อ่าน 6 นาที
การปรับตัวแบบเกาส์เซียน
การปรับตัวแบบเกาส์เซียน (Gaussian adaptation หรือ GA)หรือที่เรียกว่า การปรับตัว แบบปกติหรือแบบธรรมชาติ (Normal or Natural adaptation หรือ
การปรับตัวแบบเกาส์เซียน
| ส่วนหนึ่งของชุดบทความเกี่ยวกับ |
| อัลกอริทึมวิวัฒนาการ |
|---|
 |
| อัลกอริทึมทางพันธุกรรม (GA) |
| การเขียนโปรแกรมเชิงพันธุกรรม (GP) |
| วิวัฒนาการเชิงอนุพันธ์ |
| กลยุทธ์วิวัฒนาการ |
| การเขียนโปรแกรมเชิงวิวัฒนาการ |
| หัวข้อที่เกี่ยวข้อง |
การปรับตัวแบบเกาส์เซียน (Gaussian adaptation หรือ GA)หรือที่เรียกว่า การปรับตัว แบบปกติหรือแบบธรรมชาติ (Normal or Natural adaptation หรือ NA)เป็นอัลกอริธึมเชิงวิวัฒนาการที่ออกแบบมาเพื่อเพิ่มผลผลิตในการผลิตให้สูงสุดเนื่องจากความเบี่ยงเบนทางสถิติของค่าส่วนประกอบของ ระบบ ประมวลผลสัญญาณกล่าวโดยย่อ GA เป็นกระบวนการปรับตัวแบบสุ่ม โดยที่ตัวอย่างจำนวนหนึ่งของ เวกเตอร์ nมิติx [ x T = ( x 1 , x 2 , ..., x n )] ถูกนำมาจากการแจกแจงแบบเกาส์เซียนหลายตัวแปร N ( m , M )ซึ่งมีค่าเฉลี่ยmและเมทริกซ์โมเมนต์Mตัวอย่างเหล่านี้จะถูกทดสอบว่าผ่านหรือไม่ผ่าน โมเมนต์อันดับที่หนึ่งและอันดับที่สองของเกาส์เซียนที่จำกัดเฉพาะตัวอย่างที่ผ่านคือm*และ M *
ผลลัพธ์ของการเลือกxเป็นตัวอย่างที่ผ่านเกณฑ์นั้นถูกกำหนดโดยฟังก์ชันs ( x ) โดยที่ 0 < s ( x ) < q ≤ 1 ซึ่งs ( x ) คือความน่าจะเป็นที่ x จะถูกเลือกเป็นตัวอย่างที่ผ่านเกณฑ์ ความน่าจะเป็นเฉลี่ยของการพบตัวอย่างที่ผ่านเกณฑ์ (ผลผลิต) คือ

ดังนั้นทฤษฎีบทของ GA จึงกล่าวไว้ว่า:
สำหรับs ( x ) ใดๆ และสำหรับค่าP < q ใดๆ จะมีฟังก์ชันความหนาแน่นความน่าจะ เป็นแบบเกาส์เซียน (Gaussian pdf ) ที่เหมาะสมที่สุดสำหรับการกระจายสูงสุดเสมอ เงื่อนไขที่จำเป็นสำหรับจุดเหมาะสมที่สุดเฉพาะที่คือm = m * และMเป็นสัดส่วนกับM * ปัญหาคู่ขนานก็ได้รับการแก้ไขเช่นกัน: Pมีค่าสูงสุดในขณะที่รักษาการกระจายให้คงที่ (Kjellström, 1991)
สามารถค้นหาบทพิสูจน์ของทฤษฎีบทได้ในบทความของ Kjellström ปี 1970 และ Kjellström & Taxén ปี 1981
เนื่องจากการกระจายตัวถูกนิยามว่าเป็นเลขชี้กำลังของเอนโทรปี/ความไม่เป็นระเบียบ/ ข้อมูลเฉลี่ยดังนั้นจึงสรุปได้ทันทีว่าทฤษฎีบทนี้ใช้ได้กับแนวคิดเหล่านั้นด้วยเช่นกัน โดยรวมแล้ว นี่หมายความว่าการปรับตัวแบบเกาส์เซียนสามารถดำเนินการเพิ่มผลผลิตและข้อมูลเฉลี่ย ให้สูงสุดพร้อมกันได้ (โดยไม่จำเป็นต้องกำหนดผลผลิตหรือข้อมูลเฉลี่ยเป็นฟังก์ชันเกณฑ์)
ทฤษฎีบทนี้ใช้ได้กับทุกขอบเขตที่ยอมรับได้และทุกการแจกแจงแบบเกาส์เซียนสามารถใช้ได้โดยการทำซ้ำแบบวัฏจักรของการเปลี่ยนแปลงแบบสุ่มและการเลือก (เช่นเดียวกับวิวัฒนาการตามธรรมชาติ) ในแต่ละรอบ จะมีการสุ่มตัวอย่างจุดที่แจกแจงแบบเกาส์เซียนจำนวนมากพอสมควร และทดสอบว่าอยู่ในขอบเขตที่ยอมรับได้หรือไม่ จากนั้นจุดศูนย์กลางมวลของการแจกแจงแบบเกาส์เซียนmจะถูกย้ายไปยังจุดศูนย์กลางมวลของจุดที่ได้รับการอนุมัติ (เลือก) m * ดังนั้น กระบวนการจะลู่เข้าสู่สภาวะสมดุลที่สอดคล้องกับทฤษฎีบท คำตอบที่ได้จะเป็นเพียงค่าประมาณเสมอ เนื่องจากจุดศูนย์กลางมวลจะถูกกำหนดสำหรับจุดจำนวนจำกัดเท่านั้น
อัลกอริธึมนี้ถูกนำมาใช้ครั้งแรกในปี 1969 ในฐานะอัลกอริธึมการปรับให้เหมาะสมอย่างแท้จริง โดยทำให้ขอบเขตที่ยอมรับได้เล็กลงเรื่อยๆ (ในลักษณะเดียวกับการจำลองการอบอ่อน Kirkpatrick 1983) ตั้งแต่ปี 1970 เป็นต้นมา อัลกอริธึมนี้ถูกนำมาใช้ทั้งเพื่อการปรับให้เหมาะสมทั่วไปและการเพิ่มผลผลิตสูงสุด
วิวัฒนาการตามธรรมชาติและการปรับตัวแบบเกาส์เซียน
นอกจากนี้ยังมีการเปรียบเทียบกับวิวัฒนาการตามธรรมชาติของประชากรสิ่งมีชีวิต ในกรณีนี้s ( x ) คือความน่าจะเป็นที่แต่ละตัวที่มี ฟีโนไทป์ xจะอยู่รอดโดยการให้กำเนิดลูกหลานในรุ่นต่อไป ซึ่งเป็นนิยามของความเหมาะสมของแต่ละบุคคลที่กำหนดโดย Hartl ในปี 1981 ผลผลิตPจะถูกแทนที่ด้วยความเหมาะสมเฉลี่ยที่กำหนดเป็นค่าเฉลี่ยของกลุ่มตัวอย่างในประชากรขนาดใหญ่
ลักษณะทางฟีโนไทป์มักมีการกระจายแบบเกาส์เซียนในประชากรขนาดใหญ่ และเงื่อนไขที่จำเป็นสำหรับการวิวัฒนาการตามธรรมชาติที่จะสามารถปฏิบัติตามทฤษฎีการปรับตัวแบบเกาส์เซียนได้ โดยพิจารณาจากลักษณะเชิงปริมาณแบบเกาส์เซียนทั้งหมด คือ การที่วิวัฒนาการนั้นสามารถผลักดันจุดศูนย์กลางมวลของการกระจายแบบเกาส์เซียนไปยังจุดศูนย์กลางมวลของแต่ละบุคคลที่ถูกคัดเลือกได้ ซึ่งสามารถทำได้โดยกฎของฮาร์ดี-ไวน์เบิร์กเป็นไปได้เพราะทฤษฎีการปรับตัวแบบเกาส์เซียนนั้นใช้ได้กับทุกขอบเขตที่ยอมรับได้โดยไม่ขึ้นอยู่กับโครงสร้าง (Kjellström, 1996)
ในกรณีนี้ กฎของการแปรผันทางพันธุกรรม เช่น ครอสโอเวอร์ การผกผัน การสลับตำแหน่ง ฯลฯ อาจถูกมองว่าเป็นตัวสร้างเลขสุ่มสำหรับลักษณะภายนอก ดังนั้น ในแง่นี้ การปรับตัวแบบเกาส์เซียนอาจถูกมองว่าเป็นอัลกอริธึมทางพันธุกรรม
วิธีการปีนเขา
สามารถคำนวณค่าความเหมาะสมเฉลี่ยได้หากทราบการกระจายตัวของพารามิเตอร์และโครงสร้างของภูมิทัศน์ ภูมิทัศน์จริงนั้นไม่เป็นที่รู้จัก แต่ภาพด้านล่างแสดงโปรไฟล์สมมติ (สีน้ำเงิน) ของภูมิทัศน์ตามแนวเส้น (x) ในห้องที่ครอบคลุมโดยพารามิเตอร์ดังกล่าว เส้นโค้งสีแดงคือค่าเฉลี่ยโดยอิงจากเส้นโค้งระฆังสีแดงที่ด้านล่างของภาพ ได้มาจากการปล่อยให้เส้นโค้งระฆังเลื่อนไปตาม แกน xและคำนวณค่าเฉลี่ยในแต่ละตำแหน่ง ดังที่เห็นได้ว่า ยอดและหลุมเล็กๆ ถูกทำให้เรียบ ดังนั้น หากวิวัฒนาการเริ่มต้นที่ A ด้วยความแปรปรวนที่ค่อนข้างน้อย (เส้นโค้งระฆังสีแดง) การไต่ระดับจะเกิดขึ้นบนเส้นโค้งสีแดง กระบวนการอาจติดอยู่ที่ B หรือ C เป็นเวลาหลายล้านปี ตราบใดที่ยังมีหลุมทางด้านขวาของจุดเหล่านี้อยู่ และอัตราการกลายพันธุ์น้อยเกินไป
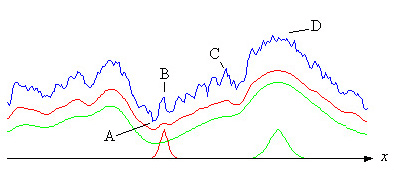
หากอัตราการกลายพันธุ์สูงเพียงพอ ความไม่เป็นระเบียบหรือความแปรปรวนอาจเพิ่มขึ้น และพารามิเตอร์อาจกระจายตัวเหมือนเส้นโค้งระฆังสีเขียว จากนั้นการไต่ระดับจะเกิดขึ้นบนเส้นโค้งสีเขียวซึ่งเรียบเนียนยิ่งขึ้น เนื่องจากช่องว่างทางด้านขวาของ B และ C หายไปแล้ว กระบวนการอาจดำเนินต่อไปจนถึงจุดสูงสุดที่ D แต่แน่นอนว่าภูมิทัศน์จะจำกัดความไม่เป็นระเบียบหรือความแปรปรวน นอกจากนี้ ขึ้นอยู่กับภูมิทัศน์ กระบวนการอาจกระตุกมาก และหากอัตราส่วนระหว่างเวลาที่กระบวนการใช้ไปที่จุดสูงสุดในท้องถิ่นกับเวลาของการเปลี่ยนผ่านไปยังจุดสูงสุดถัดไปสูงมาก มันอาจดูเหมือนสมดุลแบบไม่ต่อเนื่องดังที่ Gould เสนอไว้ (ดู Ridley)
การจำลองด้วยคอมพิวเตอร์ของการปรับตัวแบบเกาส์เซียน
ทฤษฎีในปัจจุบันพิจารณาเฉพาะค่าเฉลี่ยของการแจกแจงแบบต่อเนื่องที่สอดคล้องกับจำนวนบุคคลอนันต์เท่านั้น แต่ในความเป็นจริง จำนวนบุคคลมักมีจำกัด ซึ่งก่อให้เกิดความไม่แน่นอนในการประมาณค่าmและM (เมทริกซ์โมเมนต์ของการแจกแจงแบบเกาส์เซียน) และอาจส่งผลต่อประสิทธิภาพของกระบวนการด้วย น่าเสียดายที่ยังมีความรู้เกี่ยวกับเรื่องนี้ค่อนข้างน้อย โดยเฉพาะในทางทฤษฎี
การนำการปรับตัวตามปกติไปใช้ในคอมพิวเตอร์เป็นงานที่ค่อนข้างง่าย การปรับตัวของ m อาจทำได้ทีละตัวอย่าง (แต่ละบุคคล) ตัวอย่างเช่น
- m ( i + 1) = (1 – a ) m ( i ) + ax
โดยที่xคือตัวอย่างที่ผ่านเกณฑ์ และa < 1 เป็นค่าคงที่ที่เหมาะสม โดยที่ค่าผกผันของ a แทนจำนวนบุคคลในประชากร
โดยหลักการแล้ว Mอาจได้รับการปรับปรุงหลังจากทุกขั้นตอนyที่นำไปสู่จุดที่เป็นไปได้
- x = m + yตามสมการ:
- M ( i + 1) = (1 – 2 b ) M ( i ) + 2 byy T ,
โดยที่y Tคือเมทริกซ์สลับแถวและคอลัมน์ของyและb << 1 เป็นค่าคงที่ที่ เหมาะสมอีกค่าหนึ่ง เพื่อรับประกันการเพิ่มขึ้นของข้อมูลเฉลี่ย ที่เหมาะสม y ควรมีการกระจายแบบปกติโดยมีเมทริกซ์โมเมนต์μ 2 Mโดยที่ค่าสเกลาร์μ > 1 ใช้เพื่อเพิ่มข้อมูลเฉลี่ย ( เอนโทรปีของข้อมูลความไม่เป็นระเบียบ ความหลากหลาย) ในอัตราที่เหมาะสม แต่M จะไม่ถูกนำมาใช้ในการคำนวณ แทนที่จะใช้ M เราจะใช้เมทริกซ์Wที่กำหนดโดยWW T = M
ดังนั้น เราจึงได้y = Wgโดยที่gมีการแจกแจงแบบปกติด้วยเมทริกซ์โมเมนต์μUและUคือเมทริกซ์เอกลักษณ์WและW Tอาจได้รับการปรับปรุงโดยใช้สูตรต่อไปนี้
- W = (1 – b ) W + byg T และ W T = (1 – b ) W T + bgy T
เพราะการคูณให้ผลลัพธ์
- M = (1 – 2 ข ) M + 2 บายT ,
โดยที่เงื่อนไขต่างๆ รวมถึงb 2ถูกละเลย ดังนั้นM จะถูกปรับเปลี่ยนโดยอ้อมด้วยการประมาณที่ดี ในทางปฏิบัติ การอัปเดต Wเพียงอย่างเดียว ก็เพียงพอแล้ว
- W ( ผม + 1) = (1 – ข ) W ( ผม ) + บายT .
นี่คือสูตรที่ใช้ในแบบจำลองสมอง 2 มิติอย่างง่ายที่สอดคล้องกับกฎการเรียนรู้แบบเชื่อมโยงของเฮบเบียน โปรดดูส่วนถัดไป (Kjellström, 1996 และ 1999)
ภาพด้านล่างแสดงให้เห็นถึงผลกระทบของการเพิ่มข้อมูลเฉลี่ยในฟังก์ชันความหนาแน่นความน่าจะเป็นแบบเกาส์เซียนที่ใช้ในการปีนขึ้นยอดเขา (เส้นสองเส้นแสดงถึงเส้นชั้นความสูง) ทั้งกลุ่มสีแดงและสีเขียวมีค่าความเหมาะสมเฉลี่ยเท่ากันประมาณ 65% แต่กลุ่มสีเขียวมีข้อมูลเฉลี่ย สูงกว่ามาก ทำให้กระบวนการของกลุ่มสีเขียวมีประสิทธิภาพมากกว่า ผลกระทบของการปรับตัวนี้อาจไม่เด่นชัดมากนักในกรณี 2 มิติ แต่ในกรณีมิติสูง ประสิทธิภาพของกระบวนการค้นหาอาจเพิ่มขึ้นได้หลายเท่าตัว

วิวัฒนาการในสมอง
ในสมองนั้น เชื่อกันว่าวิวัฒนาการของข้อความในดีเอ็นเอจะถูกแทนที่ด้วยวิวัฒนาการของรูปแบบสัญญาณ และภูมิทัศน์ทางฟีโนไทป์จะถูกแทนที่ด้วยภูมิทัศน์ทางจิตใจ ซึ่งมีความซับซ้อนไม่แพ้กัน การเปรียบเทียบกับภูมิทัศน์ทางจิตใจนั้นตั้งอยู่บนสมมติฐานที่ว่ารูปแบบสัญญาณบางอย่างนำไปสู่ความเป็นอยู่ที่ดีหรือประสิทธิภาพที่ดีขึ้น ตัวอย่างเช่น การควบคุมกลุ่มกล้ามเนื้อจะนำไปสู่การออกเสียงคำที่ดีขึ้นหรือการแสดงดนตรีที่ดีขึ้น
ในแบบจำลองอย่างง่ายนี้ สมมติว่าสมองประกอบด้วยส่วนประกอบที่เชื่อมต่อกัน ซึ่งอาจทำการบวก คูณ และหน่วงค่าสัญญาณได้
- แกนกลางของเซลล์ประสาทอาจเพิ่มค่าสัญญาณได้
- ไซแนปส์อาจเพิ่มจำนวนขึ้นด้วยค่าคงที่และ
- แอกซอนอาจหน่วงค่าต่างๆ ได้
นี่เป็นพื้นฐานของทฤษฎีตัวกรองดิจิทัลและเครือข่ายประสาทเทียมที่ประกอบด้วยส่วนประกอบที่สามารถบวก คูณ และหน่วงค่าสัญญาณได้ รวมถึงแบบจำลองสมองหลายแบบด้วย (Levine 1991)
ในภาพด้านล่าง ก้านสมองถูกสมมติให้ส่งสัญญาณที่มีการกระจายแบบเกาส์เซียน ซึ่งอาจเป็นไปได้เนื่องจากเซลล์ประสาทบางเซลล์ทำงานแบบสุ่ม (Kandel et al.) ก้านสมองยังประกอบด้วยโครงสร้างที่ไม่เป็นระเบียบซึ่งล้อมรอบด้วยเปลือกที่มีระเบียบมากกว่า (Bergström, 1969) และตามทฤษฎีบทขีดจำกัดกลาง ผลรวมของสัญญาณจากเซลล์ประสาทจำนวนมากอาจมีการกระจายแบบเกาส์เซียน กล่องรูปสามเหลี่ยมแสดงถึงไซแนปส์ และกล่องที่มีเครื่องหมาย + แสดงถึงแกนเซลล์
ในเปลือกสมอง สัญญาณต่างๆ จะถูกทดสอบความเป็นไปได้ เมื่อสัญญาณได้รับการยอมรับ พื้นที่สัมผัสในไซแนปส์จะได้รับการปรับปรุงตามสูตรด้านล่าง ซึ่งสอดคล้องกับทฤษฎีของเฮบเบียน รูปภาพแสดงการจำลองด้วยคอมพิวเตอร์แบบ 2 มิติของการปรับตัวแบบเกาส์เซียนตามสูตรสุดท้ายในส่วนก่อนหน้า
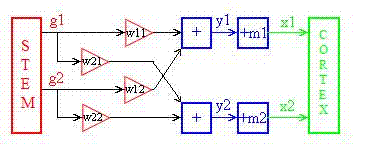
ค่า mและWจะได้รับการอัปเดตตาม:
- m 1 = 0.9 m 1 + 0.1 x 1; m 2 = 0.9 m 2 + 0.1 x 2 ;
- w 11 = 0.9 w 11 + 0.1 y 1 g 1 ; w 12 = 0.9 w 12 + 0.1 y 1 g 2 ;
- w 21 = 0.9 w 21 + 0.1 y 2 g 1 ; w 22 = 0.9 w 22 + 0.1 y 2 g 2 ;
ดังที่เห็นได้ นี่คล้ายคลึงกับสมองขนาดเล็กที่ถูกควบคุมโดยทฤษฎีการเรียนรู้แบบเฮบเบียน (Kjellström, 1996, 1999 และ 2002)
การปรับตัวแบบเกาส์เซียนและเจตจำนงเสรี
การปรับตัวแบบเกาส์เซียนในฐานะแบบจำลองวิวัฒนาการของสมองที่สอดคล้อง กับ ทฤษฎีการเรียนรู้แบบเชื่อมโยงของเฮบเบียน นำเสนอมุมมองทางเลือกเกี่ยวกับเจตจำนงเสรีเนื่องจากความสามารถของกระบวนการนี้ในการเพิ่มค่าเฉลี่ยความเหมาะสมของรูปแบบสัญญาณในสมองให้สูงสุด โดยการไต่ระดับภูมิทัศน์ทางจิตใจในลักษณะเดียวกับการวิวัฒนาการของลักษณะทางฟีโนไทป์
กระบวนการสุ่มเช่นนี้ทำให้เรามีอิสระในการเลือกมาก แต่แทบไม่มีเจตจำนงเลย อย่างไรก็ตาม ภาพลวงตาของเจตจำนงอาจเกิดขึ้นจากความสามารถของกระบวนการในการเพิ่มค่าเฉลี่ยความเหมาะสมให้สูงสุด ทำให้กระบวนการนั้นมุ่งสู่เป้าหมาย กล่าวคือ มันชอบจุดสูงสุดที่สูงกว่าในภูมิทัศน์มากกว่าจุดที่ต่ำกว่า หรือชอบทางเลือกที่ดีกว่ามากกว่าทางเลือกที่แย่กว่า ในลักษณะนี้ เจตจำนงลวงอาจปรากฏขึ้น มุมมองที่คล้ายกันนี้ได้ถูกนำเสนอโดย Zohar ในปี 1990 ดูเพิ่มเติมที่ Kjellström ในปี 1999
ทฤษฎีบทประสิทธิภาพสำหรับการค้นหาแบบสุ่ม
ประสิทธิภาพของการปรับตัวแบบเกาส์เซียนนั้นอาศัยทฤษฎีสารสนเทศของ Claude E. Shannon (ดูเนื้อหาสารสนเทศ ) เมื่อเหตุการณ์เกิดขึ้นด้วยความน่าจะเป็นPสารสนเทศ −log( P ) ก็สามารถได้รับมาได้ ตัวอย่างเช่น ถ้าค่าเฉลี่ยของความเหมาะสมคือPสารสนเทศที่ได้รับสำหรับแต่ละบุคคลที่ถูกเลือกให้มีชีวิตรอดจะเป็น −log( P ) โดยเฉลี่ย และงาน/เวลาที่จำเป็นในการได้รับสารสนเทศนั้นเป็นสัดส่วนกับ 1/ Pดังนั้น ถ้าประสิทธิภาพ E ถูกกำหนดให้เป็นสารสนเทศหารด้วยงาน/เวลาที่จำเป็นในการได้รับ เราจะได้ว่า:
- E = − P log( P ).
ฟังก์ชันนี้จะมีค่าสูงสุดเมื่อP = 1/ e = 0.37 Gaines ก็ได้ผลลัพธ์เดียวกันนี้โดยใช้วิธีการที่แตกต่างกัน
E = 0 ถ้าP = 0 สำหรับกระบวนการที่มีอัตราการกลายพันธุ์อนันต์ และถ้าP = 1 สำหรับกระบวนการที่มีอัตราการกลายพันธุ์ = 0 (โดยที่กระบวนการนั้นยังมีชีวิตอยู่) มาตรวัดประสิทธิภาพนี้ใช้ได้กับกระบวนการ ค้นหาแบบสุ่มจำนวนมากโดยมีเงื่อนไขบางประการที่ต้องเป็นไปตามนั้น
1. การค้นหาควรเป็นอิสระทางสถิติและมีประสิทธิภาพเท่าเทียมกันในทิศทางพารามิเตอร์ที่แตกต่างกัน เงื่อนไขนี้อาจเป็นไปได้โดยประมาณเมื่อเมทริกซ์โมเมนต์ของเกาส์เซียนได้รับการปรับให้มีข้อมูลเฉลี่ย สูงสุด ในบางขอบเขตที่ยอมรับได้ เนื่องจากการแปลงเชิงเส้นของกระบวนการทั้งหมดไม่ส่งผลกระทบต่อประสิทธิภาพ
2. บุคคลทุกคนมีต้นทุนเท่ากัน และอนุพันธ์ที่P = 1 มีค่าน้อยกว่า 0
จากนั้นจึงสามารถพิสูจน์ทฤษฎีบทต่อไปนี้ได้:
มาตรการประสิทธิภาพทั้งหมดที่ตรงตามเงื่อนไขข้างต้นจะเป็นสัดส่วนเชิงอะซิมโทติกกับ – P log( P/q ) เมื่อจำนวนมิติเพิ่มขึ้น และจะมีค่าสูงสุดที่P = q exp(-1) (Kjellström, 1996 และ 1999)
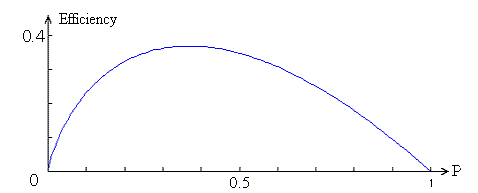
ภาพด้านบนแสดงฟังก์ชันประสิทธิภาพที่เป็นไปได้สำหรับกระบวนการค้นหาแบบสุ่ม เช่น การปรับตัวแบบเกาส์เซียน ทางด้านซ้าย กระบวนการจะมีความวุ่นวายมากที่สุดเมื่อP = 0 ในขณะที่ทางด้านขวาจะมีความเป็นระเบียบเรียบร้อยอย่างสมบูรณ์เมื่อP = 1
ในตัวอย่างโดย Rechenberg ในปี 1971 และ 1973 การเดินแบบสุ่มถูกผลักผ่านทางเดินที่ทำให้ค่าพารามิเตอร์x 1 มีค่าสูงสุด ในกรณีนี้ บริเวณที่ยอมรับได้ถูกกำหนดให้เป็นช่วงมิติ ( n − 1) ในพารามิเตอร์x 2 , x 3 , ..., x nแต่ ค่า x 1ที่ต่ำกว่าค่าที่ยอมรับได้ล่าสุดจะไม่ได้รับการยอมรับ เนื่องจากPไม่สามารถเกิน 0.5 ในกรณีนี้ ความเร็วสูงสุดไปสู่ ค่า x 1 ที่สูงขึ้น จึงเกิดขึ้นเมื่อP = 0.5/ e = 0.18 ซึ่งสอดคล้องกับผลการค้นพบของ Rechenberg
อีกมุมมองหนึ่งที่อาจน่าสนใจในบริบทนี้คือ ไม่จำเป็นต้องมีคำจำกัดความของข้อมูล (นอกเหนือจากที่ว่าจุดตัวอย่างภายในขอบเขตที่ยอมรับได้จะให้ข้อมูลเกี่ยวกับขอบเขตของขอบเขตนั้น) สำหรับการพิสูจน์ทฤษฎีบท ดังนั้น เนื่องจากสูตรดังกล่าวอาจตีความได้ว่าเป็นข้อมูลหารด้วยงานที่จำเป็นในการได้มาซึ่งข้อมูลนั้น นี่จึงเป็นข้อบ่งชี้ว่า −log( P ) เป็นตัวเลือกที่ดีในการใช้เป็นมาตรวัดข้อมูล
อัลกอริทึม Stauffer และ Grimson
การปรับตัวแบบเกาส์เซียนยังถูกนำไปใช้เพื่อวัตถุประสงค์อื่น ๆ เช่น การกำจัดเงาด้วย "อัลกอริทึม Stauffer-Grimson" ซึ่งเทียบเท่ากับการปรับตัวแบบเกาส์เซียนที่ใช้ในหัวข้อ "การจำลองการปรับตัวแบบเกาส์เซียนด้วยคอมพิวเตอร์" ข้างต้น ในทั้งสองกรณีใช้วิธีความน่าจะเป็นสูงสุดในการประมาณค่าเฉลี่ยโดยการปรับตัวทีละตัวอย่าง
แต่ก็มีความแตกต่างกันอยู่ ในกรณีของ Stauffer-Grimson ข้อมูลไม่ได้ถูกนำมาใช้เพื่อควบคุมตัวสร้างเลขสุ่มสำหรับการปรับศูนย์กลาง การเพิ่มค่าเฉลี่ยความเหมาะสม การหาค่าเฉลี่ยข้อมูลหรือผลผลิตทางการผลิต การปรับตัวของเมทริกซ์โมเมนต์ก็แตกต่างกันมากเมื่อเทียบกับ "วิวัฒนาการในสมอง" ข้างต้น
ดูเพิ่มเติม
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การปรับตัวแบบเกาส์เซียน
การปรับตัวแบบเกาส์เซียน (Gaussian adaptation หรือ GA)หรือที่เรียกว่า การปรับตัว แบบปกติหรือแบบธรรมชาติ (Normal or Natural adaptation หรือ
วิวัฒนาการตามธรรมชาติและการปรับตัวแบบเกาส์เซียน
นอกจากนี้ยังมีการเปรียบเทียบกับวิวัฒนาการตามธรรมชาติของประชากรสิ่งมีชีวิต ในกรณีนี้ s ( x ) คือความน่าจะเป็นที่แต่ละตัวที่มี ฟีโนไทป์ x จะอยู่รอดโดยการให้กำเนิดลูกหลานในรุ่นต่อไป ซึ่งเป็นนิยามของความเหมาะสมของแต่ละบุคคลที่กำหนดโดย Hartl ในปี 1981 ผลผลิต P...
วิธีการปีนเขา
สามารถคำนวณค่าความเหมาะสมเฉลี่ยได้หากทราบการกระจายตัวของพารามิเตอร์และโครงสร้างของภูมิทัศน์ ภูมิทัศน์จริงนั้นไม่เป็นที่รู้จัก แต่ภาพด้านล่างแสดงโปรไฟล์สมมติ (สีน้ำเงิน) ของภูมิทัศน์ตามแนวเส้น (x) ในห้องที่ครอบคลุมโดยพารามิเตอร์ดังกล่าว...
การจำลองด้วยคอมพิวเตอร์ของการปรับตัวแบบเกาส์เซียน
ทฤษฎีในปัจจุบันพิจารณาเฉพาะค่าเฉลี่ยของการแจกแจงแบบต่อเนื่องที่สอดคล้องกับจำนวนบุคคลอนันต์เท่านั้น แต่ในความเป็นจริง จำนวนบุคคลมักมีจำกัด ซึ่งก่อให้เกิดความไม่แน่นอนในการประมาณค่า m และ M (เมทริกซ์โมเมนต์ของการแจกแจงแบบเกาส์เซียน)...