อ่าน 15 นาที
เว็บครอว์เลอร์
เว็บครอว์เลอร์บางครั้งเรียกว่าสไปเดอร์หรือสไปเดอร์บอทและมักย่อเป็นครอว์เลอร์คือบอทอินเทอร์เน็ตที่เรียกดูเวิลด์ไวด์เว็บ อย่างเป็นระบบ...
เว็บครอว์เลอร์
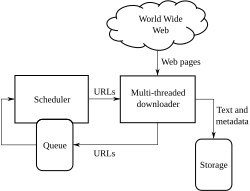
เว็บครอว์เลอร์บางครั้งเรียกว่าสไปเดอร์หรือสไปเดอร์บอทและมักย่อเป็นครอว์เลอร์คือบอทอินเทอร์เน็ตที่เรียกดูเวิลด์ไวด์เว็บ อย่างเป็นระบบ และโดยทั่วไปจะดำเนินการโดยเครื่องมือค้นหาเพื่อวัตถุประสงค์ในการจัดทำดัชนีเว็บ ( เว็บสไปเดอร์ริ่ง ) [ 1 ]
เครื่องมือค้นหาบนเว็บและเว็บไซต์ อื่นๆ บางแห่ง ใช้ซอฟต์แวร์ รวบรวมข้อมูลเว็บหรือซอฟต์แวร์สไปเดอร์ริ่ง เพื่ออัปเดตเนื้อหาเว็บ ของตนเอง หรือดัชนีเนื้อหาเว็บของเว็บไซต์อื่นๆ โปรแกรมรวบรวมข้อมูลเว็บจะคัดลอกหน้าเว็บเพื่อนำไปประมวลผลโดยเครื่องมือค้นหา ซึ่งจะจัดทำดัชนีหน้าเว็บที่ดาวน์โหลดมาเพื่อให้ผู้ใช้สามารถค้นหาได้อย่างมีประสิทธิภาพมากขึ้น
โปรแกรมรวบรวมข้อมูล (Crawler) ใช้ทรัพยากรบนระบบที่เข้าชม และมักเข้าชมเว็บไซต์โดยไม่ได้รับการร้องขอ ปัญหาเรื่องตารางเวลา การโหลด และ "ความสุภาพ" จะเข้ามามีบทบาทเมื่อมีการเข้าถึงหน้าเว็บจำนวนมาก มีกลไกสำหรับเว็บไซต์สาธารณะที่ไม่ต้องการให้โปรแกรมรวบรวมข้อมูลทราบ ตัวอย่างเช่น การแนบrobots.txtไฟล์สามารถขอให้บอทจัดทำดัชนีเฉพาะบางส่วนของเว็บไซต์ หรือไม่จัดทำดัชนีเลยก็ได้
จำนวนหน้าเว็บมีขนาดใหญ่มาก และเครื่องมือค้นหาไม่ได้จัดทำดัชนีเนื้อหาเว็บทั้งหมด การศึกษาเครื่องมือค้นหาในช่วงปลายทศวรรษ 1990 พบว่าเครื่องมือค้นหาแต่ละตัวจัดทำดัชนีเพียงเศษเสี้ยวของเว็บที่สามารถจัดทำดัชนีได้ในขณะนั้น[ 2 ] [ 3 ]เครื่องมือค้นหาสมัยใหม่ใช้ระบบการรวบรวม การจัดทำดัชนี และการจัดอันดับเพื่อส่งคืนผลลัพธ์ที่เกี่ยวข้องอย่างรวดเร็ว แม้ว่าจะไม่ได้รวบรวม จัดทำดัชนี หรือให้บริการทุกหน้าก็ตาม[ 4 ]
โปรแกรมรวบรวมข้อมูล (Crawler) สามารถตรวจสอบความถูกต้องของไฮเปอร์ลิงก์และ โค้ด HTMLได้ นอกจากนี้ยังสามารถใช้สำหรับการดึงข้อมูลจากเว็บไซต์และ การ เขียน โปรแกรมโดยใช้ข้อมูลเป็นหลัก ได้อีกด้วย
การตั้งชื่อ
เว็บครอว์เลอร์ยังเป็นที่รู้จักในชื่อสไปเดอร์ [ 5 ] แอนท์ตัวจัดทำดัชนีอัตโนมัติ [ 6 ]หรือ (ในบริบทของ ซอฟต์แวร์ FOAF ) เว็บสคัตเตอร์[ 7 ]
ภาพรวม
เว็บครอว์เลอร์เริ่มต้นด้วยรายการURLที่จะเยี่ยมชม URL แรกเหล่านั้นเรียกว่าซีด (seeds ) เมื่อครอว์เลอร์เยี่ยมชม URL เหล่านี้ โดยการสื่อสารกับเว็บเซิร์ฟเวอร์ที่ตอบสนองต่อ URL เหล่านั้น มันจะระบุไฮเปอร์ลิงก์ ทั้งหมด ในหน้าเว็บที่ดึงมาได้ และเพิ่มลงในรายการ URL ที่จะเยี่ยมชม ซึ่งเรียกว่า โครว์ลอร์นเทียร์ (crawl frontier ) URL จากฟรอนเทียร์จะ ถูกเยี่ยมชม แบบวนซ้ำตามชุดนโยบาย หากครอว์เลอร์กำลังทำการเก็บถาวรเว็บไซต์ (หรือการเก็บถาวรเว็บ ) มันจะคัดลอกและบันทึกข้อมูลไปพร้อมกัน โดยปกติแล้วไฟล์เก็บถาวรจะถูกจัดเก็บในลักษณะที่สามารถดู อ่าน และนำทางได้ราวกับว่าอยู่บนเว็บจริง แต่จะถูกเก็บรักษาไว้เป็น 'สแนปช็อต' [ 8 ]
ปริมาณข้อมูลจำนวนมากบ่งชี้ว่าโปรแกรมรวบรวมข้อมูลสามารถดาวน์โหลดหน้าเว็บได้เพียงจำนวนจำกัดภายในระยะเวลาที่กำหนด ดังนั้นจึงจำเป็นต้องจัดลำดับความสำคัญของการดาวน์โหลด อัตราการเปลี่ยนแปลงที่สูงอาจหมายความว่าหน้าเว็บเหล่านั้นอาจได้รับการอัปเดตหรือถูกลบไปแล้ว
จำนวน URL ที่เป็นไปได้ที่ซอฟต์แวร์ฝั่งเซิร์ฟเวอร์สร้างขึ้น ทำให้เว็บครอว์เลอร์หลีกเลี่ยงการดึงเนื้อหาซ้ำซ้อนได้ ยาก มี ชุดค่าผสมของ พารามิเตอร์ HTTP GET (ตาม URL) ที่ไม่มีที่สิ้นสุด ซึ่งมีเพียงส่วนน้อยเท่านั้นที่จะส่งคืนเนื้อหาที่ไม่ซ้ำกัน ตัวอย่างเช่น แกลเลอรีรูปภาพออนไลน์อย่างง่ายอาจมีตัวเลือกสามแบบให้ผู้ใช้เลือก ตามที่ระบุไว้ในพารามิเตอร์ HTTP GET ใน URL หากมีวิธีการเรียงลำดับรูปภาพสี่แบบ ขนาดภาพขนาด ย่อ สามแบบ รูปแบบไฟล์สองแบบ และตัวเลือกในการปิดใช้งานเนื้อหาที่ผู้ใช้ป้อน ชุดเนื้อหาเดียวกันสามารถเข้าถึงได้ด้วย URL ที่แตกต่างกันถึง 48 URL ซึ่งทั้งหมดอาจเชื่อมโยงกันอยู่ในเว็บไซต์การรวมกันทางคณิตศาสตร์ นี้ สร้างปัญหาให้กับครอว์เลอร์ เนื่องจากพวกมันต้องคัดกรองผ่านชุดค่าผสมที่ไม่มีที่สิ้นสุดของการเปลี่ยนแปลงเล็กน้อยที่เขียนด้วยสคริปต์ เพื่อดึงเนื้อหาที่ไม่ซ้ำกัน
ดังที่ Edwards และคณะได้กล่าวไว้ว่า "เนื่องจากแบนด์วิดท์สำหรับการดำเนินการรวบรวมข้อมูลนั้นไม่ได้มีไม่จำกัดและไม่ได้ฟรี จึงจำเป็นต้องรวบรวมข้อมูลบนเว็บด้วยวิธีการที่ไม่เพียงแต่ปรับขนาดได้ แต่ยังมีประสิทธิภาพด้วย หากต้องการรักษาระดับคุณภาพหรือความสดใหม่ในระดับที่เหมาะสม" [ 9 ]โปรแกรมรวบรวมข้อมูลต้องเลือกอย่างระมัดระวังในแต่ละขั้นตอนว่าจะเยี่ยมชมหน้าเว็บใดต่อไป
นโยบายการรวบรวมข้อมูล
พฤติกรรมของเว็บครอว์เลอร์เป็นผลมาจากการรวมกันของนโยบายต่างๆ: [ 10 ]
- นโยบายการคัดเลือกซึ่งระบุหน้าเว็บที่จะดาวน์โหลด
- นโยบายการเข้าชมซ้ำซึ่งระบุว่าควรตรวจสอบการเปลี่ยนแปลงของหน้าเว็บเมื่อใด
- นโยบายด้านมารยาทที่ระบุวิธีการหลีกเลี่ยงการทำให้เว็บไซต์ มีภาระมากเกินไป
- นโยบายการทำงานแบบขนานที่ระบุวิธีการประสานงานกับโปรแกรมรวบรวมข้อมูลเว็บแบบกระจาย
นโยบายการคัดเลือก
ด้วยขนาดของเว็บในปัจจุบัน แม้แต่เครื่องมือค้นหาขนาดใหญ่ก็ครอบคลุมเพียงส่วนหนึ่งของเว็บที่เปิดเผยต่อสาธารณะเท่านั้น การศึกษาในปี 2009 แสดงให้เห็นว่าแม้แต่เครื่องมือค้นหา ขนาดใหญ่ก็ยัง จัดทำดัชนีเว็บได้ไม่เกิน 40–70% [ 11 ]การศึกษาครั้งก่อนโดยSteve LawrenceและLee Gilesแสดงให้เห็นว่าไม่มีเครื่องมือค้นหาใดจัดทำดัชนีเว็บได้มากกว่า 16% ในปี 1999 [ 12 ]เนื่องจากโปรแกรมรวบรวมข้อมูลจะดาวน์โหลดเพียงเศษส่วนของหน้าเว็บ เท่านั้น จึงเป็นที่พึงปรารถนาอย่างยิ่งที่เศษส่วนที่ดาวน์โหลดมานั้นจะต้องมีหน้าเว็บที่เกี่ยวข้องมากที่สุด ไม่ใช่เพียงแค่ตัวอย่างแบบสุ่มของเว็บ
สิ่งนี้จำเป็นต้องมีตัวชี้วัดความสำคัญเพื่อจัดลำดับความสำคัญของหน้าเว็บ ความสำคัญของหน้าเว็บขึ้นอยู่กับ คุณภาพ โดยเนื้อแท้ความนิยมในแง่ของลิงก์หรือการเข้าชม และแม้กระทั่ง URL (กรณีหลังนี้เกิดขึ้นกับเครื่องมือค้นหาเฉพาะทาง ที่จำกัดอยู่เฉพาะ โดเมนระดับบนสุดเดียวหรือเครื่องมือค้นหาที่จำกัดอยู่เฉพาะเว็บไซต์ที่กำหนดไว้) การออกแบบนโยบายการคัดเลือกที่ดีนั้นมีความยากลำบากเพิ่มเติม คือ ต้องทำงานกับข้อมูลที่ไม่สมบูรณ์ เนื่องจากไม่ทราบชุดหน้าเว็บทั้งหมดในระหว่างการรวบรวมข้อมูล
Junghoo Cho และคณะได้ทำการศึกษาครั้งแรกเกี่ยวกับนโยบายสำหรับการจัดกำหนดการรวบรวมข้อมูล ชุดข้อมูลของพวกเขาคือการรวบรวมข้อมูล 180,000 หน้าจากstanford.eduโดเมน ซึ่งมีการจำลองการรวบรวมข้อมูลโดยใช้กลยุทธ์ที่แตกต่างกัน[ 13 ]ตัวชี้วัดลำดับที่ทดสอบ ได้แก่ การค้นหา แบบกว้าง (breadth-first) , จำนวน ลิงก์ย้อนกลับและ การคำนวณ PageRank บางส่วน ข้อสรุปประการหนึ่งคือ หากโปรแกรมรวบรวมข้อมูลต้องการดาวน์โหลดหน้าเว็บที่มี PageRank สูงในช่วงต้นของกระบวนการรวบรวมข้อมูล กลยุทธ์ PageRank บางส่วนจะดีกว่า ตามด้วยการค้นหาแบบกว้างและจำนวนลิงก์ย้อนกลับ อย่างไรก็ตาม ผลลัพธ์เหล่านี้ใช้ได้กับโดเมนเดียวเท่านั้น Cho ยังเขียนวิทยานิพนธ์ปริญญาเอกที่ Stanford เกี่ยวกับการรวบรวมข้อมูลเว็บอีกด้วย[ 14 ]
Marc Najorkและ Janet Wiener ได้ทำการรวบรวมข้อมูลจริงบนหน้าเว็บ 328 ล้านหน้า โดยใช้การเรียงลำดับแบบกว้าง[ 15 ]พวกเขาพบว่าการรวบรวมข้อมูลแบบกว้างจะจับหน้าเว็บที่มี Pagerank สูงได้ตั้งแต่ช่วงต้นของการรวบรวมข้อมูล (แต่พวกเขาไม่ได้เปรียบเทียบกลยุทธ์นี้กับกลยุทธ์อื่นๆ) คำอธิบายที่ผู้เขียนให้ไว้สำหรับผลลัพธ์นี้คือ "หน้าเว็บที่สำคัญที่สุดมีลิงก์จำนวนมากจากโฮสต์หลายแห่ง และลิงก์เหล่านั้นจะถูกค้นพบตั้งแต่เนิ่นๆ โดยไม่คำนึงถึงว่าการรวบรวมข้อมูลเริ่มต้นจากโฮสต์หรือหน้าเว็บใด"
Abiteboul ออกแบบกลยุทธ์การรวบรวมข้อมูลโดยใช้อัลกอริทึมที่เรียกว่า OPIC (On-line Page Importance Computation) [ 16 ]ใน OPIC แต่ละหน้าจะได้รับ "เงินสด" จำนวนหนึ่งซึ่งกระจายอย่างเท่าเทียมกันในหมู่หน้าที่ชี้ไป คล้ายกับการคำนวณ PageRank แต่เร็วกว่าและทำเพียงขั้นตอนเดียว โปรแกรมรวบรวมข้อมูลที่ขับเคลื่อนด้วย OPIC จะดาวน์โหลดหน้าในขอบเขตการรวบรวมข้อมูลที่มี "เงินสด" สูงกว่าก่อน การทดลองดำเนินการในกราฟสังเคราะห์ 100,000 หน้าที่มีการกระจายแบบกำลังของลิงก์ขาเข้า อย่างไรก็ตาม ไม่มีการเปรียบเทียบกับกลยุทธ์อื่นหรือการทดลองในเว็บจริง
Boldi และคณะใช้การจำลองบนชุดย่อยของเว็บจำนวน 40 ล้านหน้าจาก.itโดเมนและ 100 ล้านหน้าจากการรวบรวมข้อมูลของ WebBase โดยทดสอบการค้นหาแบบกว้างก่อนเทียบกับการค้นหาแบบลึกก่อน การเรียงลำดับแบบสุ่ม และกลยุทธ์แบบรอบรู้ การเปรียบเทียบขึ้นอยู่กับว่า PageRank ที่คำนวณจากการรวบรวมข้อมูลบางส่วนนั้นใกล้เคียงกับค่า PageRank ที่แท้จริงมากน้อยเพียงใด การเข้าชมบางประเภทที่สะสม PageRank ได้อย่างรวดเร็ว (โดยเฉพาะอย่างยิ่ง การค้นหาแบบกว้างก่อนและการเข้าชมแบบรอบรู้) จะให้ค่าประมาณแบบก้าวหน้าที่ไม่ดีนัก[ 17 ] [ 18 ]
Baeza-Yates และคณะใช้การจำลองกับเว็บสองชุดย่อยที่มี 3 ล้านหน้าจาก โดเมน .grและ.clทดสอบกลยุทธ์การรวบรวมข้อมูลหลายแบบ[ 19 ]พวกเขาแสดงให้เห็นว่าทั้งกลยุทธ์ OPIC และกลยุทธ์ที่ใช้ความยาวของคิวต่อไซต์นั้นดีกว่า การรวบรวมข้อมูล แบบกว้างและยังมีประสิทธิภาพมากในการใช้การรวบรวมข้อมูลครั้งก่อนหน้าเมื่อมีให้ใช้งานเพื่อเป็นแนวทางในการรวบรวมข้อมูลปัจจุบัน
Daneshpajouh และคณะได้ออกแบบอัลกอริธึมแบบชุมชนเพื่อค้นหาเมล็ดพันธุ์ที่ดี[ 20 ]วิธีการของพวกเขารวบรวมเว็บเพจที่มี PageRank สูงจากชุมชนต่างๆ โดยใช้จำนวนรอบน้อยกว่าเมื่อเปรียบเทียบกับการรวบรวมที่เริ่มต้นจากเมล็ดพันธุ์แบบสุ่ม สามารถดึงเมล็ดพันธุ์ที่ดีจากกราฟเว็บที่รวบรวมไว้ก่อนหน้านี้ได้โดยใช้วิธีการใหม่นี้ การใช้เมล็ดพันธุ์เหล่านี้จะทำให้การรวบรวมใหม่มีประสิทธิภาพมากยิ่งขึ้น
การจำกัดลิงก์ที่ติดตาม
โปรแกรมรวบรวมข้อมูลอาจต้องการค้นหาเฉพาะหน้าเว็บ HTML และหลีกเลี่ยงประเภท MIME อื่นๆ เพื่อให้ได้เฉพาะทรัพยากร HTML โปรแกรมรวบรวมข้อมูลอาจทำการร้องขอ HTTP HEAD เพื่อตรวจสอบประเภท MIME ของทรัพยากรเว็บก่อนที่จะร้องขอทรัพยากรทั้งหมดด้วยการร้องขอ GET เพื่อหลีกเลี่ยงการทำการร้องขอ HEAD จำนวนมาก โปรแกรมรวบรวมข้อมูลอาจตรวจสอบ URL และร้องขอทรัพยากรเฉพาะเมื่อ URL ลงท้ายด้วยอักขระบางอย่าง เช่น .html, .htm, .asp, .aspx, .php, .jsp, .jspx หรือเครื่องหมายทับ กลยุทธ์นี้อาจทำให้ทรัพยากรเว็บ HTML จำนวนมากถูกข้ามไปโดยไม่ได้ตั้งใจ
โปรแกรมรวบรวมข้อมูลบางตัวอาจหลีกเลี่ยงการร้องขอทรัพยากรใดๆ ที่มีเครื่องหมาย"?"อยู่ในนั้น (ซึ่งสร้างขึ้นแบบไดนามิก) เพื่อหลีกเลี่ยงกับดักของโปรแกรมรวบรวมข้อมูลที่อาจทำให้โปรแกรมดาวน์โหลด URL จำนวนมหาศาลจากเว็บไซต์ วิธีนี้ไม่น่าเชื่อถือหากเว็บไซต์ใช้การเขียน URL ใหม่เพื่อลดความซับซ้อนของ URL
เจ้าของเว็บไซต์อาจกำหนดไฟล์ robots.txtเพื่อแจ้งให้โปรแกรมรวบรวมข้อมูลทราบว่าอนุญาตและไม่อนุญาตการเข้าถึงทรัพยากรใดบ้างจากนั้นโปรแกรมรวบรวมข้อมูลจะใช้ข้อมูลดังกล่าวในการเลือกติดตามลิงก์ใดและหลีกเลี่ยงลิงก์ใด
การทำให้ URL เป็นมาตรฐาน
โดยปกติแล้ว โปรแกรมรวบรวมข้อมูลจะทำการ ปรับมาตรฐาน URLบางประเภทเพื่อหลีกเลี่ยงการรวบรวมข้อมูลทรัพยากรเดียวกันมากกว่าหนึ่งครั้ง คำว่าการปรับมาตรฐาน URLหรือที่เรียกว่าการกำหนดมาตรฐาน URLหมายถึงกระบวนการแก้ไขและกำหนดมาตรฐาน URL ในลักษณะที่สอดคล้องกัน มีการปรับมาตรฐานหลายประเภทที่อาจดำเนินการได้ รวมถึงการแปลง URL เป็นตัวพิมพ์เล็ก การลบส่วน "." และ ".." และการเพิ่มสแลชต่อท้ายให้กับส่วนประกอบเส้นทางที่ไม่ว่างเปล่า[ 21 ]
การคลานขึ้นไปตามทาง
โปรแกรมรวบรวมข้อมูลบางตัวตั้งใจที่จะดาวน์โหลด/อัปโหลดทรัพยากรให้ได้มากที่สุดเท่าที่จะเป็นไปได้จากเว็บไซต์ใดเว็บไซต์หนึ่ง ดังนั้นจึง มีการนำ โปรแกรมรวบรวมข้อมูลแบบไล่ระดับเส้นทางมาใช้ซึ่งจะไล่ระดับไปยังทุกเส้นทางในแต่ละ URL ที่ตั้งใจจะรวบรวมข้อมูล[ 22 ]ตัวอย่างเช่น เมื่อได้รับ URL เริ่มต้นเป็น http://llama.org/hamster/monkey/page.html มันจะพยายามรวบรวมข้อมูล /hamster/monkey/, /hamster/ และ / Cothey พบว่าโปรแกรมรวบรวมข้อมูลแบบไล่ระดับเส้นทางมีประสิทธิภาพมากในการค้นหาทรัพยากรที่แยกเดี่ยว หรือทรัพยากรที่ไม่มีลิงก์ขาเข้าใดๆ ที่จะพบได้ในการรวบรวมข้อมูลแบบปกติ
การคลานอย่างมีสมาธิ
ความสำคัญของหน้าเว็บสำหรับโปรแกรมรวบรวมข้อมูลสามารถแสดงได้ในรูปของฟังก์ชันความคล้ายคลึงกันของหน้าเว็บกับคำค้นหาที่กำหนด โปรแกรมรวบรวมข้อมูลเว็บที่พยายามดาวน์โหลดหน้าเว็บที่คล้ายคลึงกันเรียกว่าโปรแกรมรวบรวมข้อมูลแบบเน้นเฉพาะ เรื่อง หรือโปรแกรมรวบรวมข้อมูลตามหัวข้อแนวคิดของการรวบรวมข้อมูลตามหัวข้อและแบบเน้นเฉพาะเรื่องได้รับการแนะนำครั้งแรกโดยFilippo Menczer [ 23 ] [ 24 ]และโดย Soumen Chakrabarti et al. [ 25 ]
ปัญหาหลักในการรวบรวมข้อมูลแบบเน้นเป้าหมายคือ ในบริบทของเว็บครอว์เลอร์ เราต้องการที่จะสามารถคาดการณ์ความคล้ายคลึงกันของข้อความในหน้าเว็บที่กำหนดกับคำค้นหาก่อนที่จะดาวน์โหลดหน้าเว็บจริง ตัวบ่งชี้ที่เป็นไปได้คือข้อความแองเคอร์ของลิงก์ ซึ่งเป็นแนวทางที่ Pinkerton [ 26 ] ใช้ ในเว็บครอว์เลอร์ตัวแรกในยุคแรกๆ ของเว็บ Diligenti et al. [ 27 ]เสนอให้ใช้เนื้อหาทั้งหมดของหน้าเว็บที่เข้าชมแล้วเพื่ออนุมานความคล้ายคลึงกันระหว่างคำค้นหาหลักกับหน้าเว็บที่ยังไม่ได้เข้าชม ประสิทธิภาพของการรวบรวมข้อมูลแบบเน้นเป้าหมายขึ้นอยู่กับความสมบูรณ์ของลิงก์ในหัวข้อเฉพาะที่กำลังค้นหาเป็นส่วนใหญ่ และการรวบรวมข้อมูลแบบเน้นเป้าหมายมักจะอาศัยเครื่องมือค้นหาเว็บทั่วไปในการให้จุดเริ่มต้น
โปรแกรมรวบรวมข้อมูลที่เน้นด้านวิชาการ
ตัวอย่างของโปรแกรมรวบรวมข้อมูลแบบเน้นเฉพาะด้านได้แก่ โปรแกรมรวบรวมข้อมูลทางวิชาการ ซึ่งรวบรวมข้อมูลเอกสารทางวิชาการที่เข้าถึงได้ฟรี เช่นciteseerxbotซึ่งเป็นโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาCiteSeer X เครื่องมือค้นหาทางวิชาการอื่นๆ ได้แก่ Google ScholarและMicrosoft Academic Searchเป็นต้น เนื่องจากเอกสารทางวิชาการส่วนใหญ่เผยแพร่ใน รูปแบบ PDFโปรแกรมรวบรวมข้อมูลประเภทนี้จึงสนใจเป็นพิเศษในการรวบรวมข้อมูลไฟล์ PDF, PostScript , Microsoft Wordรวมถึง รูปแบบไฟล์ ซิปด้วยเหตุนี้ โปรแกรมรวบรวมข้อมูลโอเพนซอร์สทั่วไป เช่นHeritrixจึงต้องได้รับการปรับแต่งเพื่อกรองประเภท MIME อื่นๆ หรือใช้มิดเดิลแวร์ เพื่อแยกเอกสารเหล่านี้ออกมาและนำเข้าสู่ฐานข้อมูลและที่เก็บข้อมูลการรวบรวมข้อมูลแบบเน้นเฉพาะด้าน [ 28 ]การระบุว่าเอกสารเหล่านี้เป็นเอกสารทางวิชาการหรือไม่นั้นเป็นเรื่องท้าทายและอาจเพิ่มภาระให้กับกระบวนการรวบรวมข้อมูลอย่างมาก ดังนั้นจึงดำเนินการเป็นกระบวนการหลังการรวบรวมข้อมูลโดยใช้การเรียนรู้ของเครื่องหรือ อัลกอริธึม การแสดงออกปกติเอกสารทางวิชาการเหล่านี้มักได้รับจากหน้าแรกของคณะและนักศึกษา หรือจากหน้าสิ่งพิมพ์ของสถาบันวิจัย เนื่องจากเอกสารทางวิชาการคิดเป็นเพียงส่วนน้อยของหน้าเว็บทั้งหมด การเลือก seed ที่ดีจึงมีความสำคัญในการเพิ่มประสิทธิภาพของ web crawler เหล่านี้[ 29 ] crawler ทางวิชาการอื่นๆ อาจดาวน์โหลดไฟล์ข้อความธรรมดาและ ไฟล์ HTMLที่มีข้อมูลเมตาของเอกสารทางวิชาการ เช่น ชื่อเรื่อง บทความ และบทคัดย่อ ซึ่งจะเพิ่มจำนวนเอกสารโดยรวม แต่เอกสารจำนวนมากอาจไม่มีไฟล์ PDF ให้ดาวน์โหลดฟรี
โปรแกรมรวบรวมข้อมูลที่เน้นความหมาย
โปรแกรมรวบรวมข้อมูลแบบเน้นเป้าหมายอีกประเภทหนึ่งคือโปรแกรมรวบรวมข้อมูลแบบเน้นความหมาย ซึ่งใช้ออนโทโลยีโดเมนเพื่อแสดงแผนที่หัวข้อและเชื่อมโยงหน้าเว็บกับแนวคิดออนโทโลยีที่เกี่ยวข้องเพื่อวัตถุประสงค์ในการเลือกและจัดหมวดหมู่[ 30 ]นอกจากนี้ ออนโทโลยียังสามารถอัปเดตได้โดยอัตโนมัติในกระบวนการรวบรวมข้อมูล Dong et al. [ 31 ]ได้แนะนำโปรแกรมรวบรวมข้อมูลแบบเรียนรู้ออนโทโลยีโดยใช้เครื่องสนับสนุนเวกเตอร์เพื่ออัปเดตเนื้อหาของแนวคิดออนโทโลยีเมื่อรวบรวมข้อมูลหน้าเว็บ
นโยบายการเข้าชมซ้ำ
เว็บมีลักษณะที่เปลี่ยนแปลงอยู่ตลอดเวลา และการรวบรวมข้อมูลเพียงส่วนเล็ก ๆ ของเว็บอาจใช้เวลาหลายสัปดาห์หรือหลายเดือน กว่าที่โปรแกรมรวบรวมข้อมูลเว็บจะรวบรวมข้อมูลเสร็จสิ้น เหตุการณ์ต่าง ๆ มากมายอาจเกิดขึ้นแล้ว รวมถึงการสร้าง การอัปเดต และการลบข้อมูล
จากมุมมองของเครื่องมือค้นหา มีค่าใช้จ่ายที่เกี่ยวข้องกับการไม่ตรวจพบเหตุการณ์ และส่งผลให้มีสำเนาทรัพยากรที่ล้าสมัย ฟังก์ชันต้นทุนที่ใช้มากที่สุดคือความสดใหม่และอายุ[ 32 ]
ความสดใหม่ : นี่คือการวัดแบบไบนารีที่บ่งชี้ว่าสำเนาในเครื่องนั้นถูกต้องหรือไม่ ความสดใหม่ของหน้าpในที่เก็บข้อมูล ณ เวลาtกำหนดโดย:

อายุ : นี่คือตัวชี้วัดที่บ่งบอกว่าสำเนาในเครื่องนั้นล้าสมัยแค่ไหน อายุของหน้าpในที่เก็บข้อมูล ณ เวลาtกำหนดโดย:

Coffman และคณะทำงานโดยใช้คำจำกัดความของวัตถุประสงค์ของเว็บครอว์เลอร์ที่เทียบเท่ากับความสดใหม่ แต่ใช้ถ้อยคำที่แตกต่างออกไป พวกเขาเสนอว่าครอว์เลอร์ต้องลดสัดส่วนของเวลาที่หน้าเว็บยังคงล้าสมัยให้น้อยที่สุด นอกจากนี้พวกเขายังตั้งข้อสังเกตว่าปัญหาของเว็บครอว์เลอร์สามารถจำลองได้เป็นระบบโพลลิ่งแบบหลายคิว เซิร์ฟเวอร์เดียว โดยที่เว็บครอว์เลอร์เป็นเซิร์ฟเวอร์และเว็บไซต์เป็นคิว การแก้ไขหน้าเว็บคือการมาถึงของลูกค้า และเวลาเปลี่ยนผ่านคือช่วงเวลาระหว่างการเข้าถึงหน้าเว็บไปยังเว็บไซต์เดียว ภายใต้แบบจำลองนี้ เวลารอเฉลี่ยของลูกค้าในระบบโพลลิ่งจะเทียบเท่ากับอายุเฉลี่ยของเว็บครอว์เลอร์[ 33 ]
เป้าหมายของโปรแกรมรวบรวมข้อมูลคือการรักษาระดับความทันสมัยเฉลี่ยของหน้าเว็บในคอลเลกชันให้สูงที่สุดเท่าที่จะเป็นไปได้ หรือรักษาระดับอายุเฉลี่ยของหน้าเว็บให้ต่ำที่สุดเท่าที่จะเป็นไปได้ เป้าหมายทั้งสองนี้ไม่เหมือนกัน: ในกรณีแรก โปรแกรมรวบรวมข้อมูลจะสนใจเพียงว่ามีหน้าเว็บที่ล้าสมัยกี่หน้า ในขณะที่ในกรณีที่สอง โปรแกรมรวบรวมข้อมูลจะสนใจว่าสำเนาหน้าเว็บในเครื่องนั้นมีอายุเท่าใด

Cho และ Garcia-Molina ได้ศึกษานโยบายการกลับมาเยี่ยมเยียนแบบง่ายๆ สองแบบ: [ 34 ]
- นโยบายที่เป็นเอกภาพ: นโยบายนี้เกี่ยวข้องกับการกลับไปเยี่ยมชมทุกหน้าในชุดข้อมูลด้วยความถี่ที่เท่ากัน โดยไม่คำนึงถึงอัตราการเปลี่ยนแปลงของหน้าเหล่านั้น
- นโยบายตามสัดส่วน: วิธีนี้เกี่ยวข้องกับการกลับไปเยี่ยมชมหน้าเว็บที่มีการเปลี่ยนแปลงบ่อยขึ้น ความถี่ในการเยี่ยมชมจะเป็นสัดส่วนโดยตรงกับความถี่ของการเปลี่ยนแปลง (ที่คาดการณ์ไว้)
ในทั้งสองกรณี ลำดับการรวบรวมข้อมูลหน้าเว็บซ้ำๆ สามารถทำได้ทั้งแบบสุ่มหรือแบบกำหนดลำดับไว้ล่วงหน้า
Cho และ Garcia-Molina ได้พิสูจน์ผลลัพธ์ที่น่าประหลาดใจว่า ในแง่ของความสดใหม่โดยเฉลี่ย นโยบายแบบสม่ำเสมอมีประสิทธิภาพเหนือกว่านโยบายแบบสัดส่วน ทั้งในเว็บจำลองและการรวบรวมข้อมูลเว็บจริง เหตุผลโดยสัญชาตญาณคือ เนื่องจากโปรแกรมรวบรวมข้อมูลเว็บมีข้อจำกัดว่าสามารถรวบรวมข้อมูลได้กี่หน้าในกรอบเวลาที่กำหนด (1) พวกมันจะจัดสรรการรวบรวมข้อมูลใหม่มากเกินไปให้กับหน้าที่มีการเปลี่ยนแปลงอย่างรวดเร็ว โดยเสียสละหน้าที่มีการเปลี่ยนแปลงน้อยกว่า และ (2) ความสดใหม่ของหน้าที่มีการเปลี่ยนแปลงอย่างรวดเร็วจะคงอยู่เป็นระยะเวลาสั้นกว่าหน้าที่มีการเปลี่ยนแปลงน้อยกว่า กล่าวอีกนัยหนึ่ง นโยบายแบบสัดส่วนจะจัดสรรทรัพยากรมากขึ้นให้กับการรวบรวมข้อมูลหน้าที่มีการเปลี่ยนแปลงบ่อย แต่จะมีความสดใหม่โดยรวมน้อยกว่า
เพื่อปรับปรุงความสดใหม่ โปรแกรมรวบรวมข้อมูลควรลงโทษองค์ประกอบที่เปลี่ยนแปลงบ่อยเกินไป[ 35 ]นโยบายการเยี่ยมชมซ้ำที่เหมาะสมที่สุดไม่ใช่ทั้งนโยบายแบบสม่ำเสมอหรือนโยบายแบบสัดส่วน วิธีการที่เหมาะสมที่สุดในการรักษาความสดใหม่โดยเฉลี่ยให้สูงนั้นรวมถึงการละเลยหน้าที่เปลี่ยนแปลงบ่อยเกินไป และวิธีการที่เหมาะสมที่สุดในการรักษาอายุเฉลี่ยให้ต่ำคือการใช้ความถี่ในการเข้าถึงที่เพิ่มขึ้นอย่างต่อเนื่อง (และต่ำกว่าเชิงเส้น) ตามอัตราการเปลี่ยนแปลงของแต่ละหน้า ในทั้งสองกรณี ค่าที่เหมาะสมที่สุดจะใกล้เคียงกับนโยบายแบบสม่ำเสมอมากกว่านโยบายแบบสัดส่วน ดังที่Coffman et al.ตั้งข้อสังเกตว่า "เพื่อลดเวลาการล้าสมัยที่คาดหวัง การเข้าถึงหน้าใดหน้าหนึ่งควรมีระยะห่างที่สม่ำเสมอที่สุดเท่าที่จะเป็นไปได้" [ 33 ]โดยทั่วไปแล้วไม่สามารถกำหนดสูตรที่ชัดเจนสำหรับนโยบายการเยี่ยมชมซ้ำได้ แต่จะได้รับในเชิงตัวเลข เนื่องจากขึ้นอยู่กับการกระจายของการเปลี่ยนแปลงหน้า Cho และ Garcia-Molina แสดงให้เห็นว่าการแจกแจงแบบเอกซ์โพเนนเชียลเหมาะสมดีสำหรับการอธิบายการเปลี่ยนแปลงของหน้าเว็บ[ 35 ]ในขณะที่Ipeirotis และคณะแสดงวิธีการใช้เครื่องมือทางสถิติเพื่อค้นหาพารามิเตอร์ที่ส่งผลต่อการแจกแจงนี้[ 36 ]นโยบายการกลับมาเยี่ยมชมที่พิจารณาในที่นี้ถือว่าทุกหน้าเว็บมีคุณภาพเหมือนกันหมด ("ทุกหน้าเว็บบนเว็บมีค่าเท่ากัน") ซึ่งไม่ใช่สถานการณ์ที่สมจริง ดังนั้นควรมีข้อมูลเพิ่มเติมเกี่ยวกับคุณภาพของหน้าเว็บเพื่อให้ได้นโยบายการรวบรวมข้อมูลที่ดีขึ้น
นโยบายความสุภาพ
โปรแกรมรวบรวมข้อมูล (Crawler) สามารถดึงข้อมูลได้เร็วกว่าและละเอียดกว่าผู้ค้นหาที่เป็นมนุษย์มาก ดังนั้นจึงอาจส่งผลกระทบอย่างรุนแรงต่อประสิทธิภาพของเว็บไซต์ หากโปรแกรมรวบรวมข้อมูลตัวเดียวทำการร้องขอหลายครั้งต่อวินาทีและ/หรือดาวน์โหลดไฟล์ขนาดใหญ่ เซิร์ฟเวอร์อาจรับมือกับการร้องขอจากโปรแกรมรวบรวมข้อมูลหลายตัวพร้อมกันไม่ไหว
ตามที่ Koster กล่าวไว้ การใช้เว็บครอว์เลอร์มีประโยชน์สำหรับงานหลายอย่าง แต่มีค่าใช้จ่ายสำหรับชุมชนทั่วไป[ 37 ]ค่าใช้จ่ายในการใช้เว็บครอว์เลอร์ ได้แก่:
- ทรัพยากรเครือข่าย เนื่องจากโปรแกรมรวบรวมข้อมูลต้องการแบนด์วิดท์จำนวนมากและทำงานแบบขนานในระดับสูงเป็นเวลานาน
- เซิร์ฟเวอร์ทำงานหนักเกินไป โดยเฉพาะอย่างยิ่งหากความถี่ในการเข้าถึงเซิร์ฟเวอร์นั้นสูงเกินไป
- โปรแกรมรวบรวมข้อมูลที่เขียนไม่ดี ซึ่งอาจทำให้เซิร์ฟเวอร์หรือเราเตอร์ล่ม หรือดาวน์โหลดหน้าเว็บที่ไม่สามารถจัดการได้ และ
- โปรแกรมรวบรวมข้อมูลส่วนบุคคล หากถูกใช้งานโดยผู้ใช้จำนวนมากเกินไป อาจทำให้เครือข่ายและเว็บเซิร์ฟเวอร์หยุดชะงักได้
วิธีแก้ปัญหาบางส่วนสำหรับปัญหาเหล่านี้คือโปรโตคอลการยกเว้นหุ่นยนต์หรือที่รู้จักกันในชื่อโปรโตคอล robots.txt ซึ่งเป็นมาตรฐานสำหรับผู้ดูแลระบบในการระบุส่วนต่างๆ ของเว็บเซิร์ฟเวอร์ที่ไม่ควรให้ครอว์เลอร์เข้าถึง[ 38 ]มาตรฐานนี้ไม่ได้รวมคำแนะนำสำหรับช่วงเวลาในการเยี่ยมชมเซิร์ฟเวอร์เดียวกัน แม้ว่าช่วงเวลานี้จะเป็นวิธีที่มีประสิทธิภาพที่สุดในการหลีกเลี่ยงการโอเวอร์โหลดเซิร์ฟเวอร์ก็ตาม เมื่อไม่นานมานี้ เครื่องมือค้นหาเชิงพาณิชย์ เช่นGoogle , Ask Jeeves , MSNและYahoo! Searchสามารถใช้พารามิเตอร์ "Crawl-delay:" เพิ่มเติมใน ไฟล์ robots.txtเพื่อระบุจำนวนวินาทีที่จะหน่วงเวลาระหว่างคำขอ
ช่วงเวลาแรกที่เสนอระหว่างการโหลดหน้าเว็บที่ต่อเนื่องกันคือ 60 วินาที[ 39 ]อย่างไรก็ตาม หากมีการดาวน์โหลดหน้าเว็บในอัตรานี้จากเว็บไซต์ที่มีมากกว่า 100,000 หน้าผ่านการเชื่อมต่อที่สมบูรณ์แบบด้วยความหน่วงเป็นศูนย์และแบนด์วิดท์ไม่จำกัด จะต้องใช้เวลามากกว่า 2 เดือนในการดาวน์โหลดเว็บไซต์ทั้งหมดนั้น นอกจากนี้ จะมีการใช้ทรัพยากรจากเว็บเซิร์ฟเวอร์เพียงส่วนน้อยเท่านั้น
Cho ใช้ช่วงเวลา 10 วินาทีสำหรับการเข้าถึง[ 34 ]และ WIRE crawler ใช้ 15 วินาทีเป็นค่าเริ่มต้น[ 40 ] MercatorWeb crawler ปฏิบัติตามนโยบายความสุภาพแบบปรับได้: หากใช้เวลาtวินาทีในการดาวน์โหลดเอกสารจากเซิร์ฟเวอร์ที่กำหนด crawler จะรอ 10 tวินาทีก่อนที่จะดาวน์โหลดหน้าถัดไป[ 41 ] Dill และคณะใช้ 1 วินาที[ 42 ]
สำหรับผู้ที่ใช้เว็บครอว์เลอร์เพื่อวัตถุประสงค์ในการวิจัย จำเป็นต้องมีการวิเคราะห์ต้นทุนและผลประโยชน์ที่ละเอียดมากขึ้น และควรคำนึงถึงข้อควรพิจารณาด้านจริยธรรมเมื่อตัดสินใจว่าจะครอว์เลอร์ที่ใดและครอว์เลอร์ด้วยความเร็วเท่าใด[ 43 ]
หลักฐานเชิงประจักษ์จากบันทึกการเข้าถึงแสดงให้เห็นว่าช่วงเวลาการเข้าถึงจากครอว์เลอร์ที่รู้จักนั้นแตกต่างกันไปตั้งแต่ 20 วินาทีถึง 3–4 นาที เป็นที่น่าสังเกตว่าแม้จะสุภาพมากและใช้มาตรการป้องกันทั้งหมดเพื่อหลีกเลี่ยงการโอเวอร์โหลดเว็บเซิร์ฟเวอร์ แต่ก็ยังได้รับการร้องเรียนจากผู้ดูแลระบบเว็บเซิร์ฟเวอร์อยู่บ้างSergey BrinและLarry Pageตั้งข้อสังเกตในปี 1998 ว่า "...การใช้งานครอว์เลอร์ที่เชื่อมต่อกับเซิร์ฟเวอร์มากกว่าครึ่งล้านเครื่อง...ก่อให้เกิดอีเมลและโทรศัพท์จำนวนมาก เนื่องจากมีผู้คนจำนวนมากเข้ามาใช้งานออนไลน์ จึงมีผู้ที่ไม่รู้จักครอว์เลอร์อยู่เสมอ เพราะนี่เป็นครั้งแรกที่พวกเขาเห็น" [ 44 ]
นโยบายการทำงานแบบขนาน
โปรแกรม รวบรวมข้อมูล แบบขนาน (Parallel crawler) คือโปรแกรมรวบรวมข้อมูลที่ทำงานหลายกระบวนการพร้อมกัน เป้าหมายคือการเพิ่มอัตราการดาวน์โหลดให้สูงสุด ในขณะที่ลดภาระจากการทำงานแบบขนานให้น้อยที่สุด และหลีกเลี่ยงการดาวน์โหลดหน้าเดียวกันซ้ำๆ เพื่อหลีกเลี่ยงการดาวน์โหลดหน้าเดียวกันมากกว่าหนึ่งครั้ง ระบบรวบรวมข้อมูลจึงต้องมีนโยบายสำหรับการกำหนด URL ใหม่ที่ค้นพบระหว่างกระบวนการรวบรวมข้อมูล เนื่องจาก URL เดียวกันอาจถูกค้นพบโดยกระบวนการรวบรวมข้อมูลสองกระบวนการที่แตกต่างกัน
สถาปัตยกรรม

โปรแกรมรวบรวมข้อมูลไม่เพียงแต่ต้องมีกลยุทธ์การรวบรวมข้อมูลที่ดีดังที่ได้กล่าวไว้ในหัวข้อก่อนหน้านี้เท่านั้น แต่ยังควรมีสถาปัตยกรรมที่ได้รับการปรับแต่งอย่างดีเยี่ยมอีกด้วย
Shkapenyuk และ Suel ตั้งข้อสังเกตว่า: [ 45 ]
แม้ว่าจะค่อนข้างง่ายที่จะสร้างโปรแกรมรวบรวมข้อมูลที่ทำงานช้าซึ่งดาวน์โหลดได้เพียงไม่กี่หน้าต่อวินาทีในช่วงเวลาสั้นๆ แต่การสร้างระบบประสิทธิภาพสูงที่สามารถดาวน์โหลดหลายร้อยล้านหน้าในระยะเวลาหลายสัปดาห์นั้นมีความท้าทายหลายประการในด้านการออกแบบระบบ ประสิทธิภาพด้าน I/O และเครือข่าย รวมถึงความทนทานและการจัดการ
โปรแกรมรวบรวมข้อมูลบนเว็บ (Web crawler) เป็นส่วนสำคัญของเครื่องมือค้นหา และรายละเอียดเกี่ยวกับอัลกอริทึมและสถาปัตยกรรมของโปรแกรมเหล่านี้ถูกเก็บเป็นความลับทางธุรกิจ เมื่อมีการเผยแพร่การออกแบบโปรแกรมรวบรวมข้อมูล มักจะขาดรายละเอียดที่สำคัญซึ่งทำให้ผู้อื่นไม่สามารถทำซ้ำได้ นอกจากนี้ยังมีข้อกังวลที่เกิดขึ้นใหม่เกี่ยวกับ " การสแปมเครื่องมือค้นหา " ซึ่งทำให้เครื่องมือค้นหาหลัก ๆ ไม่เผยแพร่อัลกอริทึมการจัดอันดับของตน
ความปลอดภัย
แม้ว่าเจ้าของเว็บไซต์ส่วนใหญ่จะต้องการให้หน้าเว็บของตนได้รับการจัดทำดัชนีอย่างกว้างขวางที่สุดเท่าที่จะเป็นไปได้ เพื่อให้มีอันดับที่ดีในเครื่องมือค้นหาแต่การรวบรวมข้อมูลเว็บก็อาจส่งผลกระทบที่ไม่คาดคิดและนำไปสู่ การรั่ว ไหลของข้อมูลได้ หากเครื่องมือค้นหาจัดทำดัชนีทรัพยากรที่ไม่ควรเปิดเผยต่อสาธารณะ หรือหน้าเว็บที่เปิดเผยซอฟต์แวร์เวอร์ชันที่อาจมีช่องโหว่
นอกเหนือจาก คำแนะนำ ด้านความปลอดภัยของแอปพลิเคชันเว็บ มาตรฐานแล้ว เจ้าของเว็บไซต์ยังสามารถลดความเสี่ยงจากการถูกแฮ็กโดยฉวยโอกาสได้โดยการอนุญาตให้เครื่องมือค้นหาจัดทำดัชนีเฉพาะส่วนสาธารณะของเว็บไซต์เท่านั้น (ด้วยrobots.txt ) และบล็อกไม่ให้เครื่องมือค้นหาจัดทำดัชนีส่วนที่เกี่ยวข้องกับการทำธุรกรรม (หน้าเข้าสู่ระบบ หน้าส่วนตัว ฯลฯ) อย่างชัดเจน
การระบุตัวตนของครอว์เลอร์
โดยทั่วไปแล้ว โปรแกรมรวบรวมข้อมูลเว็บ (Web crawler) จะระบุตัวตนให้กับเว็บเซิร์ฟเวอร์โดยใช้ ฟิลด์ User-agentใน คำขอ HTTPผู้ดูแลเว็บไซต์มักจะตรวจสอบ บันทึกของ เว็บเซิร์ฟเวอร์และใช้ฟิลด์ User-agent เพื่อตรวจสอบว่าโปรแกรมรวบรวมข้อมูลใดบ้างที่เข้าเยี่ยมชมเว็บเซิร์ฟเวอร์และบ่อยแค่ไหน ฟิลด์ User-agent อาจมีURLที่ผู้ดูแลเว็บไซต์สามารถค้นหาข้อมูลเพิ่มเติมเกี่ยวกับโปรแกรมรวบรวมข้อมูลได้ การตรวจสอบบันทึกของเว็บเซิร์ฟเวอร์เป็นงานที่ยุ่งยาก ดังนั้นผู้ดูแลระบบบางคนจึงใช้เครื่องมือเพื่อระบุ ติดตาม และตรวจสอบโปรแกรมรวบรวมข้อมูลเว็บสแปมบอทและโปรแกรมรวบรวมข้อมูลเว็บที่เป็นอันตรายอื่นๆ มักจะไม่ใส่ข้อมูลระบุตัวตนในฟิลด์ User-agent หรืออาจปลอมแปลงตัวตนเป็นเบราว์เซอร์หรือโปรแกรมรวบรวมข้อมูลที่รู้จักกันดีอื่นๆ
ผู้ดูแลเว็บไซต์มักต้องการให้โปรแกรมรวบรวมข้อมูลเว็บ (web crawler) ระบุตัวตน เพื่อที่จะได้ติดต่อเจ้าของเว็บไซต์ได้หากจำเป็น ในบางกรณี โปรแกรมรวบรวมข้อมูลอาจติดกับดัก โดยไม่ตั้งใจ หรืออาจส่งคำขอไปยังเซิร์ฟเวอร์เว็บมากเกินไปจนเจ้าของเว็บไซต์ต้องหยุดการทำงานของโปรแกรมรวบรวมข้อมูล การระบุตัวตนยังเป็นประโยชน์สำหรับผู้ดูแลระบบที่ต้องการทราบว่าเมื่อใดที่หน้าเว็บของตนจะได้รับการจัดทำดัชนีโดยเครื่องมือค้นหา เฉพาะ เจาะจง
การท่องเว็บลึก
เว็บเพจจำนวนมหาศาลอยู่ในเว็บลึกหรือเว็บที่มองไม่เห็น[ 46 ]โดยทั่วไปแล้ว หน้าเว็บเหล่านี้จะเข้าถึงได้โดยการส่งคำค้นหาไปยังฐานข้อมูลเท่านั้น และโปรแกรมรวบรวมข้อมูลทั่วไปจะไม่สามารถค้นหาหน้าเว็บเหล่านี้ได้หากไม่มีลิงก์ที่ชี้ไปยังหน้าเว็บเหล่านั้น โปรโตคอล Sitemaps ของ Google และmod oai [ 47 ]มีจุดประสงค์เพื่อให้สามารถค้นพบทรัพยากร เว็บลึก เหล่านี้ได้
การรวบรวมข้อมูลเว็บเชิงลึกยังเพิ่มจำนวนลิงก์เว็บที่จะถูกรวบรวมอีกด้วย โปรแกรมรวบรวมข้อมูลบางตัวจะดึง<a href="URL">ข้อมูลเฉพาะ URL บางส่วนเท่านั้น ในบางกรณี เช่นGooglebotการรวบรวมข้อมูลเว็บจะทำกับข้อความทั้งหมดที่อยู่ในเนื้อหาไฮเปอร์เท็กซ์ แท็ก หรือข้อความ
แนวทางเชิงกลยุทธ์อาจถูกนำมาใช้เพื่อกำหนดเป้าหมายเนื้อหาเว็บลึก ด้วยเทคนิคที่เรียกว่าscreen scrapingซอฟต์แวร์เฉพาะทางอาจได้รับการปรับแต่งเพื่อสอบถามแบบฟอร์มเว็บที่กำหนดโดยอัตโนมัติและซ้ำ ๆ โดยมีจุดประสงค์เพื่อรวบรวมข้อมูลที่ได้ ซอฟต์แวร์ดังกล่าวสามารถใช้เพื่อครอบคลุมแบบฟอร์มเว็บหลายแบบในหลายเว็บไซต์ ข้อมูลที่ดึงมาจากผลลัพธ์ของการส่งแบบฟอร์มเว็บหนึ่งสามารถนำไปใช้เป็นอินพุตสำหรับแบบฟอร์มเว็บอื่นได้ จึงสร้างความต่อเนื่องในเว็บลึกในแบบที่ไม่สามารถทำได้ด้วยโปรแกรมรวบรวมข้อมูลเว็บแบบดั้งเดิม[ 48 ]
หน้าเว็บที่สร้างด้วยAJAXเป็นหนึ่งในหน้าเว็บที่ก่อให้เกิดปัญหาแก่โปรแกรมรวบรวมข้อมูลเว็บGoogleได้เสนอรูปแบบการเรียกใช้ AJAX ที่บอทของพวกเขาสามารถจดจำและจัดทำดัชนีได้[ 49 ]
โปรแกรมรวบรวมข้อมูลแบบภาพเทียบกับแบบโปรแกรม
มีผลิตภัณฑ์ "โปรแกรมดึงข้อมูล/รวบรวมข้อมูลเว็บแบบภาพ" จำนวนมากบนเว็บ ซึ่งจะดึงข้อมูลจากหน้าเว็บและจัดโครงสร้างข้อมูลเป็นคอลัมน์และแถวตามความต้องการของผู้ใช้ ความแตกต่างหลักอย่างหนึ่งระหว่างโปรแกรมดึงข้อมูลแบบคลาสสิกและแบบภาพคือระดับความสามารถในการเขียนโปรแกรมที่จำเป็นในการตั้งค่าโปรแกรมดึงข้อมูล โปรแกรมดึงข้อมูลแบบภาพรุ่นใหม่ล่าสุดได้ลดทักษะการเขียนโปรแกรมส่วนใหญ่ที่จำเป็นในการเขียนโปรแกรมและเริ่มต้นการดึงข้อมูลจากเว็บลงไปแล้ว
วิธีการดึง/รวบรวมข้อมูลด้วยภาพนั้นอาศัยผู้ใช้ในการ "สอน" เทคโนโลยีการรวบรวมข้อมูล ซึ่งจะติดตามรูปแบบในแหล่งข้อมูลกึ่งโครงสร้าง วิธีการหลักในการสอนการรวบรวมข้อมูลด้วยภาพคือการไฮไลต์ข้อมูลในเบราว์เซอร์และฝึกคอลัมน์และแถว แม้ว่าเทคโนโลยีนี้จะไม่ใช่เรื่องใหม่ ตัวอย่างเช่น มันเป็นพื้นฐานของ Needlebase ซึ่ง Google ได้ซื้อไป (เป็นส่วนหนึ่งของการเข้าซื้อกิจการ ITA Labs ที่ใหญ่กว่า[ 50 ] ) แต่ก็ยังมีการเติบโตและการลงทุนอย่างต่อเนื่องในด้านนี้จากนักลงทุนและผู้ใช้ปลายทาง
รายชื่อเว็บครอว์เลอร์
ต่อไปนี้คือรายชื่อสถาปัตยกรรมของโปรแกรมรวบรวมข้อมูล (crawler) ที่เผยแพร่แล้ว สำหรับโปรแกรมรวบรวมข้อมูลทั่วไป (ไม่รวมโปรแกรมรวบรวมข้อมูลเฉพาะทาง) พร้อมคำอธิบายโดยย่อ ซึ่งรวมถึงชื่อที่ใช้เรียกส่วนประกอบต่างๆ และคุณสมบัติเด่น:
โปรแกรมรวบรวมข้อมูลเว็บในอดีต
- WolfBotเป็นหุ่นยนต์สำรวจแบบมัลติเธรดขนาดใหญ่ที่สร้างขึ้นในปี 2001 โดย Mani Singh ผู้สำเร็จการศึกษาด้านวิศวกรรมโยธาจากมหาวิทยาลัยแคลิฟอร์เนียที่เดวิส
- World Wide Web Wormเป็นโปรแกรมรวบรวมข้อมูลที่ใช้สร้างดัชนีอย่างง่ายของชื่อเอกสารและ URL ดัชนีนี้สามารถค้นหาได้โดยใช้คำสั่งgrepUnix
- Yahoo! Slurp เดิมทีเป็นชื่อของ โปรแกรมรวบรวมข้อมูลบนเว็บ ของ Yahoo!จนกระทั่ง Yahoo! ทำสัญญากับMicrosoftเพื่อใช้Bingbotแทน
โปรแกรมรวบรวมข้อมูลเว็บภายในองค์กร
- Applebot คือ เว็บครอว์เลอร์ของ AppleรองรับSiriและผลิตภัณฑ์อื่นๆ[ 51 ]
- Bingbotคือชื่อของ โปรแกรมรวบรวมข้อมูลเว็บ Bing ของ Microsoft ซึ่งเข้ามาแทนที่Msnbot
- Baiduspider คือโปรแกรมรวบรวมข้อมูลเว็บของBaidu
- DuckDuckBot คือโปรแกรมรวบรวมข้อมูลเว็บของDuckDuckGo
- Googlebotได้รับการอธิบายอย่างละเอียดในระดับหนึ่ง แต่เอกสารอ้างอิงนั้นกล่าวถึงเฉพาะสถาปัตยกรรมเวอร์ชันแรกๆ ซึ่งเขียนด้วยภาษา C++ และPythonเท่านั้น ตัวรวบรวมข้อมูลถูกรวมเข้ากับกระบวนการจัดทำดัชนี เนื่องจากมีการแยกวิเคราะห์ข้อความสำหรับการจัดทำดัชนีข้อความเต็มรูปแบบและการดึง URL มีเซิร์ฟเวอร์ URL ที่ส่งรายการ URL ที่จะถูกดึงโดยกระบวนการรวบรวมข้อมูลหลายๆ กระบวนการ ระหว่างการแยกวิเคราะห์ URL ที่พบจะถูกส่งไปยังเซิร์ฟเวอร์ URL ซึ่งจะตรวจสอบว่าเคยพบ URL นั้นมาก่อนหรือไม่ หากไม่เคยพบ URL นั้นจะถูกเพิ่มเข้าไปในคิวของเซิร์ฟเวอร์ URL
- WebCrawlerถูกใช้เพื่อสร้างดัชนีข้อความเต็มรูปแบบสาธารณะชุดแรกของส่วนย่อยของเว็บ โดยใช้lib-WWWในการดาวน์โหลดหน้าเว็บ และโปรแกรมอีกตัวในการวิเคราะห์และจัดเรียง URL สำหรับการสำรวจกราฟเว็บแบบกว้าง (breadth-first exploration) นอกจากนี้ยังรวมถึงโปรแกรมรวบรวมข้อมูลแบบเรียลไทม์ที่ติดตามลิงก์โดยพิจารณาจากความคล้ายคลึงกันของข้อความแองเคอร์กับคำค้นหาที่ให้มา
- WebFountainเป็นโปรแกรมรวบรวมข้อมูลแบบกระจายและโมดูลาร์ คล้ายกับ Mercator แต่เขียนด้วยภาษา C++
- Xenonเป็นเว็บครอว์เลอร์ที่หน่วยงานภาษีของรัฐบาลใช้ในการตรวจจับการฉ้อโกง[ 52 ] [ 53 ]
โปรแกรมรวบรวมข้อมูลเว็บเชิงพาณิชย์
โปรแกรมรวบรวมข้อมูลเว็บต่อไปนี้มีให้บริการ โดยมีค่าใช้จ่าย:
- Diffbot – โปรแกรมรวบรวมข้อมูลเว็บทั่วไปที่ทำงานโดยอัตโนมัติ มีให้ใช้งานในรูปแบบAPI
- SortSite – โปรแกรมรวบรวมข้อมูลสำหรับวิเคราะห์เว็บไซต์ มีให้ใช้งานสำหรับWindowsและMac OS
- Swiftbot – โปรแกรมรวบรวมข้อมูลเว็บของSwiftype ซึ่งให้บริการในรูป แบบซอฟต์แวร์เป็นบริการ (SaaS)
- Aleph Search – โปรแกรมรวบรวมข้อมูลเว็บที่ช่วยให้สามารถรวบรวมข้อมูลจำนวนมหาศาลได้อย่างมีประสิทธิภาพสูง
โปรแกรมรวบรวมข้อมูลแบบโอเพนซอร์ส
- Apache Nutchเป็นเว็บครอว์เลอร์ที่มีความยืดหยุ่นและปรับขนาดได้สูง เขียนด้วยภาษา Java และเผยแพร่ภายใต้Apache License โดยใช้ Apache Hadoopเป็นพื้นฐานและสามารถใช้งานร่วมกับApache SolrหรือElasticsearchได้
- Grubเป็นเว็บครอว์เลอร์แบบกระจายศูนย์โอเพนซอร์สที่Wikia Searchใช้
- Heritrixคือ โปรแกรมรวบรวมข้อมูลคุณภาพสูงสำหรับการเก็บรักษาข้อมูลของ Internet Archiveซึ่งออกแบบมาเพื่อเก็บรักษาภาพรวมของเว็บไซต์ส่วนใหญ่บนเว็บเป็นระยะๆ โปรแกรมนี้เขียนด้วยภาษาJava
- ht://Digมีเว็บครอว์เลอร์รวมอยู่ในระบบจัดทำดัชนีของมัน
- HTTrackใช้โปรแกรมรวบรวมข้อมูลเว็บเพื่อสร้างสำเนาของเว็บไซต์สำหรับการดูแบบออฟไลน์ โปรแกรมนี้เขียนด้วยภาษาซีและเผยแพร่ภายใต้ใบอนุญาต GPL
- Norconex Web Crawler เป็นโปรแกรมรวบรวมข้อมูลเว็บที่สามารถปรับแต่งได้อย่างมาก เขียนด้วยภาษา Javaและเผยแพร่ภายใต้Apache Licenseสามารถใช้งานร่วมกับแหล่งเก็บข้อมูลหลายแห่ง เช่นApache Solr , Elasticsearch , Microsoft Azure Cognitive Search , Amazon CloudSearchและอื่นๆ
- mnoGoSearchเป็นโปรแกรมรวบรวมข้อมูล จัดทำดัชนี และเป็นเครื่องมือค้นหาที่เขียนด้วยภาษาซีและได้รับอนุญาตภายใต้ GPL ซึ่งเปิดใช้งานตั้งแต่ปี 2000 ถึง 2022
- Open Search Serverเป็นซอฟต์แวร์เครื่องมือค้นหาและรวบรวมข้อมูลบนเว็บที่เผยแพร่ภายใต้ใบอนุญาต GPL
- Scrapyคือเฟรมเวิร์กโอเพนซอร์สสำหรับรวบรวมข้อมูลจากเว็บไซต์ เขียนด้วยภาษา Python (ได้รับอนุญาตภายใต้BSD )
- Seeksคือเครื่องมือค้นหาแบบกระจายศูนย์ฟรี (ได้รับอนุญาตภายใต้AGPL )
- StormCrawlerคือชุดทรัพยากรสำหรับการสร้างเว็บครอว์เลอร์ที่มีความหน่วงต่ำและปรับขนาดได้บนApache Storm (ลิขสิทธิ์ Apache)
- tkWWW Robotคือโปรแกรมรวบรวมข้อมูลที่ใช้ เว็บเบราว์เซอร์ tkWWW เป็นพื้นฐาน (ได้รับอนุญาตภายใต้ GPL)
- GNU Wgetเป็น โปรแกรมรวบรวมข้อมูลแบบใช้ คำสั่งบรรทัดเขียนด้วยภาษา Cและเผยแพร่ภายใต้ใบอนุญาต GPLโดยทั่วไปแล้วจะใช้ในการคัดลอกเว็บไซต์และไฟล์ FTP
- YaCyคือเครื่องมือค้นหาแบบกระจายศูนย์ฟรี ที่สร้างขึ้นบนหลักการของเครือข่ายแบบ Peer-to-Peer (ได้รับอนุญาตภายใต้ GPL)
ดูเพิ่มเติม
- การจัดทำดัชนีอัตโนมัติ
- คลานธรรมดา
- Googlebot (สไปเดอร์ของ Google), โปรแกรมรวบรวมข้อมูล Gnutella
- การเก็บรักษาเว็บ
- เว็บกราฟ
- ซอฟต์แวร์จำลองเว็บไซต์
- การดึงข้อมูลจากเครื่องมือค้นหา
- การดึงข้อมูลจากเว็บไซต์
อ่านเพิ่มเติม
- โช, จองฮู, "โครงการรวบรวมข้อมูลเว็บ" เก็บถาวรเมื่อวันที่ 7 กรกฎาคม 2013 ที่Wayback Machine , ภาควิชาวิทยาการคอมพิวเตอร์ มหาวิทยาลัย UCLA
- ประวัติความเป็นมาของเครื่องมือค้นหาจาก สำนักพิมพ์ ไวเลย์
- WIVETเป็นโครงการวัดประสิทธิภาพของOWASPซึ่งมีเป้าหมายเพื่อวัดว่าเว็บครอว์เลอร์สามารถระบุไฮเปอร์ลิงก์ทั้งหมดในเว็บไซต์เป้าหมายได้หรือไม่
- เชสตาคอฟ, เดนิส, "ความท้าทายในปัจจุบันในการรวบรวมข้อมูลเว็บ"และ"การรวบรวมข้อมูลเว็บอัจฉริยะ"สไลด์สำหรับการสอนในงาน ICWE'13 และ WI-IAT'13
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ เว็บครอว์เลอร์
เว็บครอว์เลอร์บางครั้งเรียกว่าสไปเดอร์หรือสไปเดอร์บอทและมักย่อเป็นครอว์เลอร์คือบอทอินเทอร์เน็ตที่เรียกดูเวิลด์ไวด์เว็บ อย่างเป็นระบบ...
การตั้งชื่อ
เว็บครอว์เลอร์ยังเป็นที่รู้จักในชื่อ ส ไปเดอร์ [ 5 ] แอ น ท์ ตัว จัดทำดัชนีอัตโนมัติ [ 6 ] หรือ (ในบริบทของ ซอฟต์แวร์ FOAF ) เว็บสคัต เตอร์ [ 7 ]
ภาพรวม
เว็บครอว์เลอร์เริ่มต้นด้วยรายการ URL ที่จะเยี่ยมชม URL แรกเหล่านั้นเรียกว่า ซีด (seeds ) เมื่อครอว์เลอร์เยี่ยมชม URL เหล่านี้ โดยการสื่อสารกับ เว็บเซิร์ฟเวอร์ ที่ตอบสนองต่อ URL เหล่านั้น มันจะระบุ ไฮเปอร์ลิงก์ ทั้งหมด ในหน้าเว็บที่ดึงมาได้ และเพิ่มลงในรายการ...
นโยบายการรวบรวมข้อมูล
พฤติกรรมของเว็บครอว์เลอร์เป็นผลมาจากการรวมกันของนโยบายต่างๆ: [ 10 ]