อ่าน 6 นาที
อาร์-ทรี
R-tree คือ โครงสร้างข้อมูลแบบต้นไม้ ที่ใช้สำหรับ วิธีการเข้าถึงเชิงพื้นที่ เช่น การจัดทำดัชนีข้อมูลหลายมิติ เช่น พิกัดทางภูมิศาสตร์ สี่เหลี่ยมผืนผ้าหรือ รูปหลายเหลี่ยม R -tree...
อาร์-ทรี
| อาร์-ทรี | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| พิมพ์ | ต้นไม้ | |||||||||||||||||
| ประดิษฐ์ | พ.ศ. 2527 | |||||||||||||||||
| คิดค้นโดย | อันโตนิน กุตต์มันน์ | |||||||||||||||||
| ||||||||||||||||||

R-treeคือโครงสร้างข้อมูลแบบต้นไม้ที่ใช้สำหรับวิธีการเข้าถึงเชิงพื้นที่เช่น การจัดทำดัชนีข้อมูลหลายมิติ เช่นพิกัดทางภูมิศาสตร์สี่เหลี่ยมผืนผ้าหรือรูปหลายเหลี่ยมR -tree ได้รับการเสนอโดย Antonin Guttman ในปี 1984 [ 2 ]และมีการใช้งานอย่างแพร่หลายทั้งในเชิงทฤษฎีและเชิงประยุกต์[ 3 ]การใช้งานจริงทั่วไปของ R-tree อาจเป็นการจัดเก็บวัตถุเชิงพื้นที่ เช่น ตำแหน่งร้านอาหาร หรือรูปหลายเหลี่ยมที่ใช้สร้างแผนที่ทั่วไป เช่น ถนน อาคาร โครงร่างของทะเลสาบ ชายฝั่ง ฯลฯ จากนั้นค้นหาคำตอบได้อย่างรวดเร็วสำหรับคำถาม เช่น "ค้นหาพิพิธภัณฑ์ทั้งหมดภายในระยะ 2 กม. จากตำแหน่งปัจจุบันของฉัน" "ดึงข้อมูลส่วนของถนนทั้งหมดภายในระยะ 2 กม. จากตำแหน่งของฉัน" (เพื่อแสดงในระบบนำทาง ) หรือ "ค้นหาสถานีบริการน้ำมันที่ใกล้ที่สุด" (แม้ว่าจะไม่ได้คำนึงถึงถนนก็ตาม) R-tree ยังสามารถเร่งความเร็วการค้นหาเพื่อนบ้านที่ใกล้ที่สุด[ 4 ]สำหรับเมตริกระยะทางต่างๆ รวมถึง ระยะทาง วงกลมใหญ่[ 5 ]
แนวคิดต้นไม้ R
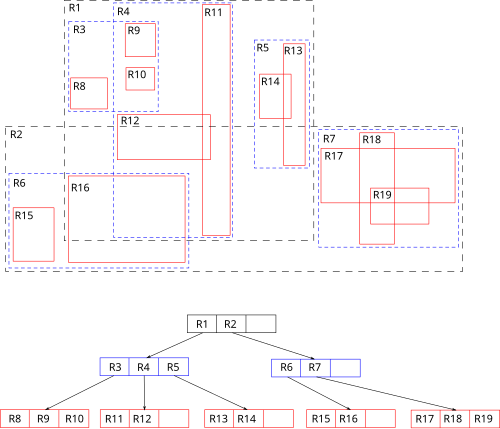
แนวคิดหลักของโครงสร้างข้อมูลนี้คือการจัดกลุ่มวัตถุที่อยู่ใกล้เคียงกันและแทนวัตถุเหล่านั้นด้วยสี่เหลี่ยมผืนผ้าที่ล้อมรอบ วัตถุนั้น ในระดับที่สูงขึ้นไปในโครงสร้างต้นไม้ โดยตัวอักษร "R" ใน R-tree ย่อมาจาก rectangle (สี่เหลี่ยมผืนผ้า) เนื่องจากวัตถุทั้งหมดอยู่ภายในสี่เหลี่ยมผืนผ้าที่ล้อมรอบนี้ การค้นหาที่ไม่ตัดกับสี่เหลี่ยมผืนผ้าที่ล้อมรอบนี้จึงไม่สามารถตัดกับวัตถุใดๆ ที่อยู่ภายในได้ ในระดับใบของต้นไม้ สี่เหลี่ยมผืนผ้าแต่ละอันจะอธิบายถึงวัตถุเพียงชิ้นเดียว ในระดับที่สูงขึ้น การรวมกลุ่มจะครอบคลุมวัตถุจำนวนมากขึ้นเรื่อยๆ ซึ่งอาจมองได้ว่าเป็นการประมาณค่าชุดข้อมูลที่หยาบขึ้นเรื่อยๆ
เช่นเดียวกับB-tree , R-tree ก็เป็นต้นไม้ค้นหาแบบสมดุล (ดังนั้นโหนดใบทั้งหมดจึงอยู่ที่ระดับความลึกเดียวกัน) จัดระเบียบข้อมูลเป็นหน้า และได้รับการออกแบบมาเพื่อจัดเก็บในดิสก์ (ดังที่ใช้ในฐานข้อมูล ) แต่ละหน้าสามารถบรรจุรายการได้สูงสุดจำนวนหนึ่ง ซึ่งมักจะแสดงด้วยสัญลักษณ์นอกจากนี้ยังรับประกันการเติมขั้นต่ำ (ยกเว้นโหนดราก) อย่างไรก็ตาม ประสิทธิภาพที่ดีที่สุดนั้นพบได้เมื่อเติมขั้นต่ำ 30%–40% ของจำนวนรายการสูงสุด (B-tree รับประกันการเติมหน้า 50% และB*-tree รับประกัน ได้ถึง 66%) เหตุผลก็คือการปรับสมดุลที่ซับซ้อนกว่าที่จำเป็นสำหรับข้อมูลเชิงพื้นที่เมื่อเทียบกับข้อมูลเชิงเส้นที่จัดเก็บใน B-tree

เช่นเดียวกับต้นไม้ส่วนใหญ่ อัลกอริทึมการค้นหา (เช่นการหาจุดตัด การหาขอบเขตการหาเพื่อนบ้านที่ใกล้ที่สุด ) ค่อนข้างเรียบง่าย แนวคิดหลักคือการใช้กรอบล้อมรอบเพื่อตัดสินใจว่าจะค้นหาภายในต้นไม้ย่อยหรือไม่ ด้วยวิธีนี้ โหนดส่วนใหญ่ในต้นไม้จะไม่ถูกอ่านในระหว่างการค้นหา เช่นเดียวกับ B-tree, R-tree เหมาะสำหรับชุดข้อมูลขนาดใหญ่และฐานข้อมูลซึ่งสามารถดึงโหนดไปยังหน่วยความจำได้เมื่อจำเป็น และไม่สามารถเก็บต้นไม้ทั้งหมดไว้ในหน่วยความจำหลักได้ แม้ว่าข้อมูลจะสามารถเก็บไว้ในหน่วยความจำ (หรือแคช) ได้ แต่ในแอปพลิเคชันเชิงปฏิบัติส่วนใหญ่ R-tree มักจะให้ประสิทธิภาพที่ดีกว่าการตรวจสอบวัตถุทั้งหมดแบบง่ายๆ เมื่อจำนวนวัตถุมากกว่าสองสามร้อยชิ้น อย่างไรก็ตาม สำหรับแอปพลิเคชันในหน่วยความจำ มีทางเลือกที่คล้ายกันซึ่งสามารถให้ประสิทธิภาพที่ดีกว่าเล็กน้อยหรือใช้งานได้ง่ายกว่าในทางปฏิบัติ เพื่อรักษาการประมวลผลในหน่วยความจำสำหรับ R-tree ในคลัสเตอร์คอมพิวเตอร์ที่โหนดการประมวลผลเชื่อมต่อกันด้วยเครือข่าย นักวิจัยได้ใช้ RDMA ( Remote Direct Memory Access ) เพื่อใช้งานแอปพลิเคชันที่เน้นข้อมูลภายใต้ R-tree ในสภาพแวดล้อมแบบกระจาย[ 6 ]แนวทางนี้สามารถปรับขนาดได้สำหรับแอปพลิเคชันขนาดใหญ่ขึ้นเรื่อยๆ และบรรลุประสิทธิภาพการประมวลผลสูงและความหน่วงต่ำสำหรับ R-tree
ความยากหลักของ R-tree คือการสร้างต้นไม้ที่มีประสิทธิภาพ ซึ่งในด้านหนึ่งต้องมีความสมดุล (เพื่อให้โหนดใบมีความสูงเท่ากัน) ในอีกด้านหนึ่ง สี่เหลี่ยมผืนผ้าไม่ควรครอบคลุมพื้นที่ว่างมากเกินไป และไม่ควรทับซ้อนกันมากเกินไป (เพื่อให้ในระหว่างการค้นหา จะต้องประมวลผลซับทรีน้อยลง) ตัวอย่างเช่น แนวคิดดั้งเดิมสำหรับการแทรกองค์ประกอบเพื่อให้ได้ต้นไม้ที่มีประสิทธิภาพ คือการแทรกเข้าไปในซับทรีที่ต้องการการขยายขอบเขตของกรอบล้อมรอบน้อยที่สุดเสมอ เมื่อหน้านั้นเต็มแล้ว ข้อมูลจะถูกแบ่งออกเป็นสองชุด ซึ่งแต่ละชุดควรครอบคลุมพื้นที่น้อยที่สุด การวิจัยและการปรับปรุง R-tree ส่วนใหญ่มีเป้าหมายเพื่อปรับปรุงวิธีการสร้างต้นไม้ และสามารถแบ่งออกเป็นสองวัตถุประสงค์หลัก ได้แก่ การสร้างต้นไม้ที่มีประสิทธิภาพตั้งแต่เริ่มต้น (เรียกว่าการโหลดแบบกลุ่ม) และการเปลี่ยนแปลงบนต้นไม้ที่มีอยู่แล้ว (การแทรกและการลบ)
R-tree ไม่รับประกันประสิทธิภาพในกรณีที่เลวร้ายที่สุดที่ ดี แต่โดยทั่วไปแล้วจะทำงานได้ดีกับข้อมูลในโลกแห่งความเป็นจริง[ 7 ] R-tree รูปแบบ Priority R-tree (แบบโหลดจำนวนมาก) มีประสิทธิภาพดีที่สุดในกรณีที่เลวร้ายที่สุด[ 8 ]แต่เนื่องจากความซับซ้อนที่เพิ่มขึ้น จึงยังคงจำกัดอยู่เฉพาะการศึกษาเชิงทฤษฎีและไม่ได้รับความสนใจมากนักในการใช้งานจริง
เมื่อข้อมูลถูกจัดระเบียบใน R-tree เพื่อนบ้านภายในระยะทางที่กำหนด r และเพื่อนบ้านที่ใกล้ที่สุด k ราย (สำหรับL p -Norm ใดๆ ) ของจุดทั้งหมดสามารถคำนวณได้อย่างมีประสิทธิภาพโดยใช้การเชื่อมต่อเชิงพื้นที่[ 9 ] [ 10 ]ซึ่งเป็นประโยชน์สำหรับอัลกอริธึมหลายตัวที่ใช้การสอบถามดังกล่าว เช่นLocal Outlier Factor DeLi-Clu [ 11 ] Density-Link-Clustering เป็น อัลกอริธึม การวิเคราะห์คลัสเตอร์ที่ใช้โครงสร้าง R-tree สำหรับการเชื่อมต่อเชิงพื้นที่ในลักษณะเดียวกันเพื่อคำนวณการจัดกลุ่ม OPTICS ได้อย่างมีประสิทธิภาพ
ตัวแปร
อัลกอริทึม
การจัดวางข้อมูล
ข้อมูลใน R-tree ถูกจัดระเบียบเป็นหน้าๆ ซึ่งแต่ละหน้าสามารถมีจำนวนรายการได้หลากหลาย (ไม่เกินจำนวนสูงสุดที่กำหนดไว้ล่วงหน้า และโดยปกติจะต้องมากกว่าจำนวนขั้นต่ำที่กำหนด) แต่ละรายการภายในโหนดที่ไม่ใช่โหนดใบจะเก็บข้อมูลสองส่วน ได้แก่ วิธีระบุโหนดลูกและกรอบสี่เหลี่ยมที่ล้อมรอบรายการทั้งหมดภายในโหนดลูกนั้น โหนดใบจะเก็บข้อมูลที่จำเป็นสำหรับโหนดลูกแต่ละโหนด ซึ่งมักจะเป็นจุดหรือกรอบสี่เหลี่ยมที่แสดงถึงโหนดลูก และตัวระบุภายนอกสำหรับโหนดลูกนั้น สำหรับข้อมูลจุด รายการในโหนดใบอาจเป็นเพียงจุดเหล่านั้น สำหรับข้อมูลรูปหลายเหลี่ยม (ซึ่งมักต้องจัดเก็บรูปหลายเหลี่ยมขนาดใหญ่) การตั้งค่าทั่วไปคือการจัดเก็บเฉพาะ MBR (สี่เหลี่ยมผืนผ้าล้อมรอบขั้นต่ำ) ของรูปหลายเหลี่ยมพร้อมกับตัวระบุที่ไม่ซ้ำกันในโครงสร้างต้นไม้
ค้นหา
กระบวนการค้นหาในโครงสร้าง R-tree ประกอบด้วยสองขั้นตอนที่สอดคล้องกับหลักการกรองและปรับปรุง (Filter and Refine Principle: FRP)ในโครงสร้างนี้ โหนดภายในทำหน้าที่เป็นตัวกรองเบื้องต้นโดยการตัดพื้นที่ที่ไม่ตัดกับคำค้นหาออกอย่างรวดเร็ว ในขณะที่โหนดใบจะให้การประเมินที่แม่นยำและละเอียดขึ้นโดยการจัดเก็บวัตถุเชิงพื้นที่จริง
โดยเฉพาะอย่างยิ่ง ในการค้นหาแบบช่วง (range searching ) ข้อมูลที่ป้อนเข้าคือสี่เหลี่ยมค้นหา (Query box) การค้นหาจะคล้ายกับการค้นหาในB+ tree มาก การค้นหาเริ่มต้นจากโหนดรากของต้นไม้ โหนดภายในแต่ละโหนดจะมีชุดของสี่เหลี่ยมและตัวชี้ไปยังโหนดลูกที่เกี่ยวข้อง และโหนดใบแต่ละโหนดจะมีสี่เหลี่ยมของวัตถุเชิงพื้นที่ (อาจมีตัวชี้ไปยังวัตถุเชิงพื้นที่อยู่ด้วย) สำหรับสี่เหลี่ยมแต่ละรูปในโหนด จะต้องพิจารณาว่ามันทับซ้อนกับสี่เหลี่ยมค้นหาหรือไม่ ถ้าใช่ จะต้องค้นหาในโหนดลูกที่เกี่ยวข้องด้วย การค้นหาจะทำซ้ำแบบนี้ไปเรื่อยๆ จนกว่าจะสำรวจโหนดที่ทับซ้อนกันทั้งหมด เมื่อถึงโหนดใบแล้ว กล่องขอบเขต (สี่เหลี่ยม) ที่อยู่ภายในจะถูกตรวจสอบกับสี่เหลี่ยมค้นหา และวัตถุ (ถ้ามี) จะถูกใส่ลงในชุดผลลัพธ์หากวัตถุนั้นอยู่ภายในสี่เหลี่ยมค้นหา
สำหรับการค้นหาลำดับความสำคัญ เช่นการค้นหาเพื่อนบ้านที่ใกล้ที่สุดแบบสอบถามประกอบด้วยจุดหรือสี่เหลี่ยมผืนผ้า โหนดรากจะถูกแทรกเข้าไปในคิวลำดับความสำคัญ การค้นหาจะดำเนินต่อไปจนกว่าคิวจะว่างเปล่าหรือได้ผลลัพธ์ตามจำนวนที่ต้องการ โดยการประมวลผลรายการที่ใกล้ที่สุดในคิว โหนดต้นไม้จะถูกขยายและแทรกโหนดลูกกลับเข้าไป รายการใบจะถูกส่งคืนเมื่อพบในคิว[ 12 ]วิธีการนี้สามารถใช้ได้กับเมตริกระยะทางต่างๆ รวมถึงระยะทางวงกลมใหญ่สำหรับข้อมูลทางภูมิศาสตร์[ 5 ]
การแทรก
ในการแทรกวัตถุ ระบบจะทำการสำรวจโครงสร้างต้นไม้แบบเรียกซ้ำ โดยเริ่มจากโหนดราก ในแต่ละขั้นตอน ระบบจะตรวจสอบสี่เหลี่ยมทั้งหมดในโหนดไดเร็กทอรีปัจจุบัน และเลือกตัวเลือกโดยใช้หลักการเชิงอนุมาน เช่น การเลือกสี่เหลี่ยมที่ต้องการการขยายขนาดน้อยที่สุด จากนั้นการค้นหาจะลงไปในหน้านี้จนกว่าจะถึงโหนดใบ หากโหนดใบเต็ม จะต้องทำการแบ่งโหนดก่อนที่จะทำการแทรก เนื่องจากวิธีการค้นหาแบบครบถ้วนนั้นมีค่าใช้จ่ายสูงเกินไป จึงใช้หลักการเชิงอนุมานในการแบ่งโหนดออกเป็นสองส่วน การเพิ่มโหนดที่สร้างขึ้นใหม่ลงในระดับก่อนหน้า ระดับนี้สามารถล้นได้อีกครั้ง และการล้นเหล่านี้สามารถแพร่กระจายขึ้นไปยังโหนดราก เมื่อโหนดรากนี้ล้นอีกครั้ง โหนดรากใหม่จะถูกสร้างขึ้น และความสูงของต้นไม้จะเพิ่มขึ้น
การเลือกซับทรีการแทรก
อัลกอริทึมจำเป็นต้องตัดสินใจว่าจะแทรกข้อมูลลงในซับทรีใด เมื่อวัตถุข้อมูลถูกบรรจุอยู่ในสี่เหลี่ยมผืนผ้าเพียงรูปเดียว การเลือกก็ชัดเจน แต่เมื่อมีตัวเลือกหรือสี่เหลี่ยมผืนผ้าหลายรูปที่ต้องการขยาย การเลือกนั้นอาจส่งผลกระทบอย่างมากต่อประสิทธิภาพของทรี
วัตถุจะถูกแทรกเข้าไปในซับทรีที่ต้องการการขยายขนาดน้อยที่สุด มีการใช้ฮิวริสติกแบบผสมตลอดทั้งกระบวนการ สิ่งที่เกิดขึ้นต่อไปคือ มันจะพยายามลดการทับซ้อนให้น้อยที่สุด (ในกรณีที่มีค่าเท่ากัน จะเลือกการขยายขนาดน้อยที่สุดก่อน แล้วจึงเลือกพื้นที่น้อยที่สุด) ในระดับที่สูงขึ้น มันจะทำงานคล้ายกับ R-tree แต่ในกรณีที่มีค่าเท่ากันอีกครั้ง จะเลือกซับทรีที่มีพื้นที่น้อยกว่า การลดการทับซ้อนของสี่เหลี่ยมในR*-treeเป็นหนึ่งในข้อดีที่สำคัญเหนือ R-tree แบบดั้งเดิม
การแบ่งโหนดที่ล้น
เนื่องจากการกระจายวัตถุทั้งหมดของโหนดหนึ่งไปยังสองโหนดนั้นมีตัวเลือกจำนวนมหาศาล จึงจำเป็นต้องใช้ฮิวริสติกเพื่อหาการแบ่งที่ดีที่สุด ใน R-tree แบบคลาสสิก Guttman ได้เสนอฮิวริสติกสองแบบ ได้แก่ QuadraticSplit และ LinearSplit ในการแบ่งแบบ QuadraticSplit อัลกอริทึมจะค้นหาคู่ของสี่เหลี่ยมผืนผ้าที่เป็นชุดค่าผสมที่แย่ที่สุดที่จะมีอยู่ในโหนดเดียวกัน และใส่เป็นวัตถุเริ่มต้นในสองกลุ่มใหม่ จากนั้นจะค้นหาข้อมูลที่มีความชอบมากที่สุดสำหรับกลุ่มใดกลุ่มหนึ่ง (ในแง่ของการเพิ่มพื้นที่) และกำหนดวัตถุนั้นให้กับกลุ่มนั้นจนกว่าวัตถุทั้งหมดจะถูกกำหนด (เพื่อให้เป็นไปตามเงื่อนไขการเติมขั้นต่ำ)
มีกลยุทธ์การแบ่งแยกอื่นๆ เช่น การแบ่งแยกของ Greene [ 13 ]ฮิวริสติกการแบ่งแยกR*-tree [ 14 ] (ซึ่งพยายามลดการทับซ้อนให้น้อยที่สุด แต่ก็ชอบหน้ากำลังสอง) หรืออัลกอริทึมการแบ่งแยกเชิงเส้นที่เสนอโดย Ang และ Tan [ 15 ] (ซึ่งอย่างไรก็ตามสามารถสร้างรูปสี่เหลี่ยมผืนผ้าที่ไม่สม่ำเสมอมาก ซึ่งมีประสิทธิภาพน้อยกว่าสำหรับการค้นหาช่วงและหน้าต่างในโลกแห่งความเป็นจริงหลายๆ อย่าง) นอกเหนือจากการมีฮิวริสติกการแบ่งแยกขั้นสูงกว่าแล้วR*-treeยังพยายามหลีกเลี่ยงการแบ่งโหนดโดยการแทรกสมาชิกโหนดบางส่วนกลับเข้าไปใหม่ ซึ่งคล้ายกับวิธีที่B-treeปรับสมดุลโหนดที่ล้นเกิน วิธีนี้แสดงให้เห็นว่าช่วยลดการทับซ้อนและเพิ่มประสิทธิภาพของต้นไม้ได้เช่นกัน
สุดท้ายX-tree [ 16 ]สามารถมองได้ว่าเป็น R*-tree รูปแบบหนึ่งที่สามารถตัดสินใจไม่แยกโหนด แต่สร้างสิ่งที่เรียกว่า super-node ที่มีรายการพิเศษทั้งหมด เมื่อไม่พบการแยกที่ดี (โดยเฉพาะอย่างยิ่งสำหรับข้อมูลที่มีมิติสูง)
 การแบ่งกำลังสองของ Guttman [ 2 ]หน้าในต้นไม้นี้ทับซ้อนกันมาก
การแบ่งกำลังสองของ Guttman [ 2 ]หน้าในต้นไม้นี้ทับซ้อนกันมาก การแยกเชิงเส้นของ Guttman [ 2 ]โครงสร้างที่แย่กว่านั้นอีก แต่ก็สร้างได้เร็วกว่าเช่นกัน
การแยกเชิงเส้นของ Guttman [ 2 ]โครงสร้างที่แย่กว่านั้นอีก แต่ก็สร้างได้เร็วกว่าเช่นกัน การแยกของกรีน[ 13 ]หน้าทับซ้อนกันน้อยกว่ามากเมื่อเทียบกับกลยุทธ์ของกัตต์แมน
การแยกของกรีน[ 13 ]หน้าทับซ้อนกันน้อยกว่ามากเมื่อเทียบกับกลยุทธ์ของกัตต์แมน การแบ่งเชิงเส้นแบบ Ang-Tan [ 15 ]กลยุทธ์นี้สร้างหน้าที่ถูกแบ่ง ซึ่งมักจะส่งผลให้ประสิทธิภาพการค้นหาไม่ดี
การแบ่งเชิงเส้นแบบ Ang-Tan [ 15 ]กลยุทธ์นี้สร้างหน้าที่ถูกแบ่ง ซึ่งมักจะส่งผลให้ประสิทธิภาพการค้นหาไม่ดี การแบ่งโทโพโลยีของต้นไม้ R* [ 14 ]หน้าต่างๆ ทับซ้อนกันน้อยลงมาก เนื่องจากต้นไม้ R* พยายามลดการทับซ้อนของหน้าให้น้อยที่สุด และการแทรกใหม่ยังช่วยปรับต้นไม้ให้เหมาะสมยิ่งขึ้น กลยุทธ์การแบ่งนี้ชอบหน้ากำลังสอง ซึ่งให้ประสิทธิภาพที่ดีกว่าสำหรับแอปพลิเคชันแผนที่ทั่วไป
การแบ่งโทโพโลยีของต้นไม้ R* [ 14 ]หน้าต่างๆ ทับซ้อนกันน้อยลงมาก เนื่องจากต้นไม้ R* พยายามลดการทับซ้อนของหน้าให้น้อยที่สุด และการแทรกใหม่ยังช่วยปรับต้นไม้ให้เหมาะสมยิ่งขึ้น กลยุทธ์การแบ่งนี้ชอบหน้ากำลังสอง ซึ่งให้ประสิทธิภาพที่ดีกว่าสำหรับแอปพลิเคชันแผนที่ทั่วไป สร้างโครงสร้างข้อมูลแบบ R* จำนวน มาก โดยใช้ Sort-Tile-Recursive (STR) หน้าใบจะไม่ทับซ้อนกันเลย และหน้าไดเร็กทอรีจะทับซ้อนกันเพียงเล็กน้อย โครงสร้างข้อมูลแบบนี้มีประสิทธิภาพสูง แต่ต้องทราบข้อมูลทั้งหมดล่วงหน้าก่อน
สร้างโครงสร้างข้อมูลแบบ R* จำนวน มาก โดยใช้ Sort-Tile-Recursive (STR) หน้าใบจะไม่ทับซ้อนกันเลย และหน้าไดเร็กทอรีจะทับซ้อนกันเพียงเล็กน้อย โครงสร้างข้อมูลแบบนี้มีประสิทธิภาพสูง แต่ต้องทราบข้อมูลทั้งหมดล่วงหน้าก่อน M-treeมีลักษณะคล้ายกับ R-tree แต่ใช้เพจทรงกลมแบบซ้อนกันอย่างไรก็ตาม การแบ่งเพจเหล่านี้มีความซับซ้อนกว่ามาก และโดยทั่วไปแล้วเพจจะทับซ้อนกันมากกว่า
M-treeมีลักษณะคล้ายกับ R-tree แต่ใช้เพจทรงกลมแบบซ้อนกันอย่างไรก็ตาม การแบ่งเพจเหล่านี้มีความซับซ้อนกว่ามาก และโดยทั่วไปแล้วเพจจะทับซ้อนกันมากกว่า







การลบ
การลบรายการออกจากหน้าอาจต้องอัปเดตกรอบสี่เหลี่ยมของหน้าแม่ อย่างไรก็ตาม เมื่อหน้าใดหน้าหนึ่งมีพื้นที่ไม่เพียงพอ ระบบจะไม่ปรับสมดุลกับหน้าข้างเคียง แต่หน้านั้นจะถูกยุบ และรายการย่อยทั้งหมด (ซึ่งอาจเป็นซับทรี ไม่ใช่แค่โหนดใบ) จะถูกแทรกกลับเข้าไปใหม่ หากในระหว่างกระบวนการนี้ โหนดรากมีองค์ประกอบเพียงรายการเดียว ความสูงของทรีอาจลดลง
การขนถ่ายจำนวนมาก
- Nearest-X: วัตถุจะถูกจัดเรียงตามพิกัดแรก ("X") จากนั้นจะถูกแบ่งออกเป็นหน้าๆ ตามขนาดที่ต้องการ
- Packed Hilbert R-tree : รูปแบบหนึ่งของ Nearest-X แต่ใช้ค่า Hilbert ของจุดศูนย์กลางของสี่เหลี่ยมผืนผ้าในการเรียงลำดับแทนที่จะใช้พิกัด X ไม่มีการรับประกันว่าหน้าต่างๆ จะไม่ทับซ้อนกัน
- Sort-Tile-Recursive (STR): [ 17 ]รูปแบบอื่นของ Nearest-X ซึ่งประมาณจำนวนใบทั้งหมดที่ต้องการเป็นปัจจัยการแบ่งที่จำเป็นในแต่ละมิติเพื่อให้ได้สิ่งนี้เป็น จากนั้นแบ่งแต่ละมิติออกเป็นพาร์ติชันที่มีขนาดเท่ากันซ้ำๆโดยใช้การเรียงลำดับแบบ 1 มิติ หน้าที่ได้ หากครอบครองมากกว่าหนึ่งหน้า จะถูกโหลดแบบกลุ่มอีกครั้งโดยใช้อัลกอริทึมเดียวกัน สำหรับข้อมูลจุด โหนดใบจะไม่ทับซ้อนกัน และจะ "แบ่ง" พื้นที่ข้อมูลออกเป็นหน้าที่มีขนาดเท่ากันโดยประมาณ
- การลดการทับซ้อนจากบนลงล่าง (OMT): [ 18 ]การปรับปรุงเหนือ STR โดยใช้แนวทางจากบนลงล่างซึ่งลดการทับซ้อนระหว่างส่วนต่างๆ และปรับปรุงประสิทธิภาพการค้นหา
- ลำดับความสำคัญ R-tree



ดูเพิ่มเติม
- ต้นไม้เซกเมนต์
- ต้นไม้ช่วงเวลา (Interval tree) – โครงสร้างต้นไม้ R-tree ที่ลดรูปแล้ว สำหรับมิติเดียว (โดยปกติคือเวลา)
- ต้นไม้ Kd
- ลำดับชั้นปริมาตรล้อมรอบ
- ดัชนีเชิงพื้นที่
- กิสท์
- กรองและปรับปรุง
ลิงก์ภายนอก
 สื่อที่เกี่ยวข้องกับR-treeใน Wikimedia Commons
สื่อที่เกี่ยวข้องกับR-treeใน Wikimedia Commons
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ อาร์-ทรี
R-tree คือ โครงสร้างข้อมูลแบบต้นไม้ ที่ใช้สำหรับ วิธีการเข้าถึงเชิงพื้นที่ เช่น การจัดทำดัชนีข้อมูลหลายมิติ เช่น พิกัดทางภูมิศาสตร์ สี่เหลี่ยมผืนผ้าหรือ รูปหลายเหลี่ยม R -tree...
แนวคิดต้นไม้ R
แนวคิดหลักของโครงสร้างข้อมูลนี้คือการจัดกลุ่มวัตถุที่อยู่ใกล้เคียงกันและแทนวัตถุเหล่านั้นด้วย สี่เหลี่ยมผืนผ้าที่ล้อมรอบ วัตถุนั้น ในระดับที่สูงขึ้นไปในโครงสร้างต้นไม้ โดยตัวอักษร "R" ใน R-tree ย่อมาจาก rectangle (สี่เหลี่ยมผืนผ้า)...
ตัวแปร
ลำดับความสำคัญ R-tree R*-tree ต้นไม้ R+ ต้นไม้ R ของฮิลเบิร์ต เอ็กซ์ทรี
การจัดวางข้อมูล
ข้อมูลใน R-tree ถูกจัดระเบียบเป็นหน้าๆ ซึ่งแต่ละหน้าสามารถมีจำนวนรายการได้หลากหลาย (ไม่เกินจำนวนสูงสุดที่กำหนดไว้ล่วงหน้า และโดยปกติจะต้องมากกว่าจำนวนขั้นต่ำที่กำหนด) แต่ละรายการภายใน โหนดที่ไม่ใช่โหนดใบ จะเก็บข้อมูลสองส่วน ได้แก่ วิธีระบุ โหนดลูก และ...