบกับเครื่องมือค้นหา ระบบการบุ๊กมาร์กทางสังคมมีข้อดีหลายประการเหนือกว่าซอฟต์แวร์การค้นหาและจัดประเภททรัพยากรแบบอัตโนมัติแบบดั้งเดิม เช่นสไปเดอร์ ของ เครื่องมือค้นหา การ จัดประเภททรัพยากรอินเทอร์เน็ต (เช่น เว็บไซต์) ตามแท็กทั้งหมดนั้นทำโดยมนุษย์ ซึ่งเข้าใจเนื้อหาของทรัพยากร ต่างจากซอฟต์แวร์ที่พยายามกำหนดความหมายและคุณภาพของทรัพยากรโดยใช้อัลกอริทึม นอกจากนี้ ผู้คนยังสามารถค้นหาและบุ๊กมาร์กหน้าเว็บที่ยังไม่ถูกสังเกตหรือจัดทำดัชนีโดยสไปเดอร์เว็บได้[ 73 ]ยิ่งไปกว่านั้น ระบบการบุ๊กมาร์กทางสังคมสามารถจัดอันดับทรัพยากรตามจำนวนครั้งที่ผู้ใช้บุ๊กมาร์ก ซึ่งอาจเป็นตัวชี้ วัดที่มีประโยชน์มากกว่า สำหรับผู้ใช้ปลายทางมากกว่าระบบที่จัดอันดับทรัพยากรตามจำนวนลิงก์ภายนอกที่ชี้ไปยังทรัพยากรนั้น อย่างไรก็ตาม การจัดอันดับทั้งสองประเภทมีความเสี่ยงต่อการฉ้อโกง (ดูการเล่นเกมกับระบบ ) และทั้งสองประเภทจำเป็นต้องมีมาตรการทางเทคนิคเพื่อพยายามจัดการกับเรื่องนี้
เทคโนโลยี
อาร์ชี
เครื่องมือค้นหาเว็บเครื่องแรกคือArchieซึ่งสร้างขึ้นในปี พ.ศ. 2533 [ 74 ]โดยAlan Emtageนักศึกษาที่มหาวิทยาลัย McGillในมอนทรีออล
วิธีการหลักในการจัดเก็บและเรียกใช้ไฟล์คือผ่านโปรโตคอลการถ่ายโอนไฟล์ (FTP) ซึ่งเป็นโปรโตคอลการสื่อสารที่กำหนดวิธีการทั่วไปสำหรับคอมพิวเตอร์ในการแลกเปลี่ยนไฟล์ผ่านทางอินเทอร์เน็ต หลักการทำงานเป็นดังนี้: ผู้ดูแลระบบตัดสินใจที่จะทำให้ไฟล์จากคอมพิวเตอร์ของตนสามารถเข้าถึงได้ พวกเขาจะตั้งค่าโปรแกรมบนคอมพิวเตอร์ของตนเรียกว่าเซิร์ฟเวอร์ FTP เมื่อมีคนบนอินเทอร์เน็ตต้องการเรียกใช้ไฟล์จากคอมพิวเตอร์เครื่องนี้ พวกเขาจะเชื่อมต่อผ่านโปรแกรมอีกโปรแกรมหนึ่งที่เรียกว่าไคลเอ็นต์ FTP โปรแกรมไคลเอ็นต์ FTP ใดๆ ก็สามารถเชื่อมต่อกับโปรแกรมเซิร์ฟเวอร์ FTP ใดๆ ก็ได้ ตราบใดที่ทั้งโปรแกรมไคลเอ็นต์และเซิร์ฟเวอร์ปฏิบัติตามข้อกำหนดที่กำหนดไว้ในโปรโตคอล FTP อย่างครบถ้วน
ในระยะแรก ผู้ที่ต้องการแบ่งปันไฟล์ต้องตั้งค่าเซิร์ฟเวอร์ FTP เพื่อให้ผู้อื่นสามารถเข้าถึงไฟล์ได้ ต่อมา เว็บไซต์ FTP แบบ "ไม่ระบุตัวตน" ได้กลายเป็นแหล่งเก็บไฟล์ ทำให้ผู้ใช้ทุกคนสามารถโพสต์และเรียกดูไฟล์ได้
ถึงแม้จะมีเว็บไซต์เก็บถาวรแล้ว ไฟล์สำคัญจำนวนมากก็ยังคงกระจัดกระจายอยู่บนเซิร์ฟเวอร์ FTP ขนาดเล็ก การค้นหาไฟล์เหล่านี้ต้องอาศัยการบอกต่อแบบปากต่อปากในโลกอินเทอร์เน็ต กล่าวคือ มีคนส่งอีเมลไปแจ้งในกลุ่มข้อความหรือในเว็บบอร์ดว่ามีไฟล์นั้นให้ดาวน์โหลดแล้ว
Archie เปลี่ยนแปลงทุกอย่าง มันรวมตัวรวบรวมข้อมูลแบบสคริปต์ซึ่งดึงรายการเว็บไซต์ไฟล์ FTP นิรนามเข้ากับตัวจับคู่การแสดงออกปกติเพื่อดึงชื่อไฟล์ที่ตรงกับคำค้นหาของผู้ใช้ (4) กล่าวอีกนัยหนึ่ง ตัวรวบรวมข้อมูลของ Archie ค้นหาเว็บไซต์ FTP ทั่วทั้งอินเทอร์เน็ตและจัดทำดัชนีไฟล์ทั้งหมดที่พบ ตัวจับคู่การแสดงออกปกติช่วยให้ผู้ใช้สามารถเข้าถึงฐานข้อมูลได้[ 75 ]
เวโรนิกา
ในปี พ.ศ. 2536 กลุ่มบริการคอมพิวเตอร์ระบบของมหาวิทยาลัยเนวาดาได้พัฒนาVeronica ขึ้น มา[ 74 ]มันถูกสร้างขึ้นมาเป็นอุปกรณ์ค้นหาประเภทหนึ่งที่คล้ายกับ Archie แต่สำหรับไฟล์ Gopher บริการค้นหา Gopher อีกตัวหนึ่งชื่อJugheadปรากฏขึ้นในเวลาต่อมาเล็กน้อย ซึ่งอาจมีจุดประสงค์เพียงอย่างเดียวเพื่อทำให้กลุ่มการ์ตูนสามตัวสมบูรณ์ Jughead เป็นตัวย่อของ Jonzy's Universal Gopher Hierarchy Excavation and Display แม้ว่าเช่นเดียวกับ Veronica เราอาจสันนิษฐานได้อย่างปลอดภัยว่าผู้สร้างได้เลือกตัวย่อนี้โดยบังเอิญ ฟังก์ชันการทำงานของ Jughead เกือบจะเหมือนกับ Veronica แม้ว่าจะดูหยาบกว่าเล็กน้อย[ 75 ]
นักเดินทางผู้เดียวดาย
World Wide Web Wandererซึ่งพัฒนาโดย Matthew Gray ในปี 1993 [ 76 ]เป็นหุ่นยนต์ตัวแรกบนเว็บและได้รับการออกแบบมาเพื่อติดตามการเติบโตของเว็บ ในตอนแรก Wanderer นับเฉพาะเว็บเซิร์ฟเวอร์ แต่หลังจากเปิดตัวได้ไม่นาน ก็เริ่มบันทึก URL ไปเรื่อยๆ ฐานข้อมูลของ URL ที่บันทึกไว้กลายเป็น Wandex ซึ่งเป็นฐานข้อมูลเว็บแรก
โปรแกรม Wanderer ของ Matthew Gray ก่อให้เกิดข้อถกเถียงอย่างมากในเวลานั้น ส่วนหนึ่งเป็นเพราะเวอร์ชันแรกๆ ของซอฟต์แวร์แพร่กระจายไปทั่วอินเทอร์เน็ตอย่างรวดเร็วและทำให้ประสิทธิภาพการทำงานของเครือข่ายโดยรวมลดลงอย่างเห็นได้ชัด การลดลงของประสิทธิภาพนี้เกิดขึ้นเนื่องจาก Wanderer เข้าถึงหน้าเว็บเดียวกันหลายร้อยครั้งต่อวัน ต่อมา Wanderer ก็ปรับปรุงวิธีการทำงาน แต่ข้อถกเถียงเกี่ยวกับว่าหุ่นยนต์ดีหรือไม่ดีต่ออินเทอร์เน็ตก็ยังคงอยู่
เพื่อตอบสนองต่อ Wanderer นั้น Martijn Koster ได้สร้าง Archie-Like Indexing of the Web หรือ ALIWEB ขึ้นในเดือนตุลาคม ปี 1993 ดังที่ชื่อบ่งบอก ALIWEB คือสิ่งที่เทียบเท่ากับ Archie ในระบบ HTTP และด้วยเหตุนี้ มันจึงยังคงมีความเป็นเอกลักษณ์ในหลายๆ ด้าน
ALIWEB ไม่มีบอทค้นหาเว็บ แต่ผู้ดูแลเว็บของเว็บไซต์ที่เข้าร่วมจะโพสต์ข้อมูลดัชนีของตนเองสำหรับแต่ละหน้าที่ต้องการให้แสดง ข้อดีของวิธีนี้คือผู้ใช้สามารถอธิบายเว็บไซต์ของตนเองได้ และบอทจะไม่วิ่งไปมากินแบนด์วิดท์ของเน็ต ข้อเสียของ ALIWEB เป็นปัญหามากกว่าในปัจจุบัน ข้อเสียหลักคือต้องส่งไฟล์ดัชนีพิเศษ ผู้ใช้ส่วนใหญ่ไม่เข้าใจวิธีการสร้างไฟล์ดังกล่าว ดังนั้นพวกเขาจึงไม่ส่งหน้าเว็บของตน ทำให้ฐานข้อมูลมีขนาดค่อนข้างเล็ก ซึ่งหมายความว่าผู้ใช้มีแนวโน้มที่จะค้นหาใน ALIWEB น้อยกว่าเว็บไซต์ขนาดใหญ่ที่ใช้บอท ปัญหา Catch-22 นี้ได้รับการแก้ไขบ้างแล้วโดยการรวมฐานข้อมูลอื่น ๆ เข้ากับการค้นหาของ ALIWEB แต่ก็ยังไม่ได้รับความนิยมเท่ากับเครื่องมือค้นหาเช่น Yahoo! หรือ Lycos [ 75 ]
ตื่นเต้น
Exciteซึ่งเดิมชื่อ Architext เริ่มต้นโดยนักศึกษาปริญญาตรีของ Stanford จำนวน 6 คนในเดือนกุมภาพันธ์ พ.ศ. 2536 แนวคิดของพวกเขาคือการใช้การวิเคราะห์ทางสถิติของความสัมพันธ์ของคำเพื่อให้การค้นหาข้อมูลจำนวนมากบนอินเทอร์เน็ตมีประสิทธิภาพมากขึ้น โครงการของพวกเขาได้รับการสนับสนุนทางการเงินอย่างเต็มที่ในช่วงกลางปี พ.ศ. 2536 เมื่อได้รับการสนับสนุนทางการเงินแล้ว พวกเขาก็ได้ปล่อยซอฟต์แวร์ค้นหาเวอร์ชันสำหรับเว็บมาสเตอร์เพื่อใช้บนเว็บไซต์ของตนเอง ในขณะนั้น ซอฟต์แวร์นี้มีชื่อว่า Architext แต่ปัจจุบันใช้ชื่อว่า Excite for Web Servers [ 75 ]
Excite เป็นเครื่องมือค้นหาเชิงพาณิชย์ที่จริงจังเครื่องแรกที่เปิดตัวในปี 1995 [ 77 ]ได้รับการพัฒนาที่ Stanford และถูกซื้อโดย @Home ในราคา 6.5 พันล้านดอลลาร์ ในปี 2001 Excite และ @Home ล้มละลาย และInfoSpaceซื้อ Excite ในราคา 10 ล้านดอลลาร์
การวิเคราะห์การค้นหาเว็บครั้งแรกบางส่วนดำเนินการกับบันทึกการค้นหาจาก Excite [ 78 ] [ 40 ]
ยาฮู!
ในเดือนเมษายน ปี 1994 เดวิด ฟิโลและเจอร์รี หยาง นักศึกษาปริญญาเอกสองคนจากมหาวิทยาลัยสแตนฟอร์ด ได้สร้างเพจขึ้นมาหลายเพจซึ่งได้รับความนิยมพอสมควร พวกเขาเรียกกลุ่มเพจเหล่านั้นว่าYahoo!คำอธิบายอย่างเป็นทางการเกี่ยวกับการเลือกชื่อนี้คือ พวกเขาคิดว่าตัวเองเป็นพวก Yahoo สองคน
เมื่อจำนวนลิงก์เพิ่มขึ้นและหน้าเว็บเริ่มได้รับจำนวนการเข้าชมหลายพันครั้งต่อวัน ทีมงานจึงสร้างวิธีการจัดระเบียบข้อมูลให้ดียิ่งขึ้น เพื่อช่วยในการค้นหาข้อมูล Yahoo! (www.yahoo.com) จึงกลายเป็นสารบบที่สามารถค้นหาได้ ฟีเจอร์การค้นหาเป็นเพียงเครื่องมือค้นหาฐานข้อมูลแบบง่ายๆ เนื่องจากข้อมูลใน Yahoo! ถูกป้อนและจัดหมวดหมู่ด้วยตนเอง Yahoo! จึงไม่ได้ถูกจัดประเภทเป็นเครื่องมือค้นหาอย่างแท้จริง แต่โดยทั่วไปแล้วถือว่าเป็นสารบบที่สามารถค้นหาได้ ต่อมา Yahoo! ได้ทำให้กระบวนการรวบรวมและจัดหมวดหมู่บางส่วนเป็นไปโดยอัตโนมัติ ทำให้ความแตกต่างระหว่างเครื่องมือค้นหาและสารบบเริ่มเลือนหายไป
โปรแกรม Wanderer บันทึกได้เฉพาะ URL เท่านั้น ซึ่งทำให้ยากต่อการค้นหาสิ่งที่ไม่ได้รับการอธิบายอย่างชัดเจนใน URL เนื่องจาก URL นั้นค่อนข้างคลุมเครืออยู่แล้ว จึงไม่เป็นประโยชน์ต่อผู้ใช้ทั่วไป การค้นหาใน Yahoo! หรือ Galaxy มีประสิทธิภาพมากกว่ามาก เพราะมีข้อมูลรายละเอียดเพิ่มเติมเกี่ยวกับเว็บไซต์ที่ถูกจัดทำดัชนีไว้
ไลคอส
ในช่วงเดือนกรกฎาคม ปี 1994 ไมเคิล มอลดิน ซึ่งลาพักงานจากมหาวิทยาลัยคาร์เนกีเมลลอน ได้พัฒนาเครื่องมือค้นหา Lycos ขึ้นมา
ประเภทของเครื่องมือค้นหาบนเว็บ
เครื่องมือค้นหาบนเว็บเป็นเว็บไซต์ที่มีฟังก์ชันในการค้นหาเนื้อหาที่จัดเก็บไว้บนเว็บไซต์อื่น ๆ วิธีการทำงานของเครื่องมือค้นหาแต่ละชนิดแตกต่างกัน แต่ทั้งหมดก็ทำหน้าที่พื้นฐานสามอย่าง[ 79 ]
- ค้นหาและเลือกเนื้อหาทั้งหมดหรือบางส่วนโดยอิงจากคำหลักที่ระบุ
- การจัดทำดัชนีเนื้อหาและการอ้างอิงตำแหน่งที่พบ
- อนุญาตให้ผู้ใช้ค้นหาคำหรือกลุ่มคำที่พบในดัชนีนั้น
กระบวนการเริ่มต้นเมื่อผู้ใช้ป้อนคำสั่งค้นหาลงในระบบผ่านทางอินเทอร์เฟซที่ให้ไว้
| พิมพ์ | ตัวอย่าง | คำอธิบาย |
|---|---|---|
| ธรรมดา | แคตตาล็อกห้องสมุด | ค้นหาโดยใช้คำสำคัญ ชื่อเรื่อง ผู้แต่ง ฯลฯ |
| อิงตามข้อความ | Google, Bing, Yahoo! | ค้นหาด้วยคำหลัก จำกัดการค้นหาโดยใช้คำค้นหาในภาษาธรรมชาติ |
| ด้วยเสียง | Google, Bing, Yahoo! | ค้นหาด้วยคำหลัก จำกัดการค้นหาโดยใช้คำค้นหาในภาษาธรรมชาติ |
| การค้นหามัลติมีเดีย | QBIC, WebSeek, SaFe | ค้นหาตามลักษณะที่ปรากฏ (รูปทรง สี ฯลฯ) |
| ถาม-ตอบ | Stack Exchange , NSIR | ค้นหาด้วยภาษาธรรมชาติ (แบบจำกัด) |
| ระบบการจัดกลุ่ม | วิวิซิโม, คลัสตี้, โทโกดา | |
| ระบบวิจัย | ลีเมอร์, นัตช์ |
โดยพื้นฐานแล้วเครื่องมือค้นหามีอยู่ 3 ประเภท ได้แก่ เครื่องมือค้นหาที่ใช้หุ่นยนต์ (เรียกว่าcrawlerหรือ spider) เครื่องมือค้นหาที่ใช้ข้อมูลจากมนุษย์ และเครื่องมือค้นหาที่เป็นลูกผสมระหว่างทั้งสองแบบ
เครื่องมือค้นหาแบบใช้โปรแกรมรวบรวมข้อมูล (Crawler) คือเครื่องมือค้นหาที่ใช้ซอฟต์แวร์อัตโนมัติ (เรียกว่า Crawler) เข้าไปเยี่ยมชมเว็บไซต์ อ่านข้อมูลบนเว็บไซต์ อ่านเมตาแท็กของเว็บไซต์ และติดตามลิงก์ที่เว็บไซต์นั้นเชื่อมโยงไป รวมถึงการจัดทำดัชนีเว็บไซต์ที่เชื่อมโยงทั้งหมดด้วย จากนั้น Crawler จะส่งข้อมูลทั้งหมดกลับไปยังที่เก็บข้อมูลส่วนกลางเพื่อทำการจัดทำดัชนี Crawler จะกลับไปตรวจสอบเว็บไซต์เป็นระยะๆ เพื่อดูว่ามีข้อมูลใดเปลี่ยนแปลงไปบ้าง ความถี่ในการตรวจสอบนี้ขึ้นอยู่กับผู้ดูแลระบบของเครื่องมือค้นหา
เครื่องมือค้นหาที่ใช้มนุษย์เป็นผู้ขับเคลื่อนนั้น อาศัยมนุษย์ในการส่งข้อมูล ซึ่งจะถูกจัดทำดัชนีและจัดหมวดหมู่ในภายหลัง เฉพาะข้อมูลที่ส่งเข้ามาเท่านั้นที่จะถูกใส่เข้าไปในดัชนี
ในทั้งสองกรณี เมื่อผู้ใช้ค้นหาข้อมูลในเครื่องมือค้นหา พวกเขากำลังค้นหาผ่านดัชนีที่เครื่องมือค้นหาสร้างขึ้น ไม่ใช่การค้นหาบนเว็บโดยตรง ดัชนีเหล่านี้เป็นฐานข้อมูลขนาดใหญ่ที่รวบรวม จัดเก็บ และนำมาค้นหาในภายหลัง นี่จึงอธิบายได้ว่าทำไมบางครั้งการค้นหาในเครื่องมือค้นหาเชิงพาณิชย์ เช่น Yahoo! หรือ Google จึงแสดงผลลัพธ์ที่เป็นลิงก์เสีย เนื่องจากผลการค้นหาขึ้นอยู่กับดัชนี หากดัชนีไม่ได้รับการอัปเดตนับตั้งแต่หน้าเว็บนั้นใช้งานไม่ได้แล้ว เครื่องมือค้นหาจะยังคงถือว่าหน้าเว็บนั้นเป็นลิงก์ที่ใช้งานได้อยู่ แม้ว่าจะใช้งานไม่ได้แล้วก็ตาม และจะยังคงเป็นเช่นนั้นจนกว่าดัชนีจะได้รับการอัปเดต
เครื่องมือค้นหาแต่ละตัวให้ผลลัพธ์ที่แตกต่างกัน ส่วนหนึ่งเป็นเพราะความแตกต่างของดัชนี ซึ่งขึ้นอยู่กับสิ่งที่สไปเดอร์ค้นพบหรือสิ่งที่มนุษย์ป้อนเข้าไป แต่ที่สำคัญกว่านั้นคือ เครื่องมือค้นหาแต่ละตัวไม่ได้ใช้อัลกอริทึมเดียวกันในการค้นหาผ่านดัชนี อัลกอริทึมคือสิ่งที่เครื่องมือค้นหาใช้ในการพิจารณาความเกี่ยวข้องของข้อมูลในดัชนีกับสิ่งที่ผู้ใช้กำลังค้นหา
หนึ่งในองค์ประกอบที่อัลกอริทึมของเครื่องมือค้นหาตรวจสอบคือความถี่และตำแหน่งของคำหลักในหน้าเว็บ โดยทั่วไปแล้วคำหลักที่มีความถี่สูงกว่าจะถูกพิจารณาว่ามีความเกี่ยวข้องมากกว่า แต่เทคโนโลยีของเครื่องมือค้นหากำลังพัฒนาให้มีความซับซ้อนมากขึ้นเพื่อพยายามยับยั้งสิ่งที่เรียกว่าการยัดคำหลัก หรือการสแปมดัชนี (keyword stuffing หรือspamdexing )
อีกหนึ่งองค์ประกอบทั่วไปที่อัลกอริทึมวิเคราะห์คือ วิธีที่หน้าเว็บเชื่อมโยงไปยังหน้าเว็บอื่นๆ ในเว็บ การวิเคราะห์ว่าหน้าเว็บเชื่อมโยงกันอย่างไร ทำให้เครื่องมือค้นหาสามารถระบุได้ทั้งเนื้อหาของหน้าเว็บ (หากคำหลักของหน้าเว็บที่เชื่อมโยงคล้ายกับคำหลักในหน้าเว็บต้นฉบับ) และว่าหน้าเว็บนั้น "สำคัญ" และสมควรได้รับการจัดอันดับที่สูงขึ้นหรือไม่ เช่นเดียวกับที่เทคโนโลยีมีความซับซ้อนมากขึ้นเรื่อยๆ ในการเพิกเฉยต่อการยัดเยียดคำหลัก เทคโนโลยีก็ฉลาดขึ้นเรื่อยๆ เช่นกันในการจับผิดผู้ดูแลเว็บไซต์ที่สร้างลิงก์ปลอมเข้าไปในเว็บไซต์ของตนเพื่อสร้างอันดับปลอม
เครื่องมือค้นหาบนเว็บสมัยใหม่เป็นระบบซอฟต์แวร์ที่ซับซ้อนมาก ซึ่งใช้เทคโนโลยีที่พัฒนามาหลายปีแล้ว มีซอฟต์แวร์เครื่องมือค้นหาหลายประเภทที่แตกต่างกันไปตามความต้องการในการ "เรียกดู" เฉพาะด้าน ได้แก่ เครื่องมือค้นหาบนเว็บ (เช่นGoogle ) เครื่องมือค้นหาฐานข้อมูลหรือข้อมูลที่มีโครงสร้าง (เช่น Dieselpoint) และเครื่องมือค้นหาแบบผสมหรือเครื่องมือค้นหาสำหรับองค์กร เครื่องมือค้นหาที่แพร่หลาย เช่น Google และYahoo!ใช้คอมพิวเตอร์หลายแสนเครื่องในการประมวลผลหน้าเว็บหลายล้านล้านหน้าเพื่อแสดงผลลัพธ์ที่ตรงเป้าหมาย เนื่องจากปริมาณการค้นหาและการประมวลผลข้อความที่สูงมาก ซอฟต์แวร์จึงจำเป็นต้องทำงานในสภาพแวดล้อมที่มีการกระจายตัวสูงและมีความซ้ำซ้อนสูง
เครื่องมือค้นหาอีกประเภทหนึ่งคือเครื่องมือค้นหาทางวิทยาศาสตร์ เครื่องมือค้นหาเหล่านี้ใช้ค้นหาเอกสารทางวิทยาศาสตร์ ตัวอย่างที่โดดเด่นที่สุดคือ Google Scholar นักวิจัยกำลังทำงานเพื่อปรับปรุงเทคโนโลยีเครื่องมือค้นหาโดยทำให้เข้าใจองค์ประกอบเนื้อหาของบทความ เช่น การดึงโครงสร้างเชิงทฤษฎีหรือผลการวิจัยที่สำคัญ[ 80 ]
ดูเพิ่มเติม
- การเปรียบเทียบเครื่องมือค้นหา
- การกลั่นกรองเนื้อหา
- ฟิลเตอร์บับเบิล
- เอฟเฟกต์ของ Google
- การค้นหาข้อมูล
- การใช้เครื่องมือค้นหาบนเว็บในห้องสมุด
- มันพินท์
- รายชื่อเครื่องมือค้นหา
- รายชื่อฐานข้อมูลทางวิชาการและเครื่องมือค้นหา
- การตอบคำถาม
- ผลกระทบจากการบิดเบือนผลการค้นหาของเครื่องมือค้นหา
- ความเป็นส่วนตัวของเครื่องมือค้นหา
- เว็บเชิงความหมาย
- โปรแกรมตรวจสอบการสะกดคำ
- ลำดับเหตุการณ์ของเครื่องมือค้นหาบนเว็บ
- เครื่องมือพัฒนาเว็บ
- การค้นหาเว็บ
- Wikipedia:Search engine testสำหรับบทช่วยสอนเกี่ยวกับการใช้เครื่องมือค้นหาเพื่อค้นคว้าบทความในวิกิพีเดีย
อ่านเพิ่มเติม
- Steve Lawrence; C. Lee Giles (1999). " การเข้าถึงข้อมูลบนเว็บ" Nature . 400 (6740): 107–9 . Bibcode : 1999Natur.400..107L . doi : 10.1038/21987 . PMID 10428673. S2CID 4347646 .
- Bing Liu (2007), การขุดค้นข้อมูลบนเว็บ: การสำรวจไฮเปอร์ลิงก์ เนื้อหา และข้อมูลการใช้งาน Springer , ISBN 3-540-37881-2
- Bar-Ilan, J. (2004). การใช้เครื่องมือค้นหาบนเว็บในการวิจัยวิทยาศาสตร์สารสนเทศ. ARIST, 38, 231–288.
- เลเวน, มาร์ค (2005). บทนำเกี่ยวกับเครื่องมือค้นหาและการนำทางบนเว็บ . เพียร์สัน.
- ฮ็อค, แรนดอล์ฟ (2007). คู่มือการค้นหาสุดขั้ว .ISBN 978-0-910965-76-7
- Javed Mostafa (กุมภาพันธ์ 2548). "การค้นหาเว็บที่ดีกว่า" Scientific American . 292 (2): 66– 73. Bibcode : 2005SciAm.292b..66M . doi : 10.1038/scientificamerican0205-66 .
- Ross, Nancy; Wolfram, Dietmar (2000). "การค้นหาของผู้ใช้ปลายทางบนอินเทอร์เน็ต: การวิเคราะห์หัวข้อคู่คำที่ส่งไปยังเครื่องมือค้นหา Excite" วารสารของสมาคม วิทยาศาสตร์สารสนเทศแห่งอเมริกา51 (10): 949– 958. doi : 10.1002/1097-4571(2000)51:10<949::AID-ASI70>3.0.CO;2-5 .
- Xie, M. และคณะ (1998). "มิติคุณภาพของเครื่องมือค้นหาทางอินเทอร์เน็ต". วารสารวิทยาศาสตร์สารสนเทศ . 24 (5): 365– 372. doi : 10.1177/016555159802400509 . S2CID 34686531 .
- การค้นหาข้อมูล: การนำไปใช้และการประเมินผลเครื่องมือค้นหาสำนักพิมพ์ MIT Press. 2010. เก็บถาวรจากต้นฉบับเมื่อวันที่ 5 ตุลาคม 2020.สืบค้นเมื่อ7 สิงหาคม 2010 .
- เยโอ ชินจอง (2023) เบื้องหลังช่องค้นหา: Google และอุตสาหกรรมอินเทอร์เน็ตระดับโลก (สำนักพิมพ์มหาวิทยาลัยอิลลินอยส์, 2023) ISBN 0-252-08712-7JSTOR 4116455
ลิงก์ภายนอก
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ เครื่องมือค้นหา
เครื่องมือ ค้นหาบนเว็บ หรือ เครื่องมือค้นหาบนอินเทอร์เน็ต คือ ระบบซอฟต์แวร์ ที่ให้ ไฮเปอร์ลิงก์ ไปยัง หน้าเว็บ และข้อมูลที่เกี่ยวข้องอื่นๆ บน เว็บ เพื่อตอบสนองต่อ คำค้นหา...
ประวัติศาสตร์
ลำดับเหตุการณ์ ( รายการทั้งหมด ) ปี เครื่องยนต์ สถานะปัจจุบัน พ.ศ. 2536 แคตตาล็อก W3 ไม่ใช้งาน อาลีเว็บ ไม่ใช้งาน จัมป์สเตชั่น ไม่ใช้งาน เวิร์ม WWW ไม่ใช้งาน พ.ศ. 2537 เว็บครอว์เลอร์ คล่องแคล่ว โก.
ก่อนปี 1990
ในปี พ.ศ. 2488 Vannevar Bush ได้อธิบายระบบการค้นหาข้อมูลที่จะช่วยให้ผู้ใช้สามารถเข้าถึงข้อมูลจำนวนมหาศาลได้ทั้งหมดจากโต๊ะทำงานเพียงโต๊ะเดียว ซึ่งเขาเรียกว่าmemex [ 2 ] เขา ได้อธิบายระบบนี้ในบทความชื่อ " As We May Think " ใน The Atlantic Monthly [ 3 ] Memex...
ทศวรรษ 1990: กำเนิดของเครื่องมือค้นหา
เครื่องมือค้นหาอินเทอร์เน็ตเครื่องแรกมีมาก่อนการเปิดตัวเว็บในเดือนธันวาคม พ.ศ. 2533: การค้นหาผู้ใช้ WHOIS มีมาตั้งแต่ปี พ.ศ. 2525 [ 7 ] และ การค้นหาผู้ใช้แบบหลายเครือข่าย Knowbot Information Service ได้ถูกนำมาใช้ครั้งแรกในปี พ.ศ.