อ่าน 12 นาที
การสุ่มตัวอย่าง (สถิติ)
ใน ทางสถิติ การประกันคุณภาพ และ ระเบียบวิธีสำรวจ การ สุ่มตัวอย่าง คือการเลือกกลุ่มย่อยของ บุคคล จาก ประชากรทางสถิติ เพื่อประมาณลักษณะของประชากรทั้งหมด กลุ่มย่อยนี้เรียกว่า...
การสุ่มตัวอย่าง (สถิติ)
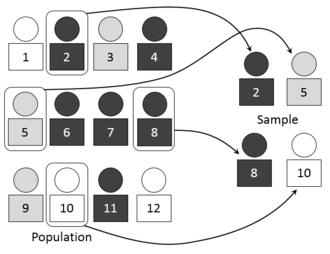
ในทางสถิติการประกันคุณภาพ และระเบียบวิธีสำรวจการสุ่มตัวอย่างคือการเลือกกลุ่มย่อยของบุคคลจากประชากรทางสถิติเพื่อประมาณลักษณะของประชากรทั้งหมด กลุ่มย่อยนี้เรียกว่าตัวอย่างทางสถิติ (หรือตัวอย่างโดยย่อ) ซึ่งมีจุดประสงค์เพื่อสะท้อนประชากรทั้งหมด และนักสถิติพยายามเก็บรวบรวมตัวอย่างที่เป็นตัวแทนของประชากร
การสุ่มตัวอย่างมีต้นทุนต่ำกว่าและเก็บรวบรวมข้อมูล ได้เร็ว กว่าการสำรวจประชากรทั้งหมด (ในหลายกรณี การเก็บข้อมูลจากประชากรทั้งหมดเป็นไปไม่ได้ เช่น การวัดขนาดของดาวฤกษ์ทั้งหมดในจักรวาล) ดังนั้น การสุ่มตัวอย่างจึงสามารถให้ข้อมูลเชิงลึกในกรณีที่ไม่สามารถวัดประชากรทั้งหมดได้
การสังเกตแต่ละครั้งจะวัดคุณสมบัติอย่างน้อยหนึ่งอย่าง (เช่น น้ำหนัก ตำแหน่ง สี หรือมวล) ของวัตถุหรือบุคคลที่เป็นอิสระ ในการสุ่มตัวอย่างแบบสำรวจสามารถใช้น้ำหนักกับข้อมูลเพื่อปรับให้เข้ากับการออกแบบตัวอย่าง โดยเฉพาะอย่างยิ่งในการสุ่มตัวอย่างแบบแบ่งชั้น [ 1 ] ผลลัพธ์จากทฤษฎีความน่าจะเป็นและทฤษฎีทางสถิติถูกนำมาใช้เพื่อเป็นแนวทางในการปฏิบัติ ในการวิจัยทางธุรกิจและการแพทย์ การสุ่มตัวอย่างถูกนำมาใช้อย่างกว้างขวางเพื่อรวบรวมข้อมูลเกี่ยวกับประชากร[ 2 ]การสุ่มตัวอย่างเพื่อการยอมรับใช้เพื่อตรวจสอบว่าล็อตการผลิตของวัสดุเป็นไปตามข้อกำหนด ที่ควบคุมหรือ ไม่
ประวัติศาสตร์
การสุ่มตัวอย่างโดยใช้การจับฉลากเป็นแนวคิดเก่าแก่ที่กล่าวถึงหลายครั้งในพระคัมภีร์ไบเบิล ในปี ค.ศ. 1786 ปิแอร์ ซิมงลาปลาซได้ประมาณจำนวนประชากรของฝรั่งเศสโดยใช้ตัวอย่าง พร้อมกับตัวประมาณอัตราส่วนเขายังคำนวณค่าประมาณความน่าจะเป็นของข้อผิดพลาดด้วย ซึ่งไม่ได้แสดงเป็นช่วงความเชื่อมั่น แบบสมัยใหม่ แต่เป็นขนาดตัวอย่างที่จำเป็นเพื่อให้ได้ขอบเขตบนที่เฉพาะเจาะจงของข้อผิดพลาดในการสุ่มตัวอย่างด้วยความน่าจะเป็น 1000/1001 ค่าประมาณของเขาใช้ทฤษฎีบทของเบย์สด้วยความน่าจะเป็นก่อนหน้า แบบสม่ำเสมอ และสมมติว่าตัวอย่างของเขาเป็นแบบสุ่มอเล็กซานเดอร์ อิวาโนวิช ชูโปรฟได้นำการสำรวจตัวอย่างมาใช้ในจักรวรรดิรัสเซียในช่วงปี ค.ศ. 1870 [ 3 ]
ในสหรัฐอเมริกา การคาดการณ์ของ Literary Digest ในปี 1936 ที่ว่าพรรครีพับลิกันจะชนะการเลือกตั้งประธานาธิบดี นั้น ผิดพลาดอย่างร้ายแรงเนื่องจากอคติ อย่างรุนแรง [1]มีผู้ตอบแบบสอบถามมากกว่าสองล้านคน โดยชื่อของพวกเขาได้มาจากรายชื่อผู้สมัครสมาชิกนิตยสารและสมุดโทรศัพท์ ไม่มีการตระหนักว่ารายชื่อเหล่านี้มีอคติไปทางพรรครีพับลิกันอย่างมาก และตัวอย่างที่ได้ แม้จะมีขนาดใหญ่มาก แต่ก็มีข้อบกพร่องอย่างมาก[ 4 ] [ 5 ]
การเลือกตั้งในสิงคโปร์ได้นำแนวปฏิบัตินี้มาใช้ตั้งแต่การเลือกตั้งปี 2558หรือที่รู้จักกันในชื่อการนับตัวอย่าง โดยตามที่กรมการเลือกตั้ง (ELD) ซึ่งเป็นคณะกรรมการการเลือกตั้งของประเทศระบุว่า การนับตัวอย่างช่วยลดการคาดเดาและข้อมูลที่ผิดพลาด ในขณะเดียวกันก็ช่วยให้เจ้าหน้าที่การเลือกตั้งตรวจสอบผลการเลือกตั้งในเขตเลือกตั้งนั้นได้ แม้ว่าการนับตัวอย่างที่รายงานจะให้ผลลัพธ์ที่บ่งชี้ได้ค่อนข้างแม่นยำ โดยมีอัตราความคลาดเคลื่อน 4% ที่ช่วงความเชื่อมั่น 95% แต่ ELD เตือนประชาชนว่าการนับตัวอย่างนั้นแยกต่างหากจากผลอย่างเป็นทางการ และเจ้าหน้าที่ผู้รับผิดชอบ การเลือกตั้งเท่านั้น ที่จะประกาศผลอย่างเป็นทางการเมื่อการนับคะแนนเสร็จสิ้น[ 6 ] [ 7 ]
นิยามประชากร
การปฏิบัติทางสถิติที่ประสบความสำเร็จนั้นขึ้นอยู่กับการกำหนดปัญหาอย่างมีเป้าหมาย ในการสุ่มตัวอย่างนั้น รวมถึงการกำหนด " ประชากร " ที่เราจะสุ่มตัวอย่างมา ประชากรสามารถนิยามได้ว่ารวมถึงบุคคลหรือสิ่งของทั้งหมดที่มีลักษณะที่เราต้องการทำความเข้าใจ เนื่องจากโดยปกติแล้วมักไม่มีเวลาหรือเงินทุนเพียงพอที่จะรวบรวมข้อมูลจากทุกคนหรือทุกสิ่งในประชากร เป้าหมายจึงกลายเป็นการหาตัวอย่างที่เป็นตัวแทน (หรือกลุ่มย่อย) ของประชากรนั้น
บางครั้งสิ่งที่กำหนดกลุ่มประชากรนั้นชัดเจนอยู่แล้ว ตัวอย่างเช่น ผู้ผลิตจำเป็นต้องตัดสินใจว่าวัสดุล็อตหนึ่งจากการผลิตนั้นมีคุณภาพสูงพอที่จะส่งให้ลูกค้าหรือไม่ หรือควรจะทิ้งหรือแก้ไขใหม่เนื่องจากคุณภาพต่ำ ในกรณีนี้ ล็อตนั้นก็คือกลุ่มประชากรนั่นเอง
แม้ว่ากลุ่มเป้าหมายที่สนใจมักจะเป็นวัตถุทางกายภาพ แต่บางครั้งก็จำเป็นต้องเก็บตัวอย่างในช่วงเวลา สถานที่ หรือการผสมผสานของมิติเหล่านี้ ตัวอย่างเช่น การตรวจสอบการจัดสรรพนักงานในซูเปอร์มาร์เก็ตอาจตรวจสอบความยาวของแถวรอชำระเงินในช่วงเวลาต่างๆ หรือการศึกษาเกี่ยวกับนกเพนกวินที่ใกล้สูญพันธุ์อาจมุ่งเน้นไปที่การทำความเข้าใจการใช้พื้นที่ล่าสัตว์ต่างๆ ของพวกมันในช่วงเวลาต่างๆ สำหรับมิติของเวลา อาจเน้นไปที่ช่วงเวลาหรือเหตุการณ์เฉพาะเจาะจง
ในบางกรณี 'ประชากร' ที่ถูกตรวจสอบอาจจับต้องได้ยากยิ่งกว่านั้น ตัวอย่างเช่นโจเซฟ แจ็กเกอร์ศึกษาพฤติกรรมของ วงล้อ รูเล็ตในคาสิโนแห่งหนึ่งในมอนเตคาร์โลและใช้สิ่งนี้เพื่อระบุวงล้อที่มีความลำเอียง ในกรณีนี้ 'ประชากร' ที่แจ็กเกอร์ต้องการตรวจสอบคือพฤติกรรมโดยรวมของวงล้อ (เช่นการกระจายความน่าจะเป็น ของผลลัพธ์จากการทดลองจำนวนอนันต์ครั้ง) ในขณะที่ 'ตัวอย่าง' ของเขาเกิดจากผลลัพธ์ที่สังเกต ได้ จากวงล้อนั้น ข้อพิจารณาที่คล้ายกันนี้เกิดขึ้นเมื่อทำการวัดคุณสมบัติของวัสดุซ้ำๆ เช่น ค่าการนำไฟฟ้าของทองแดง
สถานการณ์เช่นนี้มักเกิดขึ้นเมื่อต้องการศึกษาหาความรู้เกี่ยวกับระบบสาเหตุซึ่ง ประชากร ที่สังเกตเป็นผลลัพธ์ ในกรณีเช่นนี้ ทฤษฎีการสุ่มตัวอย่างอาจพิจารณาประชากรที่สังเกตเป็นตัวอย่างจาก "ประชากรกลุ่มใหญ่กว่า" ตัวอย่างเช่น นักวิจัยอาจศึกษาอัตราความสำเร็จของโปรแกรม "เลิกบุหรี่" ใหม่กับกลุ่มทดสอบ 100 คน เพื่อทำนายผลกระทบของโปรแกรมหากมีการนำไปใช้ทั่วประเทศ ในที่นี้ ประชากรกลุ่มใหญ่กว่าคือ "ทุกคนในประเทศ หากสามารถเข้าถึงการรักษาได้" ซึ่งเป็นกลุ่มที่ยังไม่มีอยู่จริง เนื่องจากโปรแกรมยังไม่พร้อมให้บริการแก่ทุกคน
กลุ่มตัวอย่างที่นำมาใช้ในการศึกษาอาจไม่ใช่กลุ่มเดียวกับกลุ่มเป้าหมายที่ต้องการข้อมูล บ่อยครั้งที่กลุ่มทั้งสองมีส่วนที่ทับซ้อนกันมากแต่ไม่ทั้งหมด เนื่องจากปัญหาเรื่องกรอบแนวคิด ฯลฯ (ดูด้านล่าง) บางครั้งกลุ่มตัวอย่างอาจแยกจากกันโดยสิ้นเชิง เช่น การศึกษาหนูเพื่อทำความเข้าใจสุขภาพของมนุษย์ให้ดียิ่งขึ้น หรือการศึกษาข้อมูลจากผู้ที่เกิดในปี 2008 เพื่อคาดการณ์เกี่ยวกับผู้ที่เกิดในปี 2009
การใช้เวลาเพื่อให้แน่ใจว่ากลุ่มตัวอย่างและกลุ่มประชากรเป้าหมายมีความแม่นยำนั้น มักเป็นการใช้เวลาอย่างคุ้มค่า เพราะจะช่วยให้พบประเด็น ความคลุมเครือ และคำถามมากมายที่อาจถูกมองข้ามไปในขั้นตอนนี้
กรอบการสุ่มตัวอย่าง
ในกรณีที่ตรงไปตรงมาที่สุด เช่น การสุ่มตัวอย่างวัสดุจากสายการผลิต (การสุ่มตัวอย่างเพื่อยอมรับคุณภาพเป็นล็อต) จะเป็นที่พึงปรารถนาอย่างยิ่งที่จะระบุและวัดค่าทุกชิ้นในประชากร และรวมทุกชิ้นไว้ในตัวอย่างของเรา อย่างไรก็ตาม ในกรณีทั่วไปแล้ว วิธีนี้มักเป็นไปไม่ได้หรือทำได้ไม่สะดวก ไม่มีวิธีใดที่จะระบุหนูทุกตัวในกลุ่มหนูทั้งหมดได้ ในกรณีที่การลงคะแนนเสียงไม่เป็นภาคบังคับ ก็ไม่มีวิธีใดที่จะระบุได้ว่าใครจะไปลงคะแนนเสียงในการเลือกตั้งที่จะมาถึง (ก่อนการเลือกตั้ง) ประชากรที่ไม่แม่นยำเหล่านี้ไม่เหมาะสมกับการสุ่มตัวอย่างด้วยวิธีการใดๆ ที่กล่าวมาข้างต้น และไม่สามารถใช้ทฤษฎีทางสถิติได้
เพื่อเป็นการแก้ไข เราจึงแสวงหากรอบการสุ่มตัวอย่างที่มีคุณสมบัติที่เราสามารถระบุองค์ประกอบแต่ละอย่างและรวมไว้ในตัวอย่างของเรา[ 8 ] [ 9 ] [ 10 ] [ 11 ]กรอบประเภทที่ตรงไปตรงมาที่สุดคือรายการองค์ประกอบของประชากร (โดยเฉพาะอย่างยิ่งประชากรทั้งหมด) พร้อมข้อมูลการติดต่อที่เหมาะสม ตัวอย่างเช่น ในการสำรวจความคิดเห็นกรอบการสุ่มตัวอย่างที่เป็นไปได้ ได้แก่ทะเบียนผู้มีสิทธิเลือกตั้งและสมุดโทรศัพท์
ตัวอย่างความน่าจะเป็นคือตัวอย่างที่ทุกหน่วยในประชากรมีโอกาส (มากกว่าศูนย์) ที่จะถูกเลือกในตัวอย่าง และความน่าจะเป็นนี้สามารถกำหนดได้อย่างแม่นยำ การรวมกันของคุณลักษณะเหล่านี้ทำให้สามารถสร้างค่าประมาณที่ไม่ลำเอียงของผลรวมประชากรได้ โดยการถ่วงน้ำหนักหน่วยตัวอย่างตามความน่าจะเป็นของการถูกเลือก
ตัวอย่าง: เราต้องการประมาณรายได้รวมของประชากรผู้ใหญ่ที่อาศัยอยู่ในถนนสายหนึ่ง เราไปเยี่ยมบ้านแต่ละหลังในถนนสายนั้น ระบุตัวผู้ใหญ่ทุกคนที่อาศัยอยู่ที่นั่น และสุ่มเลือกผู้ใหญ่หนึ่งคนจากแต่ละบ้าน (เช่น เราสามารถกำหนดหมายเลขสุ่มให้กับแต่ละคน โดยใช้การ แจกแจงแบบเอก รูป (uniform distribution)ระหว่าง 0 ถึง 1 และเลือกคนที่หมายเลขสูงสุดในแต่ละบ้าน) จากนั้นเราจะสัมภาษณ์คนที่ถูกเลือกและหาว่ารายได้ของเขาหรือเธอเท่าไหร่
บุคคลที่อาศัยอยู่คนเดียวมีโอกาสถูกเลือกอย่างแน่นอน ดังนั้นเราจึงนำรายได้ของพวกเขามาบวกกับประมาณการรายได้รวม แต่บุคคลที่อาศัยอยู่ในครัวเรือนที่มีผู้ใหญ่สองคนมีโอกาสถูกเลือกเพียงหนึ่งในสองเท่านั้น เพื่อให้สอดคล้องกับเรื่องนี้ เมื่อเรามาถึงครัวเรือนดังกล่าว เราจะนับรายได้ของบุคคลที่ถูกเลือกเป็นสองเท่าของรายได้รวม (บุคคลที่ถูก เลือกจากครัวเรือนนั้น อาจมองได้ว่าเป็นตัวแทนของบุคคลที่ ไม่ถูก เลือก ด้วยเช่นกัน)
ในตัวอย่างข้างต้น ไม่ใช่ทุกคนจะมีโอกาสถูกเลือกเท่ากัน สิ่งที่ทำให้เป็นตัวอย่างแบบความน่าจะเป็นคือความจริงที่ว่าเรารู้ความน่าจะเป็นของแต่ละคน เมื่อทุกองค์ประกอบในประชากรมีโอกาสถูกเลือกเท่ากัน เราเรียกว่าการออกแบบแบบ 'ความน่าจะเป็นในการเลือกเท่ากัน' (EPS) การออกแบบดังกล่าวเรียกอีกอย่างว่า 'การถ่วงน้ำหนักด้วยตนเอง' เพราะหน่วยตัวอย่างทั้งหมดได้รับน้ำหนักเท่ากัน
การสุ่มตัวอย่างโดยใช้หลักความน่าจะเป็น ได้แก่ การสุ่มตัวอย่างแบบสุ่ม อย่างง่าย การสุ่มตัวอย่าง แบบเป็นระบบการสุ่มตัวอย่างแบบแบ่งชั้นการสุ่มตัวอย่างตามสัดส่วนของขนาด และการสุ่มตัวอย่างแบบกลุ่มหรือ แบบหลายขั้นตอน วิธีการสุ่มตัวอย่างโดยใช้หลักความน่าจะเป็นต่างๆ เหล่านี้มีสิ่งที่เหมือนกันอยู่สองประการ:
- องค์ประกอบแต่ละอย่างมีโอกาสถูกสุ่มเลือกที่ไม่เป็นศูนย์ที่ทราบค่าแล้ว และ
- เกี่ยวข้องกับการสุ่มเลือกในบางจุด
การสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น
การสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็นคือวิธีการสุ่มตัวอย่างใดๆ ที่บางส่วนของประชากรไม่มีโอกาสถูกเลือก (บางครั้งเรียกว่า 'อยู่นอกขอบเขต'/'ครอบคลุมไม่ครบถ้วน') หรือไม่สามารถกำหนดความน่าจะเป็นของการเลือกได้อย่างแม่นยำ วิธีการนี้เกี่ยวข้องกับการเลือกองค์ประกอบโดยอาศัยสมมติฐานเกี่ยวกับประชากรที่สนใจ ซึ่งเป็นเกณฑ์ในการเลือก ดังนั้น เนื่องจากการเลือกองค์ประกอบไม่ได้เป็นการสุ่ม การสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็นจึงไม่สามารถประมาณค่าความคลาดเคลื่อนของการสุ่มตัวอย่างได้ เงื่อนไขเหล่านี้ก่อให้เกิดอคติจากการตัดออกซึ่งจำกัดปริมาณข้อมูลที่ตัวอย่างสามารถให้ได้เกี่ยวกับประชากร ข้อมูลเกี่ยวกับความสัมพันธ์ระหว่างตัวอย่างและประชากรมีจำกัด ทำให้ยากที่จะคาดการณ์จากตัวอย่างไปยังประชากรทั้งหมด
ตัวอย่าง: เราไปเยี่ยมทุกบ้านในถนนสายหนึ่ง และสัมภาษณ์คนแรกที่มาเปิดประตู ในบ้านที่มีผู้อยู่อาศัยมากกว่าหนึ่งคน วิธีนี้เป็นการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น เพราะบางคนมีแนวโน้มที่จะมาเปิดประตูมากกว่า (เช่น คนว่างงานที่ใช้เวลาส่วนใหญ่อยู่ที่บ้านมีแนวโน้มที่จะมาเปิดประตูมากกว่าเพื่อนร่วมบ้านที่ทำงานอยู่และอาจจะอยู่ที่ทำงานเมื่อผู้สัมภาษณ์ไปเยี่ยม) และการคำนวณความน่าจะเป็นเหล่านี้ก็ทำได้ยากในทางปฏิบัติ
วิธีการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น ได้แก่ การสุ่มตัวอย่าง แบบสะดวกการสุ่มตัวอย่างแบบโควตาการสุ่มตัวอย่างแบบลูกโซ่และการสุ่มตัวอย่างแบบเจาะจงนอกจากนี้ ผลกระทบจากการไม่ตอบสนองอาจทำให้ การออกแบบการสุ่มตัวอย่าง แบบใช้ความน่าจะเป็นกลายเป็นการออกแบบแบบไม่ใช้ความน่าจะเป็นได้ หากไม่เข้าใจลักษณะของการไม่ตอบสนองอย่างถ่องแท้ เนื่องจากผลกระทบจากการไม่ตอบสนองจะเปลี่ยนแปลงความน่าจะเป็นของการถูกสุ่มตัวอย่างของแต่ละองค์ประกอบอย่างมีประสิทธิภาพ
วิธีการสุ่มตัวอย่าง
ภายในกรอบการทำงานประเภทใดก็ตามที่ระบุไว้ข้างต้น สามารถใช้วิธีการสุ่มตัวอย่างได้หลากหลายวิธี ทั้งแบบเดี่ยวหรือแบบผสมผสาน ปัจจัยที่มักมีอิทธิพลต่อการเลือกใช้รูปแบบการออกแบบเหล่านี้ ได้แก่:
- ลักษณะและคุณภาพของกรอบรูป
- ความพร้อมของข้อมูลเพิ่มเติมเกี่ยวกับหน่วยต่างๆ บนเฟรม
- ข้อกำหนดด้านความแม่นยำ และความจำเป็นในการวัดความแม่นยำ
- คาดว่าจะมีการวิเคราะห์ตัวอย่างอย่างละเอียดหรือไม่
- ข้อกังวลด้านต้นทุน/การดำเนินงาน
การสุ่มตัวอย่างแบบง่าย
ในการสุ่มตัวอย่างแบบง่าย (SRS) ที่มีขนาดที่กำหนดไว้ ชุดย่อยทั้งหมดของกรอบการสุ่มตัวอย่างจะมีโอกาสถูกเลือกเท่ากัน ดังนั้นแต่ละองค์ประกอบของกรอบจึงมีโอกาสถูกเลือกเท่ากัน กรอบจะไม่ถูกแบ่งย่อยหรือแยกส่วน ยิ่งไปกว่านั้นคู่ขององค์ประกอบใดๆ ก็ตามจะมีโอกาสถูกเลือกเท่ากับคู่ขององค์ประกอบอื่นๆ (และในทำนองเดียวกันสำหรับสามองค์ประกอบ และอื่นๆ) สิ่งนี้ช่วยลดอคติและทำให้การวิเคราะห์ผลลัพธ์ง่ายขึ้น โดยเฉพาะอย่างยิ่ง ความแปรปรวนระหว่างผลลัพธ์แต่ละรายการภายในตัวอย่างเป็นตัวบ่งชี้ที่ดีของความแปรปรวนในประชากรโดยรวม ซึ่งทำให้การประเมินความถูกต้องของผลลัพธ์ทำได้ค่อนข้างง่าย
การสุ่มตัวอย่างแบบง่ายอาจมีความเสี่ยงต่อข้อผิดพลาดในการสุ่มตัวอย่าง เนื่องจากความสุ่มของการเลือกอาจทำให้ได้ตัวอย่างที่ไม่สะท้อนองค์ประกอบของประชากร ตัวอย่างเช่น การสุ่มตัวอย่างแบบง่ายจากคนสิบคนในประเทศหนึ่งโดยเฉลี่ยแล้ว จะ ได้ผู้ชายห้าคนและผู้หญิงห้าคน แต่การทดลองใดๆ ก็ตามมีแนวโน้มที่จะมีสัดส่วนของเพศใดเพศหนึ่งมากเกินไปและอีกเพศหนึ่งน้อยเกินไป เทคนิคการสุ่มตัวอย่างแบบเป็นระบบและแบบแบ่งชั้นพยายามเอาชนะปัญหานี้โดย "ใช้ข้อมูลเกี่ยวกับประชากร" เพื่อเลือกตัวอย่างที่ "เป็นตัวแทน" มากขึ้น
นอกจากนี้ การสุ่มตัวอย่างแบบสุ่มอย่างง่ายอาจยุ่งยากและน่าเบื่อเมื่อสุ่มตัวอย่างจากประชากรเป้าหมายขนาดใหญ่ ในบางกรณี นักวิจัยสนใจคำถามวิจัยที่เฉพาะเจาะจงกับกลุ่มย่อยของประชากร ตัวอย่างเช่น นักวิจัยอาจสนใจที่จะตรวจสอบว่าความสามารถทางปัญญาในฐานะตัวทำนายประสิทธิภาพในการทำงานนั้นใช้ได้กับกลุ่มเชื้อชาติต่างๆ อย่างเท่าเทียมกันหรือไม่ การสุ่มตัวอย่างแบบสุ่มอย่างง่ายไม่สามารถตอบสนองความต้องการของนักวิจัยในสถานการณ์นี้ได้ เนื่องจากไม่ได้ให้ตัวอย่างย่อยของประชากร และสามารถใช้กลยุทธ์การสุ่มตัวอย่างอื่นๆ เช่น การสุ่มตัวอย่างแบบแบ่งชั้น แทนได้
การสุ่มตัวอย่างอย่างเป็นระบบ

การสุ่มตัวอย่างแบบเป็นระบบ (หรือที่เรียกว่าการสุ่มตัวอย่างแบบช่วง) อาศัยการจัดเรียงประชากรที่ศึกษาตามลำดับที่กำหนดไว้ แล้วเลือกองค์ประกอบในช่วงเวลาปกติจากรายการที่เรียงลำดับนั้น การสุ่มตัวอย่างแบบเป็นระบบเริ่มต้นด้วยการสุ่ม แล้วดำเนินการเลือกองค์ประกอบที่kนับจากนั้นเป็นต้นไป ในกรณีนี้k = (ขนาดประชากร/ขนาดตัวอย่าง) สิ่งสำคัญคือจุดเริ่มต้นไม่ควรเป็นอันดับแรกในรายการ แต่ควรเลือกแบบสุ่มจากองค์ประกอบที่ 1 ถึงkในรายการ ตัวอย่างง่ายๆ คือการเลือกชื่อที่ 10 จากสมุดโทรศัพท์ (ตัวอย่างแบบ 'ทุกๆ 10' หรือที่เรียกว่า 'การสุ่มตัวอย่างแบบข้าม 10')
ตราบใดที่จุดเริ่มต้นเป็นการสุ่มการสุ่มตัวอย่างแบบเป็นระบบก็เป็นประเภทหนึ่งของการสุ่มตัวอย่างแบบความน่าจะเป็นวิธีการนี้ง่ายต่อการนำไปใช้ และการแบ่งชั้นที่เกิดขึ้นสามารถทำให้มีประสิทธิภาพได้หากตัวแปรที่ใช้เรียงลำดับรายการมีความสัมพันธ์กับตัวแปรที่สนใจ การสุ่มตัวอย่างแบบ 'ทุกๆ 10' มีประโยชน์อย่างยิ่งสำหรับการสุ่มตัวอย่างที่มีประสิทธิภาพจากฐานข้อมูล
ตัวอย่างเช่น สมมติว่าเราต้องการสุ่มตัวอย่างผู้คนจากถนนสายยาวที่เริ่มต้นจากย่านยากจน (บ้านเลขที่ 1) และสิ้นสุดในย่านที่มีราคาแพง (บ้านเลขที่ 1000) การสุ่มเลือกที่อยู่แบบสุ่มธรรมดาจากถนนสายนี้ อาจทำให้ได้ตัวอย่างจากย่านที่มีราคาแพงมากเกินไป และตัวอย่างจากย่านที่มีราคาแพงน้อยเกินไป (หรือในทางกลับกัน) ซึ่งจะทำให้ได้ตัวอย่างที่ไม่เป็นตัวแทนที่ดี การเลือก (เช่น) บ้านเลขที่ทุกๆ 10 หลังตามถนน จะช่วยให้ตัวอย่างกระจายตัวอย่างสม่ำเสมอตามความยาวของถนน และเป็นตัวแทนของทุกย่าน (ถ้าเราเริ่มต้นที่บ้านเลขที่ 1 และสิ้นสุดที่บ้านเลขที่ 991 เสมอ ตัวอย่างจะเอนเอียงไปทางย่านที่มีราคาแพงเล็กน้อย การสุ่มเลือกจุดเริ่มต้นระหว่างบ้านเลขที่ 1 และ 10 จะช่วยขจัดความเอนเอียงนี้ได้)
อย่างไรก็ตาม การสุ่มตัวอย่างอย่างเป็นระบบนั้นมีความอ่อนไหวเป็นพิเศษต่อความถี่ของข้อมูลในรายการ หากมีความถี่ของข้อมูลอยู่ และความถี่นั้นเป็นพหุคูณหรือตัวประกอบของช่วงเวลาที่ใช้ ตัวอย่างที่ได้ก็มีแนวโน้มที่จะไม่ เป็น ตัวแทนของประชากรโดยรวม ทำให้วิธีการนี้มีความแม่นยำน้อยกว่าการสุ่มตัวอย่างแบบสุ่มอย่างง่าย
ตัวอย่างเช่น ลองพิจารณาถนนสายหนึ่งที่บ้านเลขที่คี่ทั้งหมดอยู่ทางด้านเหนือ (ราคาแพง) และบ้านเลขที่คู่ทั้งหมดอยู่ทางด้านใต้ (ราคาถูก) ภายใต้แผนการสุ่มตัวอย่างที่กล่าวมาข้างต้น เป็นไปไม่ได้ที่จะได้ตัวอย่างที่เป็นตัวแทนที่ดี บ้านที่สุ่มมาได้จะมาจากด้านเลขที่คี่ราคาแพงทั้งหมด หรือจะมาจากด้านเลขที่คู่ราคาถูก ทั้งหมดเว้นแต่ว่านักวิจัยจะมีความรู้เกี่ยวกับอคตินี้มาก่อนและหลีกเลี่ยงมันโดยการใช้การข้าม (skip) ที่ทำให้มั่นใจได้ว่าจะข้ามไปมาระหว่างสองด้าน (การข้ามที่เป็นเลขคี่ใดๆ ก็ได้)
ข้อเสียอีกประการหนึ่งของการสุ่มตัวอย่างแบบเป็นระบบคือ แม้ในสถานการณ์ที่การสุ่มตัวอย่างแบบเป็นระบบมีความแม่นยำกว่าการสุ่มตัวอย่างแบบสุ่มอย่างง่าย (SRS) คุณสมบัติทางทฤษฎีของวิธีการนี้ทำให้ยากต่อการวัดปริมาณความแม่นยำนั้น (ในสองตัวอย่างของการสุ่มตัวอย่างแบบเป็นระบบที่กล่าวมาข้างต้น ข้อผิดพลาดในการสุ่มตัวอย่างส่วนใหญ่เกิดจากความแปรปรวนระหว่างบ้านที่อยู่ใกล้เคียงกัน – แต่เนื่องจากวิธีการนี้ไม่เคยเลือกบ้านสองหลังที่อยู่ใกล้เคียงกัน ตัวอย่างจึงไม่ให้ข้อมูลใดๆ เกี่ยวกับความแปรปรวนนั้น)
ดังที่กล่าวมาข้างต้น การสุ่มตัวอย่างอย่างเป็นระบบเป็นวิธีการของ EPS (Electronic Sample for Random) เนื่องจากองค์ประกอบทั้งหมดมีโอกาสถูกเลือกเท่ากัน (ในตัวอย่างที่ให้มาคือหนึ่งในสิบ) ไม่ใช่'การสุ่มตัวอย่างแบบสุ่มอย่างง่าย' เพราะเซตย่อยที่มีขนาดเท่ากันแต่ต่างกันจะมีโอกาสถูกเลือกต่างกัน – เช่น เซต {4,14,24,...,994} มีโอกาสถูกเลือกหนึ่งในสิบ แต่เซต {4,13,24,34,...} มีโอกาสถูกเลือกเป็นศูนย์
การสุ่มตัวอย่างอย่างเป็นระบบสามารถปรับใช้กับวิธีการที่ไม่ใช่ EPS ได้เช่นกัน ตัวอย่างเช่น โปรดดูการอภิปรายเกี่ยวกับการสุ่มตัวอย่าง PPS ด้านล่าง
การสุ่มตัวอย่างแบบแบ่งชั้น

เมื่อประชากรประกอบด้วยหมวดหมู่ที่แตกต่างกันหลายหมวดหมู่ กรอบสามารถจัดระเบียบตามหมวดหมู่เหล่านี้เป็น "ชั้น" ที่แยกจากกันได้ จากนั้นแต่ละชั้นจะถูกสุ่มตัวอย่างเป็นประชากรย่อยอิสระ ซึ่งสามารถเลือกองค์ประกอบแต่ละรายการแบบสุ่มได้[ 8 ]อัตราส่วนของขนาดของการเลือกแบบสุ่ม (หรือตัวอย่าง) ต่อขนาดของประชากรเรียกว่าเศษส่วนการสุ่มตัวอย่าง [ 12 ]การสุ่มตัวอย่างแบบแบ่งชั้นมีประโยชน์หลายประการ[ 12 ]
ประการแรก การแบ่งประชากรออกเป็นกลุ่มย่อยที่แตกต่างและเป็นอิสระต่อกัน จะช่วยให้นักวิจัยสามารถสรุปผลเกี่ยวกับกลุ่มย่อยเฉพาะเจาะจงได้ ซึ่งอาจสูญหายไปหากใช้กลุ่มตัวอย่างแบบสุ่มทั่วไป
ประการที่สอง การใช้การสุ่มตัวอย่างแบบแบ่งชั้นสามารถนำไปสู่การประมาณค่าทางสถิติที่มีประสิทธิภาพมากขึ้น (โดยมีเงื่อนไขว่าชั้นต่างๆ จะถูกเลือกโดยพิจารณาจากความเกี่ยวข้องกับเกณฑ์ที่ต้องการตรวจสอบ แทนที่จะพิจารณาจากจำนวนตัวอย่างที่มีอยู่) แม้ว่าวิธีการสุ่มตัวอย่างแบบแบ่งชั้นจะไม่นำไปสู่ประสิทธิภาพทางสถิติที่เพิ่มขึ้น แต่กลยุทธ์ดังกล่าวก็จะไม่ทำให้ประสิทธิภาพลดลงไปกว่าการสุ่มตัวอย่างแบบสุ่มธรรมดา ตราบใดที่แต่ละชั้นมีสัดส่วนที่เหมาะสมกับขนาดของกลุ่มในประชากร
ประการที่สาม บางครั้งข้อมูลอาจหาได้ง่ายกว่าสำหรับกลุ่มย่อยที่มีอยู่แล้วภายในประชากร มากกว่าสำหรับประชากรโดยรวม ในกรณีเช่นนี้ การใช้การสุ่มตัวอย่างแบบแบ่งชั้นอาจสะดวกกว่าการรวบรวมข้อมูลจากหลายกลุ่ม (แม้ว่าสิ่งนี้อาจขัดแย้งกับความสำคัญของการใช้กลุ่มย่อยที่เกี่ยวข้องกับเกณฑ์ที่กล่าวไว้ก่อนหน้านี้ก็ตาม)
สุดท้ายนี้ เนื่องจากแต่ละกลุ่มย่อยถือเป็นประชากรอิสระ จึงสามารถใช้วิธีการสุ่มตัวอย่างที่แตกต่างกันกับกลุ่มย่อยต่างๆ ได้ ซึ่งอาจช่วยให้นักวิจัยสามารถใช้วิธีการที่เหมาะสมที่สุด (หรือคุ้มค่าที่สุด) สำหรับแต่ละกลุ่มย่อยที่ระบุไว้ภายในประชากรได้
อย่างไรก็ตาม การใช้การสุ่มตัวอย่างแบบแบ่งชั้นอาจมีข้อเสียอยู่บ้าง ประการแรก การระบุชั้นและการนำวิธีการดังกล่าวไปใช้ อาจเพิ่มต้นทุนและความซับซ้อนในการเลือกตัวอย่าง รวมถึงทำให้การประมาณค่าประชากรมีความซับซ้อนมากขึ้น ประการที่สอง เมื่อพิจารณาเกณฑ์หลายประการ ตัวแปรที่ใช้ในการแบ่งชั้นอาจมีความสัมพันธ์กับบางเกณฑ์ แต่ไม่มีความสัมพันธ์กับเกณฑ์อื่น ซึ่งจะทำให้การออกแบบซับซ้อนยิ่งขึ้น และอาจลดประโยชน์ของการแบ่งชั้นลงได้ ประการสุดท้าย ในบางกรณี (เช่น การออกแบบที่มีจำนวนชั้นมาก หรือการออกแบบที่มีขนาดตัวอย่างขั้นต่ำต่อกลุ่มที่กำหนดไว้) การสุ่มตัวอย่างแบบแบ่งชั้นอาจต้องใช้ตัวอย่างขนาดใหญ่กว่าวิธีการอื่น (แม้ว่าในกรณีส่วนใหญ่ ขนาดตัวอย่างที่ต้องการจะไม่ใหญ่ไปกว่าที่จำเป็นสำหรับการสุ่มตัวอย่างแบบสุ่มอย่างง่าย)
- วิธีการสุ่มตัวอย่างแบบแบ่งชั้นจะมีประสิทธิภาพมากที่สุดเมื่อตรงตามเงื่อนไขสามประการนี้
- ความแปรปรวนภายในชั้นต่างๆ จะลดลงเหลือน้อยที่สุด
- ความแปรปรวนระหว่างชั้นต่างๆ มีค่าสูงสุด
- ตัวแปรที่ใช้ในการแบ่งกลุ่มประชากรมีความสัมพันธ์อย่างมากกับตัวแปรตามที่ต้องการ
- ข้อดีเหนือกว่าวิธีการสุ่มตัวอย่างแบบอื่น
- มุ่งเน้นกลุ่มประชากรย่อยที่สำคัญและละเลยกลุ่มที่ไม่เกี่ยวข้อง
- ช่วยให้สามารถใช้เทคนิคการสุ่มตัวอย่างที่แตกต่างกันสำหรับกลุ่มประชากรย่อยต่างๆ ได้
- ช่วยเพิ่มความแม่นยำ/ประสิทธิภาพในการประมาณการ
- ช่วยให้สามารถสร้างความสมดุลของกำลังทางสถิติในการทดสอบความแตกต่างระหว่างกลุ่มย่อยได้ดียิ่งขึ้น โดยการสุ่มตัวอย่างจำนวนเท่ากันจากกลุ่มย่อยที่มีขนาดแตกต่างกันอย่างมาก
- ข้อเสีย
- จำเป็นต้องเลือกตัวแปรการแบ่งกลุ่มที่เกี่ยวข้อง ซึ่งอาจเป็นเรื่องยาก
- วิธีนี้ใช้ไม่ได้ผลเมื่อไม่มีกลุ่มย่อยที่เป็นเนื้อเดียวกัน
- การนำไปปฏิบัติอาจมีค่าใช้จ่ายสูง
- การแบ่งชั้นภายหลัง
บางครั้งการแบ่งชั้นจะถูกนำมาใช้หลังจากขั้นตอนการสุ่มตัวอย่างในกระบวนการที่เรียกว่า "การแบ่งชั้นภายหลัง" [ 8 ]โดยทั่วไปแล้ววิธีการนี้จะถูกนำมาใช้เนื่องจากขาดความรู้ล่วงหน้าเกี่ยวกับตัวแปรการแบ่งชั้นที่เหมาะสม หรือเมื่อผู้ทำการทดลองขาดข้อมูลที่จำเป็นในการสร้างตัวแปรการแบ่งชั้นในระหว่างขั้นตอนการสุ่มตัวอย่าง แม้ว่าวิธีการนี้จะมีความเสี่ยงต่อข้อผิดพลาดของวิธีการภายหลัง แต่ก็สามารถให้ประโยชน์หลายประการในสถานการณ์ที่เหมาะสม การดำเนินการมักจะตามหลังการสุ่มตัวอย่างแบบสุ่มอย่างง่าย นอกจากการอนุญาตให้มีการแบ่งชั้นตามตัวแปรเสริมแล้ว การแบ่งชั้นภายหลังยังสามารถใช้เพื่อดำเนินการถ่วงน้ำหนัก ซึ่งสามารถปรับปรุงความแม่นยำของการประมาณค่าของตัวอย่างได้[ 8 ]
- การสุ่มตัวอย่างเกิน
การสุ่มตัวอย่างตามตัวเลือกหรือการสุ่มตัวอย่างเกินเป็นหนึ่งในกลยุทธ์การสุ่มตัวอย่างแบบแบ่งชั้น ในการสุ่มตัวอย่างตามตัวเลือก[ 13 ]ข้อมูลจะถูกแบ่งชั้นตามเป้าหมาย และจะมีการสุ่มตัวอย่างจากแต่ละชั้นเพื่อให้คลาสเป้าหมายที่หายากกว่ามีสัดส่วนในตัวอย่างมากขึ้น จากนั้นจึงสร้างแบบจำลองบนตัวอย่างที่มีอคติ นี้ ผลกระทบของตัวแปรอินพุตต่อเป้าหมายมักจะได้รับการประมาณค่าด้วยความแม่นยำที่มากขึ้นด้วยการสุ่มตัวอย่างตามตัวเลือก แม้ว่าจะใช้ขนาดตัวอย่างโดยรวมที่เล็กกว่าเมื่อเทียบกับการสุ่มตัวอย่างแบบสุ่ม ผลลัพธ์มักจะต้องได้รับการปรับเพื่อแก้ไขการสุ่มตัวอย่างเกิน
การสุ่มตัวอย่างตามสัดส่วนของขนาด
ในบางกรณี ผู้ออกแบบตัวอย่างสามารถเข้าถึง "ตัวแปรเสริม" หรือ "มาตรวัดขนาด" ซึ่งเชื่อว่ามีความสัมพันธ์กับตัวแปรที่สนใจ สำหรับแต่ละองค์ประกอบในประชากร ข้อมูลเหล่านี้สามารถนำมาใช้เพื่อปรับปรุงความแม่นยำในการออกแบบตัวอย่าง ทางเลือกหนึ่งคือการใช้ตัวแปรเสริมเป็นพื้นฐานสำหรับการแบ่งชั้นตามที่ได้กล่าวไว้ข้างต้น
อีกทางเลือกหนึ่งคือการสุ่มตัวอย่างแบบสัดส่วนตามขนาด ('PPS') ซึ่งความน่าจะเป็นในการเลือกแต่ละองค์ประกอบจะถูกกำหนดให้เป็นสัดส่วนกับขนาดขององค์ประกอบนั้น โดยมีค่าสูงสุดไม่เกิน 1 ในการออกแบบ PPS แบบง่าย ความน่าจะเป็นในการเลือกเหล่านี้สามารถนำมาใช้เป็นพื้นฐานสำหรับการสุ่มตัวอย่างแบบปัวซงได้อย่างไรก็ตาม วิธีนี้มีข้อเสียคือขนาดตัวอย่างไม่แน่นอน และส่วนต่างๆ ของประชากรอาจยังคงถูกเลือกมากเกินไปหรือน้อยเกินไปเนื่องจากความผันแปรโดยบังเอิญในการเลือก
ทฤษฎีการสุ่มตัวอย่างอย่างเป็นระบบสามารถนำมาใช้สร้างตัวอย่างที่มีความน่าจะเป็นตามขนาดได้ โดยจะถือว่าจำนวนแต่ละจำนวนภายในตัวแปรขนาดเป็นหน่วยการสุ่มตัวอย่างเดียว จากนั้นจึงระบุตัวอย่างโดยการเลือกในช่วงเวลาที่เท่ากันระหว่างจำนวนเหล่านั้นภายในตัวแปรขนาด วิธีนี้บางครั้งเรียกว่าการสุ่มตัวอย่างแบบลำดับ PPS หรือการสุ่มตัวอย่างตามหน่วยเงินในกรณีของการตรวจสอบหรือการสุ่มตัวอย่างทางนิติวิทยาศาสตร์
ตัวอย่าง: สมมติว่าเรามีโรงเรียนหกแห่ง โดยแต่ละแห่งมีจำนวนนักเรียน 150, 180, 200, 220, 260 และ 490 คน ตามลำดับ (รวมทั้งหมด 1500 คน) และเราต้องการใช้จำนวนนักเรียนเป็นพื้นฐานสำหรับการสุ่มตัวอย่างแบบ PPS ขนาดสาม ในการทำเช่นนี้ เราสามารถกำหนดหมายเลขให้กับโรงเรียนแรกตั้งแต่ 1 ถึง 150 โรงเรียนที่สองตั้งแต่ 151 ถึง 330 (= 150 + 180) โรงเรียนที่สามตั้งแต่ 331 ถึง 530 และต่อไปเรื่อยๆ จนถึงโรงเรียนสุดท้าย (1011 ถึง 1500) จากนั้นเราสุ่มเลือกหมายเลขเริ่มต้นระหว่าง 1 ถึง 500 (เท่ากับ 1500/3) และนับจำนวนนักเรียนไปตามจำนวนทวีคูณของ 500 ถ้าหมายเลขเริ่มต้นที่เราสุ่มได้คือ 137 เราจะเลือกโรงเรียนที่ได้รับหมายเลข 137, 637 และ 1137 นั่นคือโรงเรียนที่หนึ่ง ที่สี่ และที่หก
วิธีการ PPS สามารถปรับปรุงความแม่นยำสำหรับขนาดตัวอย่างที่กำหนดได้โดยการเน้นตัวอย่างไปที่องค์ประกอบขนาดใหญ่ที่มีผลกระทบมากที่สุดต่อการประมาณค่าประชากร การสุ่มตัวอย่างแบบ PPS มักใช้สำหรับการสำรวจธุรกิจ ซึ่งขนาดขององค์ประกอบแตกต่างกันอย่างมากและมักมีข้อมูลเสริมให้ใช้ได้ ตัวอย่างเช่น การสำรวจที่พยายามวัดจำนวนคืนที่แขกเข้าพักในโรงแรมอาจใช้จำนวนห้องของแต่ละโรงแรมเป็นตัวแปรเสริม ในบางกรณี การวัดค่าตัวแปรที่สนใจในอดีตสามารถใช้เป็นตัวแปรเสริมได้เมื่อพยายามสร้างค่าประมาณที่เป็นปัจจุบันมากขึ้น[ 14 ]
การสุ่มตัวอย่างแบบคลัสเตอร์

บางครั้งการเลือกผู้ตอบแบบสอบถามเป็นกลุ่ม (คลัสเตอร์) อาจประหยัดค่าใช้จ่ายมากกว่า การสุ่มตัวอย่างมักทำเป็นกลุ่มตามภูมิศาสตร์หรือตามช่วงเวลา (ตัวอย่างเกือบทั้งหมดมีการ 'จัดกลุ่ม' ตามช่วงเวลาในบางแง่ แม้ว่าโดยทั่วไปแล้วจะไม่ค่อยนำมาพิจารณาในการวิเคราะห์ก็ตาม) ตัวอย่างเช่น หากสำรวจครัวเรือนในเมือง เราอาจเลือก 100 บล็อกในเมือง แล้วสัมภาษณ์ทุกครัวเรือนในบล็อกที่เลือกไว้
การจัดกลุ่มสามารถลดค่าใช้จ่ายในการเดินทางและค่าใช้จ่ายด้านการบริหารจัดการได้ ในตัวอย่างข้างต้น ผู้สัมภาษณ์สามารถเดินทางไปเยี่ยมหลายบ้านในบล็อกเดียวกันได้ในครั้งเดียว แทนที่จะต้องขับรถไปยังบล็อกอื่นเพื่อสัมภาษณ์แต่ละบ้าน
นอกจากนี้ยังหมายความว่าไม่จำเป็นต้องมีกรอบการสุ่มตัวอย่างที่ระบุองค์ประกอบทั้งหมดในประชากรเป้าหมาย แต่สามารถเลือกกลุ่มจากกรอบระดับกลุ่มได้ โดยสร้างกรอบระดับองค์ประกอบเฉพาะสำหรับกลุ่มที่เลือกไว้เท่านั้น ในตัวอย่างข้างต้น ตัวอย่างต้องการเพียงแผนที่เมืองระดับบล็อกสำหรับการเลือกเบื้องต้น จากนั้นจึงใช้แผนที่ระดับครัวเรือนของ 100 บล็อกที่เลือกไว้ แทนที่จะใช้แผนที่ระดับครัวเรือนของทั้งเมือง
การสุ่มตัวอย่างแบบกลุ่ม (หรือที่เรียกว่าการสุ่มตัวอย่างแบบคลัสเตอร์) โดยทั่วไปจะเพิ่มความแปรปรวนของการประมาณค่าจากตัวอย่างมากกว่าการสุ่มตัวอย่างแบบสุ่มธรรมดา ขึ้นอยู่กับว่าคลัสเตอร์แต่ละกลุ่มแตกต่างกันอย่างไรเมื่อเทียบกับความแปรปรวนภายในคลัสเตอร์ ด้วยเหตุนี้ การสุ่มตัวอย่างแบบกลุ่มจึงต้องใช้ตัวอย่างขนาดใหญ่กว่าการสุ่มตัวอย่างแบบสุ่มธรรมดาเพื่อให้ได้ระดับความแม่นยำเดียวกัน แต่การประหยัดต้นทุนจากการจัดกลุ่มอาจทำให้วิธีนี้ยังคงเป็นทางเลือกที่ถูกกว่า
การสุ่มตัวอย่างแบบกลุ่ม (Cluster sampling)มักถูกนำมาใช้ใน รูปแบบของ การสุ่มตัวอย่างแบบหลายขั้นตอนซึ่งเป็นรูปแบบที่ซับซ้อนของการสุ่มตัวอย่างแบบกลุ่ม โดยมีหน่วยย่อยสองระดับขึ้นไปซ้อนกันอยู่ ขั้นตอนแรกคือการสร้างกลุ่มที่จะใช้ในการสุ่มตัวอย่าง ในขั้นตอนที่สอง จะสุ่มเลือกหน่วยตัวอย่างหลักจากแต่ละกลุ่ม (แทนที่จะใช้หน่วยทั้งหมดที่อยู่ในกลุ่มที่เลือกไว้) ในขั้นตอนต่อๆ ไป จะสุ่มเลือกหน่วยตัวอย่างเพิ่มเติมในแต่ละกลุ่มที่เลือกไว้ และเป็นเช่นนี้เรื่อยไป จนกระทั่งถึงหน่วยสุดท้ายทั้งหมด (เช่น บุคคล) ที่เลือกไว้ในขั้นตอนสุดท้ายของกระบวนการนี้ จึงทำให้เทคนิคนี้โดยพื้นฐานแล้วคือกระบวนการสุ่มตัวอย่างย่อยจากตัวอย่างสุ่มก่อนหน้า
การสุ่มตัวอย่างแบบหลายขั้นตอนสามารถลดต้นทุนการสุ่มตัวอย่างได้อย่างมาก โดยที่ต้องสร้างรายการประชากรทั้งหมด (ก่อนที่จะใช้วิธีการสุ่มตัวอย่างอื่นๆ) การสุ่มตัวอย่างแบบหลายขั้นตอนสามารถลดต้นทุนจำนวนมากที่เกี่ยวข้องกับการสุ่มตัวอย่างแบบคลัสเตอร์แบบดั้งเดิมได้ โดยการกำจัดงานที่เกี่ยวข้องกับการอธิบายคลัสเตอร์ที่ไม่ได้รับการเลือก[ 14 ]อย่างไรก็ตาม ตัวอย่างแต่ละตัวอาจไม่ได้เป็นตัวแทนที่สมบูรณ์ของประชากรทั้งหมด
การสุ่มตัวอย่างแบบโควต้า
ในการสุ่มตัวอย่างแบบโควตาประชากรจะถูกแบ่งออกเป็นกลุ่มย่อยที่ไม่ซ้ำซ้อนกัน ก่อน เช่นเดียวกับ การสุ่มตัวอย่างแบบแบ่งชั้นจากนั้นจึงใช้ดุลยพินิจในการเลือกกลุ่มตัวอย่างหรือหน่วยจากแต่ละกลุ่มตามสัดส่วนที่กำหนด ตัวอย่างเช่น ผู้สัมภาษณ์อาจได้รับคำสั่งให้สุ่มตัวอย่างหญิง 200 คนและชาย 300 คนที่มีอายุระหว่าง 45 ถึง 60 ปี
ขั้นตอนที่สองนี้เองที่ทำให้เทคนิคนี้เป็นการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น ในการสุ่มตัวอย่างแบบโควตา การเลือกตัวอย่างไม่ได้เป็นการสุ่มตัวอย่างเช่น ผู้สัมภาษณ์อาจถูกล่อใจให้สัมภาษณ์ผู้ที่ดูให้ความช่วยเหลือมากที่สุด ปัญหาคือตัวอย่างเหล่านี้อาจมีความลำเอียงเพราะไม่ใช่ทุกคนจะมีโอกาสถูกเลือก องค์ประกอบแบบสุ่มนี้เป็นจุดอ่อนที่สำคัญที่สุด และการสุ่มตัวอย่างแบบโควตาเทียบกับการสุ่มตัวอย่างแบบใช้ความน่าจะเป็นเป็นประเด็นถกเถียงกันมาหลายปีแล้ว
การสุ่มตัวอย่างแบบมินิแม็กซ์
ในชุดข้อมูลที่ไม่สมดุล ซึ่งอัตราส่วนการสุ่มตัวอย่างไม่เป็นไปตามสถิติของประชากร เราสามารถสุ่มตัวอย่างชุดข้อมูลใหม่ในลักษณะอนุรักษ์นิยมที่เรียกว่าการสุ่มตัวอย่างแบบมินิแม็กซ์การสุ่มตัวอย่างแบบมินิแม็กซ์มีที่มาจากอัตราส่วนมินิแม็กซ์ของแอนเดอร์สัน ซึ่งพิสูจน์แล้วว่ามีค่าเท่ากับ 0.5: ในการจำแนกแบบไบนารี ขนาดตัวอย่างของแต่ละคลาสควรถูกเลือกให้เท่ากัน อัตราส่วนนี้สามารถพิสูจน์ได้ว่าเป็นอัตราส่วนมินิแม็กซ์ภายใต้สมมติฐานของตัวจำแนก LDAที่มีการกระจายแบบเกาส์เซียนเท่านั้น แนวคิดของการสุ่มตัวอย่างแบบมินิแม็กซ์ได้รับการพัฒนาขึ้นเมื่อเร็ว ๆ นี้สำหรับกฎการจำแนกประเภททั่วไปที่เรียกว่าตัวจำแนกอัจฉริยะแบบคลาส ในกรณีนี้ อัตราส่วนการสุ่มตัวอย่างของคลาสจะถูกเลือกเพื่อให้ข้อผิดพลาดของตัวจำแนกกรณีที่เลวร้ายที่สุดเหนือสถิติของประชากรที่เป็นไปได้ทั้งหมดสำหรับความน่าจะเป็นก่อนหน้าของคลาสจะเป็นค่าที่ดีที่สุด[ 12 ]
การสุ่มตัวอย่างโดยบังเอิญ
การสุ่มตัวอย่างโดยบังเอิญ (บางครั้งเรียกว่า การสุ่มตัวอย่าง แบบคว้า การ สุ่มตัวอย่าง แบบสะดวกหรือการสุ่มตัวอย่างแบบโอกาส ) เป็นการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็นประเภทหนึ่ง ซึ่งเกี่ยวข้องกับการเลือกตัวอย่างจากส่วนของประชากรที่อยู่ใกล้ตัว กล่าวคือ เลือกประชากรเพราะหาได้ง่ายและสะดวก อาจเป็นการพบปะกับบุคคลนั้น หรือรวมบุคคลนั้นไว้ในตัวอย่างเมื่อได้พบกัน หรือเลือกโดยการค้นหาผ่านวิธีการทางเทคโนโลยี เช่น อินเทอร์เน็ต หรือทางโทรศัพท์ นักวิจัยที่ใช้ตัวอย่างประเภทนี้ไม่สามารถสรุปผลทางวิทยาศาสตร์เกี่ยวกับประชากรทั้งหมดจากตัวอย่างนี้ได้ เพราะตัวอย่างนั้นจะไม่เป็นตัวแทนที่เพียงพอ ตัวอย่างเช่น หากผู้สัมภาษณ์ทำการสำรวจที่ศูนย์การค้าในช่วงเช้าของวันใดวันหนึ่ง ผู้คนที่พวกเขาสามารถสัมภาษณ์ได้จะจำกัดอยู่เฉพาะผู้ที่อยู่ที่นั่นในเวลานั้น ซึ่งจะไม่เป็นตัวแทนความคิดเห็นของสมาชิกคนอื่นๆ ในสังคมในพื้นที่นั้น หากทำการสำรวจในเวลาต่างๆ ของวันและหลายครั้งต่อสัปดาห์ การสุ่มตัวอย่างประเภทนี้มีประโยชน์มากที่สุดสำหรับการทดสอบนำร่อง ข้อควรพิจารณาที่สำคัญหลายประการสำหรับนักวิจัยที่ใช้ตัวอย่างแบบสะดวก ได้แก่:
- มีกลไกควบคุมใดบ้างในการออกแบบการวิจัยหรือการทดลองที่สามารถช่วยลดผลกระทบของกลุ่มตัวอย่างที่ไม่สุ่มและได้มาโดยสะดวก เพื่อให้มั่นใจได้ว่าผลลัพธ์จะเป็นตัวแทนของประชากรได้ดียิ่งขึ้น?
- มีเหตุผลอันควรเชื่อหรือไม่ว่ากลุ่มตัวอย่างที่เลือกมาโดยสะดวกกลุ่มใดกลุ่มหนึ่งจะตอบสนองหรือมีพฤติกรรมแตกต่างไปจากกลุ่มตัวอย่างแบบสุ่มจากประชากรกลุ่มเดียวกัน?
- คำถามที่งานวิจัยนี้ถามนั้น สามารถหาคำตอบได้อย่างเพียงพอโดยใช้กลุ่มตัวอย่างแบบสะดวกหรือไม่?
In social science research, snowball sampling is a similar technique, where existing study subjects are used to recruit more subjects into the sample. Some variants of snowball sampling, such as respondent driven sampling, allow calculation of selection probabilities and are probability sampling methods under certain conditions.
Voluntary sampling
The voluntary sampling method is a type of nonprobability sampling. Volunteers choose to complete a survey.
Volunteers may be invited through advertisements in social media.[15] The target population for advertisements can be selected by characteristics like location, age, sex, income, occupation, education, or interests using tools provided by the social medium. The advertisement may include a message about the research and link to a survey. After following the link and completing the survey, the volunteer submits the data to be included in the sample population. This method can reach a global population but is limited by the campaign budget. Volunteers outside the invited population may also be included in the sample.
It is difficult to make generalizations from this sample because it may not represent the total population. Often, volunteers have a strong interest in the main topic of the survey.
Line-intercept sampling
Line-intercept sampling is a method of sampling elements in a region whereby an element is sampled if a chosen line segment, called a "transect", intersects the element.
Panel sampling
Panel sampling is the method of first selecting a group of participants through a random sampling method and then asking that group for (potentially the same) information several times over a period of time. Therefore, each participant is interviewed at two or more time points; each period of data collection is called a "wave". The method was developed by sociologist Paul Lazarsfeld in 1938 as a means of studying political campaigns.[16] This longitudinal sampling-method allows estimates of changes in the population, for example with regard to chronic illness to job stress to weekly food expenditures. Panel sampling can also be used to inform researchers about within-person health changes due to age or to help explain changes in continuous dependent variables such as spousal interaction.[17] There have been several proposed methods of analyzing panel data, including MANOVA, growth curves, and structural equation modeling with lagged effects.
Snowball sampling
การสุ่มตัวอย่างแบบลูกโซ่ (Snowball sampling) คือการหาผู้ตอบแบบสอบถามกลุ่มเล็กๆ ในช่วงเริ่มต้น และใช้กลุ่มนั้นในการสรรหาผู้ตอบแบบสอบถามเพิ่มเติม วิธีนี้มีประโยชน์อย่างยิ่งในกรณีที่ประชากรซ่อนตัวอยู่หรือยากต่อการนับจำนวน
การสุ่มตัวอย่างเชิงทฤษฎี
การสุ่มตัวอย่างเชิงทฤษฎี[ 18 ]เกิดขึ้นเมื่อมีการเลือกตัวอย่างตามผลลัพธ์ของข้อมูลที่รวบรวมไว้จนถึงปัจจุบัน โดยมีเป้าหมายเพื่อพัฒนาความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับพื้นที่หรือพัฒนาทฤษฎี โดยจะรวบรวมตัวอย่างทั่วไปเบื้องต้นก่อน โดยมีเป้าหมายเพื่อตรวจสอบแนวโน้มทั่วไป ซึ่งการสุ่มตัวอย่างเพิ่มเติมอาจประกอบด้วยกรณีสุดขั้วหรือกรณีเฉพาะเจาะจงมาก ๆ ซึ่งอาจเลือกเพื่อเพิ่มโอกาสสูงสุดที่ปรากฏการณ์จะสามารถสังเกตได้จริง
การสุ่มตัวอย่างเชิงรุก
ในการสุ่มตัวอย่างแบบแอคทีฟตัวอย่างที่ใช้ในการฝึกอัลกอริธึมการเรียนรู้ของเครื่องจะถูกเลือกอย่างกระตือรือร้น ซึ่งสามารถนำมาเปรียบเทียบกับการเรียนรู้แบบแอคทีฟ (การเรียนรู้ของเครื่อง)ได้ เช่นกัน
การเลือกโดยใช้ดุลยพินิจ
การสุ่มตัวอย่างโดยใช้ดุลยพินิจ หรือที่รู้จักกันในชื่อการสุ่มตัวอย่างโดยผู้เชี่ยวชาญหรือการสุ่มตัวอย่างแบบเจาะจง เป็นรูปแบบหนึ่งของการสุ่มตัวอย่างที่ไม่ใช่แบบสุ่ม โดยตัวอย่างจะถูกเลือกตามความคิดเห็นของผู้เชี่ยวชาญ ซึ่งสามารถเลือกผู้เข้าร่วมได้โดยพิจารณาจากคุณค่าของข้อมูลที่พวกเขานำเสนอ
การสุ่มตัวอย่างแบบสุ่ม
การสุ่มตัวอย่างแบบสุ่มหมายถึงแนวคิดในการใช้การตัดสินใจของมนุษย์เพื่อจำลองความสุ่ม แม้ว่าตัวอย่างจะถูกเลือกด้วยมือ แต่เป้าหมายคือเพื่อให้แน่ใจว่าไม่มีอคติโดยเจตนาในการเลือกตัวอย่าง แต่มักจะล้มเหลวเนื่องจากอคติในการเลือก [ 19 ] โดยทั่วไปแล้วการสุ่มตัวอย่างแบบสุ่มมักถูกเลือกใช้เนื่องจากความสะดวก เมื่อไม่มีเครื่องมือหรือความสามารถในการ ดำเนินการวิธีการสุ่มตัวอย่างอื่น ๆ
จุดอ่อนสำคัญของตัวอย่างดังกล่าวคือมักจะไม่แสดงถึงลักษณะของประชากรทั้งหมด แต่เป็นเพียงส่วนหนึ่งของประชากรเท่านั้น เนื่องจากการเป็นตัวแทนที่ไม่สมดุลนี้ ผลลัพธ์จากการสุ่มตัวอย่างแบบสุ่มจึงมักมีอคติ[ 20 ]
การเปลี่ยนชิ้นส่วนที่เลือก
วิธีการสุ่มตัวอย่างอาจเป็นแบบไม่ใส่คืน ('WOR' – ไม่สามารถเลือกองค์ประกอบใด ๆ ได้มากกว่าหนึ่งครั้งในตัวอย่างเดียวกัน) หรือแบบใส่คืน ('WR' – องค์ประกอบหนึ่งอาจปรากฏหลายครั้งในตัวอย่างเดียว) ตัวอย่างเช่น หากเราจับปลา วัดขนาด แล้วปล่อยกลับลงน้ำทันทีก่อนที่จะดำเนินการสุ่มตัวอย่างต่อไป นี่คือการออกแบบแบบ WR เพราะเราอาจจับและวัดขนาดปลาตัวเดียวกันได้มากกว่าหนึ่งครั้ง อย่างไรก็ตาม หากเราไม่ปล่อยปลากลับลงน้ำ หรือไม่ติดแท็กและปล่อยปลาแต่ละตัวหลังจากจับได้ นี่จะกลายเป็นการออกแบบแบบ WOR
การกำหนดขนาดตัวอย่าง
สูตร ตาราง และแผนภูมิฟังก์ชันกำลัง เป็นวิธีการที่รู้จักกันดีในการกำหนดขนาดตัวอย่าง
ขั้นตอนการใช้ตารางขนาดตัวอย่าง:
- สมมติขนาดผลกระทบที่สนใจ α และ β
- ตรวจสอบตารางขนาดตัวอย่าง[ 21 ]
- เลือกตารางที่ตรงกับค่า α ที่เลือกไว้
- ค้นหาแถวที่ตรงกับกำลังไฟฟ้าที่ต้องการ
- ค้นหาคอลัมน์ที่ตรงกับขนาดผลกระทบที่ประเมินไว้
- จุดตัดระหว่างคอลัมน์และแถวคือขนาดตัวอย่างขั้นต่ำที่ต้องการ
การสุ่มตัวอย่างและการเก็บรวบรวมข้อมูล
การเก็บรวบรวมข้อมูลที่ดีนั้นประกอบด้วย:
- ปฏิบัติตามกระบวนการสุ่มตัวอย่างที่กำหนดไว้
- การจัดเรียงข้อมูลตามลำดับเวลา
- จดบันทึกความคิดเห็นและเหตุการณ์อื่นๆ ที่เกี่ยวข้อง
- การบันทึกกรณีที่ไม่ตอบสนอง
การประยุกต์ใช้การสุ่มตัวอย่าง
การสุ่มตัวอย่างช่วยให้สามารถเลือกจุดข้อมูลที่เหมาะสมจากชุดข้อมูลขนาดใหญ่เพื่อประมาณลักษณะของประชากรทั้งหมดได้ ตัวอย่างเช่น มีทวีตประมาณ 600 ล้านทวีตที่ถูกสร้างขึ้นทุกวัน ไม่จำเป็นต้องดูทวีตทั้งหมดเพื่อกำหนดหัวข้อที่ถูกพูดคุยกันในแต่ละวัน และไม่จำเป็นต้องดูทวีตทั้งหมดเพื่อกำหนดความรู้สึกต่อแต่ละหัวข้อ มีการพัฒนาสูตรทางทฤษฎีสำหรับการสุ่มตัวอย่างข้อมูล Twitter [ 22 ]
ในกระบวนการผลิต ข้อมูลจากเซ็นเซอร์ประเภทต่างๆ เช่น เสียง การสั่นสะเทือน ความดัน กระแสไฟฟ้า แรงดันไฟฟ้า และข้อมูลจากตัวควบคุม จะมีให้ใช้งานในช่วงเวลาสั้นๆ การคาดการณ์เวลาหยุดทำงานอาจไม่จำเป็นต้องพิจารณาข้อมูลทั้งหมด แต่การพิจารณาข้อมูลเพียงบางส่วนก็อาจเพียงพอแล้ว
ข้อผิดพลาดในการสำรวจตัวอย่าง
ผลการสำรวจมักมีความคลาดเคลื่อนอยู่บ้าง ความคลาดเคลื่อนทั้งหมดสามารถแบ่งออกเป็นความคลาดเคลื่อนจากการสุ่มตัวอย่างและความคลาดเคลื่อนที่ไม่ได้เกิดจากการสุ่มตัวอย่าง คำว่า "ความคลาดเคลื่อน" ในที่นี้รวมถึงความคลาดเคลื่อนที่เป็นระบบและความคลาดเคลื่อนแบบสุ่มด้วย
ข้อผิดพลาดและอคติในการสุ่มตัวอย่าง
ข้อผิดพลาดและความลำเอียงในการสุ่มตัวอย่างเกิดจากการออกแบบการสุ่มตัวอย่าง ซึ่งได้แก่:
- อคติในการเลือก : เมื่อความน่าจะเป็นในการเลือกที่แท้จริงแตกต่างจากความน่าจะเป็นที่ใช้ในการคำนวณผลลัพธ์
- ข้อผิดพลาดจากการสุ่มตัวอย่าง : ความผันแปรแบบสุ่มในผลลัพธ์เนื่องจากองค์ประกอบในตัวอย่างถูกเลือกแบบสุ่ม
ข้อผิดพลาดที่ไม่เกี่ยวข้องกับการสุ่มตัวอย่าง
ข้อผิดพลาดที่ไม่เกี่ยวข้องกับการสุ่มตัวอย่าง คือข้อผิดพลาดอื่นๆ ที่อาจส่งผลกระทบต่อค่าประมาณการสำรวจขั้นสุดท้าย ซึ่งเกิดจากปัญหาในการเก็บรวบรวมข้อมูล การประมวลผล หรือการออกแบบตัวอย่าง ข้อผิดพลาดดังกล่าวอาจรวมถึง:
- การครอบคลุมเกินขอบเขต: การรวมข้อมูลจากนอกกลุ่มประชากร
- การครอบคลุมไม่ครบถ้วน: กรอบการสุ่มตัวอย่างไม่ครอบคลุมองค์ประกอบบางส่วนในประชากร
- ข้อผิดพลาดในการวัด: เช่น เมื่อผู้ตอบแบบสอบถามเข้าใจคำถามผิด หรือพบว่าตอบคำถามได้ยาก
- ข้อผิดพลาดในการประมวลผล: ข้อผิดพลาดในการเข้ารหัสข้อมูล
- อคติจากการไม่ตอบสนองหรือการมีส่วนร่วม : ความล้มเหลวในการได้รับข้อมูลที่ครบถ้วนจากบุคคลที่เลือกทั้งหมด
หลังจากเก็บตัวอย่างแล้ว จะมีการทบทวนกระบวนการที่ใช้ในการเก็บตัวอย่างอย่างแม่นยำ แทนที่จะเป็นกระบวนการที่ตั้งใจไว้ เพื่อศึกษาผลกระทบที่ความคลาดเคลื่อนใดๆ อาจมีต่อการวิเคราะห์ในภายหลัง
ปัญหาเฉพาะอย่างหนึ่งเกี่ยวข้องกับการไม่ตอบสนองการไม่ตอบสนองมีสองประเภทหลัก: [ 23 ] [ 24 ]
- การไม่ตอบแบบสอบถาม (การไม่กรอกข้อมูลในส่วนใดส่วนหนึ่งของแบบสอบถาม)
- การไม่ตอบแบบสอบถาม (ส่งแบบสอบถามหรือเข้าร่วมแบบสอบถาม แต่ไม่กรอกแบบสอบถามให้ครบถ้วนอย่างน้อยหนึ่งส่วน/หลายส่วน)
ในการสุ่มตัวอย่างแบบสำรวจบุคคลจำนวนมากที่ระบุว่าเป็นส่วนหนึ่งของกลุ่มตัวอย่างอาจไม่เต็มใจที่จะเข้าร่วม ไม่มีเวลาเข้าร่วม ( ต้นทุนค่าเสียโอกาส ) [ 25 ]หรือผู้ดูแลการสำรวจอาจไม่สามารถติดต่อพวกเขาได้ ในกรณีนี้ มีความเสี่ยงที่จะเกิดความแตกต่างระหว่างผู้ตอบแบบสอบถามและผู้ไม่ตอบแบบสอบถาม ซึ่งนำไปสู่การประมาณค่าพารามิเตอร์ของประชากรที่ลำเอียง ปัญหานี้มักได้รับการแก้ไขโดยการปรับปรุงการออกแบบแบบสำรวจ การเสนอสิ่งจูงใจ และการทำการศึกษาติดตามผลซึ่งพยายามติดต่อผู้ที่ไม่ตอบแบบสอบถามซ้ำๆ และเพื่อระบุลักษณะความคล้ายคลึงและความแตกต่างของพวกเขากับส่วนที่เหลือของกลุ่มตัวอย่าง[ 26 ]ผลกระทบยังสามารถบรรเทาได้โดยการถ่วงน้ำหนักข้อมูล (เมื่อมีเกณฑ์มาตรฐานของประชากร) หรือโดยการเติมข้อมูลตามคำตอบของคำถามอื่นๆ การไม่ตอบแบบสอบถามเป็นปัญหาอย่างยิ่งในการสุ่มตัวอย่างทางอินเทอร์เน็ต สาเหตุของปัญหานี้อาจรวมถึงแบบสำรวจที่ออกแบบไม่เหมาะสม[ 24 ]การสำรวจมากเกินไป (หรือความเหนื่อยล้าจากการสำรวจ) [ 17 ] [ 27 ] และข้อเท็จจริงที่ว่าผู้เข้าร่วมที่มีศักยภาพอาจมีที่อยู่อีเมลหลายรายการ ซึ่งพวกเขาไม่ได้ใช้แล้วหรือไม่ได้ตรวจสอบเป็นประจำ
น้ำหนักการสำรวจ
ในหลายสถานการณ์ สัดส่วนของกลุ่มตัวอย่างอาจแตกต่างกันไปตามชั้น และข้อมูลจะต้องได้รับการถ่วงน้ำหนักเพื่อให้เป็นตัวแทนของประชากรได้อย่างถูกต้อง ตัวอย่างเช่น การสุ่มตัวอย่างแบบง่ายของบุคคลในสหราชอาณาจักรอาจไม่รวมถึงบางคนที่อาศัยอยู่ในเกาะห่างไกลของสกอตแลนด์ ซึ่งการสุ่มตัวอย่างจะมีค่าใช้จ่ายสูงมาก วิธีที่ประหยัดกว่าคือการใช้การสุ่มตัวอย่างแบบแบ่งชั้น โดยแบ่งเป็นชั้นเมืองและชนบท กลุ่มตัวอย่างในชนบทอาจมีจำนวนน้อยกว่าที่ควรจะเป็น แต่จะได้รับการถ่วงน้ำหนักอย่างเหมาะสมในการวิเคราะห์เพื่อชดเชย
โดยทั่วไปแล้ว ควรถ่วงน้ำหนักข้อมูลหากการออกแบบการสุ่มตัวอย่างไม่ได้ให้โอกาสที่แต่ละบุคคลจะถูกเลือกอย่างเท่าเทียมกัน ตัวอย่างเช่น เมื่อครัวเรือนมีโอกาสถูกเลือกเท่ากัน แต่มีการสัมภาษณ์เพียงคนเดียวจากแต่ละครัวเรือน จะทำให้คนจากครัวเรือนขนาดใหญ่มีโอกาสถูกสัมภาษณ์น้อยลง ซึ่งสามารถแก้ไขได้โดยใช้การถ่วงน้ำหนักแบบสำรวจ ในทำนองเดียวกัน ครัวเรือนที่มีหมายเลขโทรศัพท์มากกว่าหนึ่งหมายเลขจะมีโอกาสถูกเลือกมากขึ้นในการสุ่มตัวอย่างแบบสุ่มหมายเลขโทรศัพท์ และการถ่วงน้ำหนักสามารถปรับแก้ปัญหานี้ได้
นอกจากนี้ น้ำหนักยังสามารถใช้เพื่อวัตถุประสงค์อื่น ๆ ได้ เช่น ช่วยแก้ไขปัญหาการไม่ตอบสนอง
วิธีการสร้างตัวอย่างแบบสุ่ม
- ตารางเลขสุ่ม
- อัลกอริทึมทางคณิตศาสตร์สำหรับการสร้างเลขสุ่มเทียม
- อุปกรณ์สุ่มแบบกายภาพ เช่น เหรียญ ไพ่ หรืออุปกรณ์ที่ซับซ้อน เช่นERNIE
ดูเพิ่มเติม
- การเก็บรวบรวมข้อมูล
- เอฟเฟกต์การออกแบบ
- ทฤษฎีการประมาณค่า
- ทฤษฎีการสุ่มตัวอย่างของ Gy
- ปัญหาของรถถังเยอรมัน
- ตัวประมาณค่าฮอร์วิตซ์-ทอมป์สัน
- การสุ่มตัวอย่างไฮเปอร์คิวบ์ละติน
- สถิติอย่างเป็นทางการ
- ตัวประมาณอัตราส่วน
- การจำลองแบบ (สถิติ)
- กลไกการสุ่มตัวอย่าง
- การสุ่มตัวอย่างซ้ำ (สถิติ)
- การสุ่มตัวเลขแบบเทียม
- การกำหนดขนาดตัวอย่าง
- การสุ่มตัวอย่าง (กรณีศึกษา)
- อคติในการสุ่มตัวอย่าง
- การกระจายตัวอย่าง
- ข้อผิดพลาดในการสุ่มตัวอย่าง
- การคัดแยก
- การสุ่มตัวอย่างแบบสำรวจ
หมายเหตุ
ตำราของ Groves และคณะ ให้ภาพรวมของระเบียบวิธีวิจัยแบบสำรวจ รวมถึงวรรณกรรมล่าสุดเกี่ยวกับการพัฒนาแบบสอบถาม (โดยอาศัยพื้นฐานจากจิตวิทยาการรู้คิด ) :
- โรเบิร์ต โกรฟส์และคนอื่นๆวิธีการสำรวจ (2010 ฉบับพิมพ์ครั้งที่ 2 [2004]) ISBN 0-471-48348-6.
หนังสือเล่มอื่นๆ เน้นทฤษฎีทางสถิติของการสุ่มตัวอย่างสำรวจ และต้องอาศัยความรู้พื้นฐานทางสถิติบ้าง ดังที่ได้กล่าวไว้ในตำราเรียนต่อไปนี้:
- เดวิด เอส. มัวร์และจอร์จ พี. แมคเคบ (กุมภาพันธ์ 2548) " ความรู้เบื้องต้นเกี่ยวกับการปฏิบัติทางสถิติ " (ฉบับที่ 5) สำนักพิมพ์ WH Freeman & Company ISBN 0-7167-6282-X.
- ฟรีดแมน, เดวิด ; พิซานี, โรเบิร์ต; เพอร์เวส, โรเจอร์ (2007) สถิติ (ฉบับที่ 4). นิวยอร์ก: นอร์ตัน . ไอเอสบีเอ็น 978-0-393-92972-0.
หนังสือเรียนเบื้องต้นของ Scheaffer และคณะ ใช้สมการกำลังสองจากพีชคณิตระดับมัธยมปลาย:
- Scheaffer, Richard L., William Mendenhal และ R. Lyman Ott. การสุ่มตัวอย่างสำรวจเบื้องต้นฉบับที่ห้า. เบลมอนต์: สำนักพิมพ์ Duxbury, 1996.
จำเป็นต้องมีสถิติทางคณิตศาสตร์เพิ่มเติมสำหรับ Lohr, Särndal และคนอื่นๆ และสำหรับ Cochran: [ 28 ]
- Cochran, William G. (1977). เทคนิคการสุ่มตัวอย่าง (ฉบับที่สาม). Wiley. ISBN 978-0-471-16240-7.
- โลห์ร, ชารอน แอล. (1999). การสุ่มตัวอย่าง: การออกแบบและการวิเคราะห์ . ดักซ์เบอรี. ISBN 978-0-534-35361-2.
- ซาร์นดาล, คาร์ล-เอริค ; สเวนส์สัน, เบงต์; เร็ตแมน, ม.ค. (1992) การสุ่มตัวอย่างแบบสำรวจ โดยใช้แบบจำลองช่วยสปริงเกอร์-แวร์แลกไอเอสบีเอ็น 978-0-387-40620-6.
หนังสือสำคัญทางประวัติศาสตร์ของเดมิงและคิชยังคงมีคุณค่าสำหรับนักสังคมศาสตร์ในการให้ข้อมูลเชิงลึก (โดยเฉพาะอย่างยิ่งเกี่ยวกับสำมะโนประชากรของสหรัฐอเมริกาและสถาบันวิจัยสังคมแห่งมหาวิทยาลัยมิชิแกน ):
- เดมิง, ดับเบิลยู. เอ็ดเวิร์ดส์ (1966). ทฤษฎีการสุ่มตัวอย่างบางประการ . สำนักพิมพ์โดเวอร์ . ISBN 978-0-486-64684-8. OCLC 166526 .
- คิช, เลสลี (1995) การสุ่มตัวอย่างแบบสำรวจไวลีย์ISBN 0-471-10949-5
อ่านเพิ่มเติม
- Singh, GN, Jaiswal, AK และ Pandey AK (2021), วิธีการเติมข้อมูลที่ขาดหายไปที่ดีขึ้นสำหรับการสุ่มตัวอย่างต่อเนื่องสองครั้ง, การสื่อสารทางสถิติ: ทฤษฎีและวิธีการ DOI:10.1080/03610926.2021.1944211
- Chambers, RL และ Skinner, CJ (บรรณาธิการ) (2003), การวิเคราะห์ข้อมูลจากการสำรวจ , Wiley, ISBN 0-471-89987-9
- Deming, W. Edwards (1975) ว่าด้วยความน่าจะเป็นเป็นพื้นฐานสำหรับการกระทำThe American Statistician , 29(4), หน้า 146–152
- Gy, P (2012) การสุ่มตัวอย่างระบบวัสดุที่ไม่เป็นเนื้อเดียวกันและเปลี่ยนแปลงได้: ทฤษฎีความไม่เป็นเนื้อเดียวกัน การสุ่มตัวอย่าง และการทำให้เป็นเนื้อเดียวกัน , Elsevier Science, ISBN 978-0444556066
- Korn, EL และ Graubard, BI (1999) การวิเคราะห์แบบสำรวจสุขภาพ สำนักพิมพ์ Wiley, ISBN 0-471-13773-1
- Lucas, Samuel R. (2012). doi : 10.1007/s11135-012-9775-3 "Beyond the Existence Proof: Ontological Conditions, Epistemological Implications, and In-Depth Interview Research."], Quality & Quantity , doi : 10.1007/s11135-012-9775-3 .
- สจวร์ต, อลัน (1962) แนวคิดพื้นฐานของการสุ่มตัวอย่างทางวิทยาศาสตร์บริษัท ฮาฟเนอร์ พับลิชชิ่ง นิวยอร์ก
- Smith, TMF (1984). "สถานการณ์ปัจจุบันและการพัฒนาที่อาจเกิดขึ้น: มุมมองส่วนตัวบางประการ: การสำรวจตัวอย่าง" วารสารของราชสมาคมสถิติ, ชุด A . 147 (ครบรอบ 150 ปีของราชสมาคมสถิติ, ฉบับที่ 2): 208– 221. doi : 10.2307/2981677 . JSTOR 2981677 .
- Smith, TMF (1993). "ประชากรและการคัดเลือก: ข้อจำกัดของสถิติ (สุนทรพจน์ของประธาน)". วารสารของราชสมาคมสถิติ, ซีรีส์ A. 156 ( 2): 144– 166. doi : 10.2307/2982726 . JSTOR 2982726 .(ภาพเหมือนของทีเอ็มเอฟ สมิธ อยู่ในหน้า 144)
- Smith, TMF (2001). "ครบรอบร้อยปี: การสำรวจตัวอย่าง". Biometrika . 88 (1): 167– 243. doi : 10.1093/biomet/88.1.167 .
- Smith, TMF (2001). "Biometrika ครบรอบ 100 ปี: การสำรวจตัวอย่าง". ในDM TitteringtonและDR Cox (บรรณาธิการ).Biometrika : หนึ่งร้อยปี สำนักพิมพ์มหาวิทยาลัยออกซ์ฟ อร์ด หน้า 165–194 ISBN 978-0-19-850993-6.
- Whittle, P. (พฤษภาคม 1954). "การสุ่มตัวอย่างเชิงป้องกันที่เหมาะสมที่สุด". วารสารสมาคมวิจัยปฏิบัติการแห่งอเมริกา 2 ( 2): 197– 203. doi : 10.1287/opre.2.2.197 . JSTOR 166605 .
มาตรฐาน
ไอโอเอส
- ชุด ISO 2859
- ชุด ISO 3951
เอสเอเอสที
- มาตรฐาน ASTM E105 แนวปฏิบัติมาตรฐานสำหรับการสุ่มตัวอย่างวัสดุแบบความน่าจะเป็น
- มาตรฐาน ASTM E122 วิธีปฏิบัติในการคำนวณขนาดตัวอย่างเพื่อประมาณค่าเฉลี่ยของลักษณะเฉพาะของล็อตหรือกระบวนการ โดยมีค่าความคลาดเคลื่อนที่ยอมรับได้ระบุไว้
- มาตรฐาน ASTM E141 แนวปฏิบัติมาตรฐานสำหรับการยอมรับหลักฐานโดยอิงจากผลการสุ่มตัวอย่างแบบความน่าจะเป็น
- มาตรฐาน ASTM E1402 คำศัพท์ที่เกี่ยวข้องกับการสุ่มตัวอย่าง
- มาตรฐาน ASTM E1994 แนวปฏิบัติในการใช้แผนการสุ่มตัวอย่าง AOQL และ LTPD ที่มุ่งเน้นกระบวนการ
- มาตรฐาน ASTM E2234 แนวปฏิบัติมาตรฐานสำหรับการสุ่มตัวอย่างกระแสผลิตภัณฑ์ตามคุณลักษณะที่จัดทำดัชนีโดย AQL
ANSI, ASQ
- ANSI/ASQ Z1.4
มาตรฐานของรัฐบาลกลางและกองทัพสหรัฐฯ
- มิล-สเตด-105
- มาตรฐานทางทหาร 1916
ลิงก์ภายนอก
 สื่อที่เกี่ยวข้องกับการสุ่มตัวอย่าง (สถิติ)ในวิกิมีเดียคอมมอนส์
สื่อที่เกี่ยวข้องกับการสุ่มตัวอย่าง (สถิติ)ในวิกิมีเดียคอมมอนส์
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การสุ่มตัวอย่าง (สถิติ)
ใน ทางสถิติ การประกันคุณภาพ และ ระเบียบวิธีสำรวจ การ สุ่มตัวอย่าง คือการเลือกกลุ่มย่อยของ บุคคล จาก ประชากรทางสถิติ เพื่อประมาณลักษณะของประชากรทั้งหมด กลุ่มย่อยนี้เรียกว่า...
ประวัติศาสตร์
การสุ่มตัวอย่างโดยใช้การจับฉลากเป็นแนวคิดเก่าแก่ที่กล่าวถึงหลายครั้งในพระคัมภีร์ไบเบิล ในปี ค.ศ.
นิยามประชากร
การปฏิบัติทางสถิติที่ประสบความสำเร็จนั้นขึ้นอยู่กับการกำหนดปัญหาอย่างมีเป้าหมาย ในการสุ่มตัวอย่างนั้น รวมถึงการกำหนด " ประชากร " ที่เราจะสุ่มตัวอย่างมา ประชากรสามารถนิยามได้ว่ารวมถึงบุคคลหรือสิ่งของทั้งหมดที่มีลักษณะที่เราต้องการทำความเข้าใจ...
กรอบการสุ่มตัวอย่าง
ในกรณีที่ตรงไปตรงมาที่สุด เช่น การสุ่มตัวอย่างวัสดุจากสายการผลิต (การสุ่มตัวอย่างเพื่อยอมรับคุณภาพเป็นล็อต) จะเป็นที่พึงปรารถนาอย่างยิ่งที่จะระบุและวัดค่าทุกชิ้นในประชากร และรวมทุกชิ้นไว้ในตัวอย่างของเรา อย่างไรก็ตาม ในกรณีทั่วไปแล้ว...