อ่าน 6 นาที
สถาปัตยกรรมไมโคร
ใน สาขาอิเล็กทรอนิกส์ วิทยาศาสตร์ คอมพิวเตอร์ และ วิศวกรรมคอมพิวเตอร์ สถาปัตยกรรม ไมโคร หรือที่เรียกว่า การจัดระเบียบคอมพิวเตอร์ และบางครั้งย่อว่า μarch หรือ uarch คือวิธีการที่...
สถาปัตยกรรมไมโคร
ในสาขาอิเล็กทรอนิกส์วิทยาศาสตร์คอมพิวเตอร์และวิศวกรรมคอมพิวเตอร์ สถาปัตยกรรม ไมโครหรือที่เรียกว่าการจัดระเบียบคอมพิวเตอร์และบางครั้งย่อว่าμarchหรือuarchคือวิธีการที่สถาปัตยกรรมชุดคำสั่ง (ISA) ที่กำหนดถูกนำไปใช้ในโปรเซสเซอร์ เฉพาะ [ 1 ] ISA ที่กำหนดอาจถูกนำไปใช้ด้วยสถาปัตยกรรมไมโครที่แตกต่างกัน[ 2 ] [ 3 ] การนำไปใช้อาจแตกต่างกันไปเนื่องจากเป้าหมายที่แตกต่างกันของการออกแบบที่กำหนด หรือเนื่องจากการเปลี่ยนแปลงทางเทคโนโลยี[ 4 ]
สถาปัตยกรรมคอมพิวเตอร์คือการผสมผสานระหว่างสถาปัตยกรรมไมโครและสถาปัตยกรรมชุดคำสั่ง
ความสัมพันธ์กับสถาปัตยกรรมชุดคำสั่ง

ISA นั้นโดยคร่าวๆ แล้วเหมือนกับแบบจำลองการเขียนโปรแกรมของโปรเซสเซอร์ในมุมมองของ โปรแกรมเมอร์ ภาษาแอสเซมบลีหรือผู้เขียนคอมไพเลอร์ ISA ประกอบด้วยคำสั่งแบบจำลองการประมวลผลรีจิสเตอร์ของโปรเซสเซอร์รูปแบบที่อยู่และข้อมูล และอื่นๆ ส่วนสถาปัตยกรรมไมโครนั้นประกอบด้วยส่วนประกอบต่างๆ ของโปรเซสเซอร์ และวิธีการที่ส่วนประกอบเหล่านั้นเชื่อมต่อและทำงานร่วมกันเพื่อนำ ISA ไปใช้งาน
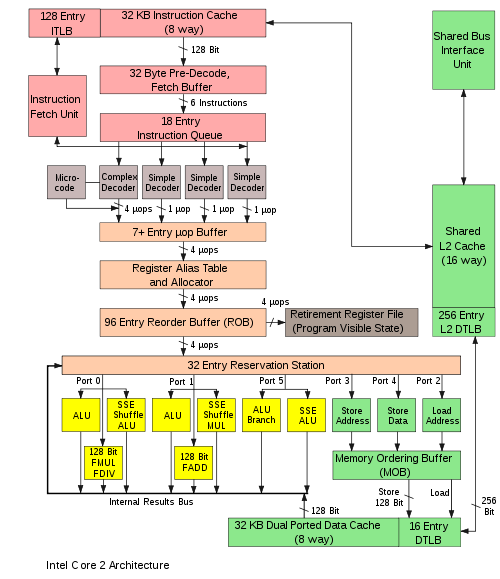
สถาปัตยกรรมไมโครของเครื่องมักจะแสดงเป็นแผนภาพ (ที่มีรายละเอียดมากหรือน้อย) ที่อธิบายการเชื่อมต่อระหว่างองค์ประกอบสถาปัตยกรรมไมโครต่างๆ ของเครื่อง ซึ่งอาจเป็นอะไรก็ได้ตั้งแต่เกตและรีจิสเตอร์เดี่ยวๆ ไปจนถึงหน่วยคำนวณและตรรกะ (ALU) ที่สมบูรณ์ และแม้แต่องค์ประกอบที่ใหญ่กว่านั้น แผนภาพเหล่านี้โดยทั่วไปจะแยกเส้นทางข้อมูล (ที่วางข้อมูล) และเส้นทางควบคุม (ซึ่งอาจกล่าวได้ว่าควบคุมข้อมูล) [ 5 ]
โดยปกติแล้ว ผู้ที่ออกแบบระบบจะวาดแผนผังไมโครสถาปัตยกรรมเฉพาะในรูปแบบของแผนภาพการไหลของข้อมูลเช่นเดียวกับแผนภาพบล็อกแผนภาพไมโครสถาปัตยกรรมจะแสดงองค์ประกอบไมโครสถาปัตยกรรม เช่นหน่วยคำนวณและตรรกะและไฟล์รีจิสเตอร์ในรูปสัญลักษณ์แผนผังเดียว โดยทั่วไป แผนภาพจะเชื่อมต่อองค์ประกอบเหล่านั้นด้วยลูกศร เส้นหนา และเส้นบาง เพื่อแยกความแตกต่างระหว่างบัสสามสถานะ (ซึ่งต้องใช้บัฟเฟอร์สามสถานะสำหรับแต่ละอุปกรณ์ที่ขับเคลื่อนบัส) บัสแบบทิศทางเดียว (ซึ่งขับเคลื่อนโดยแหล่งเดียวเสมอ เช่นเดียวกับบัสแอดเดรสในคอมพิวเตอร์ที่ง่ายกว่า ซึ่งขับเคลื่อนโดยรีจิสเตอร์แอดเดรสหน่วยความจำ ) และสายควบคุมแต่ละเส้น คอมพิวเตอร์ที่ง่ายมากจะมีโครงสร้างบัสข้อมูลเพียงแบบเดียว คือมีบัสสามสถานะ เพียงตัวเดียว แผนภาพของคอมพิวเตอร์ที่ซับซ้อนกว่ามักจะแสดงบัสสามสถานะหลายตัว ซึ่งช่วยให้เครื่องสามารถดำเนินการหลายอย่างพร้อมกันได้
แต่ละองค์ประกอบทางสถาปัตยกรรมระดับไมโครจะถูกแสดงด้วยแผนผังที่อธิบายถึงการเชื่อมต่อของเกตตรรกะที่ใช้ในการสร้างองค์ประกอบนั้น แต่ละเกตตรรกะจะถูกแสดงด้วยแผนภาพวงจรที่อธิบายถึงการเชื่อมต่อของทรานซิสเตอร์ที่ใช้ในการสร้างเกตนั้นในตระกูลตรรกะ เฉพาะ เครื่องจักรที่มีสถาปัตยกรรมระดับไมโครต่างกันอาจมีสถาปัตยกรรมชุดคำสั่งเดียวกัน และดังนั้นจึงสามารถประมวลผลโปรแกรมเดียวกันได้ สถาปัตยกรรมระดับไมโครและ/หรือโซลูชันวงจรใหม่ๆ พร้อมกับความก้าวหน้าในการผลิตเซมิคอนดักเตอร์ คือสิ่งที่ทำให้โปรเซสเซอร์รุ่นใหม่ๆ สามารถทำงานได้มีประสิทธิภาพสูงขึ้นในขณะที่ใช้สถาปัตยกรรมชุดคำสั่งเดียวกัน
โดยหลักการแล้ว สถาปัตยกรรมไมโครเพียงแบบเดียวสามารถประมวลผลชุดคำสั่งการทำงาน (ISA) ที่แตกต่างกันได้หลายแบบ โดยมีการเปลี่ยนแปลงไมโคร โค้ด เพียงเล็กน้อยเท่านั้น
แง่มุมต่างๆ

เส้นทางข้อมูลแบบไปป์ไลน์ เป็นรูปแบบการออกแบบเส้นทางข้อมูลที่ใช้กันมากที่สุดในสถาปัตยกรรมไมโครในปัจจุบัน เทคนิคนี้ใช้ในไมโครโปรเซสเซอร์ไมโครคอนโทรลเลอร์และDSP สมัยใหม่ส่วนใหญ่ สถาปัตยกรรมแบบไปป์ไลน์ช่วยให้คำสั่งหลายคำสั่งสามารถซ้อนทับกันในการดำเนินการได้ คล้ายกับสายการผลิต ไปป์ไลน์ประกอบด้วยขั้นตอนต่างๆ หลายขั้นตอนซึ่งเป็นพื้นฐานในการออกแบบสถาปัตยกรรมไมโคร[ 5 ]บางขั้นตอนเหล่านี้ได้แก่ การดึงคำสั่ง การถอดรหัสคำสั่ง การดำเนินการ และการเขียนกลับ สถาปัตยกรรมบางแบบมีขั้นตอนอื่นๆ เช่น การเข้าถึงหน่วยความจำ การออกแบบไปป์ไลน์เป็นหนึ่งในงานหลักของสถาปัตยกรรมไมโคร
หน่วยประมวลผลก็มีความสำคัญอย่างยิ่งต่อสถาปัตยกรรมระดับไมโคร หน่วยประมวลผลประกอบด้วยหน่วยคำนวณและตรรกะ (ALU), หน่วยประมวลผลจุดลอยตัว (FPU), หน่วยโหลด/จัดเก็บข้อมูล, การคาดการณ์การแตกแขนง และSIMDหน่วยเหล่านี้ทำหน้าที่ดำเนินการหรือคำนวณต่างๆ ของโปรเซสเซอร์ การเลือกจำนวนหน่วยประมวลผล ความหน่วง และปริมาณงานของหน่วยประมวลผลเป็นงานออกแบบสถาปัตยกรรมระดับไมโครที่สำคัญ ขนาด ความหน่วง ปริมาณงาน และการเชื่อมต่อของหน่วยความจำภายในระบบก็เป็นการตัดสินใจในด้านสถาปัตยกรรมระดับไมโครเช่นกัน
การตัดสินใจด้านการออกแบบในระดับระบบ เช่น การตัดสินใจว่าจะรวมอุปกรณ์ต่อพ่วงเช่นตัวควบคุมหน่วยความจำ หรือไม่นั้น ถือเป็นส่วนหนึ่งของกระบวนการออกแบบสถาปัตยกรรมระดับไมโคร ซึ่งรวมถึงการตัดสินใจเกี่ยวกับระดับประสิทธิภาพและการเชื่อมต่อของอุปกรณ์ต่อพ่วงเหล่านี้ด้วย
แตกต่างจากการออกแบบสถาปัตยกรรมที่เป้าหมายหลักคือการบรรลุระดับประสิทธิภาพที่เฉพาะเจาะจง การออกแบบสถาปัตยกรรมระดับไมโครจะให้ความสำคัญกับข้อจำกัดอื่นๆ มากกว่า เนื่องจากข้อตัดสินใจในการออกแบบสถาปัตยกรรมระดับไมโครส่งผลโดยตรงต่อส่วนประกอบต่างๆ ในระบบ จึงต้องให้ความสำคัญกับประเด็นต่างๆ เช่น พื้นที่/ต้นทุนของชิป การใช้พลังงาน ความซับซ้อนของตรรกะ ความง่ายในการเชื่อมต่อ ความสามารถในการผลิต ความง่ายในการแก้ไขข้อผิดพลาด และความสามารถในการทดสอบ
แนวคิดสถาปัตยกรรมระดับจุลภาค
รอบคำสั่ง
ในการรันโปรแกรม ซีพียูแบบชิปเดี่ยวหรือหลายชิปทั้งหมด:
- อ่านคำสั่งและถอดรหัสคำสั่งนั้น
- ค้นหาข้อมูลที่เกี่ยวข้องทั้งหมดที่จำเป็นต่อการประมวลผลคำสั่ง
- ดำเนินการตามคำแนะนำ
- เขียนผลลัพธ์ออกมา
วงจรคำสั่งจะทำงานซ้ำอย่างต่อเนื่องจนกว่าจะปิดเครื่อง
สถาปัตยกรรมไมโครแบบหลายรอบ
ในอดีต คอมพิวเตอร์รุ่นแรกๆ นั้นใช้การออกแบบแบบมัลติไซเคิล คอมพิวเตอร์ขนาดเล็กและราคาถูกที่สุดมักจะยังคงใช้เทคนิคนี้อยู่ สถาปัตยกรรมแบบมัลติไซเคิลมักใช้จำนวนองค์ประกอบตรรกะโดยรวมน้อยที่สุดและใช้พลังงานในปริมาณที่เหมาะสม สามารถออกแบบให้มีจังหวะเวลาที่แน่นอนและมีความน่าเชื่อถือสูง โดยเฉพาะอย่างยิ่ง ไม่มีไปป์ไลน์ที่จะหยุดชะงักเมื่อมีการกระโดดแบบมีเงื่อนไขหรือการขัดจังหวะ อย่างไรก็ตาม สถาปัตยกรรมไมโครอื่นๆ มักจะประมวลผลคำสั่งได้มากกว่าต่อหน่วยเวลา โดยใช้ตระกูลตรรกะเดียวกัน เมื่อพูดถึง "ประสิทธิภาพที่ดีขึ้น" การปรับปรุงนั้นมักจะสัมพันธ์กับการออกแบบแบบมัลติไซเคิล
ในคอมพิวเตอร์แบบมัลติไซเคิล คอมพิวเตอร์จะดำเนินการสี่ขั้นตอนตามลำดับ โดยใช้เวลาหลายรอบสัญญาณนาฬิกา การออกแบบบางอย่างสามารถดำเนินการตามลำดับนี้ได้ภายในสองรอบสัญญาณนาฬิกา โดยการดำเนินการในแต่ละขั้นตอนสลับกันไปบนขอบสัญญาณนาฬิกา โดยอาจมีการดำเนินการที่ใช้เวลานานกว่าเกิดขึ้นนอกรอบหลัก ตัวอย่างเช่น ขั้นตอนที่หนึ่งบนขอบขาขึ้นของรอบแรก ขั้นตอนที่สองบนขอบขาลงของรอบแรก เป็นต้น
ในตรรกะควบคุม การรวมกันของตัวนับรอบ สถานะรอบ (สูงหรือต่ำ) และบิตของรีจิสเตอร์ถอดรหัสคำสั่ง จะกำหนดว่าแต่ละส่วนของคอมพิวเตอร์ควรทำอะไรอย่างแม่นยำ ในการออกแบบตรรกะควบคุม เราสามารถสร้างตารางบิตที่อธิบายสัญญาณควบคุมไปยังแต่ละส่วนของคอมพิวเตอร์ในแต่ละรอบของแต่ละคำสั่ง จากนั้น ตารางตรรกะนี้สามารถทดสอบได้ในการจำลองซอฟต์แวร์โดยการรันโค้ดทดสอบ หากตารางตรรกะถูกวางไว้ในหน่วยความจำและใช้เพื่อรันคอมพิวเตอร์จริง จะเรียกว่าไมโครโปรแกรมในการออกแบบคอมพิวเตอร์บางแบบ ตารางตรรกะจะถูกปรับให้เหมาะสมในรูปแบบของตรรกะเชิงผสมที่สร้างจากเกตตรรกะ โดยปกติจะใช้โปรแกรมคอมพิวเตอร์ที่ปรับตรรกะให้เหมาะสม คอมพิวเตอร์ยุคแรกใช้การออกแบบตรรกะแบบเฉพาะกิจสำหรับการควบคุม จนกระทั่งMaurice Wilkesคิดค้นวิธีการแบบตารางนี้และเรียกว่าไมโครโปรแกรมมิง[ 6 ]
เพิ่มความเร็วในการประมวลผล
สิ่งที่ทำให้ขั้นตอนที่ดูเรียบง่ายนี้ซับซ้อนขึ้นก็คือความจริงที่ว่าลำดับชั้นของหน่วยความจำ ซึ่งรวมถึงแคชหน่วยความจำหลักและหน่วยเก็บข้อมูลแบบไม่ลบเลือน เช่นฮาร์ดดิสก์ (ซึ่งเป็นที่เก็บคำสั่งโปรแกรมและข้อมูล) นั้นช้ากว่าตัวประมวลผลเองเสมอ ขั้นตอนที่ (2) มักจะทำให้เกิดความล่าช้าเป็นเวลานาน (ในแง่ของ CPU) ในขณะที่ข้อมูลมาถึงผ่านบัสของคอมพิวเตอร์มีการวิจัยจำนวนมากเกี่ยวกับการออกแบบที่หลีกเลี่ยงความล่าช้าเหล่านี้ให้มากที่สุดเท่าที่จะเป็นไปได้ ตลอดหลายปีที่ผ่านมา เป้าหมายหลักคือการประมวลผลคำสั่งแบบขนานให้มากขึ้น ซึ่งจะช่วยเพิ่มความเร็วในการประมวลผลโปรแกรมอย่างมีประสิทธิภาพ ความพยายามเหล่านี้ได้นำไปสู่ตรรกะและโครงสร้างวงจรที่ซับซ้อน ในตอนแรก เทคนิคเหล่านี้สามารถนำไปใช้ได้เฉพาะกับเมนเฟรมหรือซูเปอร์คอมพิวเตอร์ที่มีราคาแพงเท่านั้น เนื่องจากปริมาณวงจรที่จำเป็นสำหรับเทคนิคเหล่านี้ เมื่อการผลิตเซมิคอนดักเตอร์ก้าวหน้าขึ้น เทคนิคเหล่านี้ก็สามารถนำไปใช้บนชิปเซมิคอนดักเตอร์ชิ้นเดียวได้มากขึ้นเรื่อยๆ ดูกฎของมัวร์
การเลือกชุดคำสั่ง
ชุดคำสั่งมีการเปลี่ยนแปลงไปตามกาลเวลา จากเดิมที่เรียบง่ายมาก ไปสู่ความซับซ้อนมากขึ้น (ในหลายๆ ด้าน) ในช่วงไม่กี่ปีที่ผ่านมาสถาปัตยกรรมแบบโหลด-สโตร์ , VLIWและEPICได้รับความนิยม สถาปัตยกรรมที่เกี่ยวข้องกับการประมวลผลแบบขนานข้อมูลได้แก่SIMDและVectorsป้ายกำกับบางป้ายที่ใช้เพื่อระบุประเภทของสถาปัตยกรรม CPU นั้นไม่ได้สื่อความหมายได้ดีนัก โดยเฉพาะอย่างยิ่งป้ายกำกับ CISC การออกแบบในยุคแรกๆ จำนวนมากที่ถูกเรียกย้อนหลังว่า " CISC " นั้น แท้จริงแล้วเรียบง่ายกว่าโปรเซสเซอร์ RISC สมัยใหม่ (ในหลายๆ ด้าน) อย่างมาก
อย่างไรก็ตาม การเลือกสถาปัตยกรรมชุดคำสั่งอาจส่งผลกระทบอย่างมากต่อความซับซ้อนในการสร้างอุปกรณ์ประสิทธิภาพสูง กลยุทธ์ที่โดดเด่นซึ่งใช้ในการพัฒนาโปรเซสเซอร์ RISC รุ่นแรกๆ คือการลดความซับซ้อนของคำสั่งให้น้อยที่สุด โดยผสมผสานความซับซ้อนเชิงความหมายของแต่ละคำสั่งเข้ากับความสม่ำเสมอและความเรียบง่ายของการเข้ารหัส คำสั่งที่เป็นมาตรฐานเหล่านี้สามารถดึงข้อมูล ถอดรหัส และประมวลผลได้อย่างง่ายดายในลักษณะแบบไปป์ไลน์ และเป็นกลยุทธ์ที่เรียบง่ายในการลดจำนวนระดับตรรกะเพื่อให้ได้ความถี่ในการทำงานสูง หน่วยความจำแคชคำสั่งช่วยชดเชยความถี่ในการทำงานที่สูงขึ้นและความหนาแน่นของโค้ด ที่ต่ำโดยธรรมชาติ ในขณะที่ชุดรีจิสเตอร์ขนาดใหญ่ถูกใช้เพื่อลดการเข้าถึงหน่วยความจำ (ที่ช้า) ให้มากที่สุดเท่าที่จะเป็นไปได้
การประมวลผลคำสั่งแบบไปป์ไลน์
หนึ่งในเทคนิคแรกๆ และทรงพลังที่สุดในการปรับปรุงประสิทธิภาพคือการใช้การประมวลผลแบบไปป์ไลน์คำสั่งการออกแบบโปรเซสเซอร์ในยุคแรกๆ จะดำเนินการทุกขั้นตอนข้างต้นสำหรับคำสั่งหนึ่งก่อนที่จะไปยังคำสั่งถัดไป วงจรส่วนใหญ่จะไม่ได้ใช้งานในแต่ละขั้นตอน ตัวอย่างเช่น วงจรถอดรหัสคำสั่งจะไม่ได้ใช้งานในระหว่างการประมวลผล เป็นต้น
การประมวลผลแบบไปป์ไลน์ช่วยเพิ่มประสิทธิภาพโดยอนุญาตให้คำสั่งหลายคำสั่งทำงานผ่านโปรเซสเซอร์พร้อมกัน ในตัวอย่างพื้นฐานเดียวกัน โปรเซสเซอร์จะเริ่มถอดรหัส (ขั้นตอนที่ 1) คำสั่งใหม่ในขณะที่คำสั่งก่อนหน้ากำลังรอผลลัพธ์ ซึ่งจะทำให้มีคำสั่งมากถึงสี่คำสั่งที่ "กำลังดำเนินการ" ในเวลาเดียวกัน ทำให้โปรเซสเซอร์ดูเร็วขึ้นถึงสี่เท่า แม้ว่าแต่ละคำสั่งจะใช้เวลานานเท่าเดิมในการดำเนินการให้เสร็จสิ้น (เนื่องจากยังมีสี่ขั้นตอน) แต่ CPU โดยรวมแล้วจะ "ประมวลผล" คำสั่งได้เร็วกว่ามาก
RISC ทำให้ไปป์ไลน์มีขนาดเล็กลงและสร้างได้ง่ายขึ้นมาก โดยการแยกแต่ละขั้นตอนของกระบวนการคำสั่งออกจากกันอย่างชัดเจนและทำให้ใช้เวลาเท่ากันคือหนึ่งรอบการทำงาน โปรเซสเซอร์โดยรวมทำงานใน ลักษณะ สายการผลิตโดยมีคำสั่งเข้ามาทางด้านหนึ่งและผลลัพธ์ออกไปอีกด้านหนึ่ง เนื่องจากความซับซ้อนที่ลดลงของไปป์ไลน์ RISC แบบดั้งเดิมทำให้แกนประมวลผลแบบไปป์ไลน์และแคชคำสั่งสามารถวางไว้บนชิปขนาดเดียวกันได้ ซึ่งหากเป็นแบบ CISC จะมีพื้นที่จำกัดสำหรับแกนประมวลผลเพียงอย่างเดียว นี่คือเหตุผลที่แท้จริงที่ทำให้ RISC เร็วกว่า โปรเซสเซอร์รุ่นแรกๆ เช่นSPARCและMIPSมักทำงานได้เร็วกว่า โซลูชัน CISC ของ IntelและMotorola มากกว่า 10 เท่า ที่ความเร็วสัญญาณนาฬิกาและราคาเดียวกัน
การประมวลผลแบบไปป์ไลน์ไม่ได้จำกัดอยู่เฉพาะสถาปัตยกรรม RISC เท่านั้น ในปี 1986 โปรเซสเซอร์ VAX รุ่นท็อป ( VAX 8800 ) ก็ใช้การประมวลผลแบบไปป์ไลน์อย่างมาก ซึ่งมาก่อนการออกแบบ MIPS และ SPARC เชิงพาณิชย์รุ่นแรกๆ เล็กน้อย ปัจจุบันซีพียูสมัยใหม่ส่วนใหญ่ (แม้แต่ซีพียูฝังตัว) ก็ใช้การประมวลผลแบบไปป์ไลน์แล้ว และซีพียูแบบไมโครโค้ดที่ไม่มีการประมวลผลแบบไปป์ไลน์นั้นพบได้เฉพาะในโปรเซสเซอร์ฝังตัวที่มีพื้นที่จำกัดมากเท่านั้น เครื่อง CISC ขนาดใหญ่ ตั้งแต่ VAX 8800 ไปจนถึงโปรเซสเซอร์ Intel และ AMD รุ่นใหม่ ล้วนใช้ทั้งไมโครโค้ดและการประมวลผลแบบไปป์ไลน์ การพัฒนาด้านการประมวลผลแบบไปป์ไลน์และการแคชเป็นความก้าวหน้าทางสถาปัตยกรรมไมโครที่สำคัญสองประการที่ทำให้ประสิทธิภาพของโปรเซสเซอร์สามารถก้าวทันเทคโนโลยีวงจรที่ใช้ได้
แคช
ไม่นานนัก การพัฒนาด้านการผลิตชิปก็ทำให้สามารถวางวงจรจำนวนมากขึ้นบนแผ่นชิปได้ และนักออกแบบก็เริ่มมองหาวิธีใช้ประโยชน์จากมัน หนึ่งในวิธีที่พบได้บ่อยที่สุดคือการเพิ่มหน่วยความจำแคชบนแผ่นชิปให้มากขึ้นเรื่อยๆ แคชเป็นหน่วยความจำที่เร็วและมีราคาแพง สามารถเข้าถึงได้ในไม่กี่รอบการทำงาน ต่างจากหน่วยความจำหลักที่ต้องใช้หลายรอบการทำงาน ซีพียูมีตัวควบคุมแคชซึ่งทำหน้าที่อ่านและเขียนข้อมูลจากแคชโดยอัตโนมัติ หากข้อมูลอยู่ในแคชอยู่แล้ว ก็จะถูกเข้าถึงจากที่นั่น ซึ่งช่วยประหยัดเวลาได้อย่างมาก ในขณะที่หากข้อมูลไม่อยู่ในแคช โปรเซสเซอร์จะ "หยุดชะงัก" ในขณะที่ตัวควบคุมแคชกำลังอ่านข้อมูลเข้ามา
การออกแบบสถาปัตยกรรม RISC เริ่มเพิ่มแคชในช่วงกลางถึงปลายทศวรรษ 1980 โดยส่วนใหญ่มักมีเพียง 4 KB เท่านั้น จำนวนแคชเพิ่มขึ้นเรื่อย ๆ ปัจจุบันซีพียูทั่วไปมีแคชอย่างน้อย 2 MB ในขณะที่ซีพียูที่มีประสิทธิภาพสูงกว่าจะมี 4, 6, 12 MB หรือแม้แต่ 32 MB หรือมากกว่านั้น โดยรุ่นที่มีขนาดแคชสูงสุดคือ 768 MB ในตระกูล EPYC Milan-X รุ่นใหม่ล่าสุด ซึ่งจัดเรียงเป็นลำดับชั้นของหน่วยความจำ หลายระดับ โดยทั่วไปแล้ว แคชที่มากขึ้นหมายถึงประสิทธิภาพที่มากขึ้น เนื่องจากลดการหยุดชะงัก (stalling)
แคชและไปป์ไลน์นั้นเข้ากันได้อย่างลงตัว ก่อนหน้านี้ การสร้างไปป์ไลน์ที่ทำงานได้เร็วกว่าความหน่วงในการเข้าถึงหน่วยความจำภายนอกชิปนั้นไม่ค่อยสมเหตุสมผลนัก แต่การใช้หน่วยความจำแคชบนชิปแทน ทำให้ไปป์ไลน์สามารถทำงานได้ด้วยความเร็วเท่ากับความหน่วงในการเข้าถึงแคช ซึ่งใช้เวลาน้อยกว่ามาก ส่งผลให้ความถี่ในการทำงานของโปรเซสเซอร์เพิ่มขึ้นได้เร็วกว่าหน่วยความจำภายนอกชิปมาก
การทำนายสาขา
อุปสรรคประการหนึ่งในการบรรลุประสิทธิภาพที่สูงขึ้นผ่านการประมวลผลแบบขนานระดับคำสั่ง มาจากการหยุดชะงักและการล้างไปป์ไลน์เนื่องจากคำสั่งกระโดด โดยปกติแล้ว จะไม่ทราบว่าคำสั่งกระโดดแบบมีเงื่อนไขจะเกิดขึ้นหรือไม่ จนกว่าจะถึงช่วงท้ายของไปป์ไลน์ เนื่องจากคำสั่งกระโดดแบบมีเงื่อนไขขึ้นอยู่กับผลลัพธ์ที่ได้จากรีจิสเตอร์ ตั้งแต่เวลาที่ตัวถอดรหัสคำสั่งของโปรเซสเซอร์ได้คำนวณว่าพบคำสั่งกระโดดแบบมีเงื่อนไข จนถึงเวลาที่สามารถอ่านค่ารีจิสเตอร์ที่ใช้ตัดสินใจได้ ไปป์ไลน์จะต้องหยุดชะงักเป็นเวลาหลายรอบการทำงาน หรือหากไม่หยุดชะงักและคำสั่งกระโดดเกิดขึ้น ไปป์ไลน์ก็จะต้องถูกล้าง เมื่อความเร็วสัญญาณนาฬิกาเพิ่มขึ้น ความลึกของไปป์ไลน์ก็จะเพิ่มขึ้นตามไปด้วย และโปรเซสเซอร์สมัยใหม่บางตัวอาจมี 20 ขั้นตอนหรือมากกว่านั้น โดยเฉลี่ยแล้ว ทุกๆ คำสั่งที่ห้าที่ถูกประมวลผลจะเป็นคำสั่งกระโดด ดังนั้นหากไม่มีการแทรกแซงใดๆ จะทำให้เกิดการหยุดชะงักเป็นจำนวนมาก
เทคนิคต่างๆ เช่นการคาดการณ์การกระโดด (Branch Prediction)และการประมวลผลแบบคาดการณ์ล่วงหน้า (Speculative Execution)ถูกนำมาใช้เพื่อลดค่าปรับของการกระโดดเหล่านี้ การคาดการณ์การกระโดดคือการที่ฮาร์ดแวร์คาดเดาอย่างมีเหตุผลว่าการกระโดดนั้นจะเกิดขึ้นหรือไม่ ในความเป็นจริงแล้ว ด้านใดด้านหนึ่งของการกระโดดจะถูกเรียกใช้บ่อยกว่าอีกด้านหนึ่งมาก การออกแบบสมัยใหม่มีระบบการคาดการณ์ทางสถิติที่ค่อนข้างซับซ้อน ซึ่งจะตรวจสอบผลลัพธ์ของการกระโดดในอดีตเพื่อคาดการณ์อนาคตด้วยความแม่นยำที่มากขึ้น การคาดเดานี้ช่วยให้ฮาร์ดแวร์สามารถดึงคำสั่งล่วงหน้าได้โดยไม่ต้องรอการอ่านรีจิสเตอร์ การประมวลผลแบบคาดการณ์ล่วงหน้าเป็นการปรับปรุงเพิ่มเติมที่โค้ดตามเส้นทางที่คาดการณ์ไว้ไม่เพียงแต่ถูกดึงล่วงหน้าเท่านั้น แต่ยังถูกประมวลผลก่อนที่จะทราบว่าควรกระโดดหรือไม่ ซึ่งอาจให้ประสิทธิภาพที่ดีขึ้นเมื่อการคาดเดาดี แต่ก็มีความเสี่ยงที่จะเกิดค่าปรับมหาศาลเมื่อการคาดเดาไม่ดี เนื่องจากต้องยกเลิกคำสั่งบางอย่าง
ซูเปอร์สเกลาร์
แม้ว่าจะมีการเพิ่มความซับซ้อนและจำนวนเกตที่จำเป็นเพื่อรองรับแนวคิดที่กล่าวมาข้างต้น แต่การพัฒนาในการผลิตเซมิคอนดักเตอร์ก็ทำให้สามารถใช้เกตตรรกะได้มากขึ้นในเวลาต่อมา
ในโครงร่างข้างต้น โปรเซสเซอร์จะประมวลผลส่วนต่าง ๆ ของคำสั่งเดียวในแต่ละครั้ง โปรแกรมคอมพิวเตอร์จะทำงานได้เร็วขึ้นหากประมวลผลหลายคำสั่งพร้อมกัน นี่คือสิ่งที่ โปรเซสเซอร์แบบ ซูเปอร์สเกลาร์ทำได้ โดยการจำลองหน่วยการทำงาน เช่น ALU การจำลองหน่วยการทำงานนี้เป็นไปได้ก็ต่อเมื่อพื้นที่ของชิปโปรเซสเซอร์แบบคำสั่งเดียวไม่เกินขีดจำกัดของสิ่งที่สามารถผลิตได้อย่างน่าเชื่อถืออีกต่อไป ในช่วงปลายทศวรรษ 1980 การออกแบบแบบซูเปอร์สเกลาร์เริ่มเข้าสู่ตลาด
ในการออกแบบสมัยใหม่ มักพบหน่วยโหลดสองหน่วย หน่วยจัดเก็บหนึ่งหน่วย (คำสั่งจำนวนมากไม่มีผลลัพธ์ให้จัดเก็บ) หน่วยคำนวณเลขจำนวนเต็มสองหน่วยขึ้นไป หน่วยคำนวณเลขทศนิยมสองหน่วยขึ้นไป และมักจะมี หน่วย SIMDบางประเภทด้วย ตรรกะการออกคำสั่งมีความซับซ้อนมากขึ้นโดยการอ่านรายการคำสั่งจำนวนมากจากหน่วยความจำและส่งต่อไปยังหน่วยประมวลผลต่างๆ ที่ว่างอยู่ ณ จุดนั้น จากนั้นผลลัพธ์จะถูกรวบรวมและจัดเรียงใหม่ในตอนท้าย
การดำเนินการที่ไม่เป็นไปตามลำดับ
การเพิ่มแคชช่วยลดความถี่หรือระยะเวลาของการหยุดชะงักเนื่องจากการรอการดึงข้อมูลจากลำดับชั้นของหน่วยความจำ แต่ไม่ได้กำจัดปัญหาการหยุดชะงักเหล่านี้ไปโดยสิ้นเชิง ในการออกแบบยุคแรกๆการพลาดแคชจะบังคับให้ตัวควบคุมแคชหยุดการทำงานของโปรเซสเซอร์และรอ แน่นอนว่าอาจมีคำสั่งอื่นๆ ในโปรแกรมที่มีข้อมูลพร้อมใช้งานในแคช ณ จุดนั้นการประมวลผลแบบไม่เรียงลำดับช่วยให้สามารถประมวลผลคำสั่งที่พร้อมใช้งานได้ในขณะที่คำสั่งก่อนหน้ารออยู่ในแคช จากนั้นจึงจัดเรียงผลลัพธ์ใหม่เพื่อให้ดูเหมือนว่าทุกอย่างเกิดขึ้นตามลำดับที่ตั้งโปรแกรมไว้ เทคนิคนี้ยังใช้เพื่อหลีกเลี่ยงการหยุดชะงักที่ขึ้นอยู่กับตัวดำเนินการอื่นๆ เช่น คำสั่งที่รอผลลัพธ์จากการดำเนินการจุดลอยตัวที่มีความหน่วงต่ำ หรือการดำเนินการหลายรอบอื่นๆ
การเปลี่ยนชื่อทะเบียน
การเปลี่ยนชื่อรีจิสเตอร์หมายถึงเทคนิคที่ใช้เพื่อหลีกเลี่ยงการประมวลผลคำสั่งโปรแกรมแบบอนุกรมโดยไม่จำเป็น เนื่องจากการใช้รีจิสเตอร์เดียวกันซ้ำโดยคำสั่งเหล่านั้น สมมติว่าเรามีคำสั่งสองกลุ่มที่จะใช้รีจิสเตอร์ เดียวกัน ชุดคำสั่งหนึ่งจะถูกประมวลผลก่อนเพื่อให้รีจิสเตอร์ว่างสำหรับชุดคำสั่งอีกชุดหนึ่ง แต่ถ้าชุดคำสั่งอีกชุดหนึ่งถูกกำหนดให้ใช้รีจิสเตอร์ที่คล้ายกันแต่แตกต่างกัน คำสั่งทั้งสองชุดสามารถประมวลผลพร้อมกันหรือแบบอนุกรมก็ได้
การประมวลผลแบบมัลติโปรเซสซิ่งและมัลติเธรดดิ้ง
สถาปนิกคอมพิวเตอร์เริ่มติดขัดกับความไม่สอดคล้องกันที่เพิ่มขึ้นระหว่างความถี่ในการทำงานของ CPU และ เวลาในการเข้าถึง DRAMเทคนิคใดๆ ที่ใช้ประโยชน์จากความขนานระดับคำสั่ง (ILP) ภายในโปรแกรมเดียวก็ไม่สามารถชดเชยความล่าช้าที่เกิดขึ้นเมื่อต้องดึงข้อมูลจากหน่วยความจำหลักได้ นอกจากนี้ จำนวนทรานซิสเตอร์จำนวนมากและความถี่ในการทำงานสูงที่จำเป็นสำหรับเทคนิค ILP ขั้นสูงกว่านั้น ยังต้องการระดับการกระจายพลังงานที่ไม่สามารถระบายความร้อนได้อย่างประหยัดอีกต่อไป ด้วยเหตุผลเหล่านี้ คอมพิวเตอร์รุ่นใหม่จึงเริ่มใช้ประโยชน์จากระดับความขนานที่สูงขึ้นซึ่งอยู่นอกเหนือโปรแกรมเดียวหรือเธรดโปรแกรมเดียว
แนวโน้มนี้บางครั้งเรียกว่าการประมวลผลแบบปริมาณงาน (throughput computing ) แนวคิดนี้มีต้นกำเนิดมาจากตลาดเมนเฟรม ซึ่งการประมวลผลธุรกรรมออนไลน์ไม่ได้เน้นเพียงแค่ความเร็วในการดำเนินการของธุรกรรมแต่ละรายการ แต่ยังเน้นถึงความสามารถในการจัดการกับธุรกรรมจำนวนมหาศาลด้วย เนื่องจากแอปพลิเคชันที่ใช้ธุรกรรมเป็นหลัก เช่น การกำหนดเส้นทางเครือข่ายและการให้บริการเว็บไซต์ เพิ่มขึ้นอย่างมากในช่วงทศวรรษที่ผ่านมา อุตสาหกรรมคอมพิวเตอร์จึงหันมาให้ความสำคัญกับประเด็นเรื่องความจุและปริมาณงานอีกครั้ง
เทคนิคหนึ่งที่ทำให้เกิดการประมวลผลแบบขนานคือการใช้ ระบบ มัลติโปร เซสซิ่ง ซึ่งเป็นระบบคอมพิวเตอร์ที่มีซีพียูหลายตัว เดิมทีระบบมัลติโปรเซสซิ่งนั้นสงวนไว้สำหรับ เมนเฟรมและซูเปอร์คอมพิวเตอร์ระดับสูง แต่ปัจจุบันเซิร์ฟเวอร์มัลติโปรเซสซิ่งขนาดเล็ก (2-8 ตัว) กลายเป็นเรื่องปกติในตลาดธุรกิจขนาดเล็ก สำหรับบริษัทขนาดใหญ่ มัลติโปรเซสซิ่งขนาดใหญ่ (16-256 ตัว) เป็นเรื่องปกติ แม้แต่คอมพิวเตอร์ส่วนบุคคลที่มีซีพียูหลายตัวก็ปรากฏขึ้นตั้งแต่ทศวรรษ 1990 เป็นต้นมา
ด้วยการลดขนาดของทรานซิสเตอร์ลงอย่างต่อเนื่องซึ่งเป็นไปได้ด้วยความก้าวหน้าของเทคโนโลยีเซมิคอนดักเตอร์ซีพียูแบบมัลติคอร์จึงปรากฏขึ้น โดยมีการนำซีพียูหลายตัวมาใช้งานบนชิปซิลิคอนเดียวกัน เริ่มแรกใช้ในชิปที่มุ่งเป้าไปที่ตลาดอุปกรณ์ฝังตัว ซึ่งซีพียูที่เรียบง่ายและขนาดเล็กกว่าจะช่วยให้สามารถติดตั้งซีพียูหลายตัวบนชิปซิลิคอนชิ้นเดียวได้ ในปี 2548 เทคโนโลยีเซมิคอนดักเตอร์ทำให้สามารถ ผลิตชิป CMP ซีพียูเดสก์ท็อประดับไฮเอนด์แบบ ดูอัลคอร์ได้ในปริมาณมาก บางดีไซน์ เช่นUltraSPARC T1ของSun Microsystemsได้กลับไปใช้ดีไซน์ที่เรียบง่ายกว่า (แบบสเกลาร์ เรียงลำดับ) เพื่อให้สามารถบรรจุโปรเซสเซอร์ได้มากขึ้นบนชิปซิลิคอนชิ้นเดียว
อีกเทคนิคหนึ่งที่ได้รับความนิยมมากขึ้นในปัจจุบันคือมัลติเธรดดิ้ง (Multithreading ) ในมัลติเธรดดิ้ง เมื่อโปรเซสเซอร์ต้องดึงข้อมูลจากหน่วยความจำระบบที่ทำงานช้า แทนที่จะรอให้ข้อมูลมาถึง โปรเซสเซอร์จะสลับไปยังโปรแกรมหรือเธรดอื่นที่พร้อมจะทำงาน แม้ว่าวิธีนี้จะไม่ทำให้โปรแกรม/เธรดนั้นเร็วขึ้น แต่จะช่วยเพิ่มประสิทธิภาพโดยรวมของระบบโดยลดเวลาที่ CPU ว่างอยู่
ในเชิงแนวคิด การทำงานแบบมัลติเธรดดิ้งเทียบเท่ากับการสลับบริบทในระดับระบบปฏิบัติการ ความแตกต่างคือ CPU แบบมัลติเธรดดิ้งสามารถสลับเธรดได้ในรอบการทำงานของ CPU เพียงหนึ่งรอบ แทนที่จะใช้รอบการทำงานของ CPU หลายร้อยหรือหลายพันรอบ ซึ่งเป็นสิ่งที่การสลับบริบทโดยทั่วไปต้องการ สิ่งนี้ทำได้โดยการจำลองฮาร์ดแวร์สถานะ (เช่นไฟล์รีจิสเตอร์และตัวนับโปรแกรม ) สำหรับแต่ละเธรดที่ทำงานอยู่
อีกหนึ่งการปรับปรุงที่สำคัญคือการประมวลผลแบบมัลติเธรดพร้อมกันเทคนิคนี้ช่วยให้ซีพียูแบบซูเปอร์สเกลาร์สามารถประมวลผลคำสั่งจากโปรแกรม/เธรดต่างๆ พร้อมกันได้ในรอบการทำงานเดียวกัน
ดูเพิ่มเติม
- หน่วยควบคุม
- สถาปัตยกรรมฮาร์ดแวร์
- ภาษาอธิบายฮาร์ดแวร์ (HDL)
- การประมวลผลแบบขนานระดับคำสั่ง (ILP)
- รายชื่อสถาปัตยกรรมไมโครของซีพียู AMD
- รายชื่อสถาปัตยกรรมไมโครของซีพียู Intel
- รายชื่อสถาปัตยกรรมไมโครของซีพียู ARM
- การออกแบบโปรเซสเซอร์
- การประมวลผลสตรีม
- วีเอชดีแอล
- วงจรรวมขนาดใหญ่มาก (VLSI)
- เวริล็อก
- การเปรียบเทียบสถาปัตยกรรมไมโครของซีพียู
อ่านเพิ่มเติม
- การบรรยายด้านสถาปัตยกรรมคอมพิวเตอร์ของมหาวิทยาลัยคาร์เนกีเมลลอน
- แพตเตอร์สัน, ดี.; เฮนเนสซี, เจ. (2004). การจัดระเบียบและการออกแบบคอมพิวเตอร์: ส่วนต่อประสานระหว่างฮาร์ดแวร์และซอฟต์แวร์มอร์แกน คอฟแมนน์ISBN 1-55860-604-1.
- Hamacher, VC; Vrasenic, ZG; Zaky, SG (2001). การจัดระเบียบคอมพิวเตอร์ . McGraw-Hill. ISBN 0-07-232086-9.
- สตอลลิงส์, วิลเลียม (2002). การจัดระเบียบและสถาปัตยกรรมคอมพิวเตอร์ . สำนักพิมพ์เพรนติสฮอลล์. ISBN 0-13-035119-9.
- เฮส์, เจพี (2002). สถาปัตยกรรมและองค์ประกอบของคอมพิวเตอร์ . แมคกรอว์-ฮิลล์. ISBN 0-07-286198-3.
- Schneider, Gary Michael (1985). หลักการของการจัดระเบียบคอมพิวเตอร์ . Wiley. หน้า 6–7 . ISBN 0-471-88552-5.
- มาโน, เอ็ ม . มอร์ริส (1992). สถาปัตยกรรมระบบคอมพิวเตอร์ . เพรนติส ฮอลล์. หน้า 3. ISBN 0-13-175563-3.
- Abd-El-Barr, Mostafa; El-Rewini, Hesham (2004). พื้นฐานขององค์ประกอบและสถาปัตยกรรมคอมพิวเตอร์ . Wiley. หน้า 1. ISBN 0-471-46741-3.
- การ์ดเนอร์, เจ (2001). "สถาปัตยกรรมไมโครของโปรเซสเซอร์พีซี" . เอ็กซ์ตรีมเทค.
- Gilreath, William F.; Laplante, Phillip A. (2012) [2003]. สถาปัตยกรรมคอมพิวเตอร์: มุมมองแบบมินิมัลลิสต์ Springer. ISBN 978-1-4615-0237-1.
- Patterson, David A. (10 ตุลาคม 2018). ยุคทองใหม่สำหรับสถาปัตยกรรมคอมพิวเตอร์ . US Berkeley ACM AM Turing Laureate Colloquium. ctwj53r07yI.
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ สถาปัตยกรรมไมโคร
ใน สาขาอิเล็กทรอนิกส์ วิทยาศาสตร์ คอมพิวเตอร์ และ วิศวกรรมคอมพิวเตอร์ สถาปัตยกรรม ไมโคร หรือที่เรียกว่า การจัดระเบียบคอมพิวเตอร์ และบางครั้งย่อว่า μarch หรือ uarch คือวิธีการที่...
ความสัมพันธ์กับสถาปัตยกรรมชุดคำสั่ง
ISA นั้น โดยคร่าวๆ แล้วเหมือนกับแบบจำลองการเขียนโปรแกรมของโปรเซสเซอร์ในมุมมองของ โปรแกรมเมอร์ ภาษาแอสเซมบลี หรือผู้เขียนคอมไพเลอร์ ISA ประกอบด้วย คำสั่ง แบบ จำลองการประมวล ผล รีจิสเตอร์ของโปรเซสเซอร์ รูปแบบที่อยู่และข้อมูล และอื่นๆ...
แง่มุมต่างๆ
เส้นทาง ข้อมูล แบบไปป์ไลน์ เป็นรูปแบบการออกแบบเส้นทางข้อมูลที่ใช้กันมากที่สุดในสถาปัตยกรรมไมโครในปัจจุบัน เทคนิคนี้ใช้ในไมโครโปรเซสเซอร์ ไมโครคอนโทรลเลอร์ และ DSP สมัยใหม่ส่วนใหญ่ สถาปัตยกรรมแบบไปป์ไลน์ช่วยให้คำสั่งหลายคำสั่งสามารถซ้อนทับกันในการดำเนินการได้...
รอบคำสั่ง
ในการรันโปรแกรม ซีพียูแบบชิปเดี่ยวหรือหลายชิปทั้งหมด: