อ่าน 4 นาที
การประมาณความหนาแน่น
ใน ทางสถิติ การ ประมาณความหนาแน่นของความน่าจะเป็น หรือเรียกง่ายๆ ว่า การประมาณความหนาแน่น คือการสร้าง การประมาณค่า โดยอาศัย ข้อมูล ที่สังเกตได้ ของ ฟังก์ชันความหนาแน่นของความน่าจะ...
การประมาณความหนาแน่น

ในทางสถิติการประมาณความหนาแน่นของความน่าจะเป็นหรือเรียกง่ายๆ ว่าการประมาณความหนาแน่นคือการสร้างการประมาณค่าโดยอาศัยข้อมูล ที่สังเกตได้ ของฟังก์ชันความหนาแน่นของความน่าจะ เป็นพื้นฐานที่ไม่สามารถ สังเกตได้ ฟังก์ชันความหนาแน่นที่ไม่สามารถสังเกตได้นั้น ถือว่าเป็นความหนาแน่นที่ประชากรขนาดใหญ่กระจายตัวอยู่ โดยทั่วไปแล้ว ข้อมูลจะถูกมองว่าเป็นตัวอย่างสุ่มจากประชากรนั้น[ 1 ]
มีการใช้แนวทางที่หลากหลายในการประมาณความหนาแน่น รวมถึงหน้าต่าง Parzen และ เทคนิคการจัดกลุ่มข้อมูลหลายประเภท รวมถึง การหาปริมาณเวกเตอร์ รูปแบบพื้นฐานที่สุดของการประมาณความหนาแน่นคือฮิสโตแกรมที่ ปรับขนาดใหม่
ตัวอย่าง
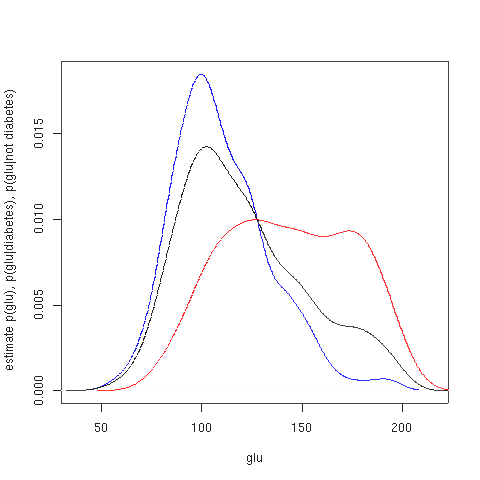


เราจะพิจารณาบันทึกเกี่ยวกับอุบัติการณ์ของโรคเบาหวานข้อความต่อไปนี้คัดลอกมาจาก คำอธิบาย ชุดข้อมูล โดยตรง :
- กลุ่มผู้หญิงที่มีอายุอย่างน้อย 21 ปี เชื้อสายอินเดียนแดงเผ่า ปิมาและอาศัยอยู่ใกล้เมืองฟีนิกซ์ รัฐแอริโซนา ได้รับการทดสอบโรคเบาหวานตามเกณฑ์ขององค์การอนามัยโลกข้อมูลถูกรวบรวมโดยสถาบันโรคเบาหวาน โรคระบบทางเดินอาหาร และโรคไตแห่งชาติของสหรัฐอเมริกา เราใช้บันทึกที่สมบูรณ์ 532 รายการ[ 2 ] [ 3 ]
ในตัวอย่างนี้ เราสร้างค่าประมาณความหนาแน่นสามค่าสำหรับ "glu" ( ความเข้มข้น ของกลูโคสในพลาสมา ) ค่าแรกขึ้นอยู่กับการมีโรคเบาหวาน ค่าที่สองขึ้นอยู่กับการไม่มีโรคเบาหวาน และค่าที่สามไม่ขึ้นอยู่กับโรคเบาหวาน จากนั้นจึงใช้ค่าประมาณความหนาแน่นแบบมีเงื่อนไขเหล่านี้เพื่อสร้างความน่าจะเป็นของโรคเบาหวานโดยขึ้นอยู่กับ "glu"
ข้อมูล "glu" ได้รับมาจากแพ็กเกจ MASS [ 4 ]ของภาษาการเขียนโปรแกรม Rภายใน R ?Pima.trและ?Pima.teให้รายละเอียดข้อมูลที่สมบูรณ์ยิ่งขึ้น
ค่าเฉลี่ยของ "glu" ในผู้ป่วยเบาหวานคือ 143.1 และค่าเบี่ยงเบนมาตรฐานคือ 31.26 ส่วนค่าเฉลี่ยของ "glu" ในผู้ที่ไม่เป็นเบาหวานคือ 110.0 และค่าเบี่ยงเบนมาตรฐานคือ 24.29 จากข้อมูลนี้ เราจะเห็นว่า ในชุดข้อมูลนี้ ผู้ป่วยเบาหวานมีความสัมพันธ์กับระดับ "glu" ที่สูงกว่า ซึ่งจะเห็นได้ชัดเจนยิ่งขึ้นเมื่อแสดงกราฟของฟังก์ชันความหนาแน่นที่ประมาณไว้
รูปแรกแสดงค่าประมาณความหนาแน่นของp (glu | diabetes=1), p (glu | diabetes=0) และp (glu) ค่าประมาณความหนาแน่นเหล่านี้เป็นค่าประมาณความหนาแน่นแบบเคอร์เนลโดยใช้เคอร์เนลแบบเกาส์เซียน กล่าวคือ ฟังก์ชันความหนาแน่นแบบเกาส์เซียนจะถูกวางไว้ที่แต่ละจุดข้อมูล และผลรวมของฟังก์ชันความหนาแน่นจะถูกคำนวณในช่วงของข้อมูล
จากความหนาแน่นของ "glu" ที่มีเงื่อนไขว่าเป็นโรคเบาหวาน เราสามารถหาความน่าจะเป็นของโรคเบาหวานที่มีเงื่อนไขว่าเป็น "glu" ได้โดยใช้กฎของเบย์สเพื่อความกระชับ ในสูตรนี้ "โรคเบาหวาน" จะถูกย่อเป็น "db."

รูปที่สองแสดงความน่าจะเป็นภายหลังที่ประมาณไว้p (เบาหวาน=1 | กลูโคส) จากข้อมูลเหล่านี้ ดูเหมือนว่าระดับ "กลูโคส" ที่เพิ่มขึ้นจะเกี่ยวข้องกับโรคเบาหวาน
การใช้งานและวัตถุประสงค์
การใช้การประมาณความหนาแน่นที่เป็นธรรมชาติมากอย่างหนึ่งคือการตรวจสอบคุณสมบัติของชุดข้อมูลที่กำหนดอย่างไม่เป็นทางการ การประมาณความหนาแน่นสามารถให้ข้อบ่งชี้ที่มีค่าเกี่ยวกับคุณลักษณะต่างๆ เช่น ความเบี่ยงเบนและความหลากหลายของข้อมูล ในบางกรณี การประมาณความหนาแน่นจะให้ข้อสรุปที่อาจถือได้ว่าเป็นความจริงที่ชัดเจน ในขณะที่ในกรณีอื่นๆ การประมาณความหนาแน่นจะเป็นเพียงการชี้ทางไปสู่การวิเคราะห์เพิ่มเติมและ/หรือการรวบรวมข้อมูล[ 5 ]

ส่วนสำคัญอย่างหนึ่งของสถิติคือการนำเสนอข้อมูลกลับไปยังลูกค้าเพื่ออธิบายและแสดงให้เห็นถึงข้อสรุปที่อาจได้มาด้วยวิธีการอื่น การประมาณค่าความหนาแน่นนั้นเหมาะสมอย่างยิ่งสำหรับจุดประสงค์นี้ ด้วยเหตุผลที่ว่าเข้าใจได้ง่ายสำหรับผู้ที่ไม่ใช่ผู้เชี่ยวชาญด้านคณิตศาสตร์
ตัวอย่างเพิ่มเติมที่แสดงให้เห็นถึงการใช้การประมาณความหนาแน่นเพื่อวัตถุประสงค์ในการสำรวจและการนำเสนอ รวมถึงกรณีสำคัญของข้อมูลสองตัวแปร[ 7 ]
การประมาณความหนาแน่นยังถูกนำมาใช้บ่อยครั้งในการตรวจจับความผิดปกติหรือการตรวจจับสิ่งแปลกใหม่ : [ 8 ]หากการสังเกตอยู่ในบริเวณที่มีความหนาแน่นต่ำมาก ก็มีแนวโน้มที่จะเป็นความผิดปกติหรือสิ่งแปลกใหม่
- ในด้านอุทกวิทยาฮิสโตแกรมและฟังก์ชันความหนาแน่นโดยประมาณของข้อมูลปริมาณน้ำฝนและการไหลของแม่น้ำ ซึ่งวิเคราะห์ด้วยการกระจายความน่าจะเป็นจะถูกนำมาใช้เพื่อให้ได้ข้อมูลเชิงลึกเกี่ยวกับพฤติกรรมและความถี่ของการเกิดขึ้น[ 9 ]ตัวอย่างแสดงอยู่ในรูปสีน้ำเงิน
การประมาณความหนาแน่นเคอร์เนล

ในทางสถิติการประมาณความหนาแน่นเคอร์เนล (KDE) คือการประยุกต์ใช้ การปรับ เรียบเคอร์เนลสำหรับการประมาณความหนาแน่นความน่าจะเป็น กล่าว คือวิธีการที่ไม่ใช้พารามิเตอร์ ใน การประมาณฟังก์ชันความหนาแน่นความน่าจะเป็นของตัวแปรสุ่มโดยใช้เคอร์เนลเป็นน้ำหนัก KDE แก้ปัญหาการปรับเรียบข้อมูลพื้นฐานที่อนุมานเกี่ยวกับประชากรโดยอาศัยตัวอย่าง ข้อมูลที่จำกัด ในบางสาขา เช่นการประมวลผลสัญญาณและเศรษฐศาสตร์เชิง ปริมาณ เรียกอีกอย่างว่า วิธีหน้าต่าง Parzen–Rosenblatt ตามชื่อของEmanuel ParzenและMurray Rosenblattซึ่งโดยทั่วไปแล้วได้รับการยกย่องว่าสร้างวิธีการนี้ขึ้นมาอย่างอิสระในรูปแบบปัจจุบัน[ 10 ] [ 11 ]หนึ่งในการประยุกต์ใช้ที่มีชื่อเสียงของการประมาณความหนาแน่นเคอร์เนลคือการประมาณความหนาแน่นส่วนขอบ แบบมีเงื่อนไขของคลาส ของข้อมูลเมื่อใช้ตัวจำแนกแบบเบย์แบบง่ายซึ่งสามารถปรับปรุงความแม่นยำในการทำนายได้[ 12 ]
ดูเพิ่มเติม
- การแจกแจงความถี่
- การประมาณความหนาแน่นเคอร์เนล
- ข้อผิดพลาดกำลังสองเฉลี่ยแบบบูรณาการ
- ฮิสโตแกรม
- การประมาณความหนาแน่นเคอร์เนลแบบหลายตัวแปร
- การประมาณความหนาแน่นสเปกตรัม
- การฝังเคอร์เนลของการกระจาย
- แบบจำลองเชิงกำเนิด
- การประยุกต์ใช้สถิติเชิงลำดับ: การประมาณความหนาแน่นแบบไม่ใช้พารามิเตอร์
- การปรับการกระจายความน่าจะเป็น
ลิงก์ภายนอก
- CREEM: ศูนย์วิจัยด้านแบบจำลองทางนิเวศวิทยาและสิ่งแวดล้อมดาวน์โหลดซอฟต์แวร์ประเมินความหนาแน่นฟรี ได้แก่Distance 4 (จากหน่วยวิจัยเพื่อการประเมินประชากรสัตว์ป่า "RUWPA") และWiSP
- สรุปเนื้อหาของคลังข้อมูลการเรียนรู้ของเครื่องจักร UCI (ดู "ฐานข้อมูลโรคเบาหวานของชาวอินเดียนแดงเผ่าปิมา" สำหรับชุดข้อมูลต้นฉบับจำนวน 732 รายการ และหมายเหตุเพิ่มเติม)
- โค้ด MATLAB สำหรับการประมาณความหนาแน่นแบบหนึ่งมิติ และ สองมิติ
- ซอฟต์แวร์ libAGF ที่เขียนด้วยภาษา C++ สำหรับ การ ประมาณความหนาแน่นเคอร์เนลแบบแปรผัน
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การประมาณความหนาแน่น
ใน ทางสถิติ การ ประมาณความหนาแน่นของความน่าจะเป็น หรือเรียกง่ายๆ ว่า การประมาณความหนาแน่น คือการสร้าง การประมาณค่า โดยอาศัย ข้อมูล ที่สังเกตได้ ของ ฟังก์ชันความหนาแน่นของความน่าจะ...
ตัวอย่าง
เราจะพิจารณาบันทึกเกี่ยวกับอุบัติการณ์ของ โรคเบาหวาน ข้อความต่อไปนี้คัดลอกมาจาก คำอธิบาย ชุดข้อมูล โดยตรง :
การใช้งานและวัตถุประสงค์
การใช้การประมาณความหนาแน่นที่เป็นธรรมชาติมากอย่างหนึ่งคือการตรวจสอบคุณสมบัติของชุดข้อมูลที่กำหนดอย่างไม่เป็นทางการ การประมาณความหนาแน่นสามารถให้ข้อบ่งชี้ที่มีค่าเกี่ยวกับคุณลักษณะต่างๆ เช่น ความเบี่ยงเบนและความหลากหลายของข้อมูล ในบางกรณี...
การประมาณความหนาแน่นเคอร์เนล
ใน ทางสถิติ การ ประมาณความหนาแน่นเคอร์เนล (KDE) คือการประยุกต์ใช้ การปรับ เรียบเคอร์เนล สำหรับ การประมาณความหนาแน่นความน่าจะเป็น กล่าว คือวิธีการ ที่ไม่ใช้พารามิเตอร์ ใน การประมาณ ฟังก์ชัน ความหนาแน่นความน่าจะเป็น ของ ตัวแปรสุ่ม โดยใช้ เคอร์เนล เป็น น้ำหนัก...