อ่าน 7 นาที
ทฤษฎีการประมาณค่า
ในทางคณิตศาสตร์ทฤษฎีการประมาณค่าเกี่ยวข้องกับวิธีการประมาณค่าฟังก์ชัน ด้วยฟังก์ชันที่เรียบง่ายกว่า ได้ดีที่สุดและการกำหนดลักษณะเชิงปริมาณของข้อผิดพลาดที่เกิดขึ้นจากวิธีการดังกล่าว.
ทฤษฎีการประมาณค่า
ในทางคณิตศาสตร์ทฤษฎีการประมาณค่าเกี่ยวข้องกับวิธีการประมาณค่าฟังก์ชัน ด้วยฟังก์ชันที่เรียบง่ายกว่า ได้ดีที่สุดและการกำหนดลักษณะเชิงปริมาณของข้อผิดพลาดที่เกิดขึ้นจากวิธีการดังกล่าว ความหมายของคำว่า " ดีที่สุด"และ " เรียบง่ายกว่า"จะขึ้นอยู่กับการประยุกต์ใช้
หัวข้อที่เกี่ยวข้องอย่างใกล้ชิดคือ การประมาณค่าฟังก์ชันโดยใช้ชุดอนุกรมฟูริเยร์แบบทั่วไปซึ่งก็คือการประมาณค่าโดยอาศัยการรวมผลของชุดพจน์ที่อิงตามพหุนามเชิงตั้งฉาก
ปัญหาหนึ่งที่น่าสนใจเป็นพิเศษคือ การประมาณค่าฟังก์ชันใน ไลบรารีทางคณิตศาสตร์ ของคอมพิวเตอร์โดยใช้การดำเนินการที่สามารถทำได้บนคอมพิวเตอร์หรือเครื่องคิดเลข (เช่น การบวกและการคูณ) เพื่อให้ผลลัพธ์ใกล้เคียงกับฟังก์ชันจริงมากที่สุดเท่าที่จะเป็นไปได้ โดยทั่วไปแล้วจะใช้วิธีการประมาณค่าด้วยพหุนามหรือจำนวนตรรกยะ (อัตราส่วนของพหุนาม)
จุดประสงค์คือการทำให้ค่าประมาณใกล้เคียงกับฟังก์ชันจริงมากที่สุด โดยทั่วไปแล้วจะมีความแม่นยำใกล้เคียงกับความแม่นยำของ การคำนวณ เลข ทศนิยมของคอมพิวเตอร์ ซึ่งทำได้โดยการใช้พหุนามดีกรี สูง และ/หรือจำกัดขอบเขตของโดเมนที่พหุนามต้องใช้ในการประมาณฟังก์ชัน การจำกัดขอบเขตมักทำได้โดยการใช้สูตรการบวกหรือการปรับขนาดต่างๆ สำหรับฟังก์ชันที่กำลังประมาณ ไลบรารีทางคณิตศาสตร์สมัยใหม่มักลดขอบเขตลงเป็นส่วนเล็กๆ จำนวนมาก และใช้พหุนามดีกรีต่ำสำหรับแต่ละส่วน
 |  |
พหุนามที่เหมาะสมที่สุด
เมื่อเลือกโดเมน (โดยทั่วไปคือช่วง) และดีกรีของพหุนามแล้ว พหุนามนั้นจะถูกเลือกในลักษณะที่ทำให้ค่าความคลาดเคลื่อนกรณีที่เลวร้ายที่สุดมีค่าน้อยที่สุด กล่าวคือ เป้าหมายคือการลดค่าสูงสุดของโดยที่P ( x ) คือพหุนามประมาณค่าf ( x ) คือฟังก์ชันจริง และxเปลี่ยนแปลงไปตามช่วงที่เลือก สำหรับฟังก์ชันที่มีพฤติกรรมที่ดี จะมี พหุนาม ดีกรีN อยู่ ตัวหนึ่งที่จะทำให้เส้นโค้งความคลาดเคลื่อนแกว่งไปมาระหว่างและรวมทั้งหมดN + 2 ครั้ง ทำให้เกิดความคลาดเคลื่อนกรณีที่เลวร้ายที่สุด เท่ากับ จะเห็นได้ว่ามี พหุนามดีกรี N อยู่ ตัว หนึ่ง ที่สามารถประมาณค่า จุด N + 1 จุดบนเส้นโค้งได้ ทฤษฎีบท การแกว่งเท่า กันยืนยัน ว่าพหุนามดังกล่าวเป็นตัวเลือกที่ดีที่สุดเสมอเป็นไปได้ที่จะสร้างฟังก์ชันf ( x ) ที่ไม่มีพหุนามดังกล่าวอยู่ แต่ในทางปฏิบัติแล้วเกิดขึ้นได้ยาก




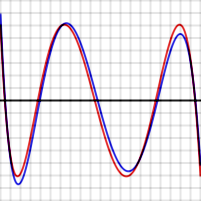
ตัวอย่างเช่น กราฟที่แสดงทางด้านขวาแสดงข้อผิดพลาดในการประมาณค่า log(x) และ exp(x) สำหรับN = 4 เส้นโค้งสีแดงสำหรับพหุนามที่เหมาะสมที่สุดนั้นเป็นเส้นตรงกล่าวคือ เส้นโค้งจะแกว่งไปมาระหว่างและอย่างแม่นยำ ในแต่ละกรณี จำนวนจุดสูงสุดและต่ำสุดคือN + 2 นั่นคือ 6 จุดสูงสุดและต่ำสุดสองจุดอยู่ที่จุดปลายของช่วง ที่ขอบด้านซ้ายและด้านขวาของกราฟ
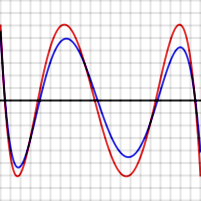
เพื่อพิสูจน์ว่าสิ่งนี้เป็นจริงโดยทั่วไป สมมติว่าPเป็นพหุนามดีกรีNที่มีคุณสมบัติตามที่อธิบายไว้ นั่นคือ มันทำให้เกิดฟังก์ชันความคลาดเคลื่อนที่มี ค่าสุดขั้ว N + 2 ค่า โดยมีเครื่องหมายสลับกันและขนาดเท่ากัน กราฟสีแดงทางด้านขวาแสดงให้เห็นว่าฟังก์ชันความคลาดเคลื่อนนี้อาจมีลักษณะอย่างไรสำหรับN = 4 สมมติว่าQ ( x ) (ซึ่งฟังก์ชันความคลาดเคลื่อนแสดงด้วยสีน้ำเงินทางด้านขวา) เป็นพหุนามดีกรีN อีกตัวหนึ่งที่ประมาณค่า f ได้ดี กว่าPโดยเฉพาะอย่างยิ่งQอยู่ใกล้fมากกว่าPสำหรับแต่ละค่าxᵢที่เกิดค่าสุดขั้วของ P − fดังนั้น

เมื่อค่าสูงสุดของP − fเกิดขึ้นที่x iแล้ว

และเมื่อค่าต่ำสุดของP − fเกิดขึ้นที่x iแล้ว

ดังนั้น ดังที่เห็นได้ในกราฟ [ P ( x ) − f ( x )] − [ Q ( x ) − f ( x )] จะต้องสลับเครื่องหมายสำหรับ ค่า x i จำนวน N + 2 ค่าแต่ [ P ( x ) − f ( x )] − [ Q ( x ) − f ( x )] ลดรูปเป็นP ( x ) − Q ( x ) ซึ่งเป็นพหุนามดีกรีNฟังก์ชันนี้เปลี่ยนเครื่องหมายอย่างน้อยN + 1 ครั้ง ดังนั้น ตามทฤษฎีบทค่ากลาง ฟังก์ชันนี้ จึงมี ราก N + 1 ตัว ซึ่งเป็นไปไม่ได้สำหรับพหุนามดีกรีN
การประมาณค่าเชบิเชฟ
เราสามารถหาพหุนามที่ใกล้เคียงกับค่าที่เหมาะสมที่สุดได้โดยการขยายฟังก์ชันที่กำหนดให้ในรูปของพหุนามเชบิเชฟแล้วตัดการขยายนั้นที่ระดับที่ต้องการ วิธีนี้คล้ายกับการวิเคราะห์ฟูริเยร์ของฟังก์ชัน โดยใช้พหุนามเชบิเชฟแทนฟังก์ชันตรีโกณมิติแบบปกติ
หากเราคำนวณสัมประสิทธิ์ในการกระจายเชบิเชฟสำหรับฟังก์ชันหนึ่ง:

จากนั้นจึงตัดอนุกรมออกหลังจากพจน์นั้น จะได้พหุนามดีกรีN ที่ ประมาณค่า f ( x )

เหตุผลที่พหุนามนี้เกือบจะเหมาะสมที่สุดก็คือ สำหรับฟังก์ชันที่มีอนุกรมกำลังลู่เข้าอย่างรวดเร็ว หากอนุกรมถูกตัดออกหลังจากพจน์ใดพจน์หนึ่ง ข้อผิดพลาดทั้งหมดที่เกิดจากการตัดออกจะใกล้เคียงกับพจน์แรกหลังจากการตัดออก กล่าวคือ พจน์แรกหลังจากการตัดออกจะครอบงำพจน์ต่อๆ ไปทั้งหมด เช่นเดียวกันหากการกระจายอยู่ในรูปของพหุนามบัคกิ้ง หากการกระจายเชบิเชฟถูกตัดออกหลังจากข้อผิดพลาดจะมีรูปแบบที่ใกล้เคียงกับผลคูณของพหุนามเชบิเชฟมีคุณสมบัติว่าเป็นพหุนามระดับ – มันจะแกว่งไปมาระหว่าง +1 และ −1 ในช่วง [−1, 1] มี ค่าสุดขั้วระดับ N + 2 ค่า ซึ่งหมายความว่าข้อผิดพลาดระหว่างf ( x ) และการกระจายเชบิเชฟจนถึง นั้นใกล้เคียงกับฟังก์ชันระดับที่มีค่า สุดขั้ว N + 2 ค่า ดังนั้นจึงใกล้เคียงกับพหุนามดีกรี N ที่ เหมาะสมที่สุด

ในกราฟด้านบน ฟังก์ชันความคลาดเคลื่อนสีน้ำเงินบางครั้งดีกว่า (ภายใน) ฟังก์ชันสีแดง แต่บางครั้งก็แย่กว่า ซึ่งหมายความว่ามันไม่ใช่พหุนามที่เหมาะสมที่สุด ความคลาดเคลื่อนนี้รุนแรงน้อยกว่าสำหรับฟังก์ชัน exp ซึ่งมีอนุกรมกำลังที่ลู่เข้าอย่างรวดเร็วมาก เมื่อเทียบกับฟังก์ชัน log
การประมาณค่าแบบเชบิเชฟเป็นพื้นฐานสำหรับการหา ปริพันธ์เชิงตัวเลข แบบคลีนชอว์-เคอร์ติสซึ่งเป็นเทคนิค การหาปริพันธ์เชิงตัวเลข
อัลกอริทึมของเรเมซ
อัลกอริทึม Remez (บางครั้งสะกดว่า Remes) ใช้ในการสร้างพหุนามP ( x ) ที่เหมาะสมที่สุดเพื่อประมาณค่าฟังก์ชันf ( x ) ที่กำหนดในช่วงเวลาที่กำหนด เป็นอัลกอริทึมแบบวนซ้ำที่ลู่เข้าสู่พหุนามที่มีฟังก์ชันความคลาดเคลื่อนที่มี ค่าสุดขีด N +2 ระดับ ตามทฤษฎีบทข้างต้น พหุนามนั้นจึงเหมาะสมที่สุด
อัลกอริทึมของ Remez ใช้ประโยชน์จากข้อเท็จจริงที่ว่าเราสามารถสร้าง พหุนาม ดีกรีNที่นำไปสู่ค่าความคลาดเคลื่อนที่คงที่และสลับกันได้ โดยกำหนดจุดทดสอบ N + 2 จุด
เมื่อมีจุดทดสอบN + 2 จุด , , ... (โดยที่และน่าจะเป็นจุดปลายของช่วงการประมาณค่า) จะต้องแก้สมการเหล่านี้:




ด้านขวาสลับเครื่องหมายกัน
นั่นคือ

เนื่องจาก, ..., ถูกกำหนดมาแล้ว จึงทราบกำลังของตัวแปรทั้งหมด และ, ..., ก็ทราบเช่นกัน นั่นหมายความว่าสมการข้างต้นเป็นเพียง สมการเชิงเส้น N + 2 สมการใน ตัวแปร N + 2 ตัวคือ, , ..., , และเมื่อกำหนดจุดทดสอบ, ..., แล้ว เราสามารถแก้ระบบสมการนี้เพื่อหาพหุนามPและจำนวนได้





กราฟด้านล่างแสดงตัวอย่างนี้ โดยสร้างพหุนามดีกรีสี่ที่ประมาณค่าในช่วง [−1, 1] จุดทดสอบถูกกำหนดไว้ที่ −1, −0.7, −0.1, +0.4, +0.9 และ 1 ค่าเหล่านี้แสดงด้วยสีเขียว ค่าที่ได้คือ 4.43 × 10 −4

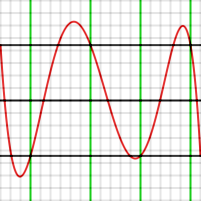
กราฟแสดงข้อผิดพลาดนั้นแสดงค่าที่จุดทดสอบทั้งหกจุด รวมถึงจุดปลายด้วย แต่จุดเหล่านั้นไม่ใช่จุดสุดขั้ว หากจุดทดสอบภายในทั้งสี่จุดเป็นจุดสุดขั้ว (กล่าวคือ ฟังก์ชันP ( x ) f ( x ) มีค่าสูงสุดหรือต่ำสุดที่จุดเหล่านั้น) พหุนามนั้นก็จะเหมาะสมที่สุด

ขั้นตอนที่สองของอัลกอริทึมของ Remez ประกอบด้วยการย้ายจุดทดสอบไปยังตำแหน่งโดยประมาณที่ฟังก์ชันข้อผิดพลาดมีค่าสูงสุดหรือต่ำสุดเฉพาะที่ ตัวอย่างเช่น จากกราฟ เราสามารถบอกได้ว่าจุดที่ −0.1 ควรอยู่ที่ประมาณ −0.28 วิธีการทำเช่นนี้ในอัลกอริทึมคือการใช้รอบเดียวของวิธีของนิวตันเนื่องจากเรารู้ค่าอนุพันธ์อันดับที่หนึ่งและอันดับที่สองของP ( x ) − f ( x )เราจึงสามารถคำนวณได้โดยประมาณว่าต้องย้ายจุดทดสอบไปไกลแค่ไหนเพื่อให้ได้ค่าอนุพันธ์เป็นศูนย์
การคำนวณอนุพันธ์ของพหุนามนั้นทำได้ง่าย นอกจากนี้ยังต้องสามารถคำนวณอนุพันธ์อันดับที่หนึ่งและอันดับที่สองของf ( x ) ได้ด้วย อัลกอริทึมของ Remez ต้องการความสามารถในการคำนวณ, , และด้วยความแม่นยำสูงมาก อัลกอริทึมทั้งหมดต้องดำเนินการด้วยความแม่นยำสูงกว่าความแม่นยำของผลลัพธ์ที่ต้องการ



หลังจากย้ายจุดทดสอบแล้ว จะทำซ้ำส่วนของสมการเชิงเส้นเพื่อสร้างพหุนามใหม่ จากนั้นจึงใช้วิธีของนิวตันในการย้ายจุดทดสอบอีกครั้ง ลำดับนี้จะดำเนินต่อไปจนกว่าผลลัพธ์จะลู่เข้าสู่ความแม่นยำที่ต้องการ อัลกอริทึมนี้ลู่เข้าอย่างรวดเร็วมาก การลู่เข้าเป็นแบบกำลังสองสำหรับฟังก์ชันที่มีคุณสมบัติที่ดี กล่าวคือ ถ้าจุดทดสอบอยู่ภายในค่าที่ถูกต้อง ผลลัพธ์ที่ได้ก็จะอยู่ภายในค่าที่ถูกต้องโดยประมาณหลังจากรอบถัดไป


โดยทั่วไปแล้ว อัลกอริทึมของ Remez จะเริ่มต้นด้วยการเลือกค่าสุดขั้วของพหุนาม Chebyshev เป็นจุดเริ่มต้น เนื่องจากฟังก์ชันข้อผิดพลาดสุดท้ายจะมีลักษณะคล้ายกับพหุนามนั้น
วารสารหลัก
ดูเพิ่มเติม
ลิงก์ภายนอก
- ประวัติความเป็นมาของทฤษฎีการประมาณค่า (HAT)
- การสำรวจในทฤษฎีการประมาณค่า (SAT)
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ ทฤษฎีการประมาณค่า
ในทางคณิตศาสตร์ทฤษฎีการประมาณค่าเกี่ยวข้องกับวิธีการประมาณค่าฟังก์ชัน ด้วยฟังก์ชันที่เรียบง่ายกว่า ได้ดีที่สุดและการกำหนดลักษณะเชิงปริมาณของข้อผิดพลาดที่เกิดขึ้นจากวิธีการดังกล่าว.
พหุนามที่เหมาะสมที่สุด
เมื่อเลือกโดเมน (โดยทั่วไปคือช่วง) และดีกรีของพหุนามแล้ว พหุนามนั้นจะถูกเลือกในลักษณะที่ทำให้ค่าความคลาดเคลื่อนกรณีที่เลวร้ายที่สุดมีค่าน้อยที่สุด กล่าวคือ เป้าหมายคือการลดค่าสูงสุดของโดยที่ P ( x ) คือพหุนามประมาณค่า f ( x ) คือฟังก์ชันจริง และ x...
การประมาณค่าเชบิเชฟ
เราสามารถหาพหุนามที่ใกล้เคียงกับค่าที่เหมาะสมที่สุดได้โดยการขยายฟังก์ชันที่กำหนดให้ในรูปของ พหุนามเชบิเชฟ แล้วตัดการขยายนั้นที่ระดับที่ต้องการ วิธีนี้คล้ายกับ การวิเคราะห์ฟูริเยร์ ของฟังก์ชัน โดยใช้พหุนามเชบิเชฟแทนฟังก์ชันตรีโกณมิติแบบปกติ
อัลกอริทึมของเรเมซ
อั ลกอริทึม Remez (บางครั้งสะกดว่า Remes) ใช้ในการสร้างพหุนาม P ( x ) ที่เหมาะสมที่สุดเพื่อประมาณค่าฟังก์ชัน f ( x ) ที่กำหนดในช่วงเวลาที่กำหนด เป็นอัลกอริทึมแบบวนซ้ำที่ลู่เข้าสู่พหุนามที่มีฟังก์ชันความคลาดเคลื่อนที่มี ค่าสุดขีด N +2 ระดับ ตามทฤษฎีบทข้างต้น...