อ่าน 6 นาที
การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์
การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์ คือการหา โปรไฟล์ดีเอ็นเอ เพื่อวัตถุประสงค์ทางกฎหมายและการสืบสวน วิธีการวิเคราะห์ดีเอ็นเอได้เปลี่ยนแปลงไปนับครั้งไม่ถ้วนตลอดหลายปีที่ผ่านมา...
การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์

| ส่วนหนึ่งของชุดบทความเกี่ยวกับ |
| นิติวิทยาศาสตร์ |
|---|
 |
|
การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์คือการหาโปรไฟล์ดีเอ็นเอเพื่อวัตถุประสงค์ทางกฎหมายและการสืบสวน วิธีการวิเคราะห์ดีเอ็นเอได้เปลี่ยนแปลงไปนับครั้งไม่ถ้วนตลอดหลายปีที่ผ่านมา เนื่องจากเทคโนโลยีพัฒนาขึ้นและทำให้สามารถหาข้อมูลเพิ่มเติมได้โดยใช้ตัวอย่างเริ่มต้นน้อยลง การวิเคราะห์ดีเอ็นเอสมัยใหม่นั้นอาศัยการคำนวณทางสถิติเกี่ยวกับความหายากของโปรไฟล์ที่ได้ในประชากร
แม้ว่าการตรวจวิเคราะห์ดีเอ็นเอจะเป็นที่รู้จักกันดีในฐานะเครื่องมือในการสืบสวนทางนิติวิทยาศาสตร์ แต่ก็สามารถนำไปใช้ในงานที่ไม่เกี่ยวข้องกับนิติวิทยาศาสตร์ได้เช่นกัน เช่นการตรวจพิสูจน์ความเป็นพ่อและการวิจัยลำดับ วงศ์ตระกูล ของมนุษย์
ประวัติศาสตร์
เจฟฟรีย์ กลาสเบิร์กเป็นคนแรกที่จดสิทธิบัตรวิธีการระบุตัวตนมนุษย์และการทดสอบความเป็นพ่อจากการวิเคราะห์ดีเอ็นเอ[ 1 ]
วิธีการสร้างโปรไฟล์ DNA ได้รับการพัฒนาโดยAlec Jeffreysและทีมงานของเขาในปี 1985 Jeffreys ค้นพบว่าตัวอย่าง DNA ที่ไม่ทราบที่มา เช่น เลือด เส้นผม น้ำลาย หรือน้ำอสุจิ สามารถนำมาวิเคราะห์และสร้างรูปแบบ/โปรไฟล์ DNA เฉพาะได้[ 2 ]หนึ่งปีหลังจากที่เขาค้นพบ Jeffreys ได้รับการขอให้ใช้วิธีการวิเคราะห์ DNA ที่เขาค้นพบใหม่นี้เพื่อเอาผิดชายคนหนึ่งที่ตำรวจเชื่อว่าเป็นผู้รับผิดชอบต่อคดีข่มขืนและฆาตกรรม 2 คดี Jeffreys พิสูจน์ได้ว่าชายคนนั้นบริสุทธิ์โดยใช้ DNA จากที่เกิดเหตุ[ 3 ]
เมื่อมีการค้นพบการวิเคราะห์ DNA ครั้งแรก กระบวนการที่เรียกว่าRestriction Fragment Length Polymorphism (RFLP) ถูกนำมาใช้ในการวิเคราะห์ DNA อย่างไรก็ตาม RFLP เป็นกระบวนการที่ไม่มีประสิทธิภาพ เนื่องจากใช้ DNA ในปริมาณมาก ซึ่งไม่สามารถหาได้จากสถานที่เกิดเหตุเสมอไป เทคโนโลยีในปัจจุบันได้พัฒนาไปไกลกว่า RFLP แล้วการวิเคราะห์ Short Tandem Repeat (STR)เป็นเทคโนโลยีที่ทันสมัยเทียบเท่ากับ RFLP การวิเคราะห์ STR ไม่เพียงแต่ใช้ตัวอย่างในการวิเคราะห์ DNA น้อยลงเท่านั้น แต่ยังเป็นส่วนหนึ่งของกระบวนการที่ใหญ่กว่าที่เรียกว่าPolymerase Chain Reaction (PCR) PCR เป็นกระบวนการที่สามารถใช้ในการสร้างสำเนาของ DNA ส่วนหนึ่งได้มากถึงหนึ่งพันล้านสำเนาอย่างรวดเร็ว[ 4 ]
ค่าใช้จ่าย
การสืบสวนทางพันธุศาสตร์ดีเอ็นเอทางนิติวิทยาศาสตร์มีราคาแพงมาก เนื่องจากต้องทดสอบผู้คนจำนวนมากและสร้างแผนผังลำดับวงศ์ตระกูลขนาดใหญ่[ 5 ]การเข้าถึงฐานข้อมูลผู้บริโภคของผู้ที่ทำการทดสอบดีเอ็นเอเพื่อความสนุกสนานก็ไม่ใช่เรื่องถูกเช่นกัน[ 5 ]ตำรวจดัตช์ได้ทำการวิเคราะห์ดีเอ็นเอจำนวนมากในคดีจำนวนหนึ่ง[ 6 ]
วิธีการ
วิธีการที่เลิกใช้แล้ว
การวิเคราะห์ RFLP

วิธีการสร้างโปรไฟล์ DNA ที่แท้จริงวิธีแรกคือการวิเคราะห์ความยาวของชิ้นส่วนจำกัด (RFLP) การใช้การวิเคราะห์ RFLP ครั้งแรกในงานนิติเวชเกิดขึ้นในปี 1985 ในสหราชอาณาจักร[ 7 ]การวิเคราะห์ประเภทนี้ใช้ลำดับซ้ำแบบเรียงต่อกันที่มีจำนวนแปรผัน (VNTRs) เพื่อแยกแยะความแตกต่างระหว่างบุคคล VNTRs พบได้ทั่วไปทั่วทั้งจีโนมและประกอบด้วยลำดับ DNA เดียวกันที่ซ้ำกันไปเรื่อยๆ[ 8 ]บุคคลที่แตกต่างกันอาจมีจำนวนการทำซ้ำที่แตกต่างกันในตำแหน่งเฉพาะในจีโนม[ 7 ]ตัวอย่างเช่น บุคคล A อาจมี 4 ครั้ง ในขณะที่บุคคล B อาจมี 5 ครั้ง ความแตกต่างเหล่านี้สามารถมองเห็นได้ผ่านกระบวนการที่เรียกว่าเจลอิเล็กโทรโฟเรซิสชิ้นส่วนขนาดเล็กจะเคลื่อนที่ผ่านเจลได้ไกลกว่าชิ้นส่วนขนาดใหญ่ ทำให้แยกออกจากกัน[ 9 ]ความแตกต่างเหล่านี้ถูกนำมาใช้เพื่อแยกแยะความแตกต่างระหว่างบุคคล และเมื่อมีการรันไซต์ VNTR หลายไซต์พร้อมกัน การวิเคราะห์ RFLP จะมีประสิทธิภาพในการแยกแยะบุคคลได้สูง[ 10 ]
กระบวนการวิเคราะห์ RFLP ใช้เวลานานมาก และเนื่องจากความยาวของการทำซ้ำที่ใช้ ซึ่งอยู่ระหว่าง 9 ถึง 100 คู่เบส[ 8 ] [ 11 ] จึงไม่สามารถใช้ วิธีการขยายสัญญาณ เช่นปฏิกิริยาลูกโซ่พอลิเมอเรสได้ ข้อจำกัดนี้ทำให้ RFLP ใช้ได้เฉพาะกับตัวอย่างที่มีปริมาณ DNA มากอยู่แล้ว และไม่สามารถทำงานได้ดีกับตัวอย่างที่เสื่อมสภาพ[ 12 ] การวิเคราะห์ RFLP เป็นวิธีการวิเคราะห์หลักที่ใช้ในห้องปฏิบัติการนิติวิทยาศาสตร์ส่วนใหญ่ ก่อนที่จะถูกยกเลิกและแทนที่ด้วยวิธีการใหม่กว่า ในที่สุด FBIก็ได้ยกเลิกอย่างสมบูรณ์ในปี 2000 และแทนที่ด้วยการวิเคราะห์ STR [ 13 ]
การทดสอบอัลฟ่า DQ

การทดสอบ DQ alpha ซึ่งพัฒนาขึ้นในปี 1991 [ 13 ]เป็นเทคนิคดีเอ็นเอทางนิติวิทยาศาสตร์แรกที่ใช้ปฏิกิริยาลูกโซ่พอลิเมอเรส[ 14 ]เทคนิคนี้ทำให้สามารถใช้เซลล์น้อยกว่าการวิเคราะห์ RFLP มาก ทำให้มีประโยชน์มากขึ้นสำหรับสถานที่เกิดเหตุอาชญากรรมที่ไม่มีวัสดุดีเอ็นเอจำนวนมากอย่างที่เคยเป็นมาก่อน[ 15 ]ตำแหน่ง (หรือโลคัส) DQ alpha 1 ยังมีความหลากหลายทางพันธุกรรมและมีอัลลีล ที่แตกต่างกันหลายแบบ ที่สามารถใช้เพื่อจำกัดกลุ่มบุคคลที่อาจทำให้เกิดผลลัพธ์นั้นและเพิ่มโอกาสในการตัดออก[ 16 ]
ตำแหน่งอัลฟา DQ ถูกรวมเข้ากับตำแหน่งอื่นๆ ในชุดอุปกรณ์เชิงพาณิชย์ที่เรียกว่า Polymarker ในปี 1993 [ 17 ] Polymarker เป็นต้นแบบของ ชุดอุปกรณ์ มัลติเพล็กซ์ สมัยใหม่ และอนุญาตให้ตรวจสอบตำแหน่งต่างๆ ได้หลายตำแหน่งด้วยผลิตภัณฑ์เดียว แม้ว่าจะมีความไวมากกว่าการวิเคราะห์ RFLP แต่ Polymarker ก็ไม่มีพลังในการจำแนกที่เท่าเทียมกับการทดสอบ RFLP แบบเก่า[ 17 ]ในปี 1995 นักวิทยาศาสตร์พยายามกลับไปใช้การวิเคราะห์แบบ VNTR ร่วมกับเทคโนโลยี PCR ที่เรียกว่าโพลีมอร์ฟิซึมความยาวชิ้นส่วนที่ขยาย (AmpFLP) [ 13 ]
แอมป์เอฟแอลพี

AmpFLP เป็นความพยายามครั้งแรกในการรวมการวิเคราะห์ VNTR กับ PCR สำหรับงานนิติเวช วิธีนี้ใช้ VNTR ที่สั้นกว่าการวิเคราะห์ RFLP ซึ่งอยู่ระหว่าง 8 ถึง 16 คู่เบส ขนาดคู่เบสที่สั้นกว่าของ AmpFLP ถูกออกแบบมาเพื่อให้ทำงานได้ดีขึ้นกับกระบวนการขยายของ PCR [ 11 ]มีความหวังว่าเทคนิคนี้จะช่วยให้การวิเคราะห์ RFLP มีประสิทธิภาพในการจำแนกแยกแยะได้ดียิ่งขึ้น พร้อมทั้งสามารถประมวลผลตัวอย่างที่มี DNA แม่แบบน้อยกว่า หรือตัวอย่างที่เสื่อมสภาพไปแล้ว อย่างไรก็ตาม มีเพียงไม่กี่ตำแหน่งเท่านั้นที่ได้รับการตรวจสอบเพื่อนำไปใช้ในงานนิติเวชโดยใช้การวิเคราะห์ AmpFLP เนื่องจากห้องปฏิบัติการนิติเวชได้เปลี่ยนไปใช้เทคนิคอื่นอย่างรวดเร็ว ทำให้ความสามารถในการจำแนกแยกแยะตัวอย่างทางนิติเวชมีข้อจำกัด[ 18 ]
เทคนิคนี้ในที่สุดก็ไม่เคยถูกนำมาใช้อย่างแพร่หลาย แม้ว่าจะยังคงใช้กันอยู่บ้างในประเทศขนาดเล็ก เนื่องจากมีต้นทุนต่ำกว่าและมีการตั้งค่าที่ง่ายกว่าเมื่อเทียบกับวิธีการใหม่ๆ[ 19 ] [ 20 ]ในช่วงปลายทศวรรษ 1990 ห้องปฏิบัติการต่างๆ เริ่มเปลี่ยนไปใช้วิธีการใหม่ๆ รวมถึงการวิเคราะห์ STR ซึ่งใช้ชิ้นส่วน DNA ที่สั้นกว่า และสามารถขยายได้อย่างน่าเชื่อถือมากขึ้นโดยใช้ PCR ในขณะที่ยังคงรักษาและปรับปรุงประสิทธิภาพในการจำแนกของวิธีการแบบเก่า[ 13 ]
วิธีการปัจจุบัน
การวิเคราะห์ STR

การวิเคราะห์ลำดับซ้ำสั้น (STR) เป็นวิธีการวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์หลักที่ใช้ในห้องปฏิบัติการดีเอ็นเอสมัยใหม่ การวิเคราะห์ STR พัฒนาต่อยอดจาก RFLP และ AmpFLP ที่ใช้ในอดีต โดยลดขนาดของหน่วยซ้ำให้เหลือ 2 ถึง 6 คู่เบส และรวมตำแหน่งทางพันธุกรรมที่แตกต่างกันหลายตำแหน่งเข้าไว้ในปฏิกิริยา PCR เดียว ชุดตรวจวิเคราะห์แบบมัลติเพล็กซ์เหล่านี้สามารถสร้างค่าอัลลีลสำหรับตำแหน่งทางพันธุกรรมที่แตกต่างกันหลายสิบตำแหน่งทั่วทั้งจีโนมพร้อมกัน ซึ่งช่วยลดเวลาที่ใช้ในการสร้างโปรไฟล์เฉพาะบุคคลได้อย่างสมบูรณ์ การวิเคราะห์ STR ได้กลายเป็นมาตรฐานทองคำสำหรับการสร้างโปรไฟล์ดีเอ็นเอและถูกนำมาใช้อย่างกว้างขวางในงานนิติวิทยาศาสตร์
การวิเคราะห์ STR สามารถจำกัดเฉพาะโครโมโซม Yได้ เช่นกัน การวิเคราะห์ Y-STRสามารถใช้ในกรณีที่เกี่ยวข้องกับความเป็นพ่อ หรือในการค้นหาญาติเนื่องจากโครโมโซม Y เหมือนกันในสายพ่อ (ยกเว้นในกรณีที่ เกิด การกลายพันธุ์ ) ชุดตรวจแบบมัลติเพล็กซ์บางชนิดรวมทั้งตำแหน่ง STR ของโครโมโซมร่างกายและ Y ไว้ในชุดเดียว ซึ่งช่วยลดเวลาในการได้ข้อมูลจำนวนมาก
ปัจจุบัน การวิเคราะห์ STR ต้องใช้เซลล์หลายเซลล์เพื่อสร้างโปรไฟล์ DNA ที่สมบูรณ์ อย่างไรก็ตาม วิทยาศาสตร์กำลังเข้าใกล้การสร้างโปรไฟล์ DNA ที่สมบูรณ์โดยใช้การวิเคราะห์ STR บนเซลล์เดียวมากขึ้น[ 21 ]
การจัดลำดับดีเอ็นเอไมโทคอนเดรีย
การลำดับดีเอ็นเอไมโทคอน เด รียเป็นเทคนิคเฉพาะทางที่ใช้ดีเอ็นเอไมโทคอนเดรียที่แยกตัวออกมาซึ่งมีอยู่ในเซลล์ส่วนใหญ่ ดีเอ็นเอชนิดนี้ถูกส่งต่อจากทางมารดาและไม่ได้มีลักษณะเฉพาะตัวระหว่างบุคคล อย่างไรก็ตาม เนื่องจากมีไมโทคอนเดรียจำนวนมากในเซลล์ การวิเคราะห์ดีเอ็นเอไมโทคอนเดรียจึงสามารถใช้ได้กับตัวอย่างที่เสื่อมสภาพอย่างมากหรือตัวอย่างที่การวิเคราะห์ STR ไม่ให้ข้อมูลที่เพียงพอต่อการนำไปใช้ประโยชน์ได้ นอกจากนี้ ดีเอ็นเอไมโทคอนเดรียยังพบได้ในบริเวณที่ไม่มีดีเอ็นเอออโตโซม เช่น ในเส้นผม
เนื่องจากมีความเสี่ยงสูงต่อการปนเปื้อนเมื่อต้องจัดการกับ mtDNA จึงมีห้องปฏิบัติการเพียงไม่กี่แห่งที่ทำการวิเคราะห์ตัวอย่างไมโทคอนเดรีย และห้องปฏิบัติการเหล่านั้นก็มีระเบียบปฏิบัติเฉพาะที่แยกตัวอย่างต่าง ๆ ออกจากกันเพื่อหลีกเลี่ยงการปนเปื้อนข้าม
ดีเอ็นเอเร็ว
Rapid DNA คือเทคโนโลยี "เก็บตัวอย่างดีเอ็นเอเพียงชิ้นเดียว ได้ผลลัพธ์ทันที" ที่ทำให้กระบวนการสกัด ขยาย และวิเคราะห์ดีเอ็นเอทั้งหมดเป็นไปโดยอัตโนมัติอย่างสมบูรณ์ เครื่องมือ Rapid DNA สามารถประมวลผลจากตัวอย่างดีเอ็นเอเพียงชิ้นเดียวไปจนถึงได้ผลลัพธ์เป็นโปรไฟล์ดีเอ็นเอได้ภายในเวลาเพียง 90 นาที และไม่จำเป็นต้องใช้ผู้เชี่ยวชาญทางวิทยาศาสตร์ในการดำเนินการ เครื่องมือเหล่านี้กำลังอยู่ระหว่างการพิจารณาเพื่อใช้ในกระบวนการบันทึกข้อมูลผู้กระทำผิด เพื่อให้เจ้าหน้าที่ตำรวจสามารถได้รับโปรไฟล์ดีเอ็นเอของผู้ถูกจับกุมได้
การจัดลำดับแบบขนานขนาดใหญ่
การจัดลำดับดีเอ็นเอแบบขนานขนาดใหญ่ (Massively Parallel Sequencing หรือ MPS) หรือที่รู้จักกันในชื่อการจัดลำดับรุ่นใหม่ (Next-Generation Sequencing) พัฒนาต่อยอดจากการวิเคราะห์ STR โดยการนำวิธีการจัดลำดับโดยตรงของตำแหน่งดีเอ็นเอมาใช้ แทนที่จะนับจำนวนการซ้ำกันในแต่ละตำแหน่ง MPS จะให้ข้อมูลลำดับเบสคู่ที่แท้จริงแก่ผู้ทำการวิจัย ในทางทฤษฎีแล้ว MPS มีความสามารถในการแยกแยะความแตกต่างระหว่างฝาแฝดเหมือนกันได้ เนื่องจากจุดกลายพันธุ์แบบสุ่มจะปรากฏให้เห็นในส่วนของการซ้ำกัน ซึ่งการวิเคราะห์ STR แบบดั้งเดิมจะตรวจไม่พบ
ความหายากของโปรไฟล์
เมื่อมีการใช้ข้อมูลดีเอ็นเอในลักษณะที่เป็นหลักฐาน จะมีการระบุสถิติการจับคู่ที่อธิบายถึงความหายากของโปรไฟล์ดีเอ็นเอในประชากร โดยเฉพาะอย่างยิ่ง สถิตินี้คือความน่าจะเป็นที่บุคคลที่สุ่มเลือกจากประชากรจะมีโปรไฟล์ดีเอ็นเอเฉพาะนั้น ไม่ใช่ความน่าจะเป็นที่โปรไฟล์นั้น"ตรงกัน" กับใครบางคนมีวิธีการต่างๆ มากมายในการคำนวณสถิตินี้ และแต่ละวิธีก็ถูกใช้โดยห้องปฏิบัติการต่างๆ ตามประสบการณ์และความชอบของตน อย่างไรก็ตาม การคำนวณอัตราส่วนความน่าจะเป็นกำลังกลายเป็นวิธีการที่นิยมมากกว่าสองวิธีที่ใช้กันทั่วไป คือ การสุ่มเลือกบุคคลที่ไม่ถูกตัดออก และความน่าจะเป็นรวมของการรวม สถิติการจับคู่มีความสำคัญอย่างยิ่งในการตีความข้อมูลดีเอ็นเอแบบผสมที่มีผู้มีส่วนร่วมมากกว่าหนึ่งคน เมื่อมีการให้สถิติเหล่านี้ในศาลหรือในรายงานของห้องปฏิบัติการ มักจะให้สำหรับสามเชื้อชาติที่พบมากที่สุดในพื้นที่นั้นๆ เนื่องจากความถี่ของอัลลีลในตำแหน่งต่างๆ เปลี่ยนแปลงไปตามบรรพบุรุษของแต่ละบุคคลhttps://strbase.nist.gov/training/6_Mixture-Statistics.pdf เก็บถาวรเมื่อ 2022-08-15 ที่Wayback Machine
ชายสุ่มสี่สุ่มห้าไม่ถูกตัดออก
ความน่าจะเป็นที่ได้จากวิธีนี้คือความน่าจะเป็นที่บุคคลที่สุ่มเลือกมาจากประชากรจะไม่สามารถถูกตัดออกจากการวิเคราะห์ข้อมูลได้ สถิติการจับคู่ประเภทนี้อธิบายได้ง่ายในศาลสำหรับบุคคลที่ไม่มีพื้นฐานทางวิทยาศาสตร์ แต่ก็สูญเสียพลังในการจำแนกไปมากเนื่องจากไม่ได้คำนึงถึงจีโนไทป์ของผู้ต้องสงสัย วิธีนี้มักใช้เมื่อตัวอย่างเสื่อมสภาพหรือมีผู้ร่วมให้ข้อมูลจำนวนมากจนไม่สามารถระบุโปรไฟล์เดียวได้ นอกจากนี้ยังเป็นประโยชน์ในการอธิบายให้บุคคลทั่วไปเข้าใจได้ง่าย เนื่องจากวิธีการได้มาซึ่งสถิตินั้นตรงไปตรงมา อย่างไรก็ตาม เนื่องจากพลังในการจำแนกที่จำกัด RMNE จึงมักไม่ถูกนำมาใช้เว้นแต่จะไม่มีวิธีการอื่นใดที่สามารถใช้ได้ RMNE ไม่แนะนำให้ใช้กับข้อมูลที่บ่งชี้ว่ามีส่วนผสมอยู่
ความน่าจะเป็นรวมของการรวม/การไม่รวม
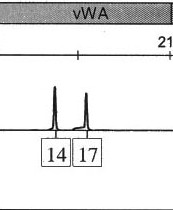

ความน่าจะเป็นรวมของการรวมหรือการแยกออก (Combined Probability of Inclusion or Exclusion: CPI หรือ CPE) คำนวณความน่าจะเป็นที่บุคคลสุ่มที่ไม่เกี่ยวข้องจะเป็นผู้มีส่วนร่วมในโปรไฟล์ DNA หรือส่วนผสมของ DNA ในวิธีนี้ สถิติสำหรับแต่ละตำแหน่ง (locus) จะถูกกำหนดโดยใช้สถิติประชากร แล้วนำมารวมกันเพื่อให้ได้ค่า CPI หรือ CPE รวม การคำนวณเหล่านี้จะทำซ้ำสำหรับตำแหน่งทั้งหมดที่มีอยู่ด้วยข้อมูลทั้งหมดที่มีอยู่ จากนั้นแต่ละค่าจะถูกคูณเข้าด้วยกันเพื่อให้ได้ความน่าจะเป็นรวมของการรวมหรือการแยกออกทั้งหมด เนื่องจากค่าต่างๆ ถูกคูณเข้าด้วยกัน จึงสามารถได้ตัวเลขที่เล็กมากโดยใช้ CPI CPI หรือ CPE ถือเป็นการคำนวณทางสถิติที่ยอมรับได้เมื่อมีการระบุว่ามีส่วนผสมhttps://www.promega.com/-/media/files/resources/conference-proceedings/ishi-15/parentage-and-mixture-statistics-workshop/generalpopulationstats.pdf?la=en
ตัวอย่างการคำนวณสำหรับโปรไฟล์แหล่งกำเนิดเดียว
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีลที่ 14 ที่vWA = 0.10204
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีล 17 ที่vWA = 0.26276
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีล 14 หรือ 17 (P) = 0.10204 + 0.26276 = 0.3648
ความน่าจะเป็นที่อัลลีลอื่นๆ จะปรากฏอยู่(Q) = 1 - Pหรือ1 - 0.3648 = 0.6352
ความน่าจะเป็นของการยกเว้นสำหรับvWA = Q 2 + 2Q(1-Q)หรือ.6352 2 + 2(.6352)(1 - .6352) = .86692096 ≈ 86.69%
ความน่าจะเป็นของการถูกรวมเข้าในvWA = 1 - CPEหรือ1 - 0.86692096 = 0.13307904 ≈ 13.31%
ตัวอย่างการคำนวณโปรไฟล์ส่วนผสม
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีลที่ 14 ที่vWA = 0.10204
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีล 15 ที่vWA = 0.11224
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีลที่ 16 ที่vWA = 0.20153
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีล 19 ที่vWA = 0.08418
ความน่าจะเป็นที่ชาวคอเคเชียนจะมีอัลลีลใดๆ ใน 14, 15, 16 หรือ 19 (P) = .10204 + .11224 + .20153 + .08418 = .49999
ความน่าจะเป็นที่อัลลีลอื่นๆ จะปรากฏอยู่(Q) = 1 - Pหรือ1 - 0.49999 = 0.50001
ความน่าจะเป็นของการยกเว้นสำหรับvWA = Q 2 + 2Q(1-Q)หรือ.50001 2 + 2(.50001)(1 - .50001) = .7500099999 ≈ 75%
ความน่าจะเป็นของการถูกรวมเข้าในvWA = 1 - CPEหรือ1 - 0.7500099999 = 0.2499900001 ≈ 25%
อัตราส่วนความน่าจะเป็น
อัตราส่วนความน่าจะเป็น (LR) คือการเปรียบเทียบความน่าจะเป็นสองค่าที่แตกต่างกัน เพื่อพิจารณาว่าค่าใดมีโอกาสเกิดขึ้นมากกว่า เมื่อเกี่ยวข้องกับการพิจารณาคดี LR คือความน่าจะเป็นของข้อโต้แย้งของฝ่ายโจทก์เทียบกับความน่าจะเป็นของข้อโต้แย้งของฝ่ายจำเลย โดยพิจารณาจากสมมติฐานเริ่มต้นของแต่ละฝ่าย ในสถานการณ์นี้ ความน่าจะเป็นของฝ่ายโจทก์มักจะเท่ากับ 1 เนื่องจากสมมติฐานคือ ฝ่ายโจทก์จะไม่ดำเนินคดีกับผู้ต้องสงสัยเว้นแต่จะแน่ใจอย่างแน่นอน (100%) ว่าได้ตัวคนร้ายที่ถูกต้องแล้ว อัตราส่วนความน่าจะเป็นกำลังเป็นที่นิยมมากขึ้นในห้องปฏิบัติการ เนื่องจากมีประโยชน์ในการนำเสนอสถิติสำหรับข้อมูลที่บ่งชี้ถึงผู้มีส่วนร่วมหลายคน รวมถึงการใช้ในซอฟต์แวร์การระบุจีโนไทป์เชิงความน่า จะเป็นที่ ทำนายการรวมกันของอัลลีลที่น่าจะเป็นไปได้มากที่สุดจากชุดข้อมูลที่กำหนด
ข้อเสียของการใช้ค่าอัตราส่วนความน่าจะเป็นคือ การทำความเข้าใจว่านักวิเคราะห์คำนวณค่าดังกล่าวได้อย่างไรนั้นเป็นเรื่องยากมาก และคณิตศาสตร์ที่เกี่ยวข้องจะซับซ้อนมากขึ้นเมื่อมีข้อมูลมากขึ้นในสมการ เพื่อแก้ไขปัญหาเหล่านี้ในศาล ห้องปฏิบัติการบางแห่งจึงได้จัดทำ "มาตราส่วนเชิงคำพูด" ขึ้นมาแทนที่ค่าตัวเลขจริงของอัตราส่วนความน่าจะเป็น
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์
การวิเคราะห์ดีเอ็นเอทางนิติวิทยาศาสตร์ คือการหา โปรไฟล์ดีเอ็นเอ เพื่อวัตถุประสงค์ทางกฎหมายและการสืบสวน วิธีการวิเคราะห์ดีเอ็นเอได้เปลี่ยนแปลงไปนับครั้งไม่ถ้วนตลอดหลายปีที่ผ่านมา...
ประวัติศาสตร์
เจฟฟรีย์ กลาสเบิร์ก เป็นคนแรกที่จดสิทธิบัตรวิธีการระบุตัวตนมนุษย์และการทดสอบความเป็นพ่อจากการวิเคราะห์ดีเอ็นเอ [ 1 ]
ค่าใช้จ่าย
การสืบสวนทางพันธุศาสตร์ดีเอ็นเอทางนิติวิทยาศาสตร์มีราคาแพงมาก เนื่องจากต้องทดสอบผู้คนจำนวนมากและสร้างแผนผังลำดับวงศ์ตระกูลขนาดใหญ่ [ 5 ] การเข้าถึงฐานข้อมูลผู้บริโภคของผู้ที่ทำการทดสอบดีเอ็นเอเพื่อความสนุกสนานก็ไม่ใช่เรื่องถูกเช่นกัน [ 5 ]...
วิธีการที่เลิกใช้แล้ว
วิธีการสร้างโปรไฟล์ DNA ที่แท้จริงวิธีแรกคือการวิเคราะห์ความยาวของชิ้นส่วนจำกัด (RFLP) การใช้การวิเคราะห์ RFLP ครั้งแรกในงานนิติเวชเกิดขึ้นในปี 1985 ในสหราชอาณาจักร [ 7 ] การวิเคราะห์ประเภทนี้ใช้ ลำดับซ้ำแบบเรียงต่อกันที่มีจำนวนแปรผัน (VNTRs)...