อ่าน 15 นาที
ลำดับความคลาดเคลื่อนต่ำ
ใน ทางคณิตศาสตร์ ลำดับ ความคลาดเคลื่อนต่ำ คือ ลำดับ ที่มีคุณสมบัติว่า สำหรับทุกค่าของ n ลำดับย่อยของลำดับนี้จะ มี ความคลาดเคลื่อน ต่ำ เอ็น {\displaystyle N} x 1 , … , x เอ็น...
ลำดับความคลาดเคลื่อนต่ำ
ในทางคณิตศาสตร์ลำดับความคลาดเคลื่อนต่ำคือลำดับที่มีคุณสมบัติว่า สำหรับทุกค่าของ n ลำดับย่อยของลำดับนี้จะ มี ความคลาดเคลื่อนต่ำ


โดยคร่าวๆ แล้ว ความคลาดเคลื่อนของลำดับจะต่ำ หากสัดส่วนของจุดในลำดับที่ตกอยู่ในเซตB ใดๆ ใกล้เคียงกับสัดส่วนของค่า B ซึ่งจะเกิดขึ้นโดยเฉลี่ย (แต่ไม่ใช่สำหรับตัวอย่างเฉพาะ) ในกรณีของลำดับที่มีการกระจาย อย่างสม่ำเสมอ คำจำกัดความเฉพาะของความคลาดเคลื่อนจะแตกต่างกันไปตามการเลือกB ( ทรงกลมหลายมิติลูกบาศก์หลายมิติฯลฯ) และวิธีการคำนวณ (โดยปกติจะทำให้เป็นมาตรฐาน) และการรวมความคลาดเคลื่อนสำหรับแต่ละ B (โดยปกติจะใช้ค่าที่แย่ที่สุด)
ลำดับความคลาดเคลื่อนต่ำเรียกอีกอย่างว่า ลำดับ กึ่งสุ่มเนื่องจากมีการใช้กันอย่างแพร่หลายแทนตัวเลขสุ่ม ที่มีการกระจายแบบสม่ำเสมอ คำว่า "กึ่ง" ใช้เพื่อบ่งบอกให้ชัดเจนยิ่งขึ้นว่าค่าของลำดับความคลาดเคลื่อนต่ำนั้นไม่ใช่ทั้งตัวเลขสุ่มหรือตัวเลขสุ่มเทียมแต่ลำดับดังกล่าวมีคุณสมบัติบางอย่างร่วมกับตัวแปรสุ่ม และในบางแอปพลิเคชัน เช่นวิธีควาซี-มอนเตคาร์โลความคลาดเคลื่อนที่ต่ำกว่าถือเป็นข้อได้เปรียบที่สำคัญ
แอปพลิเคชัน

ตัวเลขกึ่งสุ่มมีข้อดีเหนือกว่าตัวเลขสุ่มแท้ตรงที่มันครอบคลุมขอบเขตที่สนใจได้อย่างรวดเร็วและสม่ำเสมอ
การประยุกต์ใช้ที่มีประโยชน์สองประการ ได้แก่ การหาฟังก์ชันลักษณะเฉพาะของฟังก์ชันความหนาแน่นความน่าจะเป็นและการหา ฟังก์ชัน อนุพันธ์ของฟังก์ชันเชิงกำหนดที่มีสัญญาณรบกวนน้อย ตัวเลขกึ่งสุ่มช่วยให้ สามารถคำนวณ โมเมนต์ ลำดับสูง ได้อย่างแม่นยำและรวดเร็วมาก
การประยุกต์ใช้ที่ไม่เกี่ยวข้องกับการเรียงลำดับ ได้แก่ การหาค่าเฉลี่ยค่าเบี่ยงเบนมาตรฐานค่าความเบ้และค่าความโค้งของข้อมูลทางสถิติ และการหาค่าสูงสุดและต่ำสุดทั้งแบบอินทิกรัลและแบบทั่วโลกของฟังก์ชันเชิงกำหนดที่ซับซ้อน นอกจากนี้ ตัวเลขกึ่งสุ่มยังสามารถใช้เป็นจุดเริ่มต้นสำหรับอัลกอริธึมเชิงกำหนดที่ทำงานได้เฉพาะในพื้นที่ เช่นการวนซ้ำแบบนิวตัน-ราฟสัน
ตัวเลขกึ่งสุ่มยังสามารถนำมาใช้ร่วมกับอัลกอริธึมการค้นหาได้อีกด้วย โดยใช้อัลกอริธึมการค้นหาตัวเลขกึ่งสุ่มสามารถใช้ในการหาค่าฐานนิยม ค่ามัธยฐาน ช่วงความเชื่อมั่นและการกระจายสะสมของการกระจายทางสถิติ รวมถึงค่าต่ำสุดเฉพาะที่ ทั้งหมด และคำตอบทั้งหมดของฟังก์ชันเชิงกำหนด ได้
ลำดับความคลาดเคลื่อนต่ำในการอินทิเกรตเชิงตัวเลข
วิธีการต่างๆ ในการอินทิเกรตเชิงตัวเลขสามารถอธิบายได้ว่าเป็นการประมาณค่าอินทิกรัลของฟังก์ชันในช่วงใดช่วงหนึ่ง เช่น [0,1] โดยใช้ค่าเฉลี่ยของฟังก์ชันที่ประเมินค่า ณ ค่าใดค่าหนึ่งในช่วงนั้น:



ถ้าเลือกจุดตามที่กำหนด นี่คือวิธีการกฎสี่เหลี่ยมผืนผ้าถ้าเลือกจุดโดยกระจายแบบสุ่ม (หรือแบบสุ่มเทียม ) นี่คือวิธีการมอนเตคาร์โลถ้าเลือกจุดโดยเป็นองค์ประกอบของลำดับที่มีความคลาดเคลื่อนต่ำ นี่คือวิธีการกึ่งมอนเตคาร์โลผลลัพธ์ที่น่าทึ่งอย่างหนึ่งคืออสมการ Koksma–Hlawka (ที่กล่าวไว้ด้านล่าง) แสดงให้เห็นว่าข้อผิดพลาดของวิธีการดังกล่าวสามารถจำกัดได้ด้วยผลคูณของสองพจน์ โดยพจน์หนึ่งขึ้นอยู่กับค่าที่กำหนดเท่านั้นและ อีกพจน์หนึ่งคือความคลาดเคลื่อนของเซต

การสร้างเซตในลักษณะที่ว่า หากสร้างเซตที่มีองค์ประกอบแล้วไม่จำเป็นต้องคำนวณองค์ประกอบก่อนหน้าซ้ำอีกนั้นสะดวกกว่า กฎสี่เหลี่ยมผืนผ้าใช้เซตจุดที่มีความคลาดเคลื่อนต่ำ แต่โดยทั่วไปแล้วจะต้องคำนวณองค์ประกอบใหม่หากค่าเพิ่มขึ้น ในวิธีการมอนเตคาร์โลแบบสุ่ม ไม่จำเป็นต้องคำนวณองค์ประกอบใหม่หากค่าเพิ่มขึ้น แต่เซตจุดเหล่านั้นไม่มีความคลาดเคลื่อนน้อยที่สุด โดยการใช้ลำดับที่มีความคลาดเคลื่อนต่ำ เรามุ่งหวังที่จะให้ความคลาดเคลื่อนต่ำและไม่จำเป็นต้องคำนวณซ้ำ แต่ในความเป็นจริงแล้ว ลำดับที่มีความคลาดเคลื่อนต่ำจะดีขึ้นเรื่อยๆ ในแง่ของความคลาดเคลื่อนก็ต่อเมื่อเราไม่อนุญาตให้มีการคำนวณซ้ำเท่านั้น

นิยามของความคลาดเคลื่อน
ความคลาดเคลื่อนของเซตถูกนิยามโดยใช้ สัญกรณ์ ของนีเดอร์ไรเตอร์ดังนี้


โดยที่คือมาตรวัดเลเบสแบบ n มิติคือ จำนวนจุดในที่ตกอยู่ในและคือเซตของช่วงหรือกล่องแบบ n มิติในรูปแบบ







ที่ไหน.

ความคลาดเคลื่อนแบบดาว ถูกกำหนดในทำนองเดียวกัน ยกเว้นว่าค่าสูงสุดจะหาจากเซตของกล่องสี่เหลี่ยมผืนผ้าในรูปแบบ



โดยที่อยู่ในช่วงครึ่งเปิด [0, 1)

ทั้งสองมีความเกี่ยวข้องกันโดย

หมายเหตุ : ตามคำจำกัดความเหล่านี้ ความคลาดเคลื่อนแสดงถึงค่าเบี่ยงเบนความหนาแน่นของจุดที่แย่ที่สุดหรือสูงสุดของชุดจุดสม่ำเสมอ อย่างไรก็ตาม มาตรวัดข้อผิดพลาดอื่นๆ ก็มีความหมายเช่นกัน ซึ่งนำไปสู่คำจำกัดความและมาตรวัดความแปรผันอื่นๆ ตัวอย่างเช่นความคลาดเคลื่อน -discrepancy หรือความคลาดเคลื่อน -discrepancy แบบปรับศูนย์กลางที่ปรับปรุงแล้ว ก็ถูกนำมาใช้อย่างแพร่หลายเพื่อเปรียบเทียบคุณภาพของชุดจุดสม่ำเสมอ ทั้งสองวิธีนี้คำนวณได้ง่ายกว่ามากสำหรับค่าและ ที่มี ขนาดใหญ่

อสมการค็อกมา-ฮลอกา
ให้เป็นลูกบาศก์หน่วยมิติ. ให้มีการแปรผันที่จำกัดบนในความหมายของHardyและ Krause แล้วสำหรับ ใดๆใน,

![{\displaystyle {\overline {I}}^{s}=[0,1]\times \cdots \times [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b7b6b45832d30cbe2b66656b80245cb209cb4262)


อสมการKoksma – Hlawkaมีความแม่นยำในความหมายต่อไปนี้: สำหรับเซตของจุดใดๆในและใดๆจะมีฟังก์ชันที่มีการแปรผันจำกัด และเช่นนั้น






ดังนั้น คุณภาพของกฎการอินทิเกรตเชิงตัวเลขจึงขึ้นอยู่กับความคลาดเคลื่อนเท่านั้น

สูตรของฮลอกา–ซาเร็มบา
ให้. สำหรับเราเขียน และใช้สัญลักษณ์ แทนจุดที่ได้จากxโดยการแทนที่พิกัดที่ไม่ได้อยู่ในuด้วย. จากนั้น





![{\displaystyle {\frac {1}{N}}\sum _{i=1}^{N}f(x_{i})-\int _{{\bar {I}}^{s}}f(u)\,du=\sum _{\emptyset \neq u\subseteq D}(-1)^{|u|}\int _{[0,1]^{|u|}}\operatorname {disc} (x_{u},1){\frac {\partial ^{|u|}}{\partial x_{u}}}f(x_{u},1)\,dx_{u},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/646d05c4c12cae58e128651816856d90c9a25e51)
ฟังก์ชันความคลาดเคลื่อนอยู่ ที่ไหน

เวอร์ชัน L 2ของอสมการค็อกมา–ฮลอว์กา
เมื่อนำอสมการโคชี-ชวาร์ซสำหรับปริพันธ์และผลรวมมาประยุกต์ใช้กับเอกลักษณ์ฮลาวกา-ซาเรมบา เราจะได้อสมการค็อกสมา-ฮลาวกาในรูปแบบหนึ่ง:

ที่ไหน
![{\displaystyle \operatorname {disc} _{d}(\{t_{i}\})=\left(\sum _{\emptyset \neq u\subseteq D}\int _{[0,1]^{|u|}}\operatorname {disc} (x_{u},1)^{2}\,dx_{u}\right)^{1/2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/609a886b91fa44773d2ddd89c752bc1a037309a6)
และ
![{\displaystyle \|f\|_{d}=\left(\sum _{u\subseteq D}\int _{[0,1]^{|u|}}\left|{\frac {\partial ^{|u|}}{\partial x_{u}}}f(x_{u},1)\right|^{2}dx_{u}\right)^{1/2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dee8232a0985af6392e00e77e9bdfa8c4f98fe77)
ความคลาดเคลื่อนมีความสำคัญในทางปฏิบัติสูง เนื่องจากสามารถคำนวณได้อย่างรวดเร็วและชัดเจนสำหรับชุดจุดที่กำหนด ด้วยวิธีนี้จึงง่ายต่อการสร้างตัวเพิ่มประสิทธิภาพชุดจุดโดยใช้ความคลาดเคลื่อนเป็นเกณฑ์
ความไม่เท่าเทียมกันระหว่างแอร์ดอส-ตูรัน-ค็อกสมา
การหาค่าที่แน่นอนของความคลาดเคลื่อนของชุดจุดขนาดใหญ่เป็นเรื่องยากในเชิงคำนวณ อสมการ Erdős – Turán – Koksmaให้ค่าขอบเขตบน
ให้เป็นจุดในและเป็นจำนวนเต็มบวกใดๆ แล้ว


ที่ไหน

ข้อสันนิษฐานหลัก
ข้อสันนิษฐานที่ 1.มีค่าคงที่ค่าหนึ่งซึ่งขึ้นอยู่กับมิติเท่านั้นโดยที่ สำหรับเซตจุดจำกัดใดๆ



ข้อสันนิษฐานที่ 2.มีค่าคงที่ค่าหนึ่งซึ่งขึ้นอยู่กับ : เท่านั้นโดยที่:


สำหรับจำนวนอนันต์ของลำดับอนันต์ใดๆ

These conjectures are equivalent. They have been proved for by W. M. Schmidt. In higher dimensions, the corresponding problem is still open. The best-known lower bounds are due to Michael Lacey and collaborators.

Lower bounds
Let . Then


for any finite point set .
Let . W. M. Schmidt proved that for any finite point set ,


where

For arbitrary dimensions , K. F. Roth proved that


for any finite point set . Jozef Beck [1] established a double log improvement of this result in three dimensions. This was improved by D. Bilyk and M. T. Lacey to a power of a single logarithm. The best known bound for s > 2 is due D. Bilyk and M. T. Lacey and A. Vagharshakyan.[2] There exists a depending on s so that


for any finite point set .
Construction of low-discrepancy sequences
Because any distribution of random numbers can be mapped onto a uniform distribution, and quasirandom numbers are mapped in the same way, this article only concerns generation of quasirandom numbers on a multidimensional uniform distribution.
There are constructions of sequences known such that where is a certain constant, depending on the sequence. After Conjecture 2, these sequences are believed to have the best possible order of convergence. Examples below are the van der Corput sequence, the Halton sequences, and the Sobol’ sequences. One general limitation is that construction methods can usually only guarantee the order of convergence. Practically, low discrepancy can be only achieved if is large enough, and for large given s this minimum can be very large. This means running a Monte-Carlo analysis with e.g. variables and points from a low-discrepancy sequence generator may offer only a very minor accuracy improvement .




Random numbers
Sequences of quasirandom numbers can be generated from random numbers by imposing a negative correlation on those random numbers. One way to do this is to start with a set of random numbers on and construct quasirandom numbers which are uniform on using:




for odd and for even.



A second way to do it with the starting random numbers is to construct a random walk with offset 0.5 as in:

That is, take the previous quasirandom number, add 0.5 and the random number, and take the result modulo 1.
สำหรับมิติมากกว่าหนึ่งมิติสามารถใช้ ตารางลาติน ที่มีมิติเหมาะสมเพื่อสร้างค่าชดเชยเพื่อให้แน่ใจว่าครอบคลุมพื้นที่ทั้งหมดอย่างสม่ำเสมอ

การเกิดซ้ำแบบเพิ่ม
สำหรับจำนวนอตรรกยะใดๆลำดับจะเป็นดังนี้


มีความคลาดเคลื่อนที่มีแนวโน้มไปทาง. โปรดทราบว่าลำดับสามารถกำหนดได้แบบเวียนซ้ำโดย


ค่าที่ดีจะให้ค่าความคลาดเคลื่อนน้อยกว่าลำดับของตัวเลขสุ่มแบบเอกรูปอิสระ
ความคลาดเคลื่อนสามารถจำกัดได้ด้วยเลขชี้กำลังการประมาณค่าของถ้าเลขชี้กำลังการประมาณค่าคือแล้วสำหรับค่าใดๆขอบเขตต่อไปนี้จะเป็นจริง: [ 3 ]


ตามทฤษฎีบท Thue–Siegel–Rothเลขชี้กำลังประมาณค่าของจำนวนพีชคณิตอ ตรรกยะใดๆ คือ 2 ซึ่งให้ขอบเขตด้านบน

ความสัมพันธ์เวียนเกิดข้างต้นคล้ายกับความสัมพันธ์เวียนเกิดที่ใช้โดยตัวสร้างตัวเลขสุ่มเชิงเส้นซึ่งเป็นตัวสร้างตัวเลขสุ่มเทียมคุณภาพต่ำ: [ 4 ]

สำหรับการเกิดซ้ำแบบบวกที่มีความคลาดเคลื่อนต่ำข้างต้น ค่าaและmถูกเลือกให้เป็น 1 อย่างไรก็ตาม โปรดทราบว่าวิธีนี้จะไม่สร้างตัวเลขสุ่มที่เป็นอิสระ ดังนั้นจึงไม่ควรนำไปใช้เพื่อวัตถุประสงค์ที่ต้องการความเป็นอิสระ
ค่าที่มีความคลาดเคลื่อนน้อยที่สุดคือเศษส่วนของอัตราส่วนทองคำ : [ 5 ]


ค่าอีกค่าหนึ่งที่เกือบจะดีเท่ากันคือส่วนที่เป็นเศษส่วนของอัตราส่วนเงินซึ่งก็คือส่วนที่เป็นเศษส่วนของรากที่สองของ 2:

ในกรณีที่มีมากกว่าหนึ่งมิติ จำเป็นต้องใช้ตัวเลขกึ่งสุ่มแยกต่างหากสำหรับแต่ละมิติ ชุดค่าที่สะดวกที่ใช้คือ รากที่สองของจำนวนเฉพาะตั้งแต่ 2 ขึ้นไป โดยทั้งหมดคำนวณแบบโมดูลัส 1:

อย่างไรก็ตาม ชุดค่าที่อิงตามอัตราส่วนทองคำทั่วไปได้รับการแสดงให้เห็นว่าสร้างจุดที่มีการกระจายอย่างสม่ำเสมอมากขึ้น[ 6 ]
รายชื่อเครื่องกำเนิดเลขสุ่มเทียมแสดงวิธีการสร้างเลขสุ่มเทียมที่เป็นอิสระต่อกัน หมายเหตุ : ในมิติน้อยๆ การเรียกซ้ำแบบเวียนเกิดจะนำไปสู่ชุดเลขสุ่มที่มีคุณภาพดี แต่สำหรับมิติที่ใหญ่กว่า(เช่น) เครื่องกำเนิดชุดจุดอื่นๆ อาจให้ความคลาดเคลื่อนที่ต่ำกว่ามาก

ลำดับแวนเดอร์คอร์พุต
อนุญาต

ให้แทนจำนวนเต็มบวกด้วย นั่นคือกำหนดให้




จากนั้นจะมีค่าคงที่ที่ขึ้นอยู่กับเท่านั้นซึ่ง สอดคล้อง กับเงื่อนไข


ความ คลาดเคลื่อนของดาวอยู่ ที่ไหน

ลำดับฮัลตัน

ลำดับ Halton เป็นการขยายลำดับ van der Corput ไปสู่มิติที่สูงขึ้นอย่างเป็นธรรมชาติ ให้sเป็นมิติใดๆ และb 1 , ..., b sเป็นจำนวนเต็มที่ไม่มีตัวหารร่วม ใดๆ ที่มากกว่า 1 กำหนด

จากนั้นจะมีค่าคงที่Cที่ขึ้นอยู่กับb 1 , ..., b s เท่านั้น โดยที่ลำดับ { x ( n )} n ≥1เป็นลำดับมิติ s ที่มี

ชุดแฮมเมอร์สลีย์

ให้เป็น จำนวนเต็มบวกที่ไม่มีตัวหาร ร่วมกันและมากกว่า 1 สำหรับและที่ กำหนด เซต Hammersleyมิติขนาดจะถูกกำหนดโดย[ 7 ]


สำหรับ. จากนั้น


โดยที่เป็นค่าคงที่ซึ่งขึ้นอยู่กับเท่านั้น
หมายเหตุ : สูตรแสดงให้เห็นว่าเซตแฮมเมอร์สลีย์นั้นแท้จริงแล้วคือลำดับฮาลตัน แต่เราได้มิติเพิ่มมาอีกหนึ่งมิติโดยอัตโนมัติด้วยการเพิ่มการกวาดเชิงเส้น ซึ่งเป็นไปได้ก็ต่อเมื่อ ทราบค่าล่วงหน้าเท่านั้น เซตเชิงเส้นยังเป็นเซตที่มีความคลาดเคลื่อนหนึ่งมิติที่ต่ำที่สุดเท่าที่จะเป็นไปได้โดยทั่วไป น่าเสียดายที่สำหรับมิติที่สูงกว่านั้น ไม่มี "เซตบันทึกความคลาดเคลื่อน" ดังกล่าวที่รู้จัก สำหรับค่า เครื่องกำเนิดเซตจุดที่มีความคลาดเคลื่อนต่ำส่วนใหญ่จะให้ความคลาดเคลื่อนที่ใกล้เคียงกับค่าที่เหมาะสมที่สุดเป็นอย่างน้อย
ลำดับโซโบล
ลำดับโซบอลแบบ Antonov–Saleev สร้างตัวเลขระหว่างศูนย์ถึงหนึ่งโดยตรงเป็นเศษส่วนไบนารีที่มีความยาวจากชุดเศษส่วนไบนารีพิเศษที่เรียกว่าตัวเลขทิศทาง บิตของรหัส เกรย์ ของ, , ถูกใช้เพื่อเลือกตัวเลขทิศทาง ในการหาค่าลำดับโซบอล ให้ใช้การดำเนินการเอกซ์คลูซีฟออร์ของค่าไบนารีของรหัสเกรย์ของกับตัวเลขทิศทางที่เหมาะสม จำนวนมิติที่ต้องการจะมีผลต่อการเลือก





การสุ่มตัวอย่างดิสก์แบบปัวซง
การสุ่มตัวอย่างดิสก์แบบปัวซงเป็นที่นิยมในวิดีโอเกมเพื่อวางวัตถุอย่างรวดเร็วในลักษณะที่ดูเหมือนสุ่ม แต่รับประกันว่าจุดสองจุดทุกจุดจะอยู่ห่างกันอย่างน้อยตามระยะทางขั้นต่ำที่กำหนด[ 8 ]ซึ่งไม่รับประกันความคลาดเคลื่อนต่ำ (เช่น Sobol') แต่รับประกันความคลาดเคลื่อนที่ต่ำกว่าการสุ่มตัวอย่างแบบสุ่มอย่างแท้จริง เป้าหมายของรูปแบบการสุ่มตัวอย่างเหล่านี้ขึ้นอยู่กับการวิเคราะห์ความถี่มากกว่าความคลาดเคลื่อน ซึ่งเป็นรูปแบบที่เรียกว่า "สัญญาณรบกวนสีน้ำเงิน"
ตัวอย่างกราฟิก
จุดที่แสดงด้านล่างคือองค์ประกอบ 100, 1000 และ 10000 แรกในลำดับประเภท Sobol' เพื่อเปรียบเทียบ องค์ประกอบ 10000 ของลำดับจุดสุ่มเทียมก็แสดงไว้ด้วยเช่นกัน ลำดับความคลาดเคลื่อนต่ำถูกสร้างขึ้นโดย อัลกอริทึม TOMS 659 [ 9 ] การใช้งานอัลกอริทึมในFortranมีให้ใช้งานจาก Netlib
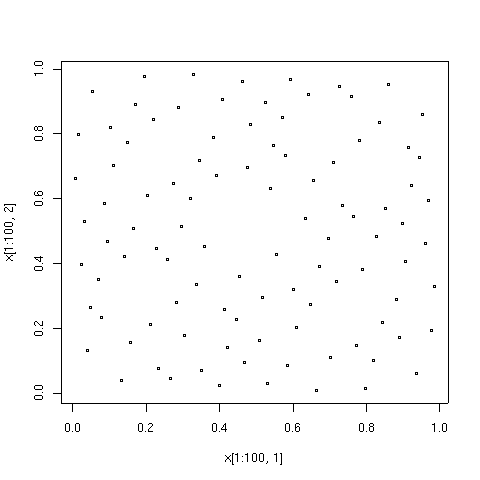 | 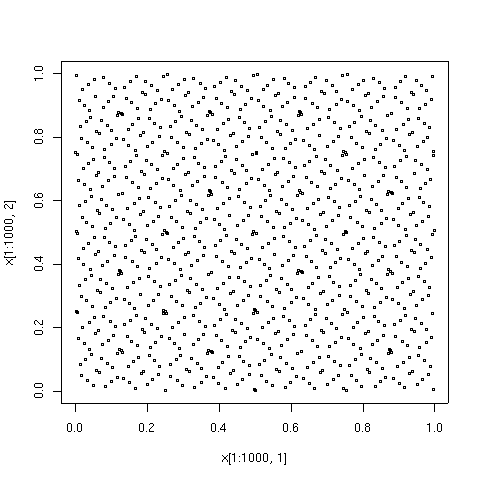 |
| 100 จุดแรกในลำดับความคลาดเคลื่อนต่ำของประเภท Sobol' | คะแนน 1,000 คะแนนแรกในลำดับเดียวกัน คะแนน 1,000 คะแนนนี้ประกอบด้วย 100 คะแนนแรก โดยมีคะแนนเพิ่มเติมอีก 900 คะแนน |
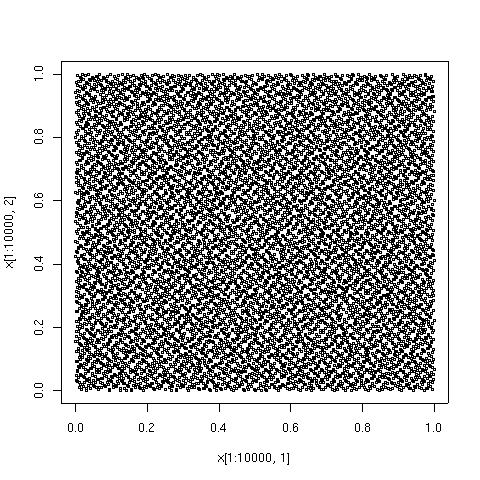 | 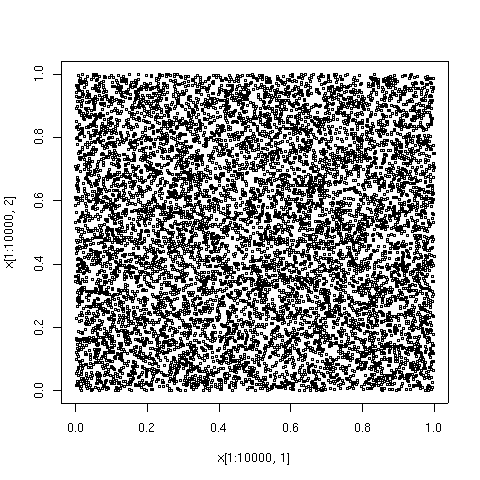 |
| 10,000 คะแนนแรกในลำดับเดียวกัน 10,000 คะแนนนี้ประกอบด้วย 1,000 คะแนนแรก โดยมีคะแนนเพิ่มเติมอีก 9,000 คะแนน | เพื่อเป็นการเปรียบเทียบ นี่คือ 10,000 จุดเริ่มต้นในลำดับของตัวเลขสุ่มเทียมที่มีการกระจายอย่างสม่ำเสมอ จะเห็นได้ว่ามีบริเวณที่มีความหนาแน่นสูงและต่ำ |
ดูเพิ่มเติม
- ทฤษฎีความคลาดเคลื่อน
- โซ่ Markov Monte Carlo
- วิธีการควาซี-มอนเตคาร์โล
- ตารางแบบเบาบาง
- การสุ่มตัวอย่างอย่างเป็นระบบ
หมายเหตุ
- ↑เบ็ค, โยซเซฟ (1989) "ทฤษฎีบทแวนอาร์เดน-เอห์เรนเฟสต์สองมิติในเรื่องความไม่ปกติของการแจกแจง " คอมโพสิตคณิตศาสตร์ . 72 (3): 269– 339. ม.ร. 1032337 . S2CID 125940424 . สบีแอล 0691.10041 .
- ^ Bilyk, Dmitriy; Lacey, Michael T.; Vagharshakyan, Armen (2008). "เกี่ยวกับความไม่เท่าเทียมกันของลูกบอลขนาดเล็กในทุกมิติ" . วารสารการวิเคราะห์เชิงฟังก์ชัน . 254 (9): 2470– 2502. arXiv : 0705.4619 . doi : 10.1016/j.jfa.2007.09.010 . S2CID 14234006 .
- ↑ไคเปอร์ส และนีเดอร์ไรเตอร์ 2005 , หน้า. 123
- ^ Knuth, Donald E. "บทที่ 3 – ตัวเลขสุ่ม" ศิลปะแห่งการเขียนโปรแกรมคอมพิวเตอร์เล่ม 2
- ^ Skarupke, Malte (16 มิถุนายน 2018). "Fibonacci Hashing: The Optimization that the World Forgot"คุณสมบัติ
อย่างหนึ่งของอัตราส่วนทองคำคือ คุณสามารถใช้มันเพื่อแบ่งช่วงใดๆ ออกเป็นส่วนย่อยๆ อย่างเท่าๆ กัน ... หากคุณไม่ทราบล่วงหน้าว่าคุณจะต้องดำเนินการกี่ขั้นตอน
- ^ Roberts, Martin (2018). "ประสิทธิภาพอันไม่สมเหตุสมผลของลำดับกึ่งสุ่ม" . เก็บถาวรจากต้นฉบับเมื่อวันที่ 1 มีนาคม 2025
- ^ Hammersley, JM; Handscomb, DC (1964). วิธี การมอนเตคาร์โลdoi : 10.1007/978-94-009-5819-7 . ISBN 978-94-009-5821-0.
{{cite book}}: ISBN / Date incompatibility (help) - ↑ เฮอร์มาน ทูลเคน ทูลเคน, เฮอร์แมน (มีนาคม 2551) "การสุ่มตัวอย่างดิสก์ปัวซง " Dev.Mag ลำดับที่ 21. หน้า 21–25 .
- ^ Bratley, Paul; Fox, Bennett L. (1988). "Algorithm 659" . ACM Transactions on Mathematical Software . 14 : 88– 100. doi : 10.1145/42288.214372 . S2CID 17325779 .
ลิงก์ภายนอก
- รวมอัลกอริธึมของ ACM (ดูอัลกอริธึมหมายเลข 647, 659 และ 738)
- ลำดับกึ่งสุ่มจากคลังข้อมูลวิทยาศาสตร์ของ GNU
- การสุ่มตัวอย่างแบบกึ่งสุ่มภายใต้ข้อจำกัดที่ FinancialMathematics.Com
- ตัวสร้างลำดับ Sobol' ในภาษา C++
- เอกสารอ้างอิง API ของ SciPy QMC: scipy.stats.qmc
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ ลำดับความคลาดเคลื่อนต่ำ
ใน ทางคณิตศาสตร์ ลำดับ ความคลาดเคลื่อนต่ำ คือ ลำดับ ที่มีคุณสมบัติว่า สำหรับทุกค่าของ n ลำดับย่อยของลำดับนี้จะ มี ความคลาดเคลื่อน ต่ำ เอ็น {\displaystyle N} x 1 , … , x เอ็น...
แอปพลิเคชัน
ตัวเลขกึ่งสุ่มมีข้อดีเหนือกว่าตัวเลขสุ่มแท้ตรงที่มันครอบคลุมขอบเขตที่สนใจได้อย่างรวดเร็วและสม่ำเสมอ
ลำดับความคลาดเคลื่อนต่ำในการอินทิเกรตเชิงตัวเลข
วิธีการต่างๆ ใน การอินทิเกรตเชิงตัวเลข สามารถอธิบายได้ว่าเป็นการประมาณค่าอินทิกรัลของฟังก์ชันในช่วงใดช่วงหนึ่ง เช่น [0,1] โดยใช้ค่าเฉลี่ยของฟังก์ชันที่ประเมินค่า ณ ค่าใดค่าหนึ่งในช่วงนั้น: เอฟ {\displaystyle f} { x 1 , … , x เอ็น } {\displaystyle...
นิยามของความคลาดเคลื่อน
ความ คลาดเคลื่อน ของเซตถูกนิยามโดยใช้ สัญกรณ์ ของนีเดอร์ไรเตอร์ ดังนี้ พี = { x 1 , … , x เอ็น } {\displaystyle P=\{x_{1},\dots ,x_{N}}\} ดี เอ็น ( พี ) = จีบ บี ∈ เจ | เอ ( บี ; พี ) เอ็น − λ ส ( บี ) | {\displaystyle D_{N}(P)=\sup _{B\in J}\left|{\frac...