อ่าน 10 นาที
การทดลองแฟกทอเรียล
ใน ทางสถิติ การ ทดลองแบบแฟกทอเรียล (หรือที่เรียกว่า การทดลองแบบแฟกทอเรียลเต็ม รูปแบบ ) จะศึกษาว่าปัจจัยหลายอย่างมีอิทธิพลต่อผลลัพธ์ที่เฉพาะเจาะจงอย่างไร ซึ่งเรียกว่า ตัวแปรตอบสนอง...
การทดลองแฟกทอเรียล

ในทางสถิติการทดลองแบบแฟกทอเรียล (หรือที่เรียกว่าการทดลองแบบแฟกทอเรียลเต็ม รูปแบบ ) จะศึกษาว่าปัจจัยหลายอย่างมีอิทธิพลต่อผลลัพธ์ที่เฉพาะเจาะจงอย่างไร ซึ่งเรียกว่าตัวแปรตอบสนองโดยแต่ละปัจจัยจะถูกทดสอบที่ค่าหรือระดับที่แตกต่างกัน และการทดลองจะรวมถึงทุกชุดค่าผสมที่เป็นไปได้ของระดับเหล่านี้ในทุกปัจจัย วิธีการที่ครอบคลุมนี้ช่วยให้นักวิจัยเห็นไม่เพียงแต่ว่าแต่ละปัจจัยส่งผลต่อตัวแปรตอบสนองอย่างไร แต่ยังเห็นว่าปัจจัยต่างๆมีปฏิสัมพันธ์และมีอิทธิพลต่อกัน อย่างไรด้วย
โดยทั่วไป การทดลองแบบแฟคทอเรียลจะทำให้สิ่งต่างๆ ง่ายขึ้นโดยใช้เพียงสองระดับสำหรับแต่ละปัจจัย ตัวอย่างเช่น การออกแบบแฟคทอเรียล 2x2 มีสองปัจจัย แต่ละปัจจัยมีสองระดับ ทำให้ได้ชุดค่าผสมที่ไม่ซ้ำกันสี่ชุดเพื่อทดสอบ ปฏิสัมพันธ์ระหว่างปัจจัยเหล่านี้มักเป็นผลลัพธ์ที่สำคัญที่สุด แม้ว่าปัจจัยแต่ละตัวจะมีผลกระทบด้วยเช่นกัน
หากการออกแบบการทดลองแบบแฟคทอเรียลเต็มรูปแบบมีความซับซ้อนเกินไปเนื่องจากจำนวนชุดค่าผสมที่มากเกินไป นักวิจัยสามารถใช้การออกแบบการทดลองแบบแฟคทอเรียลแบบเศษส่วนได้ วิธีนี้จะตัดชุดค่าผสมบางชุดออกอย่างมีกลยุทธ์ (โดยปกติอย่างน้อยครึ่งหนึ่ง) เพื่อให้การทดลองจัดการได้ง่ายขึ้น
การรวมกันของระดับปัจจัยเหล่านี้บางครั้งเรียกว่ารัน (ของการทดลอง) จุด (เมื่อมองการรวมกันเป็นจุดยอดของกราฟ ) และเซลล์ (ที่เกิดขึ้นจากการตัดกันของแถวและคอลัมน์)
ประวัติศาสตร์
การออกแบบแฟกทอเรียลถูกนำมาใช้ในศตวรรษที่ 19 โดยJohn Bennet LawesและJoseph Henry Gilbertแห่งสถานีทดลอง Rothamsted [ 1 ]
โรนัลด์ ฟิชเชอร์ โต้แย้งในปี พ.ศ. 2469 ว่าการออกแบบที่ซับซ้อน (เช่น การออกแบบแฟกทอเรียล) มีประสิทธิภาพมากกว่าการศึกษาปัจจัยทีละอย่าง[ 2 ]ฟิชเชอร์เขียนว่า
ไม่มีสุภาษิตใดที่ถูกกล่าวซ้ำบ่อยเท่ากับคำกล่าวที่ว่า เราต้องถามธรรมชาติเพียงไม่กี่คำถาม หรือในอุดมคติแล้ว ควรถามเพียงคำถามเดียวในแต่ละครั้ง ในบริบทของการทดลองภาคสนาม ผู้เขียนเชื่อมั่นว่ามุมมองนี้ผิดพลาดอย่างสิ้นเชิง เขาเสนอว่า ธรรมชาติจะตอบสนองได้ดีที่สุดต่อแบบสอบถามที่สมเหตุสมผลและคิดมาอย่างรอบคอบ อันที่จริง หากเราถามธรรมชาติเพียงคำถามเดียว ธรรมชาติมักจะปฏิเสธที่จะตอบจนกว่าจะมีการพูดคุยถึงหัวข้ออื่นเสียก่อน
การออกแบบเชิงแฟคทอเรียลช่วยให้สามารถกำหนดผลกระทบของปัจจัยหลายอย่างและแม้กระทั่งปฏิสัมพันธ์ระหว่างปัจจัยเหล่านั้นได้ โดยใช้จำนวนการทดลองเท่ากับจำนวนการทดลองที่จำเป็นในการกำหนดผลกระทบใดผลกระทบหนึ่งเพียงอย่างเดียวด้วยระดับความแม่นยำที่เท่ากัน
แฟรงก์ เยตส์ได้สร้างคุณูปการอย่างมาก โดยเฉพาะอย่างยิ่งในการวิเคราะห์การออกแบบ ด้วยการวิเคราะห์แบบเยตส์
คำว่า "แฟกทอเรียล" อาจไม่ได้ถูกนำมาใช้ในสิ่งพิมพ์ก่อนปี พ.ศ. 2478 เมื่อฟิชเชอร์ใช้คำนี้ในหนังสือของเขาเรื่องThe Design of Experiments [ 3 ]
ข้อดีและข้อเสียของการทดลองแบบแฟคทอเรียล
หลายคนตรวจสอบผลกระทบของปัจจัยหรือตัวแปรเพียงตัวเดียวเท่านั้น เมื่อเปรียบเทียบกับการทดลองแบบปัจจัยเดียวในแต่ละครั้ง (OFAT) การทดลองแบบแฟกทอเรียลมีข้อดีหลายประการ[ 4 ] [ 5 ]
- การออกแบบการทดลองแบบแฟกทอเรียลมีประสิทธิภาพมากกว่าการทดลองแบบ OFAT (One-Off and Attitude Experiment) เนื่องจากให้ข้อมูลมากกว่าในราคาที่ใกล้เคียงกันหรือต่ำกว่า และสามารถค้นหาสภาวะที่เหมาะสมที่สุดได้เร็วกว่าการทดลองแบบ OFAT
- เมื่อผลของปัจจัยหนึ่งแตกต่างกันไปตามระดับต่างๆ ของอีกปัจจัยหนึ่ง การออกแบบการทดลองแบบ OFAT จะไม่สามารถตรวจจับปฏิสัมพันธ์ ดังกล่าวได้ จำเป็นต้องใช้การออกแบบการทดลองแบบแฟกทอเรียลเพื่อตรวจจับปฏิสัมพันธ์ดัง กล่าว การใช้ OFAT เมื่อมีปฏิสัมพันธ์เกิดขึ้นอาจนำไปสู่ความเข้าใจผิดอย่างร้ายแรงเกี่ยวกับวิธีการเปลี่ยนแปลงของผลตอบสนองตามปัจจัยต่างๆ
- การออกแบบการทดลองแบบแฟกทอเรียลช่วยให้สามารถประเมินผลกระทบของปัจจัยหนึ่งได้ในหลายระดับของปัจจัยอื่นๆ ทำให้ได้ข้อสรุปที่ถูกต้องในเงื่อนไขการทดลองที่หลากหลาย
ข้อเสียหลักของการออกแบบแฟกทอเรียลเต็มรูปแบบคือความต้องการขนาดตัวอย่าง ซึ่งเพิ่มขึ้นแบบทวีคูณตามจำนวนปัจจัยหรืออินพุตที่พิจารณา[ 6 ]กลยุทธ์ทางเลือกที่มีประสิทธิภาพในการคำนวณที่ดีขึ้น ได้แก่ การออกแบบแฟกทอเรี ยล แบบเศษส่วนการสุ่มตัวอย่างแบบลาตินไฮเปอร์คิวบ์และเทคนิคการสุ่มตัวอย่างแบบกึ่งสุ่ม
ตัวอย่างข้อดีของการทดลองแบบแฟกทอเรียล
ในหนังสือของเขาImproving Almost Anything: Ideas and EssaysนักสถิติGeorge Boxได้ยกตัวอย่างมากมายเกี่ยวกับประโยชน์ของการทดลองแบบแฟกทอเรียล นี่คือตัวอย่างหนึ่ง[ 7 ]วิศวกรที่บริษัทผลิตตลับลูกปืน SKF ต้องการทราบว่าการเปลี่ยนไปใช้การออกแบบ "กรง" ที่ราคาถูกกว่าจะส่งผล ต่ออายุการใช้งาน ของตลับลูกปืนหรือไม่ วิศวกรได้ขอความช่วยเหลือจาก Christer Hellstrand นักสถิติ ในการออกแบบการทดลอง[ 8 ]

บริษัทบ็อกซ์รายงานดังต่อไปนี้ "ผลลัพธ์ได้รับการประเมินโดยการทดสอบอายุการใช้งานแบบเร่ง ... การทดลองมีค่าใช้จ่ายสูงเพราะต้องทำการทดลองบนสายการผลิตจริง และผู้ทำการทดลองวางแผนที่จะทำการทดลองสี่ครั้งด้วยกรงมาตรฐานและสี่ครั้งด้วยกรงที่ดัดแปลง คริสเตอร์ถามว่ามีปัจจัยอื่น ๆ ที่พวกเขาต้องการทดสอบหรือไม่ พวกเขาบอกว่ามี แต่การเพิ่มจำนวนการทดลองจะเกินงบประมาณ คริสเตอร์จึงแสดงให้พวกเขาเห็นว่าพวกเขาสามารถทดสอบปัจจัยเพิ่มเติมอีกสองปัจจัยได้ "ฟรี" โดยไม่ต้องเพิ่มจำนวนการทดลองและไม่ลดความแม่นยำของการประมาณผลกระทบของกรง ในการจัดเรียงนี้ เรียกว่าการออกแบบแฟคทอเรียล 2×2×2 แต่ละปัจจัยทั้งสามจะถูกทดลองที่สองระดับและรวมชุดค่าผสมที่เป็นไปได้ทั้งหมดแปดชุด ชุดค่าผสมต่างๆ สามารถแสดงได้อย่างสะดวกเป็นจุดยอดของลูกบาศก์ ... " "ในแต่ละกรณี สภาวะมาตรฐานจะแสดงด้วยเครื่องหมายลบ และสภาวะที่ดัดแปลงจะแสดงด้วยเครื่องหมายบวก ปัจจัยที่เปลี่ยนแปลงคือการอบชุบด้วยความร้อน การสัมผัสของวงแหวนด้านนอก และการออกแบบกรง ตัวเลขแสดงความยาวสัมพัทธ์ของอายุการใช้งานของตลับลูกปืน หากคุณดูที่ [กราฟลูกบาศก์] คุณจะเห็นว่าการเลือกการออกแบบกรงไม่ได้ สร้างความแตกต่างอย่างมาก... แต่ถ้าคุณหาค่าเฉลี่ยของตัวเลขคู่ต่างๆ สำหรับการออกแบบกรง คุณจะได้ [ตารางด้านล่าง] ซึ่งแสดงให้เห็นว่าปัจจัยอีกสองอย่างมีผลอย่างไร... มันนำไปสู่การค้นพบที่น่าทึ่งว่า ในการใช้งานเฉพาะนี้ อายุการใช้งานของตลับลูกปืนสามารถเพิ่มขึ้นได้ถึงห้าเท่า หากเพิ่มปัจจัยสองอย่าง คือ การสัมผัสของวงแหวนด้านนอกและการอบชุบความร้อนของวงแหวนด้านในไปพร้อมๆ กัน"
| การสั่น − | การสั่น + | |
|---|---|---|
| ความร้อน − | 18 | 23 |
| ความร้อน + | 21 | 106 |
"เมื่อนึกถึงว่าตลับลูกปืนแบบนี้มีการผลิตมานานหลายทศวรรษแล้ว ในตอนแรกจึงน่าประหลาดใจว่าทำไมจึงใช้เวลานานมากในการค้นพบการปรับปรุงที่สำคัญเช่นนี้ คำอธิบายที่เป็นไปได้คือ เนื่องจากวิศวกรส่วนใหญ่จนกระทั่งเมื่อไม่นานมานี้ ได้ทำการทดลองโดยพิจารณาปัจจัยเพียงปัจจัยเดียวในแต่ละครั้ง จึง มองข้ามผลกระทบ จากปฏิสัมพันธ์ไป"
ตัวอย่าง
การทดลองแบบแฟกทอเรียลที่ง่ายที่สุดประกอบด้วยสองระดับสำหรับแต่ละปัจจัยสองปัจจัย สมมติว่าวิศวกรต้องการศึกษาพลังงานรวมที่ใช้โดยมอเตอร์สองตัวที่แตกต่างกัน คือ มอเตอร์ A และมอเตอร์ B ซึ่งทำงานที่ความเร็วสองระดับที่แตกต่างกัน คือ 2000 หรือ 3000 รอบต่อนาที การทดลองแบบแฟกทอเรียลจะประกอบด้วยหน่วยทดลองสี่หน่วย ได้แก่ มอเตอร์ A ที่ 2000 รอบต่อนาที มอเตอร์ B ที่ 2000 รอบต่อนาที มอเตอร์ A ที่ 3000 รอบต่อนาที และมอเตอร์ B ที่ 3000 รอบต่อนาที แต่ละชุดของระดับเดียวที่เลือกจากแต่ละปัจจัยจะมีอยู่เพียงครั้งเดียว
การทดลองนี้เป็นตัวอย่างของ การทดลองแบบแฟคทอเรียล 2x2 (หรือ 2×2) ซึ่งตั้งชื่อเช่นนี้เพราะพิจารณาสองระดับ (ฐาน) สำหรับแต่ละปัจจัยสองตัว (เลขยกกำลังหรือเลขยกกำลัง) หรือ #ระดับ#ปัจจัยทำให้ได้จุด แฟคทอเรียล 2x2 = 4 จุด
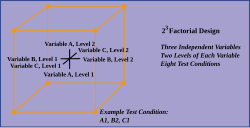
การออกแบบอาจเกี่ยวข้องกับตัวแปรอิสระหลายตัว ตัวอย่างเช่น ผลกระทบของตัวแปรป้อนเข้าสามตัวสามารถประเมินได้ในเงื่อนไขการทดลองแปดแบบ ซึ่งแสดงเป็นมุมของลูกบาศก์
การทดลองนี้สามารถดำเนินการได้โดยมีการทำซ้ำหรือไม่ทำซ้ำก็ได้ ขึ้นอยู่กับวัตถุประสงค์และทรัพยากรที่มีอยู่ ผลการทดลองจะแสดงผลกระทบของตัวแปรอิสระทั้งสามต่อตัวแปรตาม และปฏิสัมพันธ์ที่อาจเกิดขึ้น
สัญกรณ์
การทดลองแบบแฟกทอเรียลอธิบายได้ด้วยสองสิ่ง คือ จำนวนปัจจัย และจำนวนระดับของแต่ละปัจจัย ตัวอย่างเช่น การทดลองแบบแฟกทอเรียล 2×3 มีสองปัจจัย ปัจจัยแรกมี 2 ระดับ และปัจจัยที่สองมี 3 ระดับ การทดลองดังกล่าวจะมีชุดการทดลองหรือเซลล์ทั้งหมด 2×3=6 ชุด ในทำนองเดียวกัน การทดลองแบบ 2×2×3 มีสามปัจจัย สองปัจจัยมี 2 ระดับ และอีกหนึ่งปัจจัยมี 3 ระดับ รวมเป็น 12 ชุดการทดลอง หากแต่ละปัจจัยมีsระดับ (เรียกว่า การออกแบบ ระดับคงที่หรือแบบสมมาตร ) การทดลองมักจะแสดงด้วยs k โดย ที่kคือจำนวนปัจจัย ดังนั้น การทดลองแบบ 2 × 5จะมี 5 ปัจจัย แต่ละปัจจัยมี 2 ระดับ การทดลองที่ไม่ใช่ระดับคงที่เรียกว่าการทดลองระดับผสมหรือแบบไม่สมมาตร
มีธรรมเนียมปฏิบัติต่างๆ มากมายในการกำหนดระดับของแต่ละปัจจัย หากปัจจัยนั้นมีหน่วยตามธรรมชาติอยู่แล้ว ก็จะใช้หน่วยเหล่านั้น ตัวอย่างเช่น การทดลองเพาะเลี้ยงกุ้ง[ 9 ]อาจมีปัจจัยอุณหภูมิที่ 25 °C และ 35 °C ความหนาแน่นที่ 80 หรือ 160 ตัว/40 ลิตร และความเค็มที่ 10%, 25% และ 40% อย่างไรก็ตาม ในหลายกรณี ระดับของปัจจัยเป็นเพียงหมวดหมู่ และการกำหนดรหัสระดับนั้นค่อนข้างเป็นไปตามอำเภอใจ ตัวอย่างเช่น ระดับของปัจจัย 6 ระดับ อาจกำหนดเป็น 1, 2, ..., 6 ก็ได้
บี เอ | 1 | 2 | 3 |
| 1 | 11 | 12 | 13 |
| 2 | 21 | 22 | 23 |
ชุดการทดลองจะแสดงด้วยคู่ลำดับ หรือโดยทั่วไปแล้วคือทูเปิล ลำดับ ในการทดลองด้านการเพาะเลี้ยงสัตว์น้ำ ลำดับสามตัว (25, 80, 10) แสดงถึงชุดการทดลองที่มีระดับของแต่ละปัจจัยต่ำที่สุด ในการทดลองแบบ 2×3 ทั่วไป คู่ลำดับ (2, 1) จะแสดงถึงเซลล์ที่ปัจจัยAอยู่ที่ระดับ 2 และปัจจัยBอยู่ที่ระดับ 1 วงเล็บมักจะถูกละทิ้ง ดังแสดงในตารางประกอบ
| ต่ำทั้งคู่ | 00 | −− | (1) |
| ต่ำ | 01 | −+ | เอ |
| เป่า | 10 | − บวก | ข |
| ทั้งคู่สูง | 11 | ++ | ab |
ในการระบุระดับปัจจัยในการทดลอง 2k นั้นมีระบบเฉพาะสามระบบที่ปรากฏในเอกสารทางวิชาการ:
- ค่าคือ 1 และ 0;
- ค่า 1 และ −1 ซึ่งมักจะย่อด้วย + และ −;
- ตัวอักษรพิมพ์เล็กที่มีเลขชี้กำลังเป็น 0 หรือ 1
หากค่าเหล่านี้แสดงถึงการตั้งค่า "ต่ำ" และ "สูง" ของการรักษาแล้ว เป็นเรื่องปกติที่จะให้ 1 แทน "สูง" ไม่ว่าจะใช้ 0 และ 1 หรือ −1 และ 1 ก็ตาม ดังแสดงในตารางประกอบสำหรับการทดลอง 2×2 หากระดับปัจจัยเป็นเพียงหมวดหมู่ ความสัมพันธ์อาจแตกต่างออกไป ตัวอย่างเช่น เป็นเรื่องปกติที่จะแสดงเงื่อนไข "ควบคุม" และ "ทดลอง" โดยการเข้ารหัส "ควบคุม" เป็น 0 หากใช้ 0 และ 1 และเป็น 1 หากใช้ 1 และ −1 [หมายเหตุ 1 ]ตัวอย่างของกรณีหลังแสดงไว้ด้านล่างตัวอย่างนั้นแสดงให้เห็นถึงการใช้การเข้ารหัส +1 และ −1 อีกแบบหนึ่ง
สำหรับการทดลองระดับคงที่อื่นๆ ( s k ) ค่า 0, 1, ..., s −1 มักใช้เพื่อระบุระดับปัจจัย ค่าเหล่านี้คือค่าของจำนวนเต็มมอดูล sเมื่อsเป็นจำนวนเฉพาะ[หมายเหตุ 2 ]
ความแตกต่าง ผลกระทบหลัก และปฏิสัมพันธ์
บี เอ | 1 | 2 | 3 |
| 1 | μ 11 | μ 12 | μ 13 |
| 2 | μ 21 | μ 22 | μ 23 |
การตอบสนองที่คาดหวังต่อชุดการรักษาที่กำหนดเรียกว่า ค่าเฉลี่ย ของเซลล์[ 12 ]ซึ่งมักจะใช้ตัวอักษรกรีก μ แทน (คำว่าเซลล์ยืมมาจากการใช้งานในตารางข้อมูล ) สัญลักษณ์นี้แสดงให้เห็นที่นี่สำหรับการทดลอง 2 × 3
ความแตกต่างของค่าเฉลี่ยในแต่ละกลุ่มคือการรวมกันเชิงเส้นของค่าเฉลี่ยในแต่ละกลุ่ม โดยที่ผลรวมของสัมประสิทธิ์เท่ากับ 0 ความแตกต่างเหล่านี้มีความน่าสนใจในตัวเอง และเป็นองค์ประกอบพื้นฐานที่ใช้ในการกำหนดผลกระทบหลักและปฏิสัมพันธ์ต่างๆ
ในการทดลอง 2 × 3 ที่แสดงไว้ในที่นี้ นิพจน์

เป็นการเปรียบเทียบค่าเฉลี่ยของการตอบสนองของชุดการทดลองที่ 11 และ 12 (ค่าสัมประสิทธิ์ในที่นี้คือ 1 และ –1) การเปรียบเทียบนี้

กล่าวกันว่าค่าดังกล่าวเป็นผลหลักของปัจจัย Aเนื่องจากเป็นการเปรียบเทียบการตอบสนองต่อปัจจัยระดับ "1" กับการตอบสนองต่อปัจจัยระดับ "2" กล่าวได้ว่าไม่มี ผลหลักของ Aหากค่าเฉลี่ยที่แท้จริงของเซลล์ทำให้ค่าดังกล่าวเท่ากับ 0 เนื่องจากโดยหลักการแล้ว ค่าเฉลี่ยที่แท้จริงของเซลล์นั้น ไม่สามารถสังเกตได้ จึงต้องใช้ การทดสอบสมมติฐานทางสถิติเพื่อประเมินว่าค่าดังกล่าวเท่ากับ 0 หรือไม่


ปฏิสัมพันธ์ในการทดลองแบบแฟคทอเรียล คือการที่ปัจจัยต่างๆ ไม่สามารถบวกกันได้และยังแสดงออกด้วยค่าความแตกต่าง ในการทดลองแบบ 2 × 3 ค่าความแตกต่างคือ...
และ


เป็นส่วนหนึ่งของปฏิสัมพันธ์ A × B ; ปฏิสัมพันธ์จะไม่มีอยู่ (มีการบวก)หากนิพจน์เหล่านี้เท่ากับ 0 [ 13 ] [ 14 ] การบวกอาจถูกมองว่าเป็นความขนานกันระหว่างปัจจัยต่างๆ ดังที่แสดงไว้ในส่วนการวิเคราะห์ด้านล่างเช่นเดียวกับผลกระทบหลัก เราจะประเมินสมมติฐานของการบวกโดยการทำการทดสอบสมมติฐาน
เนื่องจากค่าสัมประสิทธิ์ของความแตกต่างเหล่านี้มีข้อมูลสำคัญ จึงมักแสดงเป็นเวกเตอร์คอลัมน์สำหรับตัวอย่างข้างต้น ตารางดังกล่าวอาจมีลักษณะดังนี้: [ 15 ]
| เซลล์ | |||||
|---|---|---|---|---|---|
| 11 | 1 | 1 | 0 | 1 | 1 |
| 12 | 1 | −1 | 1 | -1 | 0 |
| 13 | 1 | 0 | −1 | 0 | −1 |
| 21 | −1 | 1 | 0 | −1 | -1 |
| 22 | −1 | −1 | 1 | 1 | 0 |
| 23 | −1 | 0 | −1 | 0 | 1 |


คอลัมน์ของตารางดังกล่าวเรียกว่าเวกเตอร์ความแตกต่าง : ผลรวมของส่วนประกอบในคอลัมน์ เหล่า นั้นเท่ากับ 0 ผลกระทบแต่ละอย่างถูกกำหนดโดยทั้งรูปแบบของส่วนประกอบในคอลัมน์และจำนวนคอลัมน์
รูปแบบของส่วนประกอบของคอลัมน์เหล่านี้สะท้อนถึงคำจำกัดความทั่วไปที่Bose ให้ไว้ : [ 16 ]
- เวกเตอร์ความแตกต่างจะจัดอยู่ในกลุ่มผลกระทบหลักของปัจจัยใดปัจจัยหนึ่งก็ต่อเมื่อค่าของส่วนประกอบต่างๆ ในเวกเตอร์นั้นขึ้นอยู่กับระดับของปัจจัยนั้นเท่านั้น
- เวกเตอร์ความแตกต่างเป็นของปฏิสัมพันธ์ระหว่างสองปัจจัยเช่นAและBก็ต่อเมื่อ (i) ค่าของส่วนประกอบขึ้นอยู่กับระดับของAและB เท่านั้น และ (ii) เป็น เวกเตอร์ ตั้งฉาก (ตั้งฉาก) กับเวกเตอร์ความแตกต่างที่แสดง ถึงผลหลักของAและB [หมายเหตุ 3 ]
นิยามที่คล้ายกันนี้ใช้ได้กับการปฏิสัมพันธ์ของปัจจัยมากกว่าสองปัจจัย ตัวอย่างเช่น ในตัวอย่าง 2 × 3 รูปแบบของ คอลัมน์ Aจะเป็นไปตามรูปแบบของระดับของปัจจัยAซึ่งระบุโดยส่วนประกอบแรกของแต่ละเซลล์ ในทำนองเดียวกัน รูปแบบของ คอลัมน์ Bจะเป็นไปตามระดับของปัจจัยB (การเรียงลำดับตามBทำให้มองเห็นได้ง่ายขึ้น)
จำนวนคอลัมน์ที่จำเป็นในการระบุผลกระทบแต่ละรายการคือระดับความเป็นอิสระสำหรับผลกระทบ[หมายเหตุ 4 ]และเป็นปริมาณที่สำคัญในการวิเคราะห์ความแปรปรวนสูตรมีดังนี้: [ 18 ] [ 19 ]
- ผลกระทบหลักสำหรับปัจจัยที่มีsระดับ จะมีองศาอิสระs −1
- ปฏิสัมพันธ์ของปัจจัยสองตัวที่มี ระดับ s 1และs 2ตามลำดับ มีองศาอิสระ ( s 1 −1)( s 2 −1)
สูตรสำหรับปัจจัยมากกว่าสองตัวจะใช้รูปแบบนี้ ในตัวอย่าง 2 × 3 ข้างต้น จำนวนองศาอิสระสำหรับผลกระทบหลักสองตัวและการปฏิสัมพันธ์ — จำนวนคอลัมน์สำหรับแต่ละตัว — คือ 1, 2 และ 2 ตามลำดับ
ตัวอย่าง
ในตารางตัวอย่างต่อไปนี้ ข้อมูลในคอลัมน์ "cell" คือชุดการทดลอง: ส่วนประกอบแรกของแต่ละชุดคือระดับของปัจจัยAส่วนประกอบที่สองสำหรับปัจจัยBและส่วนประกอบที่สาม (ในตัวอย่าง 2 × 2 × 2) คือระดับของปัจจัยCผลรวมของข้อมูลในคอลัมน์อื่นๆ เท่ากับ 0 ดังนั้นแต่ละคอลัมน์จึงเป็นเวกเตอร์เปรียบเทียบ
| เซลล์ | ||||||||
|---|---|---|---|---|---|---|---|---|
| 00 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 01 | 1 | 1 | -1 | 0 | -1 | 0 | -1 | 0 |
| 02 | 1 | 1 | 0 | -1 | 0 | -1 | 0 | -1 |
| 10 | -1 | 0 | 1 | 1 | -1 | -1 | 0 | 0 |
| 11 | -1 | 0 | -1 | 0 | 1 | 0 | 0 | 0 |
| 12 | -1 | 0 | 0 | -1 | 0 | 1 | 0 | 0 |
| 20 | 0 | -1 | 1 | 1 | 0 | 0 | -1 | -1 |
| 21 | 0 | -1 | -1 | 0 | 0 | 0 | 1 | 0 |
| 22 | 0 | -1 | 0 | -1 | 0 | 0 | 0 | 1 |

การทดลองแบบ 3 × 3:ในที่นี้ เราคาดว่าจะมี 3⁻¹ = 2 องศาอิสระสำหรับผลกระทบหลักของปัจจัยAและBและ (3⁻¹)(3⁻¹) = 4 องศาอิสระสำหรับ ปฏิสัมพันธ์ A × Bซึ่งสอดคล้องกับจำนวนคอลัมน์สำหรับแต่ละผลกระทบในตารางที่แนบมาด้วย
เวกเตอร์ความแตกต่างสองตัวสำหรับAขึ้นอยู่กับระดับของปัจจัยA เท่านั้น สามารถสังเกตได้ว่ารูปแบบของข้อมูลในแต่ละ คอลัมน์ ของ Aนั้นเหมือนกับรูปแบบของส่วนประกอบแรกของ "เซลล์" (หากจำเป็น การเรียงลำดับตารางตามAจะแสดงให้เห็น) ดังนั้น เวกเตอร์ทั้งสองนี้จึงเป็นผลหลักของAในทำนองเดียวกัน เวกเตอร์ความแตกต่างสองตัวสำหรับBขึ้นอยู่กับระดับของปัจจัยB เท่านั้น กล่าวคือ ส่วนประกอบที่สองของ "เซลล์" ดังนั้นจึงเป็นผลหลักของB เช่น กัน
เวกเตอร์คอลัมน์สี่ตัวสุดท้ายเป็นของ ปฏิสัมพันธ์ A × Bเนื่องจากค่าในเวกเตอร์เหล่านั้นขึ้นอยู่กับค่าของทั้งสองปัจจัย และเนื่องจากคอลัมน์ทั้งสี่ตั้งฉากกับคอลัมน์ของAและBซึ่งสามารถตรวจสอบได้โดยการหาผลคูณดอท
การทดลองแบบ 2 × 2 × 2: การทดลองนี้จะมีระดับความเป็นอิสระ 1 ระดับสำหรับผลกระทบหลักและปฏิสัมพันธ์แต่ละรายการ ตัวอย่างเช่น ปฏิสัมพันธ์แบบสองปัจจัยจะมีระดับความเป็นอิสระ (2-1)(2-1) = 1 ระดับ ดังนั้นจึงจำเป็นต้องใช้เพียงคอลัมน์เดียวเพื่อระบุผลกระทบทั้งเจ็ดรายการ
| เซลล์ | |||||||
|---|---|---|---|---|---|---|---|
| 000 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 001 | 1 | 1 | −1 | 1 | −1 | −1 | −1 |
| 010 | 1 | −1 | 1 | −1 | 1 | −1 | −1 |
| 011 | 1 | −1 | −1 | −1 | −1 | 1 | 1 |
| 100 | −1 | 1 | 1 | −1 | −1 | 1 | −1 |
| 101 | −1 | 1 | −1 | −1 | 1 | −1 | 1 |
| 110 | −1 | −1 | 1 | 1 | −1 | −1 | 1 |
| 111 | −1 | −1 | −1 | 1 | 1 | 1 | −1 |






คอลัมน์A , BและCแสดงถึงผลกระทบหลักที่สอดคล้องกัน เนื่องจากค่าในแต่ละคอลัมน์ขึ้นอยู่กับระดับของปัจจัยที่เกี่ยวข้องเท่านั้น ตัวอย่างเช่น ค่าใน คอลัมน์ Bจะมีรูปแบบเดียวกันกับส่วนประกอบตรงกลางของ "เซลล์" ดังที่เห็นได้จากการเรียงลำดับตาม B
คอลัมน์AB , ACและBCแสดงถึงปฏิสัมพันธ์สองปัจจัยที่สอดคล้องกัน ตัวอย่างเช่น (i) ค่าใน คอลัมน์ BCขึ้นอยู่กับส่วนประกอบที่สองและสาม ( BและC ) ของเซลล์และไม่ขึ้นอยู่กับส่วนประกอบแรก ( A ) ดังที่เห็นได้จากการเรียงลำดับตามBCและ (ii) คอลัมน์ BCตั้งฉากกับคอลัมน์BและCดังที่สามารถตรวจสอบได้โดยการคำนวณผลคูณดอท
สุดท้ายนี้ คอลัมน์ ABCแสดงถึงปฏิสัมพันธ์สามปัจจัย โดยค่าในคอลัมน์นี้ขึ้นอยู่กับระดับของปัจจัยทั้งสาม และตั้งฉากกับเวกเตอร์ความแตกต่างอีกหกตัว
เมื่อนำคอลัมน์ A, B, Cมารวมกันและอ่านทีละแถวจะได้สัญลักษณ์อีกแบบหนึ่งตามที่กล่าวไว้ข้างต้น สำหรับชุดการทดลอง (เซลล์) ในการทดลองนี้: เซลล์ 000 สอดคล้องกับ +++, 001 สอดคล้องกับ ++− เป็นต้น
ในคอลัมน์AถึงABCตัวเลข 1 อาจถูกแทนที่ด้วยค่าคงที่ใดๆ ก็ได้ เนื่องจากคอลัมน์ที่ได้จะยังคงเป็นเวกเตอร์ความแตกต่างอยู่ ตัวอย่างเช่น เป็นเรื่องปกติที่จะใช้ตัวเลข 1/4 ในการทดลอง 2 × 2 × 2 [หมายเหตุ 5 ]เพื่อกำหนดผลกระทบหลักหรือปฏิสัมพันธ์แต่ละรายการ และเพื่อประกาศ ตัวอย่างเช่น ความแตกต่าง

คือ "ผล" หลักของปัจจัยAซึ่งเป็นปริมาณเชิงตัวเลขที่สามารถประมาณได้[ 20 ]
การดำเนินการ
สำหรับปัจจัยมากกว่าสองปัจจัย การทดลองแบบแฟคทอเรียล 2k โดยทั่วไปสามารถออกแบบซ้ำได้จากการทดลองแบบแฟคทอเรียล 2k - 1โดยการทำซ้ำการทดลอง 2k - 1กำหนดให้ตัวอย่างที่ทำซ้ำครั้งแรกเป็นระดับแรก (หรือระดับต่ำ) ของปัจจัยใหม่ และตัวอย่างที่ทำซ้ำครั้งที่สองเป็นระดับที่สอง (หรือระดับสูง) กรอบการทำงานนี้สามารถขยายไปสู่การ ออกแบบ ตัวอย่าง ที่ทำซ้ำสามครั้งสำหรับปัจจัยสามระดับเป็นต้น
การทดลองแบบแฟคทอเรียลช่วยให้สามารถประมาณค่าความคลาดเคลื่อนของการทดลองได้สองวิธี วิธีแรก คือ การทำซ้ำ การทดลอง หรือ อีกวิธีหนึ่งคือการใช้ หลักการความเบาบางของผลกระทบ การทำซ้ำเป็นวิธีที่ใช้กันทั่วไปสำหรับการทดลองขนาดเล็กและเป็นวิธีที่เชื่อถือได้มากในการประเมินความคลาดเคลื่อนของการทดลอง เมื่อจำนวนปัจจัยมีมาก (โดยทั่วไปมากกว่าประมาณ 5 ปัจจัย แต่ก็แตกต่างกันไปตามการใช้งาน) การทำซ้ำการออกแบบอาจทำได้ยากในทางปฏิบัติ ในกรณีเหล่านี้ มักจะทำการทดลองซ้ำเพียงครั้งเดียว และสมมติว่าปฏิสัมพันธ์ระหว่างปัจจัยที่มีลำดับสูงกว่าลำดับหนึ่ง (เช่น ระหว่างสามปัจจัยขึ้นไป) นั้นมีค่าเล็กน้อย ภายใต้สมมติฐานนี้ ค่าประมาณของปฏิสัมพันธ์ที่มีลำดับสูงดังกล่าวจะเป็นค่าประมาณของศูนย์ที่แน่นอน ดังนั้นจึงเป็นเพียงค่าประมาณของความคลาดเคลื่อนของการทดลองเท่านั้น
เมื่อมีปัจจัยหลายอย่าง การทดลองหลายครั้งจึงจำเป็น แม้ว่าจะไม่มีการทำซ้ำก็ตาม ตัวอย่างเช่น การทดลองกับปัจจัย 10 ตัว โดยแต่ละตัวมี 2 ระดับ จะได้ผลลัพธ์ 2¹⁰ = 10²⁴ ชุดค่าผสม ในบางจุด วิธีนี้อาจทำได้ยากเนื่องจากค่าใช้จ่ายสูงหรือทรัพยากรไม่เพียงพอ ในกรณีนี้อาจใช้ การออกแบบแฟกทอเรียลแบบเศษส่วน ได้
เช่นเดียวกับการทดลองทางสถิติใดๆ การทดลองแบบแฟคทอเรียลควรได้รับการสุ่มเพื่อลดผลกระทบที่อคติอาจมีต่อผลการทดลอง ในทางปฏิบัติ นี่อาจเป็นความท้าทายในการดำเนินงานอย่างมาก
การทดลองแบบแฟกทอเรียลสามารถใช้ได้เมื่อแต่ละปัจจัยมีมากกว่าสองระดับ อย่างไรก็ตาม จำนวนการทดลองที่จำเป็นสำหรับการออกแบบแฟกทอเรียลสามระดับ (หรือมากกว่า) จะมากกว่าการออกแบบแฟกทอเรียลสองระดับอย่างมาก ดังนั้น การออกแบบแฟกทอเรียลจึงน่าสนใจน้อยลงหากนักวิจัยต้องการพิจารณามากกว่าสองระดับ
การวิเคราะห์
การทดลองแฟกทอเรียลสามารถวิเคราะห์ได้โดยใช้ANOVAหรือการวิเคราะห์การถดถอย [ 21 ] ในการคำนวณผลหลักของปัจจัย "A" ในการทดลอง 2 ระดับ ให้ลบค่าเฉลี่ยการตอบสนองของการทดลองทั้งหมดที่ A อยู่ในระดับต่ำ (หรือระดับแรก) ออกจากค่าเฉลี่ยการตอบสนองของการทดลองทั้งหมดที่ A อยู่ในระดับสูง (หรือระดับที่สอง)
เครื่องมือวิเคราะห์เชิงสำรวจที่มีประโยชน์อื่นๆ สำหรับการทดลองแบบแฟคทอเรียล ได้แก่แผนภาพผลกระทบหลักแผนภาพปฏิสัมพันธ์แผนภาพพาเรโตและแผนภาพความน่าจะเป็นปกติของผลกระทบที่ประมาณ ได้
เมื่อปัจจัยเป็นแบบต่อเนื่อง การออกแบบการทดลองแบบแฟคทอเรียลสองระดับจะถือว่าผลกระทบเป็นแบบเชิงเส้นหาก คาดว่าปัจจัยจะมีผลกระทบ แบบกำลังสองควรใช้การทดลองที่ซับซ้อนกว่า เช่นการออกแบบแบบผสมส่วนกลางการหาค่าที่เหมาะสมที่สุดของปัจจัยที่อาจมีผลกระทบแบบกำลังสองเป็นเป้าหมายหลักของ ระเบียบวิธีพื้นผิว ตอบ สนอง
ตัวอย่างการวิเคราะห์
Montgomery [ 4 ]ให้ตัวอย่างการวิเคราะห์การทดลองแฟกทอเรียลดังต่อไปนี้:
วิศวกรต้องการเพิ่มอัตราการกรอง (ผลผลิต) ของกระบวนการผลิตสารเคมี และลดปริมาณฟอร์มาลดีไฮด์ที่ใช้ในกระบวนการ ความพยายามก่อนหน้านี้ในการลดฟอร์มาลดีไฮด์ส่งผลให้ลดอัตราการกรองลง อัตราการกรองปัจจุบันอยู่ที่ 75 แกลลอนต่อชั่วโมง ปัจจัยที่พิจารณามีสี่อย่าง ได้แก่ อุณหภูมิ (A) ความดัน (B) ความเข้มข้นของฟอร์มาลดีไฮด์ (C) และอัตราการกวน (D) แต่ละปัจจัยจะถูกทดสอบที่สองระดับ
ต่อจากนี้ไป เครื่องหมายลบ (−) และเครื่องหมายบวก (+) จะบ่งบอกว่าปัจจัยนั้นทำงานในระดับต่ำหรือระดับสูง ตามลำดับ
| เอ | บี | ซี | ดี | อัตราการกรอง |
|---|---|---|---|---|
| − | − | − | − | 45 |
| + | − | − | − | 71 |
| − | + | − | − | 48 |
| + | + | − | − | 65 |
| − | − | + | − | 68 |
| + | − | + | − | 60 |
| − | + | + | − | 80 |
| + | + | + | − | 65 |
| − | − | − | + | 43 |
| + | − | − | + | 100 |
| − | + | − | + | 45 |
| + | + | − | + | 104 |
| − | − | + | + | 75 |
| + | − | + | + | 86 |
| − | + | + | + | 70 |
| + | + | + | + | 96 |
 แผนภูมิแสดงผลกระทบหลัก โดยแสดงอัตราการกรองสำหรับการตั้งค่าต่ำ (−) และสูง (+) สำหรับแต่ละปัจจัย
แผนภูมิแสดงผลกระทบหลัก โดยแสดงอัตราการกรองสำหรับการตั้งค่าต่ำ (−) และสูง (+) สำหรับแต่ละปัจจัย กราฟแสดงผลกระทบจากการปฏิสัมพันธ์ โดยแสดงอัตราการกรองเฉลี่ยที่ระดับต่างๆ ทั้งสี่แบบที่เป็นไปได้ สำหรับปัจจัยคู่หนึ่งๆ
กราฟแสดงผลกระทบจากการปฏิสัมพันธ์ โดยแสดงอัตราการกรองเฉลี่ยที่ระดับต่างๆ ทั้งสี่แบบที่เป็นไปได้ สำหรับปัจจัยคู่หนึ่งๆ


เส้นที่ไม่ขนานกันในกราฟแสดงปฏิสัมพันธ์ A:C บ่งชี้ว่าผลของปัจจัย A ขึ้นอยู่กับระดับของปัจจัย C ผลลัพธ์ที่คล้ายกันนี้ยังพบได้ในปฏิสัมพันธ์ A:D ด้วย กราฟแสดงให้เห็นว่าปัจจัย B มีผลต่ออัตราการกรองน้อยมาก การวิเคราะห์ความแปรปรวน (ANOVA) ที่รวมทั้ง 4 ปัจจัยและเงื่อนไขปฏิสัมพันธ์ที่เป็นไปได้ทั้งหมดระหว่างปัจจัยเหล่านั้น ให้ค่าสัมประสิทธิ์ประมาณการดังแสดงในตารางด้านล่าง
| สัมประสิทธิ์ | ประมาณการ |
|---|---|
| สกัดกั้น | 70.063 |
| เอ | 10.813 |
| บี | 1.563 |
| ซี | 4.938 |
| ดี | 7.313 |
| เอ:บี | 0.063 |
| เอ:ซี | −9.063 |
| บี:ซี | 1.188 |
| เอ:ดี | 8.313 |
| บี:ดี | −0.188 |
| ซีดี | −0.563 |
| เอ:บี:ซี | 0.938 |
| เอ:บี:ดี | 2.063 |
| เอ:ซี:ดี | −0.813 |
| บี:ซี:ดี | −1.313 |
| เอ:บี:ซี:ดี | 0.688 |

เนื่องจากมีข้อมูลสังเกตการณ์ 16 ชุด และสัมประสิทธิ์ 16 ตัว (ค่าคงที่ ผลกระทบหลัก และปฏิสัมพันธ์) จึง ไม่สามารถคำนวณ ค่า pสำหรับแบบจำลองนี้ได้ ค่าสัมประสิทธิ์และกราฟแสดงให้เห็นว่าปัจจัยสำคัญคือ A, C และ D และพจน์ปฏิสัมพันธ์ A:C และ A:D
ค่าสัมประสิทธิ์ของ A, C และ D ในการวิเคราะห์ ANOVA เป็นค่าบวกทั้งหมด ซึ่งอาจบ่งชี้ว่าควรดำเนินการกระบวนการโดยตั้งค่าตัวแปรทั้งสามให้มีค่าสูง อย่างไรก็ตาม ผลกระทบหลักของแต่ละตัวแปรคือค่าเฉลี่ยของระดับตัวแปรอื่นๆ แผนภาพปฏิสัมพันธ์ A:C ข้างต้นแสดงให้เห็นว่าผลกระทบของปัจจัย A ขึ้นอยู่กับระดับของปัจจัย C และในทางกลับกัน ปัจจัย A (อุณหภูมิ) มีผลกระทบต่ออัตราการกรองน้อยมากเมื่อปัจจัย C อยู่ที่ระดับ + แต่ปัจจัย A มีผลกระทบต่ออัตราการกรองมากเมื่อปัจจัย C (ฟอร์มาลดีไฮด์) อยู่ที่ระดับ − การรวมกันของ A ที่ระดับ + และ C ที่ระดับ − ให้ผลลัพธ์อัตราการกรองสูงสุด ข้อสังเกตนี้แสดงให้เห็นว่าการวิเคราะห์ทีละปัจจัยอาจพลาดปฏิสัมพันธ์ที่สำคัญได้ วิศวกรจะค้นพบว่าผลกระทบของปัจจัย A ขึ้นอยู่กับระดับของปัจจัย C ได้ก็ต่อเมื่อเปลี่ยนแปลงทั้งปัจจัย A และ C พร้อมกันเท่านั้น

อัตราการกรองที่ดีที่สุดจะพบได้เมื่อค่า A และ D อยู่ในระดับสูง และค่า C อยู่ในระดับต่ำ ผลลัพธ์นี้ยังสอดคล้องกับวัตถุประสงค์ในการลดฟอร์มาลดีไฮด์ (ปัจจัย C) เนื่องจากค่า B ดูเหมือนจะไม่สำคัญ จึงสามารถตัดออกจากแบบจำลองได้ การทำ ANOVA โดยใช้ปัจจัย A, C และ D และพจน์ปฏิสัมพันธ์ A:C และ A:D ให้ผลลัพธ์ดังแสดงในตารางต่อไปนี้ ซึ่งทุกพจน์มีความสำคัญทางสถิติ (ค่า p < 0.05)
| สัมประสิทธิ์ | ประมาณการ | ข้อผิดพลาดมาตรฐาน | ค่า t | ค่า p |
|---|---|---|---|---|
| สกัดกั้น | 70.062 | 1.104 | 63.444 | 2.3 × 10 −14 |
| เอ | 10.812 | 1.104 | 9.791 | 1.9 × 10 −6 |
| ซี | 4.938 | 1.104 | 4.471 | 1.2 × 10 −3 |
| ดี | 7.313 | 1.104 | 6.622 | 5.9 × 10 −5 |
| เอ:ซี | −9.063 | 1.104 | −8.206 | 9.4 × 10 −6 |
| เอ:ดี | 8.312 | 1.104 | 7.527 | 2 × 10 −5 |
แนวทางการรายงาน
มีแนวทางการรายงานสำหรับการทดลองแบบสุ่มที่มีปัจจัย เช่น ส่วนขยาย CONSORT 2010 สำหรับการรายงานบทความการทดลองที่มีปัจจัย และส่วนขยาย SPIRIT 2013 สำหรับการรายงานโปรโตคอลการทดลองที่มีปัจจัย[ 22 ] [ 23 ] คำอธิบายโดยละเอียดและตัวอย่างของการรายงานและการดำเนินการที่ดีมีอยู่ในเอกสารอธิบายและขยายความของส่วนขยาย CONSORT และ SPIRIT [ 24 ]
ดูเพิ่มเติม
- การออกแบบเชิงผสมผสาน
- การออกแบบการทดลอง
- อาร์เรย์เชิงตั้งฉาก
- การออกแบบของ Plackett–Burman
- วิธีการของทากุจิ
- การทดสอบทีของเวลช์
เชิงอรรถอธิบาย
- ^การเลือกนี้ทำให้เกิดการจับคู่ 01 ←→ +− ซึ่งตรงข้ามกับที่กำหนดไว้ในตาราง นอกจากนี้ยังมีเหตุผลทางพีชคณิตสำหรับการทำเช่นนี้ [ 10 ]การเลือกการเข้ารหัสผ่าน + และ − ไม่สำคัญ "ตราบใดที่การติดป้ายกำกับมีความสอดคล้องกัน" [ 11 ]
- ^การเลือกใช้ระดับปัจจัยนี้ช่วยให้สามารถใช้พีชคณิตในการจัดการกับปัญหาบางอย่างของการออกแบบการทดลองได้ หาก sเป็นกำลังของจำนวนเฉพาะ ระดับต่างๆ อาจแสดงด้วยองค์ประกอบของฟิลด์จำกัดGF(s)ด้วยเหตุผลเดียวกัน
- ^ความเป็นตั้งฉากกันนั้นพิจารณาได้จากการคำนวณผลคูณดอทของเวกเตอร์
- ^ระดับความเป็นอิสระสำหรับเอฟเฟกต์นั้นแท้จริงแล้วคือมิติของปริภูมิเวกเตอร์กล่าวคือปริภูมิของเวกเตอร์ความแตกต่างทั้งหมดที่อยู่ในเอฟเฟกต์นั้น [ 17 ]
- ^และ 1/2 k-1 ใน การทดลอง2 k ครั้ง
หมายเหตุ
- ^ Yates, Frank ; Mather, Kenneth (1963). "Ronald Aylmer Fisher" . บันทึกชีวประวัติของสมาชิกราชสมาคม . 9 . ลอนดอน ประเทศอังกฤษ: ราชสมาคม : 91– 120. doi : 10.1098/rsbm.1963.0006 .
- ^ ฟิชเชอร์, โรนัลด์ (1926). "การจัดเตรียมการทดลองภาคสนาม" (PDF)วารสารกระทรวงเกษตรแห่งบริเตนใหญ่ 33 ลอนดอนประเทศอังกฤษ: กระทรวงเกษตรและประมง: 503–513
- ^ "การใช้คำศัพท์ทางคณิตศาสตร์บางคำที่เก่าแก่ที่สุดเท่าที่ทราบ (F)" . jeff560.tripod.com .
- ^ a b Montgomery, Douglas C. (2013). การออกแบบและการวิเคราะห์การทดลอง (ฉบับที่ 8). โฮโบเคน รัฐนิวเจอร์ซีย์: ไวลีย์ . ISBN 978-1-119-32093-7.
- ^ Oehlert, Gary (2000). หลักสูตรเบื้องต้นเกี่ยวกับการออกแบบและการวิเคราะห์การทดลอง (ฉบับปรับปรุง). นครนิวยอร์ก: WH Freeman and Company . ISBN 978-0-7167-3510-6.
- ^ Tong, C. (2006). "กลยุทธ์การปรับปรุงสำหรับวิธีการสุ่มตัวอย่างแบบแบ่งชั้น" วิศวกรรมความน่าเชื่อถือและความปลอดภัยของระบบ 91 ( 10– 11 ): 1257– 1265. doi : 10.1016/j.ress.2005.11.027 .
- ^ George EP, Box (2006). การพัฒนาเกือบทุกสิ่งทุกอย่าง: แนวคิดและบทความ (ฉบับปรับปรุง). โฮโบเคน รัฐนิวเจอร์ซีย์: ไวลีย์ . ASIN B01FKSM9VY .
- ^ Hellstrand, C.; Oosterhoorn, AD; Sherwin, DJ; Gerson, M. (24 กุมภาพันธ์ 1989). "ความจำเป็นของการปรับปรุงคุณภาพสมัยใหม่และประสบการณ์บางประการเกี่ยวกับการนำไปใช้ในการผลิตตลับลูกปืน [และการอภิปราย]" วารสารPhilosophical Transactions of the Royal Society . 327 (1596): 529– 537. doi : 10.1098/rsta.1989.0008 . S2CID 122252479 .
- ^คูห์ล (2000 , หน้า 200–205)
- ^เฉิง (2019 , หมายเหตุ 8.1)
- ^ Box, Hunter & Hunter (1978 , หน้า 307)
- ^ Hocking (1985 , หน้า 73) Hocking และคนอื่นๆ ใช้คำว่า "ค่าเฉลี่ยประชากร" แทนค่าที่คาดหวัง
- ^เกรย์บิลล์ (1976 , หน้า 559–560)
- ^เบเดอร์ (2022 , หน้า 29–30)
- ^เบเดอร์ (2022 , ตัวอย่าง 5.21)
- ^โบส (1947 , หน้า 110–111)
- ^เฉิง (2019 , หน้า 77)
- ^คูห์ล (2000 , หน้า 202)
- ^เฉิง (2019 , หน้า 78)
- ^ Box, Hunter & Hunter (2005 , หน้า 180)
- ^ Cohen, J (1968). "การถดถอยหลายตัวแปรเป็นระบบวิเคราะห์ข้อมูลทั่วไป" Psychological Bulletin . 70 (6): 426– 443. CiteSeerX 10.1.1.476.6180 . doi : 10.1037/h0026714 .
- ^ Kahan, Brennan; Hall, Sophie; Beller, Elaine; Birchenall, Megan; Chan, An-Wen; Elbourne, Diana; Little, Paul; Fletcher, John; Golub, Robert; Goulao, Beatriz; Hopewell, Sally; Islam, Nazrul; Zwarenstein, Merrick; Juszczak, Edmund; Alan, Montgomery (5 ธันวาคม 2023). "การรายงานการทดลองแบบสุ่มเชิงแฟคทอเรียล ส่วนขยายของคำแถลง CONSORT 2010" . JAMA . doi : 10.1001/jama.2023.19793 . PMC 7617336 .
- ^ Kahan, Brennan; Hall, Sophie; Beller, Elaine; Birchenall, Megan; Elbourne, Diana; Juszczak, Edmund; Little, Paul; Fletcher, John; Golub, Robert; Goulao, Beatriz; Hopewell, Sally; Islam, Nazrul; Zwarenstein, Merrick; Chan, An-Wen; Montogomery, Alan (5 ธันวาคม 2023). "แถลงการณ์ฉันทามติสำหรับโปรโตคอลของการทดลองแบบสุ่มเชิงแฟคทอเรียล ส่วนขยายของแถลงการณ์ SPIRIT 2013" . JAMA Network . doi : 10.1001/jamanetworkopen.2023.46121 . PMC 7617238 .
- ^ Kahan, Brennan; Edmund, Juszczak; Beller, Elaine; Birchenall, Megan; Chan, An-Wen; Hall, Sophie; Little, Paul; Fletcher, John; Golub, Robert; Goulao, Beatriz; Hopewell, Sally; Islam, Nazrul; Zwarenstein, Merrick; Elbourne, Diana; Montogomery, Alan (4 กุมภาพันธ์ 2025). "คำแนะนำสำหรับเนื้อหาโปรโตคอลและการรายงานการทดลองแบบสุ่มเชิงแฟคเตอร์: คำอธิบายและการขยายความของส่วนขยาย CONSORT 2010 และ SPIRIT 2013" . BMJ . 388 e080785. doi : 10.1136/bmj-2024-080785 . PMC 11791685 .
ลิงก์ภายนอก
- การออกแบบเชิงแฟกทอเรียล (มหาวิทยาลัยรัฐแคลิฟอร์เนีย เฟรสโน)
- GOV.UK การทดลองแบบสุ่มที่มีกลุ่มควบคุม (สาธารณสุขแห่งอังกฤษ)
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การทดลองแฟกทอเรียล
ใน ทางสถิติ การ ทดลองแบบแฟกทอเรียล (หรือที่เรียกว่า การทดลองแบบแฟกทอเรียลเต็ม รูปแบบ ) จะศึกษาว่าปัจจัยหลายอย่างมีอิทธิพลต่อผลลัพธ์ที่เฉพาะเจาะจงอย่างไร ซึ่งเรียกว่า ตัวแปรตอบสนอง...
ประวัติศาสตร์
การออกแบบแฟกทอเรียลถูกนำมาใช้ในศตวรรษที่ 19 โดย John Bennet Lawes และ Joseph Henry Gilbert แห่ง สถานีทดลอง Rothamsted [ 1 ]
ข้อดีและข้อเสียของการทดลองแบบแฟคทอเรียล
หลายคนตรวจสอบผลกระทบของปัจจัยหรือตัวแปรเพียงตัวเดียวเท่านั้น เมื่อเปรียบเทียบกับการทดลองแบบ ปัจจัยเดียวในแต่ละครั้ง (OFAT) การทดลองแบบแฟกทอเรียลมีข้อดีหลายประการ [ 4 ] [ 5 ]
ตัวอย่างข้อดีของการทดลองแบบแฟกทอเรียล
ในหนังสือของเขา Improving Almost Anything: Ideas and Essays นักสถิติ George Box ได้ยกตัวอย่างมากมายเกี่ยวกับประโยชน์ของการทดลองแบบแฟกทอเรียล นี่คือตัวอย่างหนึ่ง [ 7 ] วิศวกรที่บริษัทผลิตตลับลูกปืน SKF ต้องการทราบว่าการเปลี่ยนไปใช้การออกแบบ "กรง"...