อ่าน 12 นาที
โครงสร้างข้อมูลเซตที่ไม่เกี่ยวข้องกัน
ในวิทยาการคอมพิวเตอร์โครงสร้างข้อมูลเซตที่ไม่ซ้ำกัน (disjoint-set data structure ) หรือที่เรียกว่าโครงสร้างข้อมูลยูเนียน-ค้นหา (union–find data structure)หรือเซตผสาน-ค้นหา...
โครงสร้างข้อมูลเซตที่ไม่เกี่ยวข้องกัน
| การค้นหาเซตที่ไม่เกี่ยวข้องกัน/การค้นหาสหภาพในป่า | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| พิมพ์ | ต้นไม้หลายทาง | ||||||||||||||||||||
| ประดิษฐ์ | พ.ศ. 2507 | ||||||||||||||||||||
| คิดค้นโดย | เบอร์นาร์ด เอ. แกลเลอร์และไมเคิล เจ. ฟิชเชอร์ | ||||||||||||||||||||
| |||||||||||||||||||||
ในวิทยาการคอมพิวเตอร์โครงสร้างข้อมูลเซตที่ไม่ซ้ำกัน (disjoint-set data structure ) หรือที่เรียกว่าโครงสร้างข้อมูลยูเนียน-ค้นหา (union–find data structure)หรือเซตผสาน-ค้นหา (merge–find set ) คือโครงสร้างข้อมูลที่จัดเก็บชุดของเซตที่ไม่ซ้ำกัน (ไม่ทับซ้อนกัน) หรือกล่าวอีกนัยหนึ่งคือ จัดเก็บการแบ่งเซตออกเป็นเซตย่อย ที่ไม่ซ้ำกัน โครงสร้างนี้มีฟังก์ชันสำหรับการเพิ่มเซตใหม่ การผสานเซต (โดยแทนที่ด้วยผลรวมของเซต ) และการค้นหาสมาชิกที่เป็นตัวแทนของเซต ฟังก์ชันสุดท้ายนี้ทำให้สามารถตรวจสอบได้อย่างมีประสิทธิภาพว่าองค์ประกอบสองตัวใด ๆ อยู่ในเซตเดียวกันหรือต่างเซตกัน
แม้ว่าจะมีหลายวิธีในการใช้งานโครงสร้างข้อมูลเซตที่ไม่ซ้ำกัน แต่ในทางปฏิบัติมักจะระบุด้วยการใช้งานเฉพาะอย่างหนึ่งที่เรียกว่าป่าเซตที่ไม่ซ้ำกัน (disjoint-set forest ) ป่าชนิดพิเศษนี้ดำเนินการรวมและค้นหาในเวลาเฉลี่ย คงที่เกือบตลอดเวลา สำหรับลำดับของการบวก การรวม หรือการค้นหาm ครั้งในป่าเซตที่ไม่ซ้ำกันที่มี nโหนด เวลาทั้งหมดที่ต้องการคือO ( mα ( n ))โดยที่α( n ) คือ ฟังก์ชัน Ackermann ผกผันที่เติบโตช้ามากแม้ว่าป่าเซตที่ไม่ซ้ำกันจะไม่รับประกันเวลาต่อการดำเนินการนี้ แต่การดำเนินการแต่ละครั้งจะปรับสมดุลโครงสร้างใหม่ (ผ่านการบีบอัดต้นไม้) เพื่อให้การดำเนินการครั้งต่อไปเร็วขึ้น ส่งผลให้ป่าเซตที่ไม่ซ้ำกันมีทั้งความเหมาะสมที่สุดในเชิงอะซิมโทติกและมีประสิทธิภาพในทางปฏิบัติ
โครงสร้างข้อมูลเซตที่ไม่ซ้ำกันมีบทบาทสำคัญในอัลกอริทึมของ Kruskalสำหรับการค้นหาต้นไม้แผ่คลุมน้อยที่สุดของกราฟ ความสำคัญของต้นไม้แผ่คลุมน้อยที่สุดหมายความว่าโครงสร้างข้อมูลเซตที่ไม่ซ้ำกันรองรับอัลกอริทึมที่หลากหลาย นอกจากนี้ โครงสร้างข้อมูลเหล่านี้ยังพบการประยุกต์ใช้ในการคำนวณเชิงสัญลักษณ์และในคอมไพเลอร์ โดยเฉพาะอย่างยิ่งสำหรับปัญหา การจัดสรรรีจิสเตอร์
ประวัติศาสตร์
ป่าเซตที่ไม่เกี่ยวข้องกันได้รับการอธิบายครั้งแรกโดยBernard A. GallerและMichael J. Fischerในปี 1964 [ 2 ] ในปี 1973 HopcroftและUllmanได้จำกัดความซับซ้อนของเวลาไว้ที่ ซึ่งเป็นลอการิทึมแบบวนซ้ำของ[ 3 ]ในปี 1975 Robert Tarjanเป็นคนแรกที่พิสูจน์ ขอบเขตบน ( ฟังก์ชัน Ackermann ผกผัน ) ของความซับซ้อนของเวลาของอัลกอริทึม[ 4 ]เขายังพิสูจน์ได้ว่ามันเป็นขอบเขตที่แน่นหนา ในปี 1979 เขาแสดงให้เห็นว่านี่คือขอบเขตล่างสำหรับอัลกอริทึมบางประเภท อัลกอริทึมตัวชี้ซึ่งรวมถึงโครงสร้าง Galler-Fischer [ 5 ]ในปี 1989 FredmanและSaksแสดงให้เห็นว่าต้องเข้าถึงคำ (เฉลี่ย) บิตโดย โครงสร้างข้อมูลเซตที่ไม่เกี่ยวข้องกันใดๆ ต่อการดำเนินการ [ 6 ]ซึ่งพิสูจน์ถึงความเหมาะสมที่สุดของโครงสร้างข้อมูลในแบบจำลองนี้





ในปี พ.ศ. 2534 Galil และ Italiano ได้ตีพิมพ์ผลสำรวจโครงสร้างข้อมูลสำหรับเซตที่ไม่ซ้ำกัน[ 7 ]
ในปี พ.ศ. 2537 Richard J. Anderson และ Heather Woll ได้อธิบายเวอร์ชันขนานของ Union–Find ที่ไม่จำเป็นต้องบล็อกเลย[ 8 ]
ในปี 2550 Sylvain Conchon และ Jean-Christophe Filliâtre ได้พัฒนาโครงสร้างข้อมูลป่าเซตที่ไม่ทับซ้อนกันแบบกึ่งถาวรและกำหนดความถูกต้องอย่างเป็นทางการโดยใช้ตัวช่วยพิสูจน์Rocq (ในขณะนั้นคือCoq ) [ 9 ] "กึ่งถาวร" หมายความว่าเวอร์ชันก่อนหน้าของโครงสร้างจะถูกเก็บรักษาไว้อย่างมีประสิทธิภาพ แต่การเข้าถึงเวอร์ชันก่อนหน้าของโครงสร้างข้อมูลจะทำให้เวอร์ชันที่ใหม่กว่าไม่ถูกต้อง การใช้งานที่เร็วที่สุดของพวกเขาบรรลุประสิทธิภาพเกือบเท่ากับอัลกอริทึมที่ไม่ถาวร พวกเขาไม่ได้ทำการวิเคราะห์ความซับซ้อน
ได้มีการพิจารณารูปแบบต่างๆ ของโครงสร้างข้อมูลเซตที่ไม่ทับซ้อนกันซึ่งมีประสิทธิภาพที่ดีกว่าในปัญหาบางประเภท Gabow และ Tarjan แสดงให้เห็นว่าหากการรวมกันที่เป็นไปได้ถูกจำกัดในบางวิธี อัลกอริทึมที่มีเวลาเชิงเส้นอย่างแท้จริงก็เป็นไปได้[ 10 ]โดยเฉพาะอย่างยิ่ง เวลาเชิงเส้นสามารถทำได้หากมีการกำหนด "ต้นไม้รวม" ไว้ล่วงหน้า นี่คือต้นไม้ที่รวมองค์ประกอบทั้งหมดของเซต ให้ p[ v ] แทนผู้ปกครองในต้นไม้ จากนั้นสมมติฐานคือการดำเนินการรวมจะต้องมีรูปแบบunion ( v ,p[ v ]) สำหรับv บาง ตัว
การเป็นตัวแทน
ในส่วนนี้และส่วนต่อไป เราจะอธิบายการใช้งานโครงสร้างข้อมูลเซตที่ไม่ซ้ำกันที่พบได้บ่อยที่สุด นั่นคือ ในรูปแบบของป่า ต้นไม้ตัวชี้ไปยังโหนดแม่การแสดงผลแบบนี้เรียกว่าต้นไม้แกลเลอร์-ฟิชเชอร์
แต่ละโหนดในป่าเซตที่ไม่ซ้ำกันประกอบด้วยตัวชี้และข้อมูลเสริมบางอย่าง เช่น ขนาดหรือลำดับ (แต่ไม่ใช่ทั้งสองอย่าง) ตัวชี้เหล่านี้ใช้ในการสร้างต้นไม้ตัวชี้ไปยังโหนดแม่โดยแต่ละโหนดที่ไม่ใช่โหนดรากของต้นไม้จะชี้ไปยังโหนดแม่ของมัน เพื่อแยกแยะโหนดรากออกจากโหนดอื่น ๆ ตัวชี้ไปยังโหนดแม่ของโหนดรากจะมีค่าที่ไม่ถูกต้อง เช่นการอ้างอิงแบบวนซ้ำไปยังโหนดนั้น หรือค่าเซนติเนลแต่ละต้นไม้แสดงถึงเซตที่เก็บไว้ในป่า โดยสมาชิกของเซตคือโหนดในต้นไม้ โหนดรากทำหน้าที่เป็นตัวแทนของเซต: โหนดสองโหนดอยู่ในเซตเดียวกันก็ต่อเมื่อรากของต้นไม้ที่บรรจุโหนดเหล่านั้นเท่ากัน
โหนดในป่าสามารถจัดเก็บได้ด้วยวิธีใดก็ได้ที่สะดวกต่อการใช้งาน แต่เทคนิคที่นิยมใช้คือการจัดเก็บไว้ในอาร์เรย์ ในกรณีนี้ โหนดแม่สามารถระบุได้ด้วยดัชนีของอาร์เรย์ แต่ละรายการในอาร์เรย์ต้องการ พื้นที่จัดเก็บ Θ(log n )บิตสำหรับตัวชี้ไปยังโหนดแม่ พื้นที่จัดเก็บที่จำเป็นสำหรับส่วนที่เหลือของรายการนั้นมีจำนวนเท่ากันหรือน้อยกว่า ดังนั้นจำนวนบิตที่จำเป็นในการจัดเก็บป่าจึงเป็นΘ( n log n ) หากการใช้งานใช้โหนดขนาดคงที่ (ซึ่งจะจำกัดขนาดสูงสุดของป่าที่สามารถจัดเก็บได้) พื้นที่จัด เก็บ ที่จำเป็นจะเป็นเชิงเส้นตามn
การดำเนินงาน
โครงสร้างข้อมูลเซตที่ไม่ซ้ำกันรองรับการดำเนินการสามอย่าง ได้แก่ การสร้างเซตใหม่ที่มีองค์ประกอบใหม่ การค้นหาตัวแทนของเซตที่มีองค์ประกอบที่กำหนด และการรวมสองเซตเข้าด้วยกัน
การสร้างชุดใหม่
การดำเนินการ นี้MakeSetจะเพิ่มองค์ประกอบใหม่เข้าไปในเซตใหม่ซึ่งประกอบด้วยองค์ประกอบใหม่เพียงตัวเดียว และเซตใหม่นี้จะถูกเพิ่มเข้าไปในโครงสร้างข้อมูล หากมองโครงสร้างข้อมูลในฐานะการแบ่งส่วนของเซตMakeSetการดำเนินการนี้จะขยายเซตโดยการเพิ่มองค์ประกอบใหม่ และขยายการแบ่งส่วนที่มีอยู่โดยการใส่องค์ประกอบใหม่เข้าไปในเซตย่อยใหม่ซึ่งประกอบด้วยองค์ประกอบใหม่เพียงตัวเดียว
ในฟอเรสต์เซตที่ไม่ทับซ้อนกันMakeSetจะทำการเริ่มต้นตัวชี้ไปยังโหนดแม่และขนาดหรือลำดับของโหนดนั้น หากโหนดรากถูกแทนด้วยโหนดที่ชี้ไปยังตัวมันเอง การเพิ่มองค์ประกอบสามารถอธิบายได้โดยใช้รหัสเทียม ต่อไปนี้ :
ฟังก์ชัน MakeSet( x ) ทำงานโดยที่xยังไม่ได้อยู่ในป่าจากนั้นx.parent := x, x.size : = 1 // ถ้าโหนดเก็บขนาดx.rank := 0 // ถ้าโหนดเก็บอันดับ
การดำเนินการนี้มีเวลาในการประมวลผลเชิงเส้น โดยเฉพาะอย่างยิ่ง การเริ่มต้นฟอเรสต์เซตที่ไม่ซ้ำกันที่มี โหนด nโหนด ต้องใช้ เวลา O ( n )
การที่ไม่มีโหนดแม่ถูกกำหนดให้กับโหนดนั้น แสดงว่าโหนดนั้นไม่มีอยู่ในป่าโหนดนั้น
ในทางปฏิบัติMakeSetจะต้องมีการดำเนินการจัดสรรหน่วยความจำเพื่อเก็บค่าx นำหน้า ตราบใดที่การจัดสรรหน่วยความจำเป็นการดำเนินการที่ใช้เวลาคงที่โดยเฉลี่ย เช่นเดียวกับ การใช้งาน อาร์เรย์แบบไดนามิก ที่ดี การดำเนินการดังกล่าวจะไม่เปลี่ยนแปลงประสิทธิภาพเชิงอะซิมโทติกของป่าชุดสุ่ม
การค้นหาตัวแทนกลุ่ม
การดำเนินการ นี้Findจะติดตามสายโซ่ของตัวชี้ไปยังโหนดแม่จากโหนดคำถามที่ระบุxจนกว่าจะถึงองค์ประกอบราก องค์ประกอบรากนี้แสดงถึงเซตที่xเป็นสมาชิกอยู่ และอาจเป็นxเองก็ได้ Findฟังก์ชันนี้จะส่งคืนองค์ประกอบรากที่พบ
การดำเนินFindการแต่ละครั้งเป็นโอกาสสำคัญในการปรับปรุงโครงสร้างต้นไม้ เวลาที่ใช้ในFindการดำเนินการส่วนใหญ่จะหมดไปกับการติดตามตัวชี้ไปยังโหนดแม่ ดังนั้นโครงสร้างต้นไม้ที่แบนราบกว่าจะทำให้Findการดำเนินการเร็วขึ้น เมื่อFindมีการเรียกใช้คำสั่ง a จะไม่มีวิธีใดที่เร็วกว่าการไปถึงโหนดรากโดยการติดตามตัวชี้ไปยังโหนดแม่แต่ละตัวตามลำดับ อย่างไรก็ตาม ตัวชี้ไปยังโหนดแม่ที่เยี่ยมชมระหว่างการค้นหานี้สามารถอัปเดตให้ชี้ไปยังโหนดรากได้ใกล้ขึ้น เนื่องจากทุกองค์ประกอบที่เยี่ยมชมระหว่างทางไปยังโหนดรากเป็นส่วนหนึ่งของเซตเดียวกัน การอัปเดตนี้จึงไม่เปลี่ยนแปลงเซตที่จัดเก็บไว้ในโครงสร้างต้นไม้ แต่จะทำให้Findการดำเนินการในอนาคตเร็วขึ้น ไม่เพียงแต่สำหรับโหนดระหว่างโหนดสอบถามและโหนดรากเท่านั้น แต่ยังรวมถึงโหนดลูกหลานด้วย การอัปเดตนี้เป็นส่วนสำคัญของการรับประกันประสิทธิภาพโดยเฉลี่ยของโครงสร้างต้นไม้แบบเซตที่ไม่ซ้ำกัน
มีอัลกอริธึมหลายตัวที่Findให้ความซับซ้อนของเวลาที่เหมาะสมที่สุดในเชิงอะซิมโทติก อัลกอริธึมกลุ่มหนึ่งที่เรียกว่าการบีบอัดเส้นทาง (path compression ) ทำให้ทุกโหนดระหว่างโหนดสอบถามและโหนดรากชี้ไปยังโหนดราก การบีบอัดเส้นทางสามารถนำไปใช้ได้โดยใช้การเรียกซ้ำอย่างง่ายดังนี้:
ฟังก์ชัน Find( x ) คือถ้าx .parent ≠ x แล้วx .parent := Find( x .parent) ส่งคืนx .parent มิฉะนั้นส่งคืนx จบเงื่อนไขจบฟังก์ชัน
การใช้งานนี้จะวนซ้ำสองรอบ รอบหนึ่งขึ้นไปตามโครงสร้างต้นไม้ และอีกรอบหนึ่งลงมา จำเป็นต้องใช้หน่วยความจำชั่วคราวมากพอที่จะเก็บเส้นทางจากโหนดสอบถามไปยังโหนดราก (ในรหัสเทียมข้างต้น เส้นทางจะถูกแทนด้วยสแต็กการเรียก ) สามารถลดปริมาณหน่วยความจำนี้ให้เหลือค่าคงที่ได้โดยการวนซ้ำทั้งสองรอบในทิศทางเดียวกัน การใช้งานแบบใช้หน่วยความจำคงที่นี้จะเดินจากโหนดสอบถามไปยังโหนดรากสองครั้ง ครั้งแรกเพื่อค้นหาโหนดราก และครั้งที่สองเพื่ออัปเดตตัวชี้:
ฟังก์ชัน Find( x ) คือroot := x ในขณะที่root .parent ไม่เท่ากับroot ให้กำหนดroot := root .parent สิ้นสุดลูปในขณะที่x.parentไม่เท่ากับroot ให้กำหนดparent เป็นx.parent และกำหนด root เป็นx.parent สิ้นสุดลู ปฟังก์ชันreturn root end
TarjanและVan Leeuwenยังได้พัฒนาอัลกอริธึมแบบผ่านครั้งเดียวFindซึ่งยังคงความซับซ้อนในกรณีที่เลวร้ายที่สุดไว้ เช่นเดิม แต่มีประสิทธิภาพมากกว่าในทางปฏิบัติ[ 4 ] สิ่งเหล่านี้เรียกว่าการแบ่งเส้นทางและการแบ่งเส้นทางครึ่งหนึ่ง ทั้งสองวิธีนี้จะอัปเดตตัวชี้ผู้ปกครองของโหนดบนเส้นทางระหว่างโหนดคำถามและโหนดราก การแบ่งเส้นทางจะแทนที่ตัวชี้ผู้ปกครองทุกตัวบนเส้นทางนั้นด้วยตัวชี้ไปยังปู่ย่าตายายของโหนดนั้น:
ฟังก์ชัน Find( x ) คือwhile x .parent ≠ x do ( x , x .parent) := ( x .parent, x .parent.parent) end while return x end function
การแบ่งเส้นทางออกเป็นครึ่งๆทำงานคล้ายกัน แต่จะแทนที่ตัวชี้ไปยังโหนดแม่ทุกๆ สองตัวเท่านั้น:
ฟังก์ชัน Find( x ) คือwhile x .parent ≠ x do x .parent := x .parent.parent x := x .parent end while return x end function
การรวมสองชุดเข้าด้วยกัน
MakeSetสร้างข้อมูลซิงเกิลตัน 8 รายการUnionบางชุดจะถูกจัดกลุ่มเข้าด้วยกันการดำเนินการนี้จะแทนที่เซตที่ประกอบด้วยxและเซตที่ประกอบด้วยyด้วยผลรวมของทั้ง สองเซต ขั้นแรกจะใช้เพื่อกำหนดรากของต้นไม้ที่ประกอบด้วยxและyหากรากเหมือนกัน ก็ไม่ต้องทำอะไรเพิ่มเติม แต่ถ้าไม่เหมือนกัน ต้นไม้ทั้งสองจะต้องถูกรวมเข้าด้วยกัน ซึ่งทำได้โดยการตั้งค่าตัวชี้ไปยังโหนดแม่ของ รากของ xให้เป็น ของ yหรือตั้งค่าตัวชี้ไปยังโหนดแม่ของรากของy ให้เป็น ของ xUnion(x, y)UnionFind
การเลือกโหนดใดให้เป็นโหนดแม่มีผลต่อความซับซ้อนของการดำเนินการในอนาคตบนต้นไม้ หากทำอย่างไม่ระมัดระวัง ต้นไม้ก็อาจสูงเกินไป ตัวอย่างเช่น สมมติว่าเรากำหนดUnionให้ต้นไม้ที่มีxเป็นต้นไม้ย่อยของต้นไม้ที่มีy เสมอ เริ่มต้นด้วยป่าที่เพิ่งได้รับการเริ่มต้นด้วยองค์ประกอบต่างๆและดำเนินการ, , ..., ป่าที่ได้จะมีต้นไม้เดียวที่มีรากเป็นnและเส้นทางจาก 1 ไปยังnผ่านทุกโหนดในต้นไม้ สำหรับป่านี้ เวลาที่ใช้ในการทำงาน คือO ( n )Union(1, 2)Union(2, 3)Union(n - 1, n)Find(1)

ในการใช้งานที่มีประสิทธิภาพ ความสูงของต้นไม้จะถูกควบคุมโดยใช้การรวมตามขนาดหรือการรวมตามลำดับชั้นทั้งสองวิธีนี้ต้องการให้โหนดเก็บข้อมูลนอกเหนือจากตัวชี้ไปยังโหนดแม่ ข้อมูลนี้จะถูกใช้เพื่อตัดสินใจว่าโหนดรากใดจะกลายเป็นโหนดแม่ใหม่ ทั้งสองกลยุทธ์นี้ช่วยให้มั่นใจได้ว่าต้นไม้จะไม่ลึกเกินไป
สหภาพตามขนาด
ในกรณีของการรวมตามขนาด โหนดจะเก็บขนาดของตัวเอง ซึ่งก็คือจำนวนลูกหลาน (รวมถึงตัวโหนดเองด้วย) เมื่อต้นไม้ที่มีรากxและyถูกรวมเข้าด้วยกัน โหนดที่มีลูกหลานมากกว่าจะกลายเป็นโหนดแม่ หากโหนดทั้งสองมีจำนวนลูกหลานเท่ากัน โหนดใดโหนดหนึ่งก็สามารถเป็นโหนดแม่ได้ ในทั้งสองกรณี ขนาดของโหนดแม่ใหม่จะถูกกำหนดให้เท่ากับจำนวนลูกหลานทั้งหมดของโหนดนั้น
ฟังก์ชัน Union( x , y ) คือ// แทนที่โหนดด้วยรากx := Find( x ) y := Find( y ) ถ้าx = y แล้วให้ส่งคืนค่าเดิม// x และ y อยู่ในเซตเดียวกันอยู่แล้วจบเงื่อนไข // หากจำเป็น ให้สลับตัวแปรเพื่อให้แน่ใจว่า// x มีลูกหลานอย่างน้อยเท่ากับ y ถ้าx.size < y.size แล้ว ( x , y ) := ( y , x ) end if // กำหนดให้ x เป็นรากใหม่y.parent := x // อัปเดตขนาดของ x x.size := x.size + y.size end function
จำนวนบิตที่จำเป็นในการจัดเก็บขนาดนั้นเห็นได้ชัดว่าเท่ากับจำนวนบิตที่จำเป็นในการจัดเก็บnซึ่งจะเพิ่มค่าคงที่เข้าไปในพื้นที่จัดเก็บข้อมูลที่จำเป็นสำหรับป่าแห่งนี้
สหภาพตามลำดับชั้น
สำหรับการรวมตามลำดับ (Union by Rank) โหนดจะเก็บลำดับ ของตัว เอง ซึ่งเป็นขอบเขตบนของความสูง เมื่อโหนดได้รับการเริ่มต้น ลำดับของมันจะถูกตั้งค่าเป็นศูนย์ ในการรวมต้นไม้ที่มีรากxและyก่อนอื่นให้เปรียบเทียบลำดับของพวกมัน หากลำดับแตกต่างกัน ต้นไม้ที่มีลำดับสูงกว่าจะกลายเป็นต้นไม้แม่ และลำดับของxและyจะไม่เปลี่ยนแปลง หากลำดับเหมือนกัน ต้นไม้ใดก็ได้สามารถเป็นต้นไม้แม่ได้ แต่ลำดับของต้นไม้แม่ใหม่จะเพิ่มขึ้นหนึ่ง ในขณะที่ลำดับของโหนดมีความสัมพันธ์อย่างชัดเจนกับความสูงของมัน การเก็บลำดับนั้นมีประสิทธิภาพมากกว่าการเก็บความสูง ความสูงของโหนดสามารถเปลี่ยนแปลงได้ในระหว่างFindการดำเนินการ ดังนั้นการเก็บลำดับจึงช่วยหลีกเลี่ยงความพยายามเพิ่มเติมในการรักษาความสูงให้ถูกต้อง ในรหัสเทียม การรวมตามลำดับคือ:
ฟังก์ชัน Union( x , y ) คือ// แทนที่โหนดด้วยรากx := Find( x ) y := Find( y ) ถ้าx = y แล้วให้ส่งคืนค่าเดิม// x และ y อยู่ในเซตเดียวกันอยู่แล้วจบเงื่อนไข // หากจำเป็น ให้เปลี่ยนชื่อตัวแปรเพื่อให้แน่ใจว่า// x มีลำดับอย่างน้อยเท่ากับ y ถ้าx.rank < y.rank แล้ว ( x , y ) := ( y , x ) end if // กำหนดให้ x เป็นรากใหม่y.parent := x // ถ้าจำเป็น ให้เพิ่มอันดับของ x ถ้าx.rank = y.rank แล้วx.rank := x.rank + 1 end if end function
สามารถแสดงได้ว่าทุกโหนดมีอันดับหรือน้อยกว่า[ 11 ] ดังนั้นแต่ละอันดับสามารถจัดเก็บได้ในO (log log n )บิต และอันดับทั้งหมดสามารถจัดเก็บได้ในO ( n log log n )บิต ซึ่งทำให้อันดับเป็นส่วนที่ไม่สำคัญในเชิงอะซิมโทติกของขนาดป่า

จากตัวอย่างการใช้งานข้างต้น จะเห็นได้ชัดว่าขนาดและลำดับของโหนดไม่มีความสำคัญ เว้นแต่ว่าโหนดนั้นจะเป็นโหนดรากของต้นไม้ เมื่อโหนดกลายเป็นโหนดลูกแล้ว ขนาดและลำดับของโหนดนั้นจะไม่ถูกเรียกใช้อีกต่อไป
มีUnionการดำเนินการอีกรูปแบบหนึ่งที่ผู้ใช้สามารถกำหนดตัวแทนของเซตที่สร้างขึ้นได้ การเพิ่มฟังก์ชันนี้ลงในอัลกอริธึมข้างต้นโดยไม่สูญเสียประสิทธิภาพนั้นไม่ใช่เรื่องยาก
ความซับซ้อนเชิงเวลา
การใช้งานโครงสร้างต้นไม้แบบเซตที่ไม่ทับซ้อนกัน ซึ่งFindไม่ทำการอัปเดตตัวชี้ไปยังโหนดแม่ และUnionไม่พยายามควบคุมความสูงของต้นไม้ สามารถสร้างต้นไม้ที่มีความสูงO ( n )ได้ ในสถานการณ์เช่นนี้ การดำเนินการ Findต่างๆUnionจะใช้เวลา O ( n )
หากการใช้งานใช้การบีบอัดเส้นทางเพียงอย่างเดียว ลำดับของ การดำเนินการ nMakeSetครั้ง ตามด้วยการดำเนินการสูงสุดn − 1Unionครั้ง และ การดำเนินการ fFindครั้ง จะมีเวลาการทำงานในกรณีที่เลวร้ายที่สุดคือ[ 11 ]

การใช้ยูเนียนตามลำดับ แต่ไม่ได้อัปเดตตัวชี้แม่ในระหว่างนั้นFindจะให้เวลาทำงานสำหรับ การดำเนินการ m ครั้งของประเภทใดก็ได้ โดยที่การดำเนินการไม่เกินn ครั้ง[ 11 ]MakeSet

การรวมกันของการบีบอัดเส้นทาง การแบ่ง หรือการหารครึ่ง กับการรวมกันตามขนาดหรือตามลำดับ จะลดเวลาการทำงานสำหรับ การดำเนินการ mครั้งใดๆ ก็ได้โดยที่การดำเนินการ สูงสุด n ครั้งเหลือ เพียง [ 4 ] [ 5 ] ซึ่งทำให้เวลาการทำงานเฉลี่ยของการดำเนินการแต่ละครั้ง เป็น ซึ่งถือว่าเหมาะสมที่สุดในเชิง อะซิมโทติก หมายความว่าโครงสร้างข้อมูลเซตที่ไม่ทับซ้อนกันทุกโครงสร้างจะต้องใช้เวลาเฉลี่ยต่อการดำเนินการ[ 6 ] ในที่นี้ ฟังก์ชันคือ ฟังก์ชัน Ackermann ผกผัน ฟังก์ชัน Ackermann ผกผันเติบโตช้ามาก ดังนั้นปัจจัยนี้จึงเป็น4หรือน้อยกว่าสำหรับn ใดๆ ที่สามารถเขียนได้จริงในจักรวาลทางกายภาพ ซึ่งทำให้การดำเนินการเซตที่ไม่ทับซ้อนกันมีเวลาเฉลี่ยคงที่ในทางปฏิบัติ MakeSet



พิสูจน์ความซับซ้อนของเวลา O(m log* n) ของ Union-Find
การวิเคราะห์ประสิทธิภาพของป่าเซตที่ไม่เกี่ยวข้องกันอย่างแม่นยำนั้นค่อนข้างซับซ้อน อย่างไรก็ตาม มีการวิเคราะห์ที่ง่ายกว่ามากซึ่งพิสูจน์ได้ว่าเวลาเฉลี่ยสำหรับ การดำเนินการ mFindหรือ n ใดๆ Unionบนป่าเซตที่ไม่เกี่ยวข้องกันที่มี วัตถุ nชิ้นคือO ( m log * n )โดยที่log *หมายถึงลอการิทึมแบบวนซ้ำ[ 12 ] [ 13 ] [ 14 ] [ 15 ]
บทพิสูจน์ย่อยที่ 1: เมื่อฟังก์ชัน findไล่ตามเส้นทางไปจนถึงโหนดราก ระดับของโหนดที่พบจะเพิ่มขึ้น
เราอ้างว่าเมื่อมีการใช้การดำเนินการ Find และ Union กับชุดข้อมูล ข้อเท็จจริงนี้ยังคงเป็นจริงตลอดเวลา ในตอนเริ่มต้น เมื่อแต่ละโหนดเป็นรากของต้นไม้ของตัวเอง ข้อเท็จจริงนี้เป็นจริงอย่างเห็นได้ชัด กรณีเดียวที่ลำดับของโหนดอาจเปลี่ยนแปลงได้คือเมื่อ ใช้การดำเนินการ Union by Rankในกรณีนี้ ต้นไม้ที่มีลำดับต่ำกว่าจะถูกเชื่อมต่อกับต้นไม้ที่มีลำดับสูงกว่า แทนที่จะเป็นในทางกลับกัน และในระหว่างการดำเนินการ Find โหนดทั้งหมดที่เยี่ยมชมตามเส้นทางจะถูกเชื่อมต่อกับราก ซึ่งมีลำดับสูงกว่าลูกๆ ดังนั้นการดำเนินการนี้จะไม่เปลี่ยนแปลงข้อเท็จจริงนี้เช่นกัน
บทพิสูจน์ย่อยที่ 2: โหนดuซึ่งเป็นรากของต้นไม้ย่อยที่มีอันดับrจะมีโหนดอย่างน้อย... โหนด

ในขั้นต้น เมื่อแต่ละโหนดเป็นรากของต้นไม้ของตัวเอง ข้อความนี้เป็นจริงอย่างเห็นได้ชัด สมมติว่าโหนดuที่มีอันดับrมีโหนดอย่างน้อย2r โหนดจากนั้นเมื่อรวม ต้นไม้สองต้นที่มีอันดับ r โดยใช้การดำเนินการ รวมตามอันดับ จะได้ต้นไม้ที่มีอันดับr + 1ซึ่งรากของต้นไม้นี้มีโหนด อย่างน้อย


บทพิสูจน์ย่อยที่ 3: จำนวนโหนดที่มีอันดับr สูงสุด มีค่าไม่เกิน

จากบทพิสูจน์ย่อยที่ 2เราทราบว่าโหนดuซึ่งเป็นรากของต้นไม้ย่อยที่มีอันดับrจะมีโหนดอย่างน้อยเราจะได้จำนวนโหนดที่มีอันดับr สูงสุด เมื่อแต่ละโหนดที่มีอันดับrเป็นรากของต้นไม้ที่มีโหนดอยู่จำนวนหนึ่ง ในกรณีนี้ จำนวนโหนดที่มีอันดับrคือ
ในแต่ละช่วงเวลาของการดำเนินการ เราสามารถจัดกลุ่มจุดยอดของกราฟเป็น "กลุ่ม" ตามลำดับความสำคัญของจุดยอดเหล่านั้นได้ เรากำหนดช่วงของกลุ่มต่างๆ แบบอุปนัยดังนี้: กลุ่มที่ 0 ประกอบด้วยจุดยอดที่มีลำดับที่ 0 กลุ่มที่ 1 ประกอบด้วยจุดยอดที่มีลำดับที่ 1 กลุ่มที่ 2 ประกอบด้วยจุดยอดที่มีลำดับที่ 2 และ 3 โดยทั่วไปแล้ว หาก กลุ่มที่ Bประกอบด้วยจุดยอดที่มีลำดับอยู่ในช่วงแล้วกลุ่มที่ (B+1) จะประกอบด้วยจุดยอดที่มีลำดับอยู่ในช่วง
![{\displaystyle \left[r,2^{r}-1\right]=[r,R-1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49aa6ca95d184c363386c5c5aaa6c8932934e9b2)
![{\displaystyle \left[R,2^{R}-1\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe254e2d62c18dbe3ed168f4417653d5afd1ed23)
สำหรับให้แล้วบัคเก็ต จะมีจุดยอดที่มีลำดับ อยู่ ในช่วง



![{\displaystyle [{\text{tower}}(B-1),{\text{tower}}(B)-1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef0146c95ec30ab5e27b2ea4d6925435b79595de)
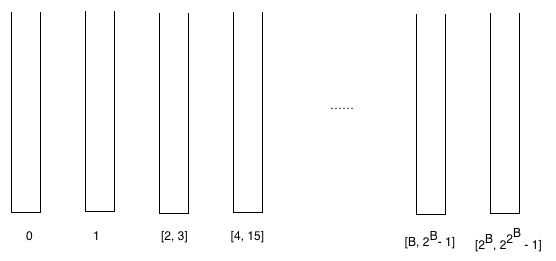

เราสามารถสังเกตขนาดของถังได้สองประการ
- จำนวนถังทั้งหมดมีค่าไม่เกิน log * n
- บทพิสูจน์: เนื่องจากไม่มีจุดยอดใดที่มีอันดับมากกว่าดังนั้นเฉพาะกลุ่มแรกเท่านั้นที่มีจุดยอด โดยที่หมายถึงค่าผกผันของฟังก์ชันที่กำหนดไว้ข้างต้น
- จำนวนองค์ประกอบสูงสุดในบัคเก็ตคือไม่เกิน.
- พิสูจน์: จำนวนองค์ประกอบสูงสุดในบัคเก็ตมีค่าไม่เกิน



![{\displaystyle \left[B,2^{B}-1\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70d4053472d64e0df71dcc2afcd0a3612a0d0ec8)


ให้Fแทนรายการของการดำเนินการ "ค้นหา" ที่ดำเนินการ และให้



ดังนั้นต้นทุนรวมของ การค้นพบ m ครั้งคือ

เนื่องจากการดำเนินการค้นหาแต่ละครั้งจะทำการท่องไปเพียงครั้งเดียวซึ่งนำไปสู่ราก ดังนั้นเราจึงมี T 1 = O ( m )
นอกจากนี้ จากขอบเขตข้างต้นเกี่ยวกับจำนวนถัง เราจะได้ T 2 = O ( m log * n )
สำหรับT 3สมมติว่าเรากำลังสำรวจขอบจากuไปยังvโดยที่uและvมีลำดับในบัคเก็ต[ B , 2 B − 1]และvไม่ใช่ราก (ในขณะที่ทำการสำรวจนี้ มิฉะนั้นการสำรวจจะถูกนับรวมในT 1 ) กำหนดค่าu ให้คงที่ และพิจารณาลำดับที่ทำหน้าที่แทนvในการดำเนินการค้นหาที่แตกต่างกัน เนื่องจากมีการบีบอัดเส้นทางและไม่นับรวมขอบไปยังราก ลำดับนี้จึงมีเฉพาะโหนดที่แตกต่างกัน และเนื่องจากLemma 1เรารู้ว่าลำดับของโหนดในลำดับนี้เพิ่มขึ้นอย่างเคร่งครัด โดยที่โหนดทั้งสองอยู่ในบัคเก็ตเดียวกัน เราจึงสรุปได้ว่าความยาวkของลำดับ (จำนวนครั้งที่โหนดuเชื่อมต่อกับรากที่แตกต่างกันในบัคเก็ตเดียวกัน) มีค่าอย่างมากที่สุดเท่ากับจำนวนลำดับในบัคเก็ตBนั่นคือ อย่างมากที่สุด


ดังนั้น,
![{\displaystyle T_{3}\leq \sum _{[B,2^{B}-1]}\sum _{u}2^{B}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c6f85cd493fd0596a25595537c645fc839d9ebf0)
จากข้อสังเกตที่ 1และ2เราสามารถสรุปได้ว่า

ดังนั้น,

โครงสร้างอื่นๆ
ลดเวลาต่อการผ่าตัดในกรณีที่เลวร้ายที่สุดให้ดีขึ้น
เวลากรณีเลวร้ายที่สุดของFindการดำเนินการในต้นไม้ที่มีการรวมตามลำดับหรือการรวมตามน้ำหนักคือ(กล่าวคือและขอบเขตนี้แน่นมาก) ในปี 1985 N. Blum ได้นำเสนอการใช้งานการดำเนินการที่ไม่ใช้การบีบอัดเส้นทาง แต่บีบอัดต้นไม้ในระหว่างนั้นการใช้งานของเขาใช้เวลาต่อการดำเนินการ[ 16 ]ดังนั้นเมื่อเปรียบเทียบกับโครงสร้างของ Galler และ Fischer แล้ว จะมีเวลากรณีเลวร้ายที่สุดต่อการดำเนินการที่ดีกว่า แต่มีเวลาเฉลี่ยที่ด้อยกว่า ในปี 1999 Alstrup และคณะได้นำเสนอโครงสร้างที่มีเวลากรณีเลวร้ายที่สุดที่เหมาะสมที่สุดพร้อมกับเวลาเฉลี่ยแบบผกผันของ Ackermann [ 17 ]



การลบ
การใช้งานปกติในรูปแบบป่าเซตที่ไม่ทับซ้อนกันนั้นไม่ตอบสนองต่อการลบองค์ประกอบอย่างเหมาะสม ในแง่ที่ว่าเวลาFindจะไม่ดีขึ้นอันเป็นผลมาจากการลดลงของจำนวนองค์ประกอบ อย่างไรก็ตาม มีการใช้งานที่ทันสมัยซึ่งอนุญาตให้ลบในเวลาคงที่และขอบเขตเวลาFindขึ้นอยู่กับจำนวนองค์ประกอบปัจจุบัน[ 18 ] [ 19 ]
ย้อนกลับไป
เป็นไปได้ที่จะขยายโครงสร้างป่าเซตที่ไม่ทับซ้อนกันบางอย่างเพื่อให้สามารถย้อนกลับได้รูปแบบพื้นฐานของการย้อนกลับคือการอนุญาตให้ Backtrack(1)ดำเนินการ ซึ่งจะยกเลิกการดำเนินการครั้งสุดท้ายUnionรูปแบบขั้นสูงกว่านั้นอนุญาตBacktrack(i)ให้ยกเลิกการรวมกัน i ครั้งสุดท้าย ผลลัพธ์ความซับซ้อนต่อไปนี้เป็นที่ทราบกันดี: มีโครงสร้างข้อมูลที่รองรับUnion และFindในเวลาต่อการดำเนินการ และในเวลา[ 20 ]ในผลลัพธ์นี้ อิสระใน การเลือกตัวแทนของเซตที่สร้างขึ้นนั้นมีความสำคัญ ไม่สามารถบรรลุเวลาเฉลี่ยที่ดีกว่าได้ภายในกลุ่มของ อัลกอริทึมตัวชี้ที่แยกได้[ 20 ]BacktrackUnion

แอปพลิเคชัน
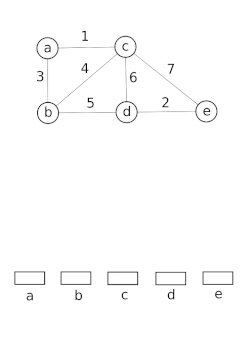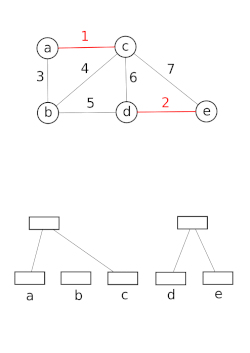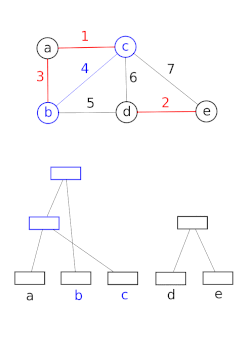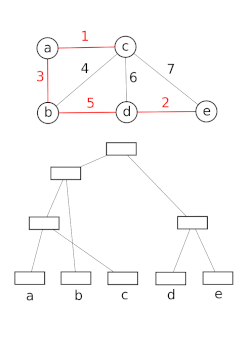
โครงสร้างข้อมูลเซตที่ไม่เกี่ยวข้องกันจำลองการแบ่งเซตตัวอย่างเช่น เพื่อติดตามส่วนประกอบที่เชื่อมต่อกันของกราฟแบบไม่มีทิศทางจากนั้นสามารถใช้แบบจำลองนี้เพื่อพิจารณาว่าจุดยอดสองจุดอยู่ในส่วนประกอบเดียวกันหรือไม่ หรือการเพิ่มขอบระหว่างจุดยอดทั้งสองจะส่งผลให้เกิดวงจรหรือไม่ อัลกอริทึม Union–Find ถูกใช้ในการใช้งานการรวมที่มีประสิทธิภาพสูง[ 21 ]
โครงสร้างข้อมูลนี้ถูกใช้โดยBoost Graph Libraryเพื่อใช้ งานฟังก์ชัน Incremental Connected Componentsนอกจากนี้ยังเป็นส่วนประกอบสำคัญในการใช้งานอัลกอริทึมของ Kruskalเพื่อค้นหาต้นไม้แผ่คลุมน้อยที่สุดของกราฟ อีกด้วย
อัลกอริทึม Hoshen -Kopelmanใช้การค้นหาแบบรวม (Union-Find)
Union-find สามารถนำมาใช้ในการสร้างอัลกอริธึม การอนุมานประเภท ที่มีประสิทธิภาพพอสมควรได้
ดูเพิ่มเติม
- การปรับปรุงพาร์ติชัน (Partition refinement ) เป็นโครงสร้างข้อมูลที่แตกต่างออกไปสำหรับการรักษาเซตที่ไม่ซ้ำกัน โดยการอัปเดตจะแยกเซตออกจากกันแทนที่จะรวมเข้าด้วยกัน
- การเชื่อมต่อแบบไดนามิก – โครงสร้างข้อมูลที่เก็บรักษาข้อมูลเกี่ยวกับส่วนประกอบที่เชื่อมต่อกันของกราฟ
ลิงก์ภายนอก
- การใช้งานในภาษา C++ซึ่งเป็นส่วนหนึ่งของไลบรารี Boost C++
- การใช้งานในภาษา Javaซึ่งเป็นส่วนหนึ่งของไลบรารี JGraphT
- การใช้งาน JavaScript
- การใช้งาน Python
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ โครงสร้างข้อมูลเซตที่ไม่เกี่ยวข้องกัน
ในวิทยาการคอมพิวเตอร์โครงสร้างข้อมูลเซตที่ไม่ซ้ำกัน (disjoint-set data structure ) หรือที่เรียกว่าโครงสร้างข้อมูลยูเนียน-ค้นหา (union–find data structure)หรือเซตผสาน-ค้นหา...
ประวัติศาสตร์
ป่าเซตที่ไม่เกี่ยวข้องกันได้รับการอธิบายครั้งแรกโดย Bernard A. Galler และ Michael J.
การเป็นตัวแทน
ในส่วนนี้และส่วนต่อไป เราจะอธิบายการใช้งานโครงสร้างข้อมูลเซตที่ไม่ซ้ำกันที่พบได้บ่อยที่สุด นั่นคือ ในรูปแบบของป่า ต้นไม้ตัวชี้ไปยังโหนดแม่ การแสดงผลแบบนี้เรียกว่า ต้นไม้แกลเลอร์-ฟิชเชอ ร์
การดำเนินงาน
โครงสร้างข้อมูลเซตที่ไม่ซ้ำกันรองรับการดำเนินการสามอย่าง ได้แก่ การสร้างเซตใหม่ที่มีองค์ประกอบใหม่ การค้นหาตัวแทนของเซตที่มีองค์ประกอบที่กำหนด และการรวมสองเซตเข้าด้วยกัน