อ่าน 7 นาที
การกู้คืนระบบไอทีจากภัยพิบัติ
การกู้คืนระบบไอทีหลังภัยพิบัติ (เรียกสั้น ๆ ว่า การกู้คืนระบบหลังภัยพิบัติ ( DR )) คือกระบวนการบำรุงรักษาหรือฟื้นฟู โครงสร้างพื้นฐาน และ ระบบ ที่สำคัญ หลังจาก ภัยพิบัติ...
การกู้คืนระบบไอทีจากภัยพิบัติ
การกู้คืนระบบไอทีหลังภัยพิบัติ (เรียกสั้น ๆ ว่าการกู้คืนระบบหลังภัยพิบัติ ( DR )) คือกระบวนการบำรุงรักษาหรือฟื้นฟูโครงสร้างพื้นฐานและระบบ ที่สำคัญ หลังจากภัยพิบัติทางธรรมชาติหรือที่เกิดจากมนุษย์ เช่น พายุหรือการสู้รบ DR ใช้ นโยบาย เครื่องมือ และขั้นตอน โดยมุ่งเน้นที่ระบบไอทีที่สนับสนุนฟังก์ชันทางธุรกิจที่สำคัญ[ 1 ]ซึ่งเกี่ยวข้องกับการรักษาส่วนสำคัญทั้งหมดของธุรกิจให้ทำงานได้แม้จะมีเหตุการณ์หยุดชะงักครั้งใหญ่ ดังนั้นจึงถือได้ว่าเป็นส่วนย่อยของความต่อเนื่องทางธุรกิจ (BC) [ 2 ] [ 3 ] DR ถือว่าไซต์หลักไม่สามารถกู้คืนได้ทันทีและจะกู้คืนข้อมูลและบริการไปยังไซต์สำรอง
ความต่อเนื่องของบริการไอที
ความต่อเนื่องของบริการไอที (ITSC)เป็นส่วนย่อยของ BCP [ 4 ]ซึ่งอาศัยตัวชี้วัด (มักใช้เป็นตัวชี้วัดความเสี่ยงหลัก ) ของเป้าหมายจุด/เวลาการกู้คืน ครอบคลุมถึงการวางแผนการกู้คืนระบบไอทีจากภัยพิบัติและการวางแผนความยืดหยุ่นของระบบไอที ในวงกว้าง นอกจากนี้ยังรวมถึงโครงสร้างพื้นฐานและบริการ ไอที ที่เกี่ยวข้องกับการสื่อสารเช่นโทรศัพท์และการสื่อสารข้อมูล[ 5 ] [ 6 ]
หลักการของไซต์สำรองข้อมูล
การวางแผนรวมถึงการจัดเตรียมสถานที่สำรอง ไม่ว่าจะเป็นสถานที่ "พร้อมใช้งาน" (ใช้งานได้ก่อนเกิดภัยพิบัติ) "พร้อมใช้งานเมื่อจำเป็น" (พร้อมที่จะเริ่มใช้งาน) หรือ "พร้อมใช้งานเมื่อต้องดำเนินการอย่างมากเพื่อเริ่มใช้งาน) และสถานที่สำรองพร้อมฮาร์ดแวร์ตามความจำเป็นเพื่อความต่อเนื่อง
ในปี 2551 สถาบันมาตรฐานอังกฤษได้เปิดตัวมาตรฐานเฉพาะที่สนับสนุนมาตรฐานความต่อเนื่องทางธุรกิจBS 25999ซึ่งมีชื่อว่า BS25777 โดยเฉพาะเพื่อปรับความต่อเนื่องของคอมพิวเตอร์ให้สอดคล้องกับความต่อเนื่องทางธุรกิจ มาตรฐานนี้ถูกยกเลิกหลังจากมีการเผยแพร่ ISO/IEC 27301 ในเดือนมีนาคม 2554 ซึ่งเป็น "เทคนิคด้านความปลอดภัย — แนวทางสำหรับความพร้อมของเทคโนโลยีสารสนเทศและการสื่อสารเพื่อความต่อเนื่องทางธุรกิจ" [ 7 ]
ITILได้กำหนดคำศัพท์เหล่านี้ไว้บางส่วน[ 8 ]
เป้าหมายเวลาในการฟื้นตัว
วัตถุประสงค์เวลาในการกู้คืน (RTO) [ 9 ] [ 10 ]คือระยะเวลาเป้าหมายและระดับการบริการที่กระบวนการทางธุรกิจจะต้องได้รับการกู้คืนหลังจากเกิดการหยุดชะงัก เพื่อหลีกเลี่ยงการหยุดชะงักของความต่อเนื่องทางธุรกิจ[ 11 ]
ตามระเบียบวิธีวางแผนความต่อเนื่องทางธุรกิจ RTO จะถูกกำหนดขึ้นในระหว่างการวิเคราะห์ผลกระทบทางธุรกิจ (BIA) โดยเจ้าของกระบวนการ ซึ่งรวมถึงการระบุช่วงเวลาสำหรับวิธีการแก้ไขปัญหาทางเลือกหรือวิธีการแก้ไขปัญหาด้วยตนเอง
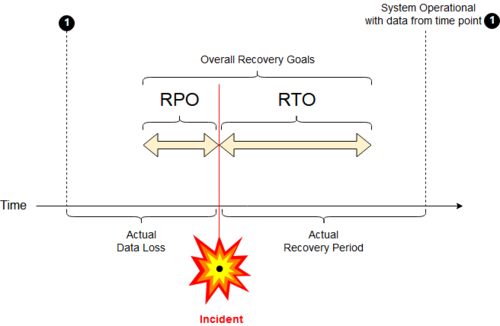
RTO เป็นส่วนเสริมของ RPO ขีดจำกัดของ ประสิทธิภาพ ITSC ที่ยอมรับได้หรือ "ทนได้" นั้นวัดโดย RTO และ RPO ในแง่ของเวลาที่สูญเสียไปจากการทำงานของกระบวนการทางธุรกิจปกติและข้อมูลที่สูญหายหรือไม่ได้รับการสำรองข้อมูลในช่วงเวลานั้น[ 11 ] [ 12 ]
เวลาฟื้นตัวจริง
Recovery Time Actual (RTA)เป็นตัวชี้วัดที่สำคัญสำหรับความต่อเนื่องทางธุรกิจและการกู้คืนจากภัยพิบัติ[ 9 ]
กลุ่มความต่อเนื่องทางธุรกิจจะทำการซ้อม (หรือสถานการณ์จริง) ตามเวลาที่กำหนด ซึ่งในระหว่างนั้น RTA จะถูกกำหนดและปรับปรุงตามความจำเป็น[ 9 ]
เป้าหมายจุดฟื้นตัว
เป้าหมาย จุดกู้คืน (RPO)คือช่วงเวลาสูงสุดที่ยอมรับได้ซึ่งข้อมูลธุรกรรมอาจสูญหายจากบริการไอที[ 11 ]
ตัวอย่างเช่น หาก RPO วัดเป็นนาที ในทางปฏิบัติ การสำรองข้อมูลแบบมิเรอร์นอกสถานที่ต้องได้รับการบำรุงรักษาอย่างต่อเนื่องเนื่องจากการสำรองข้อมูลนอกสถานที่รายวันจะไม่เพียงพอ[ 13 ]
ความสัมพันธ์กับ RTO
การกู้คืนที่ไม่เกิดขึ้นทันทีจะกู้คืนข้อมูลธุรกรรมในช่วงเวลาหนึ่งโดยไม่ก่อให้เกิดความเสี่ยงหรือการสูญเสียที่สำคัญ[ 11 ]
RPO (Recovery Point Objective) คือค่าที่ใช้วัดระยะเวลาสูงสุดที่ข้อมูลล่าสุดอาจสูญหายไปอย่างถาวร ไม่ใช่การวัดปริมาณการสูญหายโดยตรง ตัวอย่างเช่น หากแผน BC (Business Continuity) คือการกู้คืนข้อมูลจนถึงข้อมูลสำรองล่าสุดที่มีอยู่ RPO ก็คือช่วงเวลาระหว่างข้อมูลสำรองเหล่านั้น
RPO ไม่ได้ถูกกำหนดโดยระบบสำรองข้อมูลที่มีอยู่ แต่ BIA จะกำหนด RPO สำหรับแต่ละบริการ เมื่อจำเป็นต้องใช้ข้อมูลนอกสถานที่ ระยะเวลาที่ข้อมูลอาจสูญหายอาจเริ่มต้นเมื่อมีการเตรียมการสำรองข้อมูล ไม่ใช่เมื่อมีการรักษาความปลอดภัยการสำรองข้อมูลนอกสถานที่[ 12 ]
เวลาเฉลี่ย
ตัวชี้วัดการฟื้นตัวสามารถแปลงเป็น/ใช้ควบคู่กับ ตัวชี้วัด ความล้มเหลวได้การวัดผลที่ใช้กันทั่วไป ได้แก่เวลาเฉลี่ยระหว่างความล้มเหลว (MTBF), เวลาเฉลี่ยถึงความล้มเหลวครั้งแรก (MTFF), เวลาเฉลี่ยในการซ่อมแซม (MTTR) และเวลาหยุดทำงานเฉลี่ย (MDT)
จุดซิงโครไนซ์ข้อมูล
จุดการซิงโครไนซ์ข้อมูล[ 14 ]คือจุดที่การสำรองข้อมูลเสร็จสมบูรณ์ โดยจะหยุดการประมวลผลการอัปเดตในขณะที่การคัดลอกดิสก์ต่อดิสก์เสร็จสมบูรณ์ สำเนาสำรองข้อมูล[ 15 ]สะท้อนถึงเวอร์ชันก่อนหน้าของการดำเนินการคัดลอก ไม่ใช่เมื่อข้อมูลถูกคัดลอกไปยังเทปหรือส่งไปยังที่อื่น
การออกแบบระบบ
RTO และ RPO ต้องมีความสมดุล โดยคำนึงถึงความเสี่ยงทางธุรกิจควบคู่ไปกับเกณฑ์การออกแบบระบบอื่นๆ[ 16 ]
RPO เกี่ยวข้องกับเวลาที่สำรองข้อมูลไว้ภายนอกสถานที่ การส่งสำเนาแบบซิงโครนัสไปยังมิเรอร์ภายนอกสถานที่ช่วยให้สามารถรับมือกับเหตุการณ์ที่ไม่คาดฝันได้เกือบทั้งหมด การใช้การขนส่งทางกายภาพสำหรับเทป (หรือสื่อที่เคลื่อนย้ายได้อื่นๆ) เป็นเรื่องปกติ การกู้คืนสามารถเปิดใช้งานได้ที่ไซต์ที่กำหนดไว้ล่วงหน้า พื้นที่และฮาร์ดแวร์ภายนอกสถานที่ที่ใช้ร่วมกันทำให้แพ็คเกจสมบูรณ์[ 17 ]
สำหรับข้อมูลธุรกรรมที่มีปริมาณมากและมีมูลค่าสูง สามารถแบ่งฮาร์ดแวร์ไปใช้งานในหลายๆ ไซต์ได้
ประวัติศาสตร์
การวางแผนรับมือภัยพิบัติและเทคโนโลยีสารสนเทศ (IT) พัฒนาขึ้นในช่วงกลางถึงปลายทศวรรษ 1970 เมื่อผู้จัดการศูนย์คอมพิวเตอร์เริ่มตระหนักถึงความสำคัญของระบบคอมพิวเตอร์ต่อองค์กรของตน
ในเวลานั้น ระบบส่วนใหญ่เป็นเมนเฟรม แบบประมวลผลเป็นชุด เมนเฟรมที่ตั้งอยู่นอกสถานที่สามารถโหลดข้อมูลจากเทปสำรองข้อมูลได้ในระหว่างรอการกู้คืนระบบที่ไซต์หลัก ดังนั้นเวลาหยุดทำงานจึงมีความสำคัญค่อนข้างน้อย
อุตสาหกรรมการกู้คืนจากภัยพิบัติ[ 18 ] [ 19 ]พัฒนาขึ้นเพื่อให้บริการศูนย์คอมพิวเตอร์สำรอง Sungard Availability Services เป็นหนึ่งในศูนย์ดังกล่าวแห่งแรกๆ ตั้งอยู่ในศรีลังกา (1978) [ 20 ] [ 21 ]
ในช่วงทศวรรษ 1980 และ 1990 เทคโนโลยีคอมพิวเตอร์เติบโตอย่างก้าวกระโดด รวมถึงการแบ่งเวลาใช้งานภายในองค์กร การป้อนข้อมูลออนไลน์ และการประมวลผลแบบเรียลไทม์ความพร้อมใช้งานของระบบไอทีจึงมีความสำคัญมากขึ้น
หน่วยงานกำกับดูแลเข้ามามีส่วนร่วม โดยมักมีการกำหนดเป้าหมายความพร้อมใช้งานไว้ที่ 2, 3, 4 หรือ 5 เก้า (99.999%) และมีการแสวงหา โซลูชัน ที่มีความพร้อมใช้งานสูงสำหรับ สถาน ที่ที่มีอุณหภูมิ สูง
ความต่อเนื่องของบริการด้านไอทีกลายเป็นสิ่งจำเป็นในฐานะส่วนหนึ่งของการบริหารจัดการความต่อเนื่องทางธุรกิจ (Business Continuity Management: BCM) และการบริหารจัดการความปลอดภัยของข้อมูล (Information Security Management: ISM) ตามที่ระบุไว้ในมาตรฐาน ISO/IEC 27001 และ ISO 22301 ตามลำดับ
การเติบโตของการประมวลผลแบบคลาวด์ตั้งแต่ปี 2010 ได้สร้างโอกาสใหม่ๆ สำหรับความยืดหยุ่นของระบบ ผู้ให้บริการรับผิดชอบในการรักษาระดับการบริการที่สูง รวมถึงความพร้อมใช้งานและความน่าเชื่อถือ พวกเขาเสนอการออกแบบเครือข่ายที่มีความยืดหยุ่นสูง Recovery as a Service (RaaS) มีให้บริการอย่างแพร่หลายและได้รับการส่งเสริมโดยCloud Security Alliance [ 22 ]
การจำแนกประเภท
ภัยพิบัติอาจเกิดจากภัยคุกคามและอันตรายในสามประเภทหลักๆ
- ภัยธรรมชาติ ได้แก่ เหตุการณ์ทางธรรมชาติ เช่น น้ำท่วม พายุเฮอริเคน พายุทอร์นาโด แผ่นดินไหว และโรคระบาด
- อันตรายจากเทคโนโลยี ได้แก่ อุบัติเหตุหรือความล้มเหลวของระบบและโครงสร้าง เช่น การระเบิดของท่อส่ง การเกิดอุบัติเหตุทางการขนส่ง การหยุดชะงักของสาธารณูปโภค การพังทลายของเขื่อน และการรั่วไหลของสารอันตรายโดยอุบัติเหตุ
- ภัยคุกคามที่เกิดจากมนุษย์ ซึ่งรวมถึงการกระทำโดยเจตนา เช่น การโจมตีโดยผู้ร้าย การโจมตีด้วยสารเคมีหรือชีวภาพ การโจมตีทางไซเบอร์ต่อข้อมูลหรือโครงสร้างพื้นฐาน การก่อวินาศกรรม และสงคราม
มาตรการเตรียมความพร้อมสำหรับภัยพิบัติทุกประเภทและทุกรูปแบบนั้นแบ่งออกเป็น 5 ภารกิจหลัก ได้แก่ การป้องกัน การคุ้มครอง การบรรเทา การตอบสนอง และการฟื้นฟู[ 23 ]
การวางแผน
งานวิจัยสนับสนุนแนวคิดที่ว่าการนำแนวทางการวางแผนก่อนเกิดภัยพิบัติแบบองค์รวมมาใช้จะคุ้มค่ากว่า ทุกๆ 1 ดอลลาร์ที่ใช้ไปกับการบรรเทาภัยพิบัติ (เช่นแผนการฟื้นฟูหลังภัยพิบัติ ) จะช่วยประหยัดค่าใช้จ่ายในการตอบสนองและการฟื้นฟูให้กับสังคมได้ถึง 4 ดอลลาร์[ 24 ]
สถิติการกู้คืนจากภัยพิบัติในปี 2015 ชี้ให้เห็นว่าเวลาหยุดทำงานที่กินเวลาหนึ่งชั่วโมงอาจก่อให้เกิดค่าใช้จ่าย[ 25 ]
- บริษัทขนาดเล็ก 8,000 ดอลลาร์สหรัฐ
- องค์กรขนาดกลาง 74,000 ดอลลาร์ และ
- องค์กรขนาดใหญ่ที่มีรายได้ 700,000 ดอลลาร์ขึ้นไป
เนื่องจากระบบไอทีมีความสำคัญมากขึ้นเรื่อยๆ ต่อการดำเนินงานที่ราบรื่นของบริษัท และอาจรวมถึงเศรษฐกิจโดยรวมด้วย ความสำคัญของการรับประกันการดำเนินงานอย่างต่อเนื่องของระบบเหล่านั้น และการฟื้นตัวอย่างรวดเร็วจึงเพิ่มมากขึ้น[ 26 ]
มาตรการควบคุม
มาตรการควบคุม คือ ขั้นตอนหรือกลไกที่สามารถลดหรือกำจัดภัยคุกคามได้ การเลือกใช้กลไกจะสะท้อนให้เห็นในแผนการฟื้นฟูจากภัยพิบัติ (DRP)
มาตรการควบคุมสามารถจำแนกได้เป็น มาตรการควบคุมที่มุ่งป้องกันไม่ให้เหตุการณ์เกิดขึ้น มาตรการควบคุมที่มุ่งตรวจจับหรือค้นพบเหตุการณ์ที่ไม่พึงประสงค์ และมาตรการควบคุมที่มุ่งแก้ไขหรือฟื้นฟูระบบหลังจากเกิดภัยพิบัติหรือเหตุการณ์ขึ้น
การควบคุมเหล่านี้ได้รับการบันทึกและทดสอบอย่างสม่ำเสมอโดยใช้สิ่งที่เรียกว่า "การทดสอบ DR"
กลยุทธ์
กลยุทธ์การกู้คืนจากภัยพิบัติมาจากแผนความต่อเนื่องทางธุรกิจ[ 27 ]จากนั้นจึงทำการแมปตัวชี้วัดสำหรับกระบวนการทางธุรกิจกับระบบและโครงสร้างพื้นฐาน[ 28 ]การวิเคราะห์ต้นทุนและผลประโยชน์จะเน้นให้เห็นว่ามาตรการการกู้คืนจากภัยพิบัติใดเหมาะสม กลยุทธ์ที่แตกต่างกันจะมีความเหมาะสมโดยพิจารณาจากต้นทุนของการหยุดทำงานเมื่อเทียบกับต้นทุนของการนำกลยุทธ์เฉพาะไปใช้
กลยุทธ์ทั่วไปได้แก่:
- สำรองข้อมูลลงเทปและส่งไปยังสถานที่ภายนอก
- สำรองข้อมูลลงดิสก์ภายในสถานที่ (คัดลอกไปยังดิสก์ภายนอกสถานที่) หรือภายนอกสถานที่
- การจำลองข้อมูลไปยังสถานที่ภายนอก เพื่อให้เมื่อระบบได้รับการกู้คืนหรือซิงโครไนซ์แล้ว อาจใช้เทคโนโลยีเครือข่ายพื้นที่จัดเก็บข้อมูล (Storage Area Network)
- โซลูชันคลาวด์ส่วนตัวที่จำลองเมตาเดตา (VM, เทมเพลต และดิสก์) ไปยังคลาวด์ส่วนตัว เมตาเดตาได้รับการกำหนดค่าใน รูปแบบ XMLที่เรียกว่า Open Virtualization Format และสามารถกู้คืนได้อย่างง่ายดาย
- โซลูชันคลาวด์แบบไฮบริดที่จำลองทั้งระบบภายในองค์กรและศูนย์ข้อมูลภายนอกองค์กร ซึ่งช่วยให้สามารถสลับการทำงานไปยังฮาร์ดแวร์ภายในองค์กรหรือศูนย์ข้อมูลบนคลาวด์ได้ทันทีเมื่อเกิดข้อผิดพลาด
- ระบบที่มีความพร้อมใช้งานสูงซึ่งเก็บทั้งข้อมูลและระบบที่จำลองไว้ภายนอกไซต์ ทำให้สามารถเข้าถึงระบบและข้อมูลได้อย่างต่อเนื่องแม้หลังจากเกิดภัยพิบัติ (มักเกี่ยวข้องกับการจัดเก็บข้อมูลบนคลาวด์ ) [ 29 ]
มาตรการป้องกันอาจรวมถึง:
- การทำมิเรอร์ระบบและ/หรือข้อมูลในพื้นที่ และการใช้เทคโนโลยีป้องกันดิสก์ เช่นRAID
- อุปกรณ์ป้องกันไฟกระชาก — เพื่อลดผลกระทบของไฟกระชากต่ออุปกรณ์อิเล็กทรอนิกส์ที่บอบบาง
- การใช้เครื่องสำรองไฟ (UPS) และ/หรือเครื่องกำเนิดไฟฟ้าสำรองเพื่อให้ระบบทำงานต่อไปได้ในกรณีไฟฟ้าดับ
- ระบบป้องกัน/บรรเทาอัคคีภัย เช่น สัญญาณเตือนภัยและเครื่องดับเพลิง
- ซอฟต์แวร์ป้องกันไวรัสและมาตรการรักษาความปลอดภัยอื่นๆ
บริการกู้คืนระบบหลังภัยพิบัติ

การกู้คืนระบบจากภัยพิบัติในรูปแบบบริการ (DRaaS) คือข้อตกลงกับผู้ขายบุคคลที่สามเพื่อดำเนินการฟังก์ชัน DR บางส่วนหรือทั้งหมดสำหรับสถานการณ์ต่างๆ เช่น ไฟฟ้าดับ อุปกรณ์ขัดข้อง การโจมตีทางไซเบอร์ และภัยพิบัติทางธรรมชาติ[ 30 ]
การกู้คืนระบบจากภัยพิบัติสำหรับระบบคลาวด์
การปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดสามารถเพิ่มประสิทธิภาพกลยุทธ์การกู้คืนจากภัยพิบัติสำหรับระบบที่โฮสต์บนคลาวด์ได้ : [ 31 ] [ 32 ] [ 33 ]
- ความยืดหยุ่น:กลยุทธ์การกู้คืนระบบจากภัยพิบัติควรปรับเปลี่ยนได้เพื่อรองรับทั้งความล้มเหลวบางส่วน (เช่น การกู้คืนไฟล์เฉพาะ) และความล้มเหลวของระบบโดยรวม
- การทดสอบอย่างสม่ำเสมอ : การทดสอบแผนการกู้คืนระบบหลังภัยพิบัติอย่างสม่ำเสมอจะช่วยตรวจสอบประสิทธิภาพและระบุจุดอ่อนหรือช่องโหว่ต่างๆ ได้
- บทบาทและสิทธิ์ที่ชัดเจน : ควรมีการกำหนดอย่างชัดเจนว่าใครบ้างที่ได้รับอนุญาตให้ดำเนินการตามแผนการกู้คืนระบบจากภัยพิบัติ โดยให้สิทธิ์และการเข้าถึงที่แยกต่างหากสำหรับแต่ละบุคคลการแยกสิทธิ์ อย่างชัดเจน ระหว่างผู้ที่สามารถดำเนินการกู้คืนและผู้ที่เข้าถึงข้อมูลสำรองจะช่วยลดความเสี่ยงจากการกระทำที่ไม่ได้รับอนุญาตได้
- เอกสารประกอบ : แผนงานควรจัดทำเป็นเอกสารอย่างละเอียดและเข้าใจง่าย เพื่อให้ผู้ปฏิบัติงานสามารถปฏิบัติตามได้อย่างมีประสิทธิภาพในสถานการณ์ที่ตึงเครียด
ข้อกำหนดด้านกฎระเบียบ
กรอบการกำกับดูแลหลายประการกำหนดให้องค์กรที่จัดการข้อมูลที่ละเอียดอ่อนต้องมีขีดความสามารถในการกู้คืนจากภัยพิบัติ ในภาคการดูแลสุขภาพกฎความปลอดภัยของพระราชบัญญัติการพกพาและการรับผิดชอบด้านการประกันสุขภาพ (HIPAA) กำหนดให้หน่วยงานที่อยู่ภายใต้การคุ้มครองและผู้ร่วมธุรกิจต้องจัดทำแผนการกู้คืนจากภัยพิบัติเป็นส่วนหนึ่งของมาตรฐานการวางแผนฉุกเฉิน (45 CFR 164.308(a)(7)) ซึ่งรวมถึงขั้นตอนในการกู้คืนข้อมูลที่สูญหาย พร้อมกับข้อกำหนดสำหรับแผนการสำรองข้อมูล แผนปฏิบัติการในโหมดฉุกเฉิน และการทดสอบและการแก้ไขขั้นตอนฉุกเฉินเป็นระยะ[ 34 ]
ประกาศร่างกฎระเบียบ (NPRM) เดือนธันวาคม 2024 เพื่อปรับปรุงกฎความปลอดภัยของ HIPAA เสนอข้อกำหนดการกู้คืนระบบจากภัยพิบัติที่ขยายขอบเขตอย่างมีนัยสำคัญ รวมถึงข้อบังคับให้กู้คืนระบบและข้อมูลที่สำคัญภายใน 72 ชั่วโมงหลังจากการหยุดชะงัก ร่างกฎระเบียบยังกำหนดให้มีการวิเคราะห์ความสำคัญเพื่อจัดลำดับความสำคัญของลำดับการกู้คืนระบบ การทดสอบแผนการกู้คืนระบบจากภัยพิบัติเป็นประจำ และการควบคุมทางเทคนิคที่แยกต่างหากสำหรับระบบสำรองข้อมูลและระบบกู้คืน ข้อกำหนดเหล่านี้ได้รับอิทธิพลจากเหตุการณ์ขนาดใหญ่ เช่นการโจมตีทางไซเบอร์ Change Healthcare ในปี 2024ซึ่งทำให้ระบบการประมวลผลการเรียกร้องและการชำระเงินทั่วระบบการดูแลสุขภาพของสหรัฐอเมริกาหยุดชะงักเป็นเวลาหลายสัปดาห์[ 35 ]
ในภาคการเงินสภาตรวจสอบสถาบันการเงินของรัฐบาลกลาง (FFIEC) กำหนดให้สถาบันการเงินต้องรักษาและทดสอบแผนความต่อเนื่องทางธุรกิจและการกู้คืนจากภัยพิบัติ โดยมีความคาดหวังเฉพาะเจาะจงสำหรับเป้าหมายเวลาในการกู้คืนตามความสำคัญของฟังก์ชันทางธุรกิจ[ 36 ]
ดูเพิ่มเติม
- เว็บไซต์สำรองข้อมูล
- BS 25999
- การวางแผนความต่อเนื่องทางธุรกิจ
- ความต่อเนื่องทางธุรกิจ
- การปกป้องข้อมูลอย่างต่อเนื่อง
- แผนการฟื้นฟูหลังภัยพิบัติ
- การรับมือกับภัยพิบัติ
- การจัดการเหตุฉุกเฉิน
- ความพร้อมใช้งานสูง
- แผนฉุกเฉินระบบสารสนเทศ
- การกู้คืนแบบเรียลไทม์
- วัตถุประสงค์ความสม่ำเสมอในการกู้คืน
- บริการสำรองข้อมูลระยะไกล
- ห้องสมุดเทปเสมือนจริง
อ่านเพิ่มเติม
- บาร์นส์, เจมส์ (2001). คู่มือการวางแผนความต่อเนื่องทางธุรกิจ . ชิเชสเตอร์, นิวยอร์ก: จอห์น ไวลีย์. ISBN 9780470845431. OCLC 50321216 .
- เบลล์, จูดี้ เคย์ (2000). การวางแผนการเอาตัวรอดจากภัยพิบัติ: คู่มือปฏิบัติสำหรับธุรกิจ . พอร์ตฮูเอเนม, แคลิฟอร์เนีย, สหรัฐอเมริกา: การวางแผนการเอาตัวรอดจากภัยพิบัติ. ISBN 9780963058027. OCLC 45755917 .
- ฟุลเมอร์, เคนเนธ (2015). การวางแผนความต่อเนื่องทางธุรกิจ: คู่มือทีละขั้นตอนพร้อมแบบฟอร์มการวางแผน . บรูคฟิลด์, คอนเนตทิคัต: รอธสไตน์ แอสโซซิเอทส์ อิงค์. ISBN 9781931332804. OCLC 712628907 , 905750518 , 1127407034 .
- DiMattia, Susan S (2001). "การวางแผนเพื่อความต่อเนื่อง". Library Journal . 126 (19): 32– 34. ISSN 0363-0277 . OCLC 425551440 .
- Harney, John (กรกฎาคม–สิงหาคม 2547). "การดำเนินธุรกิจอย่างต่อเนื่องและการกู้คืนจากภัยพิบัติ: สำรองข้อมูลหรือปิดระบบ" . วารสาร AIIM E-DOC . ISSN 1544-3647 . OCLC 1058059544 . เก็บถาวรจากต้นฉบับเมื่อ 2551-02-04.
- "ISO 22301:2019(en), ความปลอดภัยและความยืดหยุ่น — ระบบการจัดการความต่อเนื่องทางธุรกิจ — ข้อกำหนด" . ISO.
- "ISO/IEC 27001:2013(en) เทคโนโลยีสารสนเทศ — เทคนิคด้านความปลอดภัย — ระบบการจัดการความปลอดภัยของข้อมูล — ข้อกำหนด" . ISO.
- "ISO/IEC 27002:2013(en) เทคโนโลยีสารสนเทศ — เทคนิคด้านความปลอดภัย — หลักปฏิบัติสำหรับการควบคุมความปลอดภัยของข้อมูล" . ISO.
ลิงก์ภายนอก
- "คำศัพท์เฉพาะทางด้านการวางแผนความต่อเนื่องทางธุรกิจ การกู้คืนระบบหลังภัยพิบัติ และโซลูชันเทคโนโลยีการทำสำเนาข้อมูลและการจัดเก็บข้อมูล z/OS ที่เกี่ยวข้อง" recoveryspecialties.com เก็บถาวรจากต้นฉบับเมื่อ 2020-11-14 เรียกดูเมื่อ2021-09-02
- "แผนการกู้คืนระบบไอทีหลังภัยพิบัติ" Ready.gov สืบค้นเมื่อ2 กันยายน 2021
- " คำอธิบายเกี่ยวกับ RPO (Recovery Point Objective)" IBM 8สิงหาคม 2019 สืบค้นเมื่อ2 กันยายน 2021
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การกู้คืนระบบไอทีจากภัยพิบัติ
การกู้คืนระบบไอทีหลังภัยพิบัติ (เรียกสั้น ๆ ว่า การกู้คืนระบบหลังภัยพิบัติ ( DR )) คือกระบวนการบำรุงรักษาหรือฟื้นฟู โครงสร้างพื้นฐาน และ ระบบ ที่สำคัญ หลังจาก ภัยพิบัติ...
ความต่อเนื่องของบริการไอที
ความต่อเนื่องของบริการไอที (ITSC) เป็นส่วนย่อยของ BCP [ 4 ] ซึ่งอาศัยตัวชี้วัด (มักใช้เป็น ตัวชี้วัดความเสี่ยงหลัก ) ของเป้าหมายจุด/เวลาการกู้คืน ครอบคลุมถึง การวางแผนการกู้คืนระบบไอทีจากภัยพิบัติ และ การวางแผนความยืดหยุ่นของระบบไอที ในวงกว้าง...
หลักการของไซต์สำรองข้อมูล
การวางแผนรวมถึงการจัดเตรียมสถานที่สำรอง ไม่ว่าจะเป็นสถานที่ "พร้อมใช้งาน" (ใช้งานได้ก่อนเกิดภัยพิบัติ) "พร้อมใช้งานเมื่อจำเป็น" (พร้อมที่จะเริ่มใช้งาน) หรือ "พร้อมใช้งานเมื่อต้องดำเนินการอย่างมากเพื่อเริ่มใช้งาน)...
เป้าหมายเวลาในการฟื้นตัว
วัตถุประสงค์ เวลาในการกู้คืน (RTO) [ 9 ] [ 10 ] คือระยะเวลาเป้าหมายและระดับการบริการที่ กระบวนการทางธุรกิจ จะต้องได้รับการกู้คืนหลังจากเกิดการหยุดชะงัก เพื่อหลีกเลี่ยงการหยุดชะงักของความต่อเนื่องทางธุรกิจ [ 11 ]