อ่าน 7 นาที
ข้อผิดพลาดมาตรฐาน
ค่าความคลาดเคลื่อนมาตรฐาน ( SE ) ของสถิติ (โดยปกติจะเป็นตัวประมาณค่าพารามิเตอร์เช่น ค่าเฉลี่ยหรือค่าเฉลี่ยเลขคณิต) คือค่าเบี่ยงเบนมาตรฐานของ การ แจกแจงตัวอย่าง...
ข้อผิดพลาดมาตรฐาน
ค่าความคลาดเคลื่อนมาตรฐาน ( SE ) [ 1 ]ของสถิติ (โดยปกติจะเป็นตัวประมาณค่าพารามิเตอร์เช่น ค่าเฉลี่ยหรือค่าเฉลี่ยเลขคณิต) คือค่าเบี่ยงเบนมาตรฐานของ การ แจกแจงตัวอย่าง[ 1 ] [ 2 ]ค่าความคลาดเคลื่อนมาตรฐานมักใช้ในการคำนวณ ช่วงความเชื่อมั่น[ 3 ]
การแจกแจงตัวอย่างของค่าเฉลี่ยเกิดจากการสุ่มตัวอย่างซ้ำๆ จากประชากรเดียวกัน และบันทึกค่าเฉลี่ยของตัวอย่างแต่ละครั้ง ซึ่งจะทำให้เกิดการแจกแจงของค่าเฉลี่ยตัวอย่างที่แตกต่างกัน และการแจกแจงนี้จะมีค่าเฉลี่ยและความแปรปรวน ของตัวเอง ในทางคณิตศาสตร์ ความแปรปรวนของการแจกแจงค่าเฉลี่ยตัวอย่างที่ได้จะเท่ากับความแปรปรวนของประชากรหารด้วยขนาดของตัวอย่าง เนื่องจากเมื่อขนาดของตัวอย่างเพิ่มขึ้น ค่าเฉลี่ยของตัวอย่างจะกระจุกตัวอยู่ใกล้กับค่าเฉลี่ยของประชากรมากขึ้น
ดังนั้น ความสัมพันธ์ระหว่างข้อผิดพลาดมาตรฐานของค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานจึงเป็นไปในลักษณะที่ว่า สำหรับขนาดตัวอย่างที่กำหนด ข้อผิดพลาดมาตรฐานของค่าเฉลี่ยจะเท่ากับส่วนเบี่ยงเบนมาตรฐานหารด้วยรากที่สองของขนาดตัวอย่าง[ 1 ]กล่าวอีกนัยหนึ่ง ข้อผิดพลาดมาตรฐานของค่าเฉลี่ยคือการวัดการกระจายของค่าเฉลี่ยตัวอย่างรอบค่าเฉลี่ยของประชากร
ในการวิเคราะห์การถดถอยคำว่า "ค่าความคลาดเคลื่อนมาตรฐาน" หมายถึง รากที่สองของค่าสถิติไคกำลังสองที่ลดลงหรือค่าความคลาดเคลื่อนมาตรฐานสำหรับสัมประสิทธิ์การถดถอยเฉพาะ (ดังที่ใช้ในตัวอย่างเช่นช่วงความเชื่อมั่น )
ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยตัวอย่าง
ค่าที่แน่นอน
สมมติว่ามีการสุ่มตัวอย่างการสังเกต ที่เป็นอิสระทางสถิติ จากประชากรทางสถิติที่มีส่วนเบี่ยงเบนมาตรฐานเท่ากับ(ส่วนเบี่ยงเบนมาตรฐานของประชากร) ค่าเฉลี่ยที่คำนวณจากตัวอย่างจะมีข้อผิดพลาดมาตรฐานที่เกี่ยวข้อง กับ ค่าเฉลี่ยโดยกำหนดโดย: [ 1 ]






ในทางปฏิบัติ สิ่งนี้บอกเราว่า เมื่อพยายามประมาณค่าเฉลี่ยของประชากรการลดข้อผิดพลาดในการประมาณค่าลงครึ่งหนึ่ง จำเป็นต้องใช้จำนวนตัวอย่างเพิ่มขึ้นสี่เท่า และการลดข้อผิดพลาดลงสิบเท่า จำเป็นต้องใช้จำนวนตัวอย่างเพิ่มขึ้นหนึ่งร้อยเท่า

ประมาณการ
โดยทั่วไปแล้ว ค่าเบี่ยงเบนมาตรฐานของประชากรที่ทำการสุ่มตัวอย่างมักไม่เป็นที่ทราบ ดังนั้น ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยจึงมักประมาณโดยการแทนที่ด้วยค่าเบี่ยงเบนมาตรฐานของตัวอย่างแทน:


เนื่องจากนี่เป็นเพียงตัวประมาณค่า "ความคลาดเคลื่อนมาตรฐาน" ที่แท้จริง จึงมักเห็นสัญลักษณ์อื่นๆ ปรากฏอยู่ เช่น:

สาเหตุหนึ่งที่มักก่อให้เกิดความสับสนคือการไม่สามารถแยกแยะความแตกต่างระหว่างสิ่งต่อไปนี้ได้อย่างชัดเจน:
- ค่าเบี่ยงเบนมาตรฐานของประชากร ( )
- ค่าเบี่ยงเบนมาตรฐานของตัวอย่าง ( )
- ค่าเบี่ยงเบนมาตรฐานของค่าเฉลี่ยตัวอย่าง ( ซึ่งก็คือค่าความคลาดเคลื่อนมาตรฐาน) และ
- ตัวประมาณค่าส่วนเบี่ยงเบนมาตรฐานของค่าเฉลี่ยตัวอย่าง ( ซึ่งเป็นปริมาณที่คำนวณบ่อยที่สุด และมักเรียกกันทั่วไปว่าค่าความคลาดเคลื่อนมาตรฐาน )


ความแม่นยำของผู้ประมาณค่า
เมื่อขนาดตัวอย่างเล็ก การใช้ค่าเบี่ยงเบนมาตรฐานของตัวอย่างแทนค่าเบี่ยงเบนมาตรฐานที่แท้จริงของประชากรจะทำให้ค่าเบี่ยงเบนมาตรฐานของประชากรต่ำกว่าความเป็นจริงอย่างเป็นระบบ และด้วยเหตุนี้จึงทำให้ค่าความคลาดเคลื่อนมาตรฐานต่ำกว่าความเป็นจริงด้วย สำหรับn = 2 ค่าที่ประเมินต่ำกว่าความเป็นจริงจะอยู่ที่ประมาณ 25% แต่สำหรับn = 6 ค่าที่ประเมินต่ำกว่าความเป็นจริงจะอยู่ที่เพียง 5% Gurland และ Tripathi (1971) ได้เสนอการแก้ไขและสมการสำหรับผลกระทบนี้[ 4 ] Sokal และ Rohlf (1981) ได้เสนอสมการของปัจจัยการแก้ไขสำหรับตัวอย่างขนาดเล็กที่มีn < 20 [ 5 ]ดูการประมาณค่าเบี่ยงเบนมาตรฐานที่ไม่เอนเอียงสำหรับการอภิปรายเพิ่มเติม
อนุพันธ์
ข้อผิดพลาดมาตรฐานของค่าเฉลี่ยอาจได้มาจากความแปรปรวนของผลรวมของตัวแปรสุ่มอิสระ[ 6 ]โดยพิจารณาจากนิยามของความแปรปรวนและคุณสมบัติ บางประการ หากเป็นตัวอย่างของการสังเกตอิสระจากประชากรที่มีค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานเราสามารถกำหนดผลรวมซึ่งเนื่องจากสูตรของ Bienayméจะมีความแปรปรวน



ค่าเฉลี่ยของการวัดเหล่านี้(ค่าเฉลี่ยตัวอย่าง) กำหนดโดยส่วนความแปรปรวนของค่าเฉลี่ยคือ


โดยมี การใช้ การแพร่กระจายของความแปรปรวนในสมการที่สอง ค่าความคลาดเคลื่อนมาตรฐานตามนิยามคือค่าเบี่ยงเบนมาตรฐานซึ่งเท่ากับรากที่สองของความแปรปรวน:

กล่าวอีกนัยหนึ่ง หากมีจำนวนการสังเกตต่อการสุ่มตัวอย่างมาก ( สูงกว่าความแปรปรวนของประชากร) ค่าเฉลี่ยที่คำนวณได้ต่อตัวอย่างก็ คาดว่าจะใกล้เคียงกับค่าเฉลี่ยของประชากร



สำหรับตัวแปรสุ่มที่มีความสัมพันธ์กัน จำเป็นต้องคำนวณความแปรปรวนของตัวอย่างตามทฤษฎีบทขีดจำกัดกลางของห่วงโซ่มาร์คอฟ
ตัวแปรสุ่มอิสระและมีการกระจายเหมือนกัน โดยมีขนาดตัวอย่างแบบสุ่ม
มีบางกรณีที่ทำการสุ่มตัวอย่างโดยไม่ทราบล่วงหน้าว่าจำนวนการสังเกตที่ยอมรับได้ตามเกณฑ์ใดเกณฑ์หนึ่งจะมีจำนวนเท่าใด ในกรณีเช่นนี้ ขนาดตัวอย่างจะเป็นตัวแปรสุ่มซึ่งความแปรปรวนจะเพิ่มเข้าไปในความแปรปรวนของค่าดังกล่าว[ 7 ] ซึ่งเป็นไปตามกฎของความแปรปรวนรวม



ถ้ามีการแจกแจงแบบปัวซงแล้วจะมีตัวประมาณค่าเป็นดังนั้น ตัวประมาณค่าของจึงกลายเป็นซึ่งนำไปสู่สูตรต่อไปนี้สำหรับค่าความคลาดเคลื่อนมาตรฐาน: (เนื่องจากค่าเบี่ยงเบนมาตรฐานคือรากที่สองของความแปรปรวน)





การประมาณค่าของนักเรียนเมื่อไม่ทราบค่าσ
ในการใช้งานจริงหลายๆ กรณี ค่าที่แท้จริงของσนั้นไม่เป็นที่ทราบแน่ชัด ดังนั้นเราจึงจำเป็นต้องใช้การแจกแจงที่คำนึงถึงช่วงของ ค่า σ ที่เป็นไป ได้เหล่านั้น เมื่อทราบว่าการแจกแจงพื้นฐานที่แท้จริงเป็นแบบเกาส์เซียน แม้ว่าค่า σ จะไม่ทราบ การแจกแจงที่ประมาณได้จะตามการแจกแจงแบบ Student t ค่าความคลาดเคลื่อนมาตรฐานคือค่าเบี่ยงเบนมาตรฐานของการแจกแจงแบบ Student t การแจกแจงแบบ t นั้นแตกต่างจากแบบเกาส์เซียนเล็กน้อย และจะแปรผันไปตามขนาดของตัวอย่าง ตัวอย่างขนาดเล็กมีแนวโน้มที่จะประเมินค่าเบี่ยงเบนมาตรฐานของประชากรต่ำกว่าความเป็นจริง และมีค่าเฉลี่ยที่แตกต่างจากค่าเฉลี่ยของประชากรที่แท้จริง และการแจกแจงแบบ Student t จะคำนึงถึงความน่าจะเป็นของเหตุการณ์เหล่านี้ด้วยหางที่หนักกว่าเมื่อเทียบกับแบบเกาส์เซียน ในการประมาณค่าความคลาดเคลื่อนมาตรฐานของการแจกแจงแบบ Student t นั้น เพียงพอที่จะใช้ค่าเบี่ยงเบนมาตรฐานของตัวอย่าง "s" แทนσและเราสามารถใช้ค่านี้ในการคำนวณช่วงความเชื่อมั่นได้
หมายเหตุ: การแจกแจงความน่าจะเป็นของนักเรียนสามารถประมาณได้ดีด้วยการแจกแจงแบบเกาส์เซียนเมื่อขนาดตัวอย่างมากกว่า 100 สำหรับตัวอย่างดังกล่าว เราสามารถใช้การแจกแจงแบบเกาส์เซียนได้ ซึ่งง่ายกว่ามาก นอกจากนี้ แม้ว่าการแจกแจง "ที่แท้จริง" ของประชากรจะไม่เป็นที่รู้จัก การสมมติว่าการแจกแจงของการสุ่มตัวอย่างเป็นแบบปกติก็สมเหตุสมผลสำหรับขนาดตัวอย่างที่เหมาะสม และภายใต้เงื่อนไขการสุ่มตัวอย่างบางประการ ดูทฤษฎีบทขีดจำกัดกลาง(CLT ) หากไม่เป็นไปตามเงื่อนไขเหล่านี้ การใช้การแจกแจงแบบบูตสแตรปเพื่อประมาณค่าความคลาดเคลื่อนมาตรฐานมักเป็นวิธีแก้ปัญหาที่ดี แต่ก็อาจต้องใช้การคำนวณที่ซับซ้อนมาก
ข้อสมมติและวิธีการใช้งาน
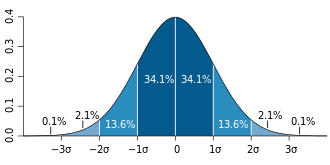
ตัวอย่างการใช้ค่าความคลาดเคลื่อนมาตรฐาน (Standard Error) ในการสร้างช่วงความเชื่อมั่นของค่าเฉลี่ยประชากรที่ไม่ทราบค่าแสดงไว้ในภาพ หากการแจกแจงตัวอย่างเป็นการแจกแจงแบบปกติค่าเฉลี่ยตัวอย่าง ค่าความคลาดเคลื่อนมาตรฐาน และควอนไทล์ของการแจกแจงแบบปกติสามารถใช้ในการคำนวณช่วงความเชื่อมั่นสำหรับค่าเฉลี่ยประชากรที่แท้จริงได้ สูตรต่อไปนี้สามารถใช้ในการคำนวณขีดจำกัดความเชื่อมั่น 95% บนและล่าง โดยที่คือค่าเฉลี่ยตัวอย่างคือค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยตัวอย่าง (ค่าเบี่ยงเบนมาตรฐานของค่าเฉลี่ยตัวอย่าง) และ1.96คือค่าโดยประมาณของ จุด เปอร์เซ็นไทล์ ที่ 97.5 ของการแจกแจงแบบปกติ :

- ขีดจำกัดบน 95% = , และ
- ขีดจำกัดล่าง 95% = .


โดยเฉพาะอย่างยิ่ง ค่าความคลาดเคลื่อนมาตรฐานของสถิติจากตัวอย่าง (เช่นค่าเฉลี่ยของตัวอย่าง ) คือค่าเบี่ยงเบนมาตรฐานที่แท้จริงหรือที่ประมาณการได้ของค่าเฉลี่ยของตัวอย่างในกระบวนการที่ใช้ในการสร้างค่าเฉลี่ยดังกล่าว กล่าวอีกนัยหนึ่งคือ เป็นค่าเบี่ยงเบนมาตรฐานที่แท้จริงหรือที่ประมาณการได้ของการแจกแจงตัวอย่างของสถิติจากตัวอย่าง สัญลักษณ์ที่ใช้แทนค่าความคลาดเคลื่อนมาตรฐานอาจเป็น SE, SEM (สำหรับค่าความคลาดเคลื่อนมาตรฐานของการวัดหรือค่าเฉลี่ย ) หรือ S Eก็ได้
ค่าความคลาดเคลื่อนมาตรฐานเป็นมาตรวัดความไม่แน่นอนของค่าอย่างง่าย และมักใช้เนื่องจาก:
- ในหลายกรณี หากทราบค่าความคลาดเคลื่อนมาตรฐานของปริมาณแต่ละอย่างแล้วก็สามารถคำนวณค่า ความคลาดเคลื่อนมาตรฐานของ ฟังก์ชัน ของปริมาณเหล่านั้นได้อย่างง่ายดาย
- เมื่อ ทราบ การกระจายความน่าจะเป็นของค่าแล้ว สามารถนำมาใช้คำนวณช่วงความเชื่อมั่น ที่แม่นยำ ได้
- เมื่อไม่ทราบการกระจายความน่าจะเป็นสามารถใช้ ความไม่เท่าเทียมกัน ของเชบิเชฟ หรือ ความไม่เท่าเทียมกันของวิโซชานสกี-เปตูนิน ในการคำนวณช่วงความเชื่อมั่นแบบอนุรักษ์นิยมได้ และ
- เมื่อขนาดตัวอย่างมีแนวโน้มเข้าสู่ค่าอนันต์ ทฤษฎีบทลิมิตกลางรับประกันว่าการแจกแจงตัวอย่างของค่าเฉลี่ยจะเป็นแบบปกติเชิง อะซิ้มโทติก
ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยเทียบกับค่าเบี่ยงเบนมาตรฐาน
ในเอกสารทางวิทยาศาสตร์และเทคนิค ข้อมูลการทดลองมักจะสรุปโดยใช้ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานของข้อมูลตัวอย่าง หรือค่าเฉลี่ยกับค่าความคลาดเคลื่อนมาตรฐาน ซึ่งมักนำไปสู่ความสับสนเกี่ยวกับการใช้แทนกันได้ อย่างไรก็ตาม ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานเป็นสถิติเชิงพรรณนาในขณะที่ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยเป็นการพรรณนาถึงกระบวนการสุ่มตัวอย่าง ส่วนเบี่ยงเบนมาตรฐานของข้อมูลตัวอย่างเป็นการอธิบายความแปรปรวนในการวัด ในขณะที่ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยเป็นการกล่าวถึงความน่าจะเป็นว่าขนาดตัวอย่างจะให้ขอบเขตที่ดีกว่าในการประมาณค่าเฉลี่ยของประชากรอย่างไร โดยพิจารณาจากทฤษฎีบทขีดจำกัดกลาง[ 8 ]
กล่าวโดยสรุป ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยตัวอย่างเป็นการประมาณว่าค่าเฉลี่ยตัวอย่างน่าจะห่างจากค่าเฉลี่ยประชากรมากน้อยเพียงใด ในขณะที่ค่าเบี่ยงเบนมาตรฐานของตัวอย่างคือระดับที่แต่ละบุคคลในตัวอย่างแตกต่างจากค่าเฉลี่ยตัวอย่าง[ 9 ]หากค่าเบี่ยงเบนมาตรฐานของประชากรมีค่าจำกัด ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยของตัวอย่างจะมีแนวโน้มเข้าใกล้ศูนย์เมื่อขนาดตัวอย่างเพิ่มขึ้น เนื่องจากค่าประมาณของค่าเฉลี่ยประชากรจะดีขึ้น ในขณะที่ค่าเบี่ยงเบนมาตรฐานของตัวอย่างจะมีแนวโน้มเข้าใกล้ค่าเบี่ยงเบนมาตรฐานของประชากรเมื่อขนาดตัวอย่างเพิ่มขึ้น
ส่วนขยาย
การแก้ไขประชากรจำกัด (FPC)
สูตรที่ให้ไว้ข้างต้นสำหรับค่าความคลาดเคลื่อนมาตรฐานนั้นตั้งอยู่บนสมมติฐานว่าประชากรมีจำนวนอนันต์ อย่างไรก็ตาม มักมีการใช้สูตรนี้กับประชากรที่มีจำนวนจำกัด เมื่อผู้คนสนใจที่จะวัดกระบวนการที่สร้างประชากรที่มีจำนวนจำกัดนั้นขึ้นมา (ซึ่งเรียกว่าการศึกษาเชิงวิเคราะห์ ) แม้ว่าสูตรข้างต้นจะไม่ถูกต้องอย่างแท้จริงเมื่อประชากรมีจำนวนจำกัด แต่ความแตกต่างระหว่างเวอร์ชันสำหรับประชากรที่มีจำนวนจำกัดและประชากรที่มีจำนวนอนันต์จะน้อยเมื่อสัดส่วนการสุ่มตัวอย่างมีขนาดเล็ก (เช่น ศึกษาเพียงส่วนน้อยของประชากรที่มีจำนวนจำกัด) ในกรณีนี้ ผู้คนมักจะไม่ทำการแก้ไขสำหรับประชากรที่มีจำนวนจำกัด โดยพื้นฐานแล้วจะถือว่าเป็นประชากรที่มีจำนวน "อนันต์โดยประมาณ"
หากสนใจวัดประชากรที่มีอยู่จำกัดซึ่งจะไม่เปลี่ยนแปลงไปตามเวลา จำเป็นต้องปรับค่าตามขนาดประชากร (เรียกว่าการศึกษาเชิงนับ ) เมื่อเศษส่วนการสุ่มตัวอย่าง (มักเรียกว่าf ) มีขนาดใหญ่ (ประมาณ 5% หรือมากกว่า) ในการศึกษาเชิงนับค่าประมาณของข้อผิดพลาดมาตรฐานจะต้องได้รับการแก้ไขโดยการคูณด้วย "การแก้ไขประชากรจำกัด" (หรือเรียกอีกอย่างว่าFPC ): [ 10 ] [ 11 ] ซึ่งสำหรับN ขนาดใหญ่ : เพื่อคำนึงถึงความแม่นยำที่เพิ่มขึ้นจากการสุ่มตัวอย่างใกล้เคียงกับเปอร์เซ็นต์ที่มากขึ้นของประชากร ผลของ FPC คือข้อผิดพลาดจะกลายเป็นศูนย์เมื่อขนาดตัวอย่างnเท่ากับขนาดประชากร N


ปรากฏการณ์นี้เกิดขึ้นในวิธีการสำรวจเมื่อทำการสุ่มตัวอย่างโดยไม่ใส่คืนหากทำการสุ่มตัวอย่างโดยใส่คืน ปรากฏการณ์ FPC จะไม่เกิดขึ้น
การแก้ไขความสัมพันธ์ในตัวอย่าง

หากค่าของปริมาณที่วัดได้Aไม่เป็นอิสระทางสถิติ แต่ได้มาจากตำแหน่งที่ทราบในพื้นที่พารามิเตอร์ xการประมาณค่าที่ไม่เอนเอียงของข้อผิดพลาดมาตรฐานที่แท้จริงของค่าเฉลี่ย (จริงๆ แล้วเป็นการแก้ไขส่วนของค่าเบี่ยงเบนมาตรฐาน) อาจได้มาจากการคูณข้อผิดพลาดมาตรฐานที่คำนวณได้ของตัวอย่างด้วยตัวประกอบ f : โดยที่สัมประสิทธิ์ความเอนเอียงของตัวอย่าง ρ คือ การประมาณค่าสัมประสิทธิ์สหสัมพันธ์ อัตโนมัติของPrais–Winsten ที่ใช้กันอย่างแพร่หลาย (ปริมาณระหว่าง −1 และ +1) สำหรับคู่จุดตัวอย่างทั้งหมด สูตรโดยประมาณนี้ใช้สำหรับขนาดตัวอย่างปานกลางถึงขนาดใหญ่ เอกสารอ้างอิงให้สูตรที่แน่นอนสำหรับขนาดตัวอย่างใดๆ และสามารถนำไปใช้กับอนุกรมเวลาที่มีสหสัมพันธ์อัตโนมัติสูง เช่น ราคาหุ้นในวอลล์สตรีท ยิ่งไปกว่านั้น สูตรนี้ใช้ได้กับ ρ ทั้งค่าบวกและค่าลบ[ 12 ]ดูการประมาณค่าเบี่ยงเบนมาตรฐานที่ไม่เอนเอียงสำหรับการอภิปรายเพิ่มเติม

ดูเพิ่มเติม
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ ข้อผิดพลาดมาตรฐาน
ค่าความคลาดเคลื่อนมาตรฐาน ( SE ) ของสถิติ (โดยปกติจะเป็นตัวประมาณค่าพารามิเตอร์เช่น ค่าเฉลี่ยหรือค่าเฉลี่ยเลขคณิต) คือค่าเบี่ยงเบนมาตรฐานของ การ แจกแจงตัวอย่าง...
ค่าที่แน่นอน
สมมติว่ามีการสุ่มตัวอย่างการสังเกต ที่เป็นอิสระทางสถิติ จาก ประชากรทางสถิติ ที่มี ส่วนเบี่ยงเบนมาตรฐาน เท่ากับ(ส่วนเบี่ยงเบนมาตรฐานของประชากร) ค่าเฉลี่ยที่คำนวณจากตัวอย่าง จะ มีข้อผิดพลาดมาตรฐานที่เกี่ยวข้อง กับ ค่า เฉลี่ย โดย กำหนดโดย: [ 1 ] n {\displaystyle...
ประมาณการ
โดยทั่วไปแล้ว ค่าเบี่ยงเบนมาตรฐานของประชากรที่ทำการสุ่มตัวอย่างมักไม่เป็นที่ทราบ ดังนั้น ค่าความคลาดเคลื่อนมาตรฐานของค่าเฉลี่ยจึงมักประมาณโดยการแทนที่ด้วย ค่าเบี่ยงเบนมาตรฐานของตัวอย่าง แทน: σ {\displaystyle \sigma } σ {\displaystyle \sigma } σ x...
อนุพันธ์
ข้อผิดพลาดมาตรฐานของค่าเฉลี่ยอาจได้มาจาก ความแปรปรวน ของผลรวมของตัวแปรสุ่มอิสระ [ 6 ] โดยพิจารณาจาก นิยาม ของความแปรปรวนและ คุณสมบัติ บางประการ หากเป็นตัวอย่างของการสังเกตอิสระจากประชากรที่มีค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานเราสามารถกำหนดผลรวมซึ่งเนื่องจาก...