อ่าน 7 นาที
แผนผังการตัดสินใจ
แผนผังการตัดสินใจ (Decision Tree ) เป็น โครงสร้างการแบ่งส่วนแบบเรียกซ้ำ เพื่อสนับสนุนการ ตัดสินใจ โดยใช้แบบจำลองคล้ายต้นไม้ ของการตัดสินใจและผลลัพธ์ที่เป็นไปได้ รวมถึง...
แผนผังการตัดสินใจ


แผนผังการตัดสินใจ (Decision Tree ) เป็น โครงสร้างการแบ่งส่วนแบบเรียกซ้ำ เพื่อสนับสนุนการ ตัดสินใจ โดยใช้แบบจำลองคล้ายต้นไม้ ของการตัดสินใจและผลลัพธ์ที่เป็นไปได้ รวมถึง ผลลัพธ์ของเหตุการณ์ โดยบังเอิญต้นทุนทรัพยากร และอรรถประโยชน์เป็นวิธีหนึ่งในการแสดงอัลกอริทึมที่ประกอบด้วยคำสั่งควบคุมแบบมีเงื่อนไขเท่านั้น
ต้นไม้ตัดสินใจมักใช้ในการวิจัยการดำเนินงานโดยเฉพาะในการวิเคราะห์การตัดสินใจ [ 1 ] เพื่อช่วยระบุกลยุทธ์ที่มีแนวโน้มมากที่สุดที่จะบรรลุเป้าหมาย แต่ยังเป็นเครื่องมือที่ได้รับความนิยมในการเรียนรู้ของเครื่องอีก ด้วย
ภาพรวม
แผนผังการตัดสินใจ (Decision Tree) เป็น โครงสร้างคล้าย ผังงาน (Flowchart)ที่แต่ละโหนดภายในแทนการทดสอบคุณลักษณะ (เช่น การโยนเหรียญจะได้หัวหรือก้อย) แต่ละกิ่งแทนผลลัพธ์ของการทดสอบ และแต่ละโหนดใบแทนป้ายกำกับคลาส (การตัดสินใจหลังจากคำนวณคุณลักษณะทั้งหมดแล้ว) เส้นทางจากโหนดรากไปยังโหนดใบแทนกฎ การจำแนกประเภท
ในการวิเคราะห์การตัดสินใจแผนผังการตัดสินใจและแผนภาพอิทธิพล ที่เกี่ยวข้องอย่างใกล้ชิด ถูกนำมาใช้เป็นเครื่องมือสนับสนุนการตัดสินใจเชิงภาพและเชิงวิเคราะห์ โดยจะคำนวณ ค่าที่คาดหวัง (หรืออรรถประโยชน์ที่คาดหวัง ) ของทางเลือกต่างๆ ที่แข่งขันกัน
ต้นไม้ตัดสินใจประกอบด้วยโหนดสามประเภท: [ 2 ]
- จุดตัดสินใจ – โดยทั่วไปจะแสดงด้วยรูปสี่เหลี่ยม
- จุดความน่าจะเป็น – โดยทั่วไปจะแสดงด้วยวงกลม
- จุดปลาย – โดยทั่วไปมักแสดงด้วยรูปสามเหลี่ยม
แผนผังการตัดสินใจมักใช้ในงานวิจัยเชิงปฏิบัติการและการจัดการเชิงปฏิบัติการหากในทางปฏิบัติจำเป็นต้องตัดสินใจแบบออนไลน์โดยไม่มีการเรียกคืนข้อมูลภายใต้ความรู้ที่ไม่สมบูรณ์ แผนผังการตัดสินใจควรใช้ควบคู่ไปกับ แบบจำลอง ความน่าจะ เป็นในฐานะ แบบจำลองทางเลือกที่ดีที่สุดหรืออัลกอริธึม แบบจำลองการเลือกแบบออนไลน์ การใช้งานอีกอย่างหนึ่งของแผนผังการตัดสินใจคือการ ใช้ เป็นวิธีการเชิงพรรณนาสำหรับการคำนวณความน่าจะเป็นแบบมีเงื่อนไข
แผนผังการตัดสินใจแผนภาพอิทธิพลฟังก์ชันอรรถประโยชน์และเครื่องมือและวิธีการวิเคราะห์การตัดสินใจ อื่นๆ ได้รับการสอนให้กับนักศึกษาระดับปริญญาตรีในโรงเรียนธุรกิจ เศรษฐศาสตร์สุขภาพ และสาธารณสุข และเป็นตัวอย่างของวิธีการวิจัยเชิงปฏิบัติการหรือวิทยาศาสตร์ การจัดการเครื่องมือเหล่านี้ยังใช้ในการทำนายการตัดสินใจของเจ้าของบ้านในสถานการณ์ปกติและสถานการณ์ฉุกเฉิน[ 3 ] [ 4 ]
ส่วนประกอบพื้นฐานของแผนผังการตัดสินใจ
องค์ประกอบของแผนผังการตัดสินใจ
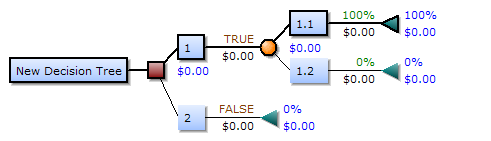
เมื่อวาดจากซ้ายไปขวา แผนผังการตัดสินใจจะมีเฉพาะโหนดแตกแขนง (เส้นทางที่แยกออก) แต่ไม่มีโหนดรวม (เส้นทางที่บรรจบกัน) ดังนั้นหากใช้การวาดด้วยมือ แผนผังอาจมีขนาดใหญ่มากและมักยากที่จะวาดให้เสร็จสมบูรณ์ด้วยมือ ในอดีต แผนผังการตัดสินใจถูกสร้างขึ้นด้วยมือ – ดังตัวอย่างที่แสดงไว้ด้านข้าง – แม้ว่าในปัจจุบันจะมีการใช้ซอฟต์แวร์เฉพาะทางมากขึ้นก็ตาม
กฎการตัดสินใจ
ต้นไม้ตัดสินใจสามารถแปลงเป็นกฎการตัดสินใจเชิงเส้นได้[ 5 ]โดยผลลัพธ์คือเนื้อหาของโหนดใบ และเงื่อนไขตามเส้นทางจะก่อให้เกิดการเชื่อมโยงในข้อความ if โดยทั่วไป กฎจะมีรูปแบบดังนี้:
- ถ้าเงื่อนไขที่ 1 และเงื่อนไขที่ 2 และเงื่อนไขที่ 3 แล้วผลลัพธ์จะเป็นอย่างไร
กฎการตัดสินใจสามารถสร้างขึ้นได้โดยการสร้างกฎความสัมพันธ์กับตัวแปรเป้าหมายทางด้านขวา นอกจากนี้ยังสามารถระบุความสัมพันธ์เชิงเวลาหรือเชิงสาเหตุได้อีกด้วย[ 6 ]
แผนผังการตัดสินใจโดยใช้สัญลักษณ์ผังงาน
โดยทั่วไปแล้ว แผนผังการตัดสินใจมักวาดโดยใช้ สัญลักษณ์ ผังงานเนื่องจากอ่านและเข้าใจได้ง่ายกว่าสำหรับหลายๆ คน โปรดสังเกตว่ามีข้อผิดพลาดเชิงแนวคิดในการคำนวณ "ดำเนินการต่อ" ในแผนผังที่แสดงด้านล่าง ข้อผิดพลาดนี้เกี่ยวข้องกับการคำนวณ "ค่าใช้จ่าย" ที่ได้รับในคดีความ
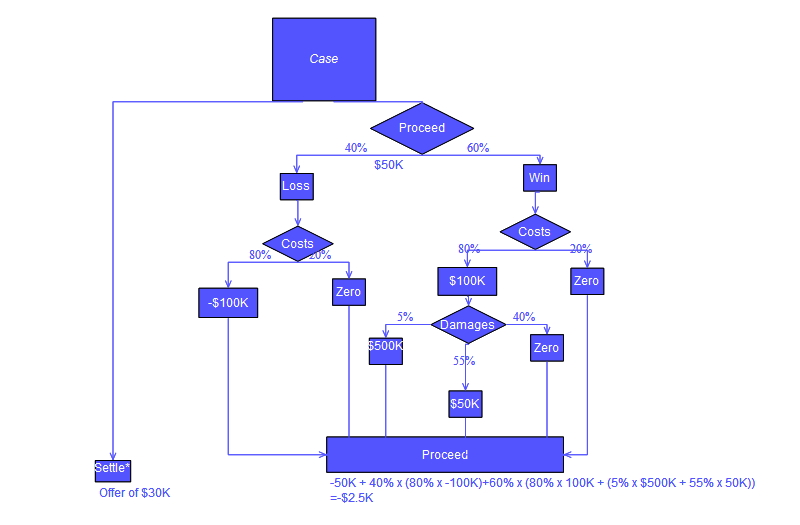
ตัวอย่างการวิเคราะห์
การวิเคราะห์สามารถคำนึงถึงความชอบหรือ ฟังก์ชันอรรถประโยชน์ของผู้ตัดสินใจ (เช่น บริษัท) ได้ ตัวอย่างเช่น:
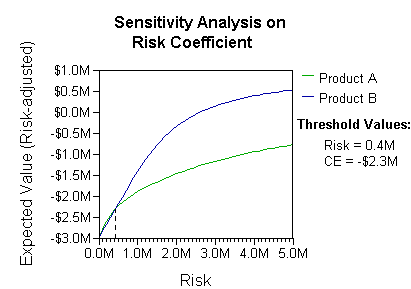
การตีความพื้นฐานในสถานการณ์นี้คือ บริษัทชอบความเสี่ยงและผลตอบแทนของ B มากกว่า ภายใต้ค่าสัมประสิทธิ์ความชอบความเสี่ยงที่สมจริง (มากกว่า 400,000 ดอลลาร์สหรัฐฯ ซึ่งในระดับความไม่ชอบความเสี่ยงดังกล่าว บริษัทจะต้องสร้างแบบจำลองกลยุทธ์ที่สาม คือ "ไม่เอาทั้ง A และ B")
อีกตัวอย่างหนึ่งที่ใช้กันทั่วไปใน หลักสูตร การวิจัยปฏิบัติการคือการกระจายเจ้าหน้าที่กู้ภัยบนชายหาด (หรือที่รู้จักกันในชื่อตัวอย่าง "ชีวิตคือชายหาด") [ 7 ]ตัวอย่างนี้อธิบายถึงชายหาดสองแห่งที่มีเจ้าหน้าที่กู้ภัยกระจายอยู่ตามชายหาดแต่ละแห่ง มีงบประมาณสูงสุดBที่สามารถกระจายระหว่างชายหาดทั้งสองแห่ง (โดยรวม) และโดยใช้ตารางผลตอบแทนส่วนเพิ่ม นักวิเคราะห์สามารถตัดสินใจได้ว่าจะจัดสรรเจ้าหน้าที่กู้ภัยให้กับชายหาดแต่ละแห่งจำนวนเท่าใด
| มีเจ้าหน้าที่รักษาความปลอดภัยประจำชายหาดแต่ละแห่ง | ป้องกันเหตุการณ์จมน้ำได้ทั้งหมด ณ ชายหาดหมายเลข 1 | ป้องกันเหตุการณ์จมน้ำได้ทั้งหมด ณ ชายหาดแห่งที่ 2 |
|---|---|---|
| 1 | 3 | 1 |
| 2 | 0 | 4 |
ในตัวอย่างนี้ สามารถวาดแผนผังการตัดสินใจเพื่อแสดงหลักการของผลตอบแทนที่ลดลงสำหรับชายหาดหมายเลข 1 ได้

แผนผังการตัดสินใจแสดงให้เห็นว่า เมื่อจัดสรรเจ้าหน้าที่กู้ภัยตามลำดับ การวางเจ้าหน้าที่กู้ภัยคนแรกไว้ที่ชายหาดหมายเลข 1 จะเหมาะสมที่สุดหากมีงบประมาณสำหรับเจ้าหน้าที่กู้ภัยเพียงคนเดียว แต่หากมีงบประมาณสำหรับเจ้าหน้าที่กู้ภัยสองคน การวางเจ้าหน้าที่กู้ภัยทั้งสองคนไว้ที่ชายหาดหมายเลข 2 จะช่วยป้องกันการจมน้ำได้มากกว่าโดยรวม

แผนภาพอิทธิพล
ข้อมูลส่วนใหญ่ในแผนผังการตัดสินใจสามารถแสดงได้อย่างกระชับยิ่งขึ้นในรูปแบบแผนภาพอิทธิพลโดยเน้นที่ประเด็นและความสัมพันธ์ระหว่างเหตุการณ์ต่างๆ
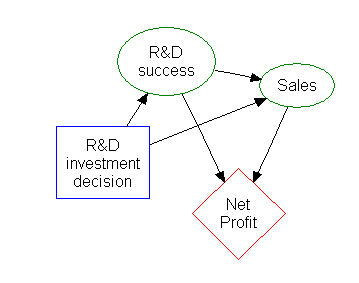
การเหนี่ยวนำกฎความสัมพันธ์
ต้นไม้ตัดสินใจยังสามารถมองได้ว่าเป็นแบบจำลองการสร้างกฎการเหนี่ยวนำจากข้อมูลเชิงประจักษ์ ต้นไม้ตัดสินใจที่เหมาะสมที่สุดจะถูกกำหนดให้เป็นต้นไม้ที่อธิบายข้อมูลส่วนใหญ่ในขณะที่ลดจำนวนระดับ (หรือ "คำถาม") ให้น้อยที่สุด[ 8 ]มีการคิดค้นอัลกอริธึมหลายตัวเพื่อสร้างต้นไม้ที่เหมาะสมที่สุดดังกล่าว เช่นID3 /4/5 [ 9 ] CLS, ASSISTANT และ CART
ข้อดีและข้อเสีย
ในบรรดาเครื่องมือสนับสนุนการตัดสินใจ แผนผังการตัดสินใจ (และแผนภาพอิทธิพล ) มีข้อดีหลายประการ แผนผังการตัดสินใจ:
- เข้าใจง่ายและตีความได้ง่าย ผู้คนสามารถเข้าใจแบบจำลองแผนผังการตัดสินใจได้หลังจากคำอธิบายสั้นๆ
- แม้จะมีข้อมูลเชิงประจักษ์น้อยก็ยังมีคุณค่า ข้อมูลเชิงลึกที่สำคัญสามารถสร้างขึ้นได้จากคำอธิบายของผู้เชี่ยวชาญเกี่ยวกับสถานการณ์ (ทางเลือก ความน่าจะเป็น และต้นทุน) และความเห็นของพวกเขาเกี่ยวกับผลลัพธ์ที่ต้องการ
- ช่วยกำหนดค่าที่แย่ที่สุด ดีที่สุด และค่าที่คาดหวังสำหรับสถานการณ์ต่างๆ
- ใช้ โมเดล แบบกล่องขาวหากผลลัพธ์ที่กำหนดได้มาจากโมเดล
- สามารถนำไปใช้ร่วมกับเทคนิคการตัดสินใจอื่นๆ ได้
- สามารถพิจารณาการกระทำของผู้มีอำนาจตัดสินใจมากกว่าหนึ่งคนได้
ข้อเสียของแผนผังการตัดสินใจ:
- โครงสร้างเหล่านี้ไม่เสถียร หมายความว่าการเปลี่ยนแปลงเล็กน้อยในข้อมูลอาจนำไปสู่การเปลี่ยนแปลงครั้งใหญ่ในโครงสร้างของแผนผังการตัดสินใจที่เหมาะสมที่สุด
- โดยทั่วไปแล้วแบบจำลองเหล่านี้มักไม่แม่นยำนัก ตัวทำนายอื่นๆ จำนวนมากทำงานได้ดีกว่าเมื่อใช้กับข้อมูลที่คล้ายคลึงกัน ปัญหานี้สามารถแก้ไขได้โดยการแทนที่ต้นไม้ตัดสินใจเดี่ยวด้วยป่าสุ่มของต้นไม้ตัดสินใจ แต่ป่าสุ่มนั้นตีความได้ยากกว่าต้นไม้ตัดสินใจเดี่ยว
- สำหรับข้อมูลที่มีตัวแปรเชิงหมวดหมู่ที่มีจำนวนระดับต่างกันการได้รับข้อมูลในต้นไม้ตัดสินใจจะเอนเอียงไปทางคุณลักษณะที่มีระดับมากกว่า[ 10 ]
- การคำนวณอาจมีความซับซ้อนมาก โดยเฉพาะอย่างยิ่งหากค่าหลายค่าไม่แน่นอน และ/หรือหากผลลัพธ์หลายอย่างมีความเชื่อมโยงกัน
การปรับปรุงต้นไม้ตัดสินใจให้เหมาะสมที่สุด
เมื่อต้องการปรับปรุงความแม่นยำของตัวจำแนกประเภทด้วยต้นไม้ตัดสินใจ ควรพิจารณาหลายสิ่งหลายอย่าง ต่อไปนี้คือการปรับปรุงที่เป็นไปได้บางประการที่ควรพิจารณาเพื่อให้แน่ใจว่าแบบจำลองต้นไม้ตัดสินใจที่สร้างขึ้นนั้นสามารถตัดสินใจหรือจำแนกประเภทได้อย่างถูกต้อง โปรดทราบว่าสิ่งเหล่านี้ไม่ใช่สิ่งเดียวที่ควรพิจารณา แต่เป็นเพียงส่วนหนึ่งเท่านั้น
การเพิ่มจำนวนระดับของต้นไม้
ความแม่นยำของต้นไม้ตัดสินใจอาจเปลี่ยนแปลงไปตามความลึกของต้นไม้ตัดสินใจ ในหลายกรณี ใบของต้นไม้จะเป็นโหนดบริสุทธิ์[ 11 ]เมื่อโหนดบริสุทธิ์ หมายความว่าข้อมูลทั้งหมดในโหนดนั้นเป็นของคลาสเดียว[ 12 ]ตัวอย่างเช่น หากคลาสในชุดข้อมูลคือมะเร็งและไม่ใช่มะเร็ง โหนดใบจะถือว่าบริสุทธิ์เมื่อข้อมูลตัวอย่างทั้งหมดในโหนดใบเป็นส่วนหนึ่งของคลาสเดียวเท่านั้น ไม่ว่าจะเป็นมะเร็งหรือไม่ใช่มะเร็ง ต้นไม้ที่ลึกกว่าไม่ได้ดีกว่าเสมอไปเมื่อทำการปรับปรุงต้นไม้ตัดสินใจ ต้นไม้ที่ลึกกว่าอาจส่งผลเสียต่อเวลาการทำงาน หากมีการใช้อัลกอริธึมการจำแนกประเภทบางอย่าง ต้นไม้ที่ลึกกว่าอาจหมายความว่าเวลาการทำงานของอัลกอริธึมการจำแนกประเภทนี้ช้าลงอย่างมาก นอกจากนี้ยังมีความเป็นไปได้ที่อัลกอริธึมที่ใช้สร้างต้นไม้ตัดสินใจจะช้าลงอย่างมากเมื่อต้นไม้ลึกขึ้น หากอัลกอริธึมการสร้างต้นไม้ที่ใช้แยกโหนดบริสุทธิ์ อาจทำให้ความแม่นยำโดยรวมของตัวจำแนกประเภทต้นไม้ลดลง บางครั้ง การลงลึกลงไปในโครงสร้างต้นไม้ตัดสินใจอาจทำให้ความแม่นยำโดยรวมลดลง ดังนั้นจึงเป็นสิ่งสำคัญมากที่จะต้องทดสอบการปรับความลึกของต้นไม้ตัดสินใจและเลือกความลึกที่ให้ผลลัพธ์ที่ดีที่สุด โดยสรุปแล้ว จากประเด็นด้านล่าง เราจะกำหนดให้ D เป็นความลึกของต้นไม้
ข้อดีที่เป็นไปได้ของการเพิ่มจำนวน D:
- ความแม่นยำของแบบจำลองการจำแนกประเภทด้วยต้นไม้ตัดสินใจเพิ่มขึ้น
ข้อเสียที่อาจเกิดขึ้นจากการเพิ่มค่า D
- ปัญหาขณะรันไทม์
- ความแม่นยำลดลงโดยทั่วไป
- การแบ่งโหนดแบบบริสุทธิ์ในขณะที่ลงลึกลงไปอาจก่อให้เกิดปัญหาได้
ความสามารถในการทดสอบความแตกต่างของผลลัพธ์การจำแนกประเภทเมื่อเปลี่ยนค่า D นั้นมีความสำคัญอย่างยิ่ง เราต้องสามารถเปลี่ยนแปลงและทดสอบตัวแปรที่อาจส่งผลต่อความแม่นยำและความน่าเชื่อถือของแบบจำลองต้นไม้ตัดสินใจได้อย่างง่ายดาย
การเลือกฟังก์ชันการแบ่งโหนด
ฟังก์ชันการแบ่งโหนดที่ใช้สามารถส่งผลต่อการปรับปรุงความแม่นยำของต้นไม้ตัดสินใจได้ ตัวอย่างเช่น การใช้ ฟังก์ชัน การได้ข้อมูล (information-gain function) อาจให้ผลลัพธ์ที่ดีกว่าการใช้ฟังก์ชันฟี (phi function) ฟังก์ชันฟีเป็นที่รู้จักกันในฐานะตัววัด "ความดี" ของการแบ่งโหนดที่เป็นไปได้ในต้นไม้ตัดสินใจ ในขณะที่ฟังก์ชันการได้ข้อมูลเป็นที่รู้จักกันในฐานะตัววัด "การลดลงของเอนโทรปี " ต่อไปนี้ เราจะสร้างต้นไม้ตัดสินใจสองต้น ต้นหนึ่งจะสร้างโดยใช้ฟังก์ชันฟีในการแบ่งโหนด และอีกต้นหนึ่งจะสร้างโดยใช้ฟังก์ชันการได้ข้อมูลในการแบ่งโหนด
ข้อดีและข้อเสียหลักของการได้มาซึ่งข้อมูลและฟังก์ชันฟี
- ข้อเสียสำคัญประการหนึ่งของการเพิ่มข้อมูลคือ คุณลักษณะที่ถูกเลือกให้เป็นโหนดถัดไปในต้นไม้มักจะมีค่าที่ไม่ซ้ำกันมากกว่า[ 13 ]
- ข้อดีอย่างหนึ่งของการเพิ่มข้อมูลคือ มันมักจะเลือกคุณลักษณะที่มีผลกระทบมากที่สุดซึ่งอยู่ใกล้กับรากของต้นไม้ นับเป็นมาตรวัดที่ดีมากสำหรับการตัดสินความสำคัญของบางคุณลักษณะ
- ฟังก์ชันฟี (phi function) ยังเป็นมาตรวัดที่ดีในการตัดสินความเกี่ยวข้องของคุณลักษณะบางอย่างโดยพิจารณาจาก "ความดี" อีกด้วย
นี่คือสูตรฟังก์ชันการได้มาซึ่งข้อมูล สูตรนี้ระบุว่า การได้มาซึ่งข้อมูลเป็นฟังก์ชันของเอนโทรปีของโหนดในต้นไม้ตัดสินใจ ลบด้วยเอนโทรปีของการแยกที่เป็นไปได้ที่โหนด t ของต้นไม้ตัดสินใจ

นี่คือสูตรของฟังก์ชันฟี ฟังก์ชันฟีจะมีค่าสูงสุดเมื่อคุณลักษณะที่เลือกแบ่งตัวอย่างในลักษณะที่ทำให้เกิดการแบ่งที่สม่ำเสมอและมีจำนวนตัวอย่างในแต่ละส่วนใกล้เคียงกัน

เราจะกำหนดค่า D ซึ่งเป็นความลึกของต้นไม้ตัดสินใจที่เรากำลังสร้าง ให้เป็นสาม (D = 3) นอกจากนี้เรายังมีชุดข้อมูลตัวอย่างมะเร็งและตัวอย่างที่ไม่เป็นมะเร็ง รวมถึงคุณลักษณะการกลายพันธุ์ที่ตัวอย่างเหล่านั้นมีหรือไม่มี หากตัวอย่างมีคุณลักษณะการกลายพันธุ์ ตัวอย่างนั้นจะถือว่ามีการกลายพันธุ์นั้น และจะถูกแทนด้วยเลขหนึ่ง หากตัวอย่างไม่มีคุณลักษณะการกลายพันธุ์ ตัวอย่างนั้นจะถือว่าไม่มีการกลายพันธุ์นั้น และจะถูกแทนด้วยเลขศูนย์
โดยสรุป C ย่อมาจากมะเร็ง และ NC ย่อมาจากไม่ใช่มะเร็ง ตัวอักษร M ย่อมาจากการกลายพันธุ์และหากตัวอย่างมีการกลายพันธุ์เฉพาะอย่างใดอย่างหนึ่ง จะแสดงเป็นเลขหนึ่งในตาราง และหากไม่มีการกลายพันธุ์จะแสดงเป็นเลขศูนย์
| เอ็ม1 | เอ็ม2 | เอ็ม3 | เอ็ม4 | เอ็ม5 | |
|---|---|---|---|---|---|
| ซี1 | 0 | 1 | 0 | 1 | 1 |
| เอ็นซี1 | 0 | 0 | 0 | 0 | 0 |
| เอ็นซี2 | 0 | 0 | 1 | 1 | 0 |
| เอ็นซี3 | 0 | 0 | 0 | 0 | 0 |
| ซี2 | 1 | 1 | 1 | 1 | 1 |
| เอ็นซี4 | 0 | 0 | 0 | 1 | 0 |
ตอนนี้ เราสามารถใช้สูตรเพื่อคำนวณค่าฟังก์ชัน phi และค่าการได้ข้อมูล (information gain) สำหรับแต่ละ M ในชุดข้อมูลได้ เมื่อคำนวณค่าทั้งหมดแล้ว เราสามารถสร้างต้นไม้ได้ สิ่งแรกที่ต้องทำคือการเลือกโหนดราก ในการได้ข้อมูลและฟังก์ชัน phi เราพิจารณาว่าการแบ่งแยกที่เหมาะสมที่สุดคือการกลายพันธุ์ที่ให้ค่าการได้ข้อมูลหรือฟังก์ชัน phi สูงที่สุด สมมติว่า M1 มีค่าฟังก์ชัน phi สูงที่สุด และ M4 มีค่าการได้ข้อมูลสูงที่สุด การกลายพันธุ์ M1 จะเป็นรากของต้นไม้ฟังก์ชัน phi ของเรา และ M4 จะเป็นรากของต้นไม้การได้ข้อมูลของเรา คุณสามารถสังเกตโหนดรากได้ด้านล่าง

เมื่อเราเลือกโหนดรากแล้ว เราสามารถแบ่งตัวอย่างออกเป็นสองกลุ่มตามว่าตัวอย่างนั้นมีการกลายพันธุ์ที่โหนดรากหรือไม่ กลุ่มเหล่านี้จะเรียกว่ากลุ่ม A และกลุ่ม B ตัวอย่างเช่น หากเราใช้ M1 ในการแบ่งตัวอย่างที่โหนดราก เราจะได้ตัวอย่าง NC2 และ C2 ในกลุ่ม A และตัวอย่างที่เหลือ NC4, NC3, NC1, C1 ในกลุ่ม B
โดยไม่คำนึงถึงการกลายพันธุ์ที่เลือกไว้สำหรับโหนดราก ให้ดำเนินการวางคุณลักษณะที่ดีที่สุดถัดไปที่มีค่าการได้มาซึ่งข้อมูลหรือฟังก์ชัน phi สูงที่สุดลงในโหนดลูกซ้ายหรือขวาของต้นไม้ตัดสินใจ เมื่อเราเลือกโหนดรากและโหนดลูกสองโหนดสำหรับต้นไม้ที่มีความลึกเท่ากับ 3 แล้ว เราก็สามารถเพิ่มใบได้ ใบเหล่านี้จะแสดงถึงการตัดสินใจจำแนกประเภทขั้นสุดท้ายที่แบบจำลองสร้างขึ้นโดยอิงจากการกลายพันธุ์ที่ตัวอย่างมีหรือไม่มี ต้นไม้ด้านซ้ายคือต้นไม้ตัดสินใจที่เราได้จากการใช้การได้มาซึ่งข้อมูลเพื่อแยกโหนด และต้นไม้ด้านขวาคือสิ่งที่ได้จากการใช้ฟังก์ชัน phi เพื่อแยกโหนด

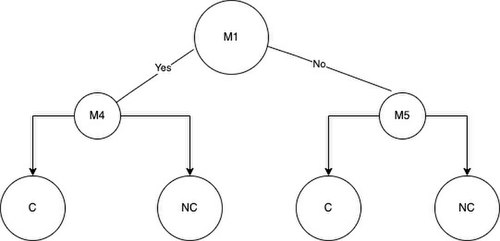
สมมติว่า ผล การจำแนกประเภทจากทั้งสองต้นไม้แสดงออกมาในรูปของ เมท ริก ซ์ความสับสน
เมทริกซ์ความสับสนของการได้รับข้อมูล:
คาดการณ์ แท้จริง | ซี | เอ็นซี |
|---|---|---|
| ซี | 1 | 1 |
| เอ็นซี | 0 | 4 |
เมทริกซ์ความสับสนของฟังก์ชัน Phi:
คาดการณ์ แท้จริง | ซี | เอ็นซี |
|---|---|---|
| ซี | 2 | 0 |
| เอ็นซี | 1 | 3 |
ต้นไม้ตัดสินใจที่ใช้ค่าการเพิ่มข้อมูล (information gain) ให้ผลลัพธ์เหมือนกันกับการใช้ฟังก์ชัน phi ในการคำนวณความแม่นยำ เมื่อเราจำแนกตัวอย่างโดยใช้แบบจำลองที่ใช้ค่าการเพิ่มข้อมูล เราจะได้ผลบวกจริง 1 ตัว ผลบวกเท็จ 1 ตัว ผลลบเท็จ 0 ตัว และผลลบจริง 4 ตัว สำหรับแบบจำลองที่ใช้ฟังก์ชัน phi เราจะได้ผลบวกจริง 2 ตัว ผลบวกเท็จ 0 ตัว ผลลบเท็จ 1 ตัว และผลลบจริง 3 ตัว ขั้นตอนต่อไปคือการประเมินประสิทธิภาพของต้นไม้ตัดสินใจโดยใช้ตัวชี้วัดสำคัญบางประการที่จะกล่าวถึงในส่วนการประเมินต้นไม้ตัดสินใจด้านล่าง ตัวชี้วัดที่จะกล่าวถึงด้านล่างนี้สามารถช่วยกำหนดขั้นตอนต่อไปที่จะต้องดำเนินการเมื่อต้องการเพิ่มประสิทธิภาพต้นไม้ตัดสินใจ
เทคนิคอื่นๆ
ข้อมูลข้างต้นไม่ใช่จุดสิ้นสุดของการสร้างและปรับปรุงประสิทธิภาพของต้นไม้ตัดสินใจ ยังมีเทคนิคมากมายในการปรับปรุงแบบจำลองการจำแนกประเภทด้วยต้นไม้ตัดสินใจที่เราสร้างขึ้น หนึ่งในเทคนิคเหล่านั้นคือการสร้างแบบจำลองต้นไม้ตัดสินใจจาก ชุดข้อมูลแบบ บูตสแตรปชุดข้อมูลแบบบูตสแตรปช่วยขจัดอคติที่เกิดขึ้นเมื่อสร้างแบบจำลองต้นไม้ตัดสินใจด้วยข้อมูลชุดเดียวกับที่ใช้ทดสอบแบบจำลอง ความสามารถในการใช้ประโยชน์จากพลังของป่าสุ่ม (random forests)ยังช่วยปรับปรุงความแม่นยำโดยรวมของแบบจำลองที่สร้างขึ้นได้อย่างมาก วิธีนี้สร้างการตัดสินใจจำนวนมากจากต้นไม้ตัดสินใจจำนวนมาก และนับคะแนนโหวตจากแต่ละต้นไม้ตัดสินใจเพื่อทำการจำแนกประเภทขั้นสุดท้าย มีเทคนิคมากมาย แต่เป้าหมายหลักคือการทดสอบการสร้างแบบจำลองต้นไม้ตัดสินใจในรูปแบบต่างๆ เพื่อให้แน่ใจว่าได้ประสิทธิภาพสูงสุดเท่าที่จะเป็นไปได้
การประเมินแผนผังการตัดสินใจ
สิ่งสำคัญคือต้องทราบถึงตัวชี้วัด ที่ใช้ในการประเมินต้นไม้ตัดสินใจ ตัวชี้วัดหลักที่ใช้ ได้แก่ความแม่นยำความไวความจำเพาะความเที่ยงตรงอัตราการพลาด อัตราการค้นพบที่ผิดพลาดและอัตราการละเว้นที่ผิดพลาดตัวชี้วัดทั้งหมดนี้ได้มาจากจำนวน ผล บวกจริงผลบวกเท็จผลลบจริงและผลลบเท็จที่ได้จากการประมวลผลชุดตัวอย่างผ่านแบบจำลองการจำแนกประเภทด้วยต้นไม้ตัดสินใจ นอกจากนี้ ยังสามารถสร้างเมทริกซ์ความสับสนเพื่อแสดงผลลัพธ์เหล่านี้ได้ ตัวชี้วัดหลักทั้งหมดนี้บอกข้อมูลที่แตกต่างกันเกี่ยวกับจุดแข็งและจุดอ่อนของแบบจำลองการจำแนกประเภทที่สร้างขึ้นจากต้นไม้ตัดสินใจของคุณ ตัวอย่างเช่น ความไวต่ำแต่ความจำเพาะสูงอาจบ่งชี้ว่าแบบจำลองการจำแนกประเภทที่สร้างจากต้นไม้ตัดสินใจนั้นไม่สามารถระบุตัวอย่างมะเร็งได้ดีเมื่อเทียบกับตัวอย่างที่ไม่เป็นมะเร็ง
ลองพิจารณาเมทริกซ์ความสับสนด้านล่างนี้ดู
คาดการณ์ แท้จริง | ซี | เอ็นซี |
|---|---|---|
| ซี | 11 (ผลบวกจริง) | 45 (ผลลบเท็จ) |
| เอ็นซี | 1 (ผลบวกเท็จ) | 105 (ค่าลบที่แท้จริง) |
ต่อไปนี้เราจะคำนวณค่าความแม่นยำ ความไว ความจำเพาะ ความเที่ยงตรง อัตราการพลาด อัตราการค้นพบที่ผิดพลาด และอัตราการละเว้นที่ผิดพลาด
ความแม่นยำ:


ความไว (TPR – อัตราผลบวกจริง): [ 14 ]


ความจำเพาะ (TNR – อัตราผลลบที่ถูกต้อง):


ความแม่นยำ (PPV – ค่าทำนายผลบวก):


อัตราการวินิจฉัยผิดพลาด (FNR – อัตราผลลบเท็จ):


อัตราการค้นพบที่ผิดพลาด (FDR):


อัตราการละเว้นที่ผิดพลาด (FOR):


เมื่อเราคำนวณตัวชี้วัดหลักเสร็จแล้ว เราสามารถสรุปเบื้องต้นเกี่ยวกับประสิทธิภาพของแบบจำลองต้นไม้ตัดสินใจที่สร้างขึ้นได้ ความแม่นยำที่เราคำนวณได้คือ 71.60% ค่าความแม่นยำนี้ถือว่าดีสำหรับการเริ่มต้น แต่เราต้องการให้แบบจำลองของเรามีความแม่นยำมากที่สุดเท่าที่จะเป็นไปได้ในขณะที่ยังคงรักษาประสิทธิภาพโดยรวมไว้ ค่าความไว 19.64% หมายความว่าจากทุกคนที่ตรวจพบว่าเป็นมะเร็งนั้น ตรวจพบว่าเป็นมะเร็งจริง หากเราดูที่ค่าความจำเพาะ 99.06% เราจะรู้ว่าจากตัวอย่างทั้งหมดที่ตรวจไม่พบมะเร็งนั้น ตรวจพบว่าเป็นมะเร็งจริง เมื่อพูดถึงความไวและความจำเพาะ สิ่งสำคัญคือต้องมีความสมดุลระหว่างสองค่านี้ ดังนั้นหากเราสามารถลดความจำเพาะเพื่อเพิ่มความไวได้ นั่นจะเป็นประโยชน์[ 15 ]นี่เป็นเพียงตัวอย่างเล็กน้อยเกี่ยวกับวิธีการใช้ค่าเหล่านี้และความหมายเบื้องหลังเพื่อประเมินแบบจำลองต้นไม้ตัดสินใจและปรับปรุงในการทำซ้ำครั้งต่อไป
ดูเพิ่มเติม
- แผนผังพฤติกรรม (ปัญญาประดิษฐ์ หุ่นยนต์ และการควบคุม) – แบบจำลองทางคณิตศาสตร์ของการดำเนินการตามแผน
- แผนภาพการตัดสินใจแบบไบนารี – โครงสร้างข้อมูลสำหรับฟังก์ชันบูลีน
- Boosting (การเรียนรู้ของเครื่อง) – วิธีการเรียนรู้แบบกลุ่ม (Ensemble learning )
- การเงินองค์กร § การประเมินมูลค่าความยืดหยุ่น - การประยุกต์ใช้เทคนิคในการประเมินมูลค่า
- วงจรการตัดสินใจ – ลำดับขั้นตอนในการตัดสินใจ
- รายการตัดสินใจ
- เมทริกซ์การตัดสินใจ – รายการค่าต่างๆ สำหรับการเปรียบเทียบ
- ตารางการตัดสินใจ – ตารางที่ระบุการดำเนินการตามเงื่อนไขต่างๆ
- แบบจำลองต้นไม้ตัดสินใจ – แบบจำลองความซับซ้อนในการคำนวณ
- เหตุผลในการออกแบบ – การระบุรายละเอียดการตัดสินใจในการออกแบบอย่างชัดเจน
- DRAKON – เครื่องมือสร้างแผนที่อัลกอริทึม
- ห่วงโซ่มาร์คอฟ – กระบวนการสุ่มที่ไม่ขึ้นอยู่กับประวัติในอดีต
- Random forest – วิธีการเรียนรู้ของเครื่องแบบกลุ่มที่ใช้โครงสร้างแบบต้นไม้
- แนวทางการจัดลำดับความสำคัญ – วิธีการวิเคราะห์การตัดสินใจแบบหลายเกณฑ์
- อัลกอริทึมอัตราต่อรอง – วิธีการคำนวณกลยุทธ์ที่เหมาะสมที่สุดสำหรับปัญหาที่มีผลลัพธ์สุดท้าย
- คณิตศาสตร์เชิงการจัดเรียงแบบทอพอโลยี – วิชาคณิตศาสตร์
- ตารางความจริง – ตารางทางคณิตศาสตร์ที่ใช้ในตรรกศาสตร์
ลิงก์ภายนอก
- บทช่วยสอนและตัวอย่างเกี่ยวกับแผนผังการตัดสินใจอย่างครอบคลุม
- แกลเลอรีตัวอย่างแผนผังการตัดสินใจ
- ต้นไม้ตัดสินใจแบบเพิ่มประสิทธิภาพด้วยการไล่ระดับ
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ แผนผังการตัดสินใจ
แผนผังการตัดสินใจ (Decision Tree ) เป็น โครงสร้างการแบ่งส่วนแบบเรียกซ้ำ เพื่อสนับสนุนการ ตัดสินใจ โดยใช้แบบจำลองคล้ายต้นไม้ ของการตัดสินใจและผลลัพธ์ที่เป็นไปได้ รวมถึง...
ภาพรวม
แผนผังการตัดสินใจ (Decision Tree) เป็น โครงสร้างคล้าย ผังงาน (Flowchart) ที่แต่ละโหนดภายในแทนการทดสอบคุณลักษณะ (เช่น การโยนเหรียญจะได้หัวหรือก้อย) แต่ละกิ่งแทนผลลัพธ์ของการทดสอบ และแต่ละโหนดใบแทนป้ายกำกับคลาส (การตัดสินใจหลังจากคำนวณคุณลักษณะทั้งหมดแล้ว)...
องค์ประกอบของแผนผังการตัดสินใจ
เมื่อวาดจากซ้ายไปขวา แผนผังการตัดสินใจจะมีเฉพาะโหนดแตกแขนง (เส้นทางที่แยกออก) แต่ไม่มีโหนดรวม (เส้นทางที่บรรจบกัน) ดังนั้นหากใช้การวาดด้วยมือ แผนผังอาจมีขนาดใหญ่มากและมักยากที่จะวาดให้เสร็จสมบูรณ์ด้วยมือ ในอดีต แผนผังการตัดสินใจถูกสร้างขึ้นด้วยมือ –...
กฎการตัดสินใจ
ต้นไม้ตัดสินใจสามารถ แปลง เป็น กฎการตัดสินใจเชิงเส้น ได้ [ 5 ] โดยผลลัพธ์คือเนื้อหาของโหนดใบ และเงื่อนไขตามเส้นทางจะก่อให้เกิดการเชื่อมโยงในข้อความ if โดยทั่วไป กฎจะมีรูปแบบดังนี้: