อ่าน 11 นาที
แบบฟอร์มการมอบหมายงานเดี่ยวแบบคงที่
ในการออกแบบ คอมไพเลอร์ รูปแบบการกำหนดค่าแบบคงที่ครั้งเดียว (มักย่อว่า รูปแบบ SSA หรือ SSA เฉยๆ) เป็นรูป แบบการแสดงผลระดับกลาง (IR) ประเภทหนึ่งซึ่งแต่ละ ตัวแปร จะ ถูกกำหนดค่า...
แบบฟอร์มการมอบหมายงานเดี่ยวแบบคงที่
ในการออกแบบคอมไพเลอร์รูปแบบการกำหนดค่าแบบคงที่ครั้งเดียว (มักย่อว่ารูปแบบ SSAหรือSSA เฉยๆ) เป็นรูป แบบการแสดงผลระดับกลาง (IR) ประเภทหนึ่งซึ่งแต่ละตัวแปรจะถูกกำหนดค่าเพียงครั้งเดียวเท่านั้น SSA ถูกใช้ในคอมไพเลอร์ที่ปรับแต่งประสิทธิภาพคุณภาพสูงส่วนใหญ่สำหรับภาษาเชิงคำสั่ง รวมถึงLLVM , GNU Compiler Collectionและคอมไพเลอร์เชิงพาณิชย์จำนวนมาก
มีอัลกอริธึมที่มีประสิทธิภาพสำหรับการแปลงโปรแกรมให้อยู่ในรูปแบบ SSA ในการแปลงเป็น SSA ตัวแปรที่มีอยู่แล้วใน IR เดิมจะถูกแยกออกเป็นเวอร์ชันต่างๆ โดยตัวแปรใหม่มักจะระบุด้วยชื่อเดิมพร้อมตัวห้อย เพื่อให้ทุกคำจำกัดความมีเวอร์ชันของตัวเอง อาจจำเป็นต้องเพิ่มคำสั่งเพิ่มเติมที่กำหนดค่าให้กับเวอร์ชันใหม่ของตัวแปร ณ จุดเชื่อมต่อของเส้นทางควบคุมการไหลสองเส้นทาง การแปลงจากรูปแบบ SSA เป็นรหัสเครื่องก็มีประสิทธิภาพเช่นกัน
SSA ช่วยให้การวิเคราะห์ต่างๆ ที่จำเป็นสำหรับการปรับปรุงประสิทธิภาพทำได้ง่ายขึ้น เช่น การกำหนดห่วงโซ่การใช้งานและการกำหนดค่าเนื่องจากเมื่อพิจารณาการใช้งานตัวแปร จะมีเพียงที่เดียวเท่านั้นที่ตัวแปรนั้นอาจได้รับค่า การปรับปรุงประสิทธิภาพส่วนใหญ่สามารถปรับให้คงรูปแบบ SSA ไว้ได้ เพื่อให้สามารถดำเนินการปรับปรุงประสิทธิภาพหนึ่งต่อจากอีกแบบได้โดยไม่ต้องวิเคราะห์เพิ่มเติม การปรับปรุงประสิทธิภาพโดยใช้ SSA มักจะมีประสิทธิภาพและทรงพลังมากกว่าการปรับปรุงประสิทธิภาพในรูปแบบที่ไม่ใช้ SSA
ใน คอมไพเลอร์ ภาษาเชิงฟังก์ชันเช่น คอมไพเลอร์สำหรับScheme และ ML มัก ใช้ รูปแบบการส่งผ่านความต่อเนื่อง (CPS) SSA เทียบเท่ากับชุดย่อยที่มีพฤติกรรมที่ดีของ CPS โดยไม่รวมการควบคุมการไหลที่ไม่ใช่แบบโลคอล ดังนั้นการเพิ่มประสิทธิภาพและการแปลงที่กำหนดขึ้นตามรูปแบบหนึ่งโดยทั่วไปจะนำไปใช้กับอีกรูปแบบหนึ่ง การใช้ CPS เป็นตัวแทนระดับกลางเป็นธรรมชาติมากกว่าสำหรับฟังก์ชันลำดับสูงและการวิเคราะห์ระหว่างขั้นตอน CPS ยังเข้ารหัสcall/cc ได้ง่าย ในขณะที่ SSA ทำไม่ได้[ 1 ]
ประวัติศาสตร์
SSA ได้รับการพัฒนาในช่วงทศวรรษ 1980 โดยนักวิจัยหลายคนของIBM Kenneth Zadeck ซึ่งเป็นสมาชิกคนสำคัญของทีม ได้ย้ายไปที่มหาวิทยาลัย Brown ในขณะที่การพัฒนายังคงดำเนินต่อไป[ 2 ] [ 3 ]บทความในปี 1986 ได้นำเสนอ birthpoints, identity assignments และการเปลี่ยนชื่อตัวแปรเพื่อให้ตัวแปรมีการกำหนดค่าคงที่เพียงครั้งเดียว[ 4 ]บทความต่อมาในปี 1987 โดยJeanne Ferranteและ Ronald Cytron [ 5 ]พิสูจน์ว่าการเปลี่ยนชื่อที่ทำในบทความก่อนหน้านี้ช่วยขจัดความสัมพันธ์ที่ผิดพลาดทั้งหมดสำหรับสเกลาร์[ 3 ]ในปี 1988 Barry Rosen, Mark N. Wegmanและ Kenneth Zadeck ได้แทนที่การกำหนดค่าคงที่ด้วยฟังก์ชัน Φ แนะนำชื่อ "static single-assignment form" และสาธิตการเพิ่มประสิทธิภาพ SSA ที่ใช้กันทั่วไปในปัจจุบัน[ 6 ] Rosen เลือกชื่อ Φ-function เพื่อให้เป็นเวอร์ชันที่เผยแพร่ได้ง่ายกว่าของ "phony function" [ 3 ] Alpern, Wegman และ Zadeck นำเสนอการปรับปรุงประสิทธิภาพอีกวิธีหนึ่ง แต่ใช้ชื่อว่า "การกำหนดค่าเดี่ยวแบบคงที่" [ 7 ]ในที่สุด ในปี 1989 Rosen, Wegman, Zadeck, Cytron และ Ferrante ก็พบวิธีที่มีประสิทธิภาพในการแปลงโปรแกรมให้เป็นรูปแบบ SSA [ 8 ]
ประโยชน์
ประโยชน์หลักของ SSA มาจากการทำให้ผลลัพธ์ของ การเพิ่มประสิทธิภาพคอมไพเลอร์หลายอย่างง่ายขึ้นและดีขึ้นพร้อมกันโดยการทำให้คุณสมบัติของตัวแปรง่ายขึ้น ตัวอย่างเช่น ลองพิจารณาโค้ดต่อไปนี้:
y := 1 y := 2 x := y
มนุษย์สามารถมองเห็นได้ว่าการกำหนดค่าแรกนั้นไม่จำเป็น และคุณค่าของyการถูกนำไปใช้ในบรรทัดที่สามนั้นมาจากการกำหนดค่าที่สองของตัวแปรy`var` โปรแกรมจะต้องทำการวิเคราะห์คำจำกัดความอย่างละเอียดเพื่อตรวจสอบเรื่องนี้ แต่ถ้าโปรแกรมอยู่ในรูปแบบ SSA ทั้งสองอย่างนี้จะเกิดขึ้นทันที:
y 1 := 1 y 2 := 2 x 1 := y 2
อัลกอริทึม การเพิ่มประสิทธิภาพของคอมไพเลอร์ที่ถูกเปิดใช้งานหรือได้รับการปรับปรุงอย่างมากโดยการใช้ SSA ได้แก่:
- การพับค่าคงที่ – การแปลงการคำนวณจากเวลาทำงานไปเป็นเวลาคอมไพล์ เช่น การพิจารณาคำสั่งเสมือน
a=3*4+5;ว่าเป็น คำสั่งa=17; - การแพร่กระจายช่วงค่า[ 9 ] – คำนวณช่วงที่เป็นไปได้ของการคำนวณล่วงหน้า ทำให้สามารถสร้างการคาดการณ์สาขาได้ล่วงหน้า
- การแพร่กระจายค่าคงที่แบบมีเงื่อนไขแบบเบาบาง – ตรวจสอบช่วงของค่าบางค่า ทำให้การทดสอบสามารถคาดการณ์สาขาที่น่าจะเป็นไปได้มากที่สุด
- การกำจัดโค้ดที่ไม่ใช้งาน – ลบโค้ดที่ไม่มีผลต่อผลลัพธ์
- การกำหนดหมายเลขค่าทั่วโลก – แทนที่การคำนวณที่ซ้ำกันซึ่งให้ผลลัพธ์เดียวกัน
- การกำจัดความซ้ำซ้อนบางส่วน – การลบการคำนวณที่ซ้ำซ้อนซึ่งเคยดำเนินการไปแล้วในบางส่วนของโปรแกรม
- การลดความซับซ้อนของการคำนวณ – การแทนที่การดำเนินการที่ใช้ต้นทุนสูงด้วยการดำเนินการที่ใช้ต้นทุนต่ำกว่าแต่มีประสิทธิภาพเทียบเท่ากัน เช่น แทนที่การคูณหรือหารจำนวนเต็มด้วยกำลังของ 2 ด้วยการเลื่อนบิตไปทางซ้าย (สำหรับการคูณ) หรือเลื่อนบิตไปทางขวา (สำหรับการหาร) ซึ่งอาจใช้ต้นทุนต่ำกว่า
- การจัดสรรรีจิสเตอร์ – เพิ่มประสิทธิภาพการใช้งานรีจิสเตอร์จำนวนจำกัดของเครื่องคอมพิวเตอร์สำหรับการคำนวณ
การแปลงเป็น SSA
การแปลงโค้ดธรรมดาให้เป็นรูปแบบ SSA นั้น ส่วนใหญ่เป็นเรื่องของการแทนที่เป้าหมายของการกำหนดค่าแต่ละครั้งด้วยตัวแปรใหม่ และแทนที่การใช้งานตัวแปรแต่ละครั้งด้วย "เวอร์ชัน" ของตัวแปรที่มาถึงจุดนั้น ตัวอย่างเช่น พิจารณาแผนผังการไหลของโปรแกรม ต่อไปนี้ :

การเปลี่ยนชื่อทางด้านซ้ายของ "x x - 3" และการเปลี่ยนการใช้งานx ต่อ ไปเป็นชื่อใหม่นั้น จะทำให้โปรแกรมไม่เปลี่ยนแปลง สามารถใช้ประโยชน์จากสิ่งนี้ใน SSA ได้โดยการสร้างตัวแปรใหม่สองตัวคือx 1และx 2ซึ่งแต่ละตัวจะถูกกำหนดค่าเพียงครั้งเดียว ในทำนองเดียวกัน การกำหนดดัชนีที่แตกต่างกันให้กับตัวแปรอื่นๆ ทั้งหมดจะได้ผลลัพธ์ดังนี้:

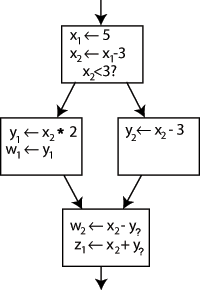
เป็นที่ชัดเจนว่าการใช้งานแต่ละครั้งหมายถึงความหมายใด ยกเว้นกรณีเดียว: การใช้งานy ทั้งสองครั้ง ในบล็อกด้านล่างอาจหมายถึงy 1หรือy 2 ก็ได้ ขึ้นอยู่กับเส้นทางการไหลของการควบคุม
เพื่อแก้ไขปัญหานี้ จึงมีการแทรกคำสั่งพิเศษในบล็อกสุดท้าย เรียกว่าฟังก์ชัน Φ (Phi)คำสั่งนี้จะสร้างนิยามใหม่ของyที่เรียกว่าy 3โดย "เลือก" y 1หรือy 2ขึ้นอยู่กับการควบคุมการไหลในอดีต
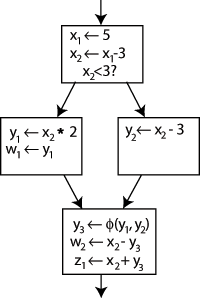
ตอนนี้ บล็อกสุดท้ายสามารถใช้y 3 ได้เลย และจะได้ค่าที่ถูกต้องไม่ว่าด้วยวิธีใดก็ตามไม่จำเป็นต้องใช้ ฟังก์ชัน Φ สำหรับ x เพราะมีเพียง x เวอร์ชันเดียวเท่านั้น คือx 2ที่มาถึงจุดนี้ ดังนั้นจึงไม่มีปัญหา (กล่าวอีกนัยหนึ่งคือ Φ( x 2 , x 2 )= x 2 )
เมื่อกำหนดกราฟควบคุมการไหลแบบใดก็ได้ อาจเป็นเรื่องยากที่จะบอกว่าควรแทรกฟังก์ชัน Φ ไว้ที่ใดและสำหรับตัวแปรใด คำถามทั่วไปนี้มีวิธีแก้ปัญหาที่มีประสิทธิภาพซึ่งสามารถคำนวณได้โดยใช้แนวคิดที่เรียกว่าขอบเขตการครอบงำ (ดูด้านล่าง)
ฟังก์ชัน Φ ไม่ได้ถูกนำไปใช้เป็นการดำเนินการของเครื่องจักรบนเครื่องคอมพิวเตอร์ส่วนใหญ่ คอมไพเลอร์สามารถใช้งานฟังก์ชัน Φ ได้โดยการแทรกการดำเนินการ "ย้าย" ไว้ที่ส่วนท้ายของบล็อกก่อนหน้าทุกบล็อก ในตัวอย่างข้างต้น คอมไพเลอร์อาจแทรกการย้ายจากy 1ไปยังy 3ที่ส่วนท้ายของบล็อกด้านซ้ายตรงกลาง และการย้ายจากy 2ไปยังy 3ที่ส่วนท้ายของบล็อกด้านขวาตรงกลาง การดำเนินการย้ายเหล่านี้อาจไม่ปรากฏในโค้ดสุดท้าย ขึ้นอยู่กับ ขั้นตอน การจัดสรรรีจิสเตอร์ ของคอมไพเลอร์ อย่างไรก็ตาม วิธีการนี้อาจใช้ไม่ได้ผลเมื่อมีการดำเนินการพร้อมกันที่สร้างอินพุตแบบคาดการณ์ล่วงหน้าให้กับฟังก์ชัน Φ ซึ่งอาจเกิดขึ้นใน เครื่องจักร แบบ wide-issueโดยทั่วไป เครื่องจักรแบบ wide-issue จะมีคำสั่งการเลือกที่คอมไพเลอร์ใช้ในสถานการณ์ดังกล่าวเพื่อใช้งานฟังก์ชัน Φ
การคำนวณค่า SSA ขั้นต่ำโดยใช้ขอบเขตความเหนือกว่า
ในกราฟควบคุมการไหล โหนด A กล่าวได้ว่าครอบงำโหนด B อย่างเด็ดขาด หากเป็นไปไม่ได้ที่จะไปถึงโหนด B โดยไม่ผ่านโหนด A ก่อน กล่าวอีกนัยหนึ่ง หากไปถึงโหนด B ได้แล้ว ก็สามารถสันนิษฐานได้ว่าโหนด A ทำงานเสร็จแล้ว โหนด A กล่าวได้ว่า ครอบงำโหนด B (หรือโหนด B ถูกครอบงำโดยโหนด A) หาก A ครอบงำ B อย่างเด็ดขาด หรือ A = B
โหนดที่ถ่ายโอนการควบคุมไปยังโหนด A เรียกว่าโหนดก่อนหน้าโดยตรงของ A
เส้นขอบเขตการครอบงำของโหนด A คือเซตของโหนด B ที่ A ไม่ได้ครอบงำ B อย่างเด็ดขาด แต่ครอบงำโหนดก่อนหน้าของ B โดยตรง จุดเหล่านี้คือจุดที่เส้นทางควบคุมหลายเส้นทางมารวมกันเป็นเส้นทางเดียว
ตัวอย่างเช่น ในโค้ดต่อไปนี้:
[1] x = random() ถ้า x < 0.5 [2] ผลลัพธ์ = "หัว" อื่น [3] ผลลัพธ์ = "หาง" จบ [4] พิมพ์(ผลลัพธ์)
โหนด 1 มีอำนาจเหนือกว่าโหนด 2, 3 และ 4 อย่างเด็ดขาด และโหนดที่อยู่ก่อนหน้าโหนด 4 โดยตรงคือโหนด 2 และ 3
ขอบเขตการครอบงำกำหนดจุดที่จำเป็นต้องใช้ฟังก์ชัน Φ ในตัวอย่างข้างต้น เมื่อการควบคุมถูกส่งต่อไปยังโหนด 4 นิยามของฟังก์ชันresultที่ใช้จะขึ้นอยู่กับว่าการควบคุมถูกส่งต่อจากโหนด 2 หรือ 3 ฟังก์ชัน Φ ไม่จำเป็นสำหรับตัวแปรที่กำหนดไว้ในตัวครอบงำ เนื่องจากมีเพียงนิยามเดียวที่เป็นไปได้เท่านั้นที่สามารถนำมาใช้ได้
มีอัลกอริทึมที่มีประสิทธิภาพสำหรับการค้นหาขอบเขตการครอบงำของแต่ละโหนด อัลกอริทึมนี้ได้รับการอธิบายไว้ครั้งแรกใน "การคำนวณแบบฟอร์มการกำหนดเดี่ยวแบบคงที่และกราฟควบคุมอย่างมีประสิทธิภาพ" โดย Ron Cytron, Jeanne Ferrante และคณะในปี 1991 [ 10 ]
Keith D. Cooper, Timothy J. Harvey และ Ken Kennedy จากRice Universityอธิบายอัลกอริทึมในบทความของพวกเขาที่มีชื่อว่าA Simple, Fast Dominance Algorithm : [ 11 ]
สำหรับแต่ละโหนด b ขอบเขตอำนาจ (b) := {} สำหรับแต่ละโหนด b ถ้าจำนวนโหนดก่อนหน้าโดยตรงของ b ≥ 2 สำหรับแต่ละ p ในโหนดก่อนหน้าโดยตรงของ b นักวิ่ง := p ในขณะที่นักวิ่ง ≠ idom(b) ขอบเขตความเด่น (ผู้วิ่ง) := ขอบเขตความเด่น (ผู้วิ่ง) ∪ { b } runner := idom(runner) ในโค้ดด้านบนidom(b)คือ โหนด ครอบงำโดยตรงของ b ซึ่งเป็นโหนดเดียวที่ครอบงำ b อย่างเคร่งครัด แต่ไม่ครอบงำโหนดอื่นใดที่ครอบงำ b อย่างเคร่งครัด
รูปแบบต่างๆ ที่ลดจำนวนฟังก์ชัน Φ ลง
SSA แบบ "ขั้นต่ำ" จะแทรกฟังก์ชัน Φ จำนวนน้อยที่สุดเท่าที่จำเป็นเพื่อให้แน่ใจว่าแต่ละชื่อได้รับการกำหนดค่าเพียงครั้งเดียว และการอ้างอิง (การใช้งาน) ชื่อแต่ละครั้งในโปรแกรมดั้งเดิมยังคงสามารถอ้างอิงถึงชื่อที่ไม่ซ้ำกันได้ (ข้อกำหนดหลังนี้จำเป็นเพื่อให้แน่ใจว่าคอมไพเลอร์สามารถเขียนชื่อสำหรับตัวถูกดำเนินการแต่ละตัวในแต่ละการดำเนินการได้)
อย่างไรก็ตาม ฟังก์ชัน Φ บางส่วนอาจไม่มีประโยชน์ด้วยเหตุนี้ การใช้ SSA ขั้นต่ำจึงไม่ได้หมายความว่าจะได้ฟังก์ชัน Φ ที่น้อยที่สุดที่จำเป็นสำหรับกระบวนการเฉพาะนั้นๆ เสมอไป สำหรับการวิเคราะห์บางประเภท ฟังก์ชัน Φ เหล่านี้อาจเกินความจำเป็นและทำให้การวิเคราะห์ทำงานได้ไม่เต็มประสิทธิภาพ
SSA ที่ตัดแต่งแล้ว
รูปแบบ SSA ที่ตัดแต่งแล้วนั้นอิงตามข้อสังเกตง่ายๆ ว่า ฟังก์ชัน Φ จำเป็นสำหรับตัวแปรที่ "มีชีวิต" หลังจากฟังก์ชัน Φ เท่านั้น (ในที่นี้ "มีชีวิต" หมายความว่าค่าถูกนำไปใช้ตามเส้นทางใดเส้นทางหนึ่งที่เริ่มต้นจากฟังก์ชัน Φ นั้นๆ) หากตัวแปรไม่มีชีวิต ผลลัพธ์ของฟังก์ชัน Φ จะไม่สามารถนำไปใช้ได้ และการกำหนดค่าโดยฟังก์ชัน Φ นั้นก็ไร้ประโยชน์
การสร้างฟอร์ม SSA ที่ตัดแต่งแล้วจะใช้ข้อมูลตัวแปรที่มีชีวิตในขั้นตอนการแทรกฟังก์ชัน Φ เพื่อตัดสินใจว่าจำเป็นต้องใช้ฟังก์ชัน Φ ที่กำหนดหรือไม่ หากชื่อตัวแปรเดิมไม่มีชีวิต ณ จุดที่แทรกฟังก์ชัน Φ ฟังก์ชัน Φ จะไม่ถูกแทรก
อีกความเป็นไปได้หนึ่งคือการมองการตัดแต่งกิ่งเป็น ปัญหา การกำจัดโค้ดที่ไม่ได้ใช้งานในกรณีนี้ ฟังก์ชัน Φ จะถือว่าใช้งานได้ก็ต่อเมื่อมีการใช้งานใดๆ ในโปรแกรมอินพุตที่จะถูกเขียนใหม่ไปยังฟังก์ชันนั้น หรือหากจะถูกใช้เป็นอาร์กิวเมนต์ในฟังก์ชัน Φ อื่นๆ เมื่อเข้าสู่รูปแบบ SSA การใช้งานแต่ละครั้งจะถูกเขียนใหม่ไปยังนิยามที่ใกล้เคียงที่สุดที่ครอบคลุมการใช้งานนั้น ฟังก์ชัน Φ จะถือว่าใช้งานได้ตราบใดที่เป็นนิยามที่ใกล้เคียงที่สุดที่ครอบคลุมการใช้งานอย่างน้อยหนึ่งครั้ง หรืออย่างน้อยหนึ่งอาร์กิวเมนต์ของฟังก์ชัน Φ ที่ใช้งานได้
SSA ที่ตัดแต่งกิ่งบางส่วน
รูปแบบ SSA แบบกึ่งตัดแต่ง[ 12 ]เป็นความพยายามที่จะลดจำนวนฟังก์ชัน Φ โดยไม่ต้องเสียค่าใช้จ่ายที่ค่อนข้างสูงในการคำนวณข้อมูลตัวแปรที่มีชีวิต โดยอิงตามข้อสังเกตต่อไปนี้: หากตัวแปรไม่เคยมีชีวิตเมื่อเข้าสู่บล็อกพื้นฐาน ตัวแปรนั้นก็ไม่จำเป็นต้องมีฟังก์ชัน Φ ในระหว่างการสร้าง SSA ฟังก์ชัน Φ สำหรับตัวแปร "เฉพาะบล็อก" ใดๆ จะถูกละเว้น
การคำนวณชุดตัวแปรเฉพาะบล็อกเป็นกระบวนการที่ง่ายและเร็วกว่าการวิเคราะห์ตัวแปรแบบเต็มรูปแบบ ทำให้รูปแบบ SSA แบบกึ่งตัดแต่งมีประสิทธิภาพในการคำนวณมากกว่ารูปแบบ SSA แบบตัดแต่ง ในทางกลับกัน รูปแบบ SSA แบบกึ่งตัดแต่งจะมีฟังก์ชัน Φ มากกว่า
การโต้แย้งแบบบล็อก
อาร์กิวเมนต์แบบบล็อกเป็นทางเลือกแทนฟังก์ชัน Φ ซึ่งมีลักษณะการแสดงผลเหมือนกัน แต่ในทางปฏิบัติอาจสะดวกกว่าในระหว่างการเพิ่มประสิทธิภาพ บล็อกจะถูกตั้งชื่อและรับรายการอาร์กิวเมนต์แบบบล็อก ซึ่งเขียนแทนพารามิเตอร์ของฟังก์ชัน เมื่อเรียกใช้บล็อก อาร์กิวเมนต์แบบบล็อกจะถูกผูกกับค่าที่ระบุMLton , Swift SIL และMLIRใช้อาร์กิวเมนต์แบบบล็อก[ 13 ] อาร์กิวเมนต์แบบบล็อกทำให้ความเชื่อมโยงกับรูปแบบการส่งผ่านความต่อเนื่อง (CPS) ชัดเจนยิ่งขึ้น: บล็อกพื้นฐานคือฟังก์ชัน ตัวแปรฟังก์ชันคืออาร์กิวเมนต์แบบบล็อก (ฟังก์ชัน Φ)
การเปลี่ยนจากแบบฟอร์ม SSA
โดยปกติแล้วรูปแบบ SSA จะไม่ถูกใช้สำหรับการดำเนินการโดยตรง (แม้ว่าจะสามารถตีความ SSA ได้ก็ตาม[ 14 ] ) และมักจะถูกใช้ "บน" IR อื่นซึ่งยังคงสอดคล้องกันโดยตรง สามารถทำได้โดยการ "สร้าง" SSA เป็นชุดฟังก์ชันที่แมปส่วนต่างๆ ของ IR ที่มีอยู่ (บล็อกพื้นฐาน คำสั่ง ตัวดำเนินการฯลฯ ) กับส่วน SSA ที่เทียบเท่ากัน เมื่อไม่จำเป็นต้องใช้รูปแบบ SSA อีกต่อไป ฟังก์ชันการแมปเหล่านี้อาจถูกทิ้งไป เหลือเพียง IR ที่ได้รับการปรับให้เหมาะสมแล้ว
การดำเนินการเพิ่มประสิทธิภาพบนรูปแบบ SSA มักนำไปสู่ SSA-Web ที่พันกัน หมายความว่ามีคำสั่ง Φ ที่ตัวถูกดำเนินการไม่ได้มีตัวถูกดำเนินการรากเดียวกันทั้งหมด ในกรณีเช่นนี้ จะใช้อัลกอริธึมแบบ color-outเพื่อออกจาก SSA อัลกอริธึมแบบง่ายๆ จะแนะนำสำเนาตามเส้นทางก่อนหน้าแต่ละเส้นทาง ซึ่งทำให้แหล่งที่มาของสัญลักษณ์รากที่แตกต่างกันถูกใส่ใน Φ มากกว่าปลายทางของ Φ มีอัลกอริธึมหลายตัวสำหรับการออกจาก SSA ด้วยสำเนาที่น้อยลง ส่วนใหญ่ใช้กราฟการรบกวนหรือการประมาณค่าบางอย่างเพื่อทำการรวมสำเนา[ 15 ]
ส่วนขยาย
การขอขยายความแบบฟอร์ม SSA สามารถแบ่งออกได้เป็นสองประเภท
ส่วนขยายของ รูปแบบการเปลี่ยนชื่อจะเปลี่ยนแปลงเกณฑ์การเปลี่ยนชื่อ โปรดจำไว้ว่าแบบฟอร์ม SSA จะเปลี่ยนชื่อตัวแปรแต่ละตัวเมื่อมีการกำหนดค่าให้กับตัวแปรนั้น รูปแบบทางเลือกอื่นๆ ได้แก่ แบบฟอร์มใช้งานครั้งเดียวแบบคงที่ (ซึ่งจะเปลี่ยนชื่อตัวแปรแต่ละตัวในแต่ละคำสั่งเมื่อมีการใช้งาน) และแบบฟอร์มข้อมูลเดียวแบบคงที่ (ซึ่งจะเปลี่ยนชื่อตัวแปรแต่ละตัวเมื่อมีการกำหนดค่า และที่ขอบเขตหลังการครอบงำ)
ส่วนขยาย เฉพาะคุณลักษณะยังคงรักษาคุณสมบัติการกำหนดค่าเดียวสำหรับตัวแปร แต่รวมความหมายใหม่เพื่อจำลองคุณลักษณะเพิ่มเติม ส่วนขยายเฉพาะคุณลักษณะบางอย่างจำลองคุณลักษณะของภาษาโปรแกรมระดับสูง เช่น อาร์เรย์ อ็อบเจ็กต์ และพอยเตอร์ที่มีนามแฝง ส่วนขยายเฉพาะคุณลักษณะอื่นๆ จำลองคุณลักษณะทางสถาปัตยกรรมระดับต่ำ เช่น การคาดการณ์และการทำนาย
คอมไพเลอร์ที่ใช้ฟอร์ม SSA
โอเพนซอร์ส
- Monoใช้ SSA ในคอมไพเลอร์ JIT ของตนที่ชื่อ Mini
- WebKitใช้ SSA ในคอมไพเลอร์ JIT ของมัน[ 16 ] [ 17 ]
- Swiftกำหนดรูปแบบ SSA ของตัวเองเหนือ LLVM IR เรียกว่า SIL (Swift Intermediate Language) [ 18 ] [ 19 ]
- คอม ไพเลอร์ Erlangได้รับการเขียนใหม่ใน OTP 22.0 เพื่อ "ใช้การแสดงผลระดับกลางภายในโดยอิงตาม Static Single Assignment (SSA)" โดยมีแผนการเพิ่มประสิทธิภาพเพิ่มเติมที่สร้างขึ้นบน SSA ในเวอร์ชันต่อๆ ไป[ 20 ]
- โครงสร้างพื้นฐานคอมไพเลอ ร์ LLVMใช้รูปแบบ SSA สำหรับค่ารีจิสเตอร์แบบสเกลาร์ทั้งหมด (ยกเว้นหน่วยความจำ) ในการแสดงโค้ดหลัก รูปแบบ SSA จะถูกกำจัดออกไปก็ต่อเมื่อมีการจัดสรรรีจิสเตอร์เกิดขึ้น ซึ่งมักเกิดขึ้นในช่วงท้ายของกระบวนการคอมไพล์ (ส่วนใหญ่มักเกิดขึ้นในขั้นตอนการเชื่อมโยง)
- ชุดคอมไพเลอร์ GNU (GCC) ใช้ SSA อย่างกว้างขวางตั้งแต่เวอร์ชัน 4 (เปิดตัวในเดือนเมษายน 2548) ส่วนหน้าจะสร้างโค้ด " GENERIC " ซึ่งจะถูกแปลงเป็นโค้ด " GIMPLE " โดย "gimplifier" จากนั้นจะมีการใช้การปรับแต่งระดับสูงกับโค้ด "GIMPLE" ในรูปแบบ SSA โค้ดระดับกลางที่ได้รับการปรับแต่งแล้วจะถูกแปลงเป็นRTL จากนั้นจะมีการใช้การปรับแต่งระดับต่ำกับ RTL และสุดท้าย ส่วนหลังที่เฉพาะเจาะจงกับสถาปัตยกรรมจะแปลง RTL เป็นภาษาแอสเซมบลี
- Go (1.7: สำหรับ สถาปัตยกรรม x86-64เท่านั้น; 1.8: สำหรับสถาปัตยกรรมที่รองรับทั้งหมด) [ 21 ] [ 22 ]
- Jikes RVM ซึ่ง เป็นเครื่องเสมือน Java แบบปรับตัวได้แบบโอเพนซอร์สของIBMใช้ Extended Array SSA ซึ่งเป็นส่วนขยายของ SSA ที่ช่วยให้สามารถวิเคราะห์ค่าสเกลาร์ อาร์เรย์ และฟิลด์ของออบเจ็กต์ในกรอบการทำงานที่เป็นหนึ่งเดียว การวิเคราะห์ Extended Array SSA จะเปิดใช้งานเฉพาะในระดับการเพิ่มประสิทธิภาพสูงสุดเท่านั้น ซึ่งจะนำไปใช้กับส่วนของโค้ดที่ถูกเรียกใช้งานบ่อยที่สุด
- เอ็นจิ้น JavaScript SpiderMonkeyของMozilla Firefox ใช้ IR ที่ใช้ SSA [ 23 ]
- เอ็นจิ้น JavaScript Chromium V8ใช้SSA ในโครงสร้างพื้นฐานคอมไพเลอร์ Crankshaft ตาม ที่ประกาศใน เดือนธันวาคม 2010
- PyPyใช้การแสดงผลแบบ SSA เชิงเส้นสำหรับข้อมูลการติดตามในคอมไพเลอร์ JIT ของมัน
- Android Runtime [ 24 ]และDalvik Virtual Machineใช้ SSA [ 25 ]
- คอมไพเลอร์ MLtonซึ่งเป็นมาตรฐานของภาษา ML ใช้ SSA ในภาษาตัวกลางภาษาหนึ่งของมัน
- LuaJITใช้การเพิ่มประสิทธิภาพตาม SSA อย่างมาก[ 26 ]
- คอมไพเลอร์PHPและHack HHVMใช้ SSA ใน IR ของมัน[ 27 ]
- คอมไพเลอ ร์ OCamlใช้SSA ใน CMM IR (ซึ่งย่อมาจาก C--) [ 28 ]
- libFirm ซึ่งเป็นไลบรารีที่ใช้เป็นมิดเดิลเอนด์และแบ็กเอนด์ของคอมไพเลอร์ใช้รูปแบบ SSA สำหรับค่ารีจิสเตอร์สเกลาร์ทั้งหมดจนกว่าจะมีการสร้างโค้ดโดยใช้ตัวจัดสรรรีจิสเตอร์ที่รองรับ SSA [ 29 ]
- ไดรเวอร์ Mesaต่างๆผ่าน NIR ซึ่งเป็นการแสดง SSA สำหรับภาษาการแรเงา[ 30 ]
ทางการค้า
- เครื่องเสมือน Java HotSpotของOracleใช้ภาษาตัวกลางแบบ SSA ในคอมไพเลอร์ JIT [ 31 ]
- แบ็กเอนด์คอมไพเลอร์ Microsoft Visual C++ที่มีอยู่ในMicrosoft Visual Studio 2015 Update 3 ใช้ SSA [ 32 ]
- SPIR-Vซึ่งเป็นมาตรฐานภาษาแรเงาสำหรับAPI กราฟิก Vulkanและภาษาเคอร์เนลสำหรับ API การคำนวณ OpenCLเป็นการแทน SSA [ 33 ]
- DXILซึ่งเป็นภาษาสำหรับการสร้างเฉดสีของ Microsoft DirectX Shader Compilerใช้การแสดงแทนแบบ SSA เนื่องจากเป็นการแตกแขนงมาจาก LLVM [ 34 ]
- ตระกูลคอมไพ เลอร์ XL ของ IBM ซึ่งรวมถึงC, C++และFortran [ 35 ]
- NVIDIA CUDA [ 36 ]
งานวิจัยและถูกละทิ้ง
- คอมไพเลอร์ ETH Oberon-2เป็นหนึ่งในโครงการสาธารณะแรกๆ ที่นำ "GSA" ซึ่งเป็นรูปแบบหนึ่งของ SSA มาใช้
- คอม ไพเลอร์ Open64ใช้รูปแบบ SSA ในตัวเพิ่มประสิทธิภาพสเกลาร์ทั่วโลก แม้ว่าโค้ดจะถูกแปลงเป็นรูปแบบ SSA ก่อนและนำออกจากรูปแบบ SSA ในภายหลังก็ตาม Open64 ใช้ส่วนขยายของรูปแบบ SSA เพื่อแสดงหน่วยความจำในรูปแบบ SSA เช่นเดียวกับค่าสเกลาร์
- ในปี 2002 นักวิจัยได้ดัดแปลง JikesRVM ของ IBM (ซึ่งในขณะนั้นมีชื่อว่า Jalapeño) ให้สามารถทำงานได้ทั้งไบต์โค้ด Java มาตรฐาน และไฟล์คลาสไบต์โค้ด SSA ที่ปลอดภัยต่อประเภทข้อมูล ( SafeTSA ) และแสดงให้เห็นถึงประโยชน์ด้านประสิทธิภาพที่สำคัญจากการใช้ไบต์โค้ด SSA
- jackccเป็นคอมไพเลอร์โอเพนซอร์สสำหรับชุดคำสั่งทางวิชาการ Jackal 3.0 มันใช้โค้ดแบบ 3 ตัวดำเนินการอย่างง่าย โดยใช้ SSA เป็นตัวแทนระดับกลาง และที่น่าสนใจคือ มันแทนที่ฟังก์ชัน Φ ด้วยคำสั่งที่เรียกว่า SAME ซึ่งสั่งให้ตัวจัดสรรรีจิสเตอร์วางช่วงข้อมูลสองช่วงไว้ในรีจิสเตอร์ทางกายภาพเดียวกัน
- โปรแกรม รวบรวมคอนเสิร์ตของรัฐอิลลินอยส์ราวปี 1994 [ 37 ]ใช้ SSA รูปแบบหนึ่งที่เรียกว่า SSU (Static Single Use) ซึ่งจะเปลี่ยนชื่อตัวแปรแต่ละตัวเมื่อมีการกำหนดค่าให้กับตัวแปรนั้น และในแต่ละบริบทเงื่อนไขที่ใช้ตัวแปรนั้น โดยพื้นฐานแล้วคือรูปแบบข้อมูลเดียวแบบคงที่ที่กล่าวถึงข้างต้น รูปแบบ SSU ได้รับการบันทึกไว้ในวิทยานิพนธ์ปริญญาเอกของ John Plevyak
- คอมไพเลอร์ COINS ใช้การปรับแต่งรูปแบบ SSA ตามที่อธิบายไว้ในที่นี้
- คอมไพเลอร์ R-Stream ของ Reservoir Labs รองรับรูปแบบที่ไม่ใช่ SSA (รายการควอด), SSA และ SSI (Static Single Information [ 38 ] ) [ 39 ]
- แม้ว่า Boomerangจะไม่ใช่คอมไพเลอร์ แต่ดีคอมไพเลอร์ใช้รูปแบบ SSA ในการแสดงผลภายใน SSA ใช้เพื่อลดความซับซ้อนในการส่งต่อการแสดงออก การระบุพารามิเตอร์และค่าส่งคืน การวิเคราะห์การรักษา และอื่นๆ
- DotGNU Portable.NET ใช้ SSA ในคอมไพเลอร์ JIT ของมัน
ดูเพิ่มเติม
- รูปแบบการส่งผ่านความต่อเนื่อง – รูปแบบเทียบเท่าที่ใช้ส่วนใหญ่ในภาษาการเขียนโปรแกรมเชิงฟังก์ชัน
- รูปแบบปกติ
ลิงก์ภายนอก
- บอสเชอร์, สตีเวน และ โนวิลโล, ดิเอโก. GCC ได้รับเฟรมเวิร์กตัวเพิ่มประสิทธิภาพใหม่บทความเกี่ยวกับการใช้งาน SSA ของ GCC และวิธีการปรับปรุงให้ดีขึ้นกว่า IR รุ่นเก่า
- บรรณานุกรม SSA : แคตตาล็อกที่ครอบคลุมของเอกสารงานวิจัย SSA
- Zadeck, F. Kenneth. "การพัฒนาแบบฟอร์มการมอบหมายเดี่ยวแบบคงที่" , การบรรยายในเดือนธันวาคม 2550 เกี่ยวกับที่มาของ SSA
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ แบบฟอร์มการมอบหมายงานเดี่ยวแบบคงที่
ในการออกแบบ คอมไพเลอร์ รูปแบบการกำหนดค่าแบบคงที่ครั้งเดียว (มักย่อว่า รูปแบบ SSA หรือ SSA เฉยๆ) เป็นรูป แบบการแสดงผลระดับกลาง (IR) ประเภทหนึ่งซึ่งแต่ละ ตัวแปร จะ ถูกกำหนดค่า...
ประวัติศาสตร์
SSA ได้รับการพัฒนาในช่วงทศวรรษ 1980 โดยนักวิจัยหลายคนของ IBM Kenneth Zadeck ซึ่งเป็นสมาชิกคนสำคัญของทีม ได้ย้ายไปที่มหาวิทยาลัย Brown ในขณะที่การพัฒนายังคงดำเนินต่อไป [ 2 ] [ 3 ] บทความในปี 1986 ได้นำเสนอ birthpoints, identity assignments...
ประโยชน์
ประโยชน์หลักของ SSA มาจากการทำให้ผลลัพธ์ของ การเพิ่มประสิทธิภาพคอมไพเลอร์ หลายอย่างง่ายขึ้นและดีขึ้นพร้อมกันโดยการทำให้คุณสมบัติของตัวแปรง่ายขึ้น ตัวอย่างเช่น ลองพิจารณาโค้ดต่อไปนี้:
การแปลงเป็น SSA
การแปลงโค้ดธรรมดาให้เป็นรูปแบบ SSA นั้น ส่วนใหญ่เป็นเรื่องของการแทนที่เป้าหมายของการกำหนดค่าแต่ละครั้งด้วยตัวแปรใหม่ และแทนที่การใช้งานตัวแปรแต่ละครั้งด้วย "เวอร์ชัน" ของตัวแปร ที่มาถึง จุดนั้น ตัวอย่างเช่น พิจารณา แผนผังการไหลของโปรแกรม ต่อไปนี้ :