อ่าน 11 นาที
อักขระชุดอักขระสากล
สมาคมยูนิโค้ด ( Unicode Consortium) และ คณะทำงานร่วม ISO/IEC JTC 1/SC 2 / WG 2 ร่วมมือกันในการจัดทำรายการอักขระ ในชุดอักขระรหัสสากล (Universal Coded Character Set หรือ UCS)...
อักขระชุดอักขระสากล

สมาคมยูนิโค้ด ( Unicode Consortium)และ คณะทำงานร่วม ISO/IEC JTC 1/SC 2 / WG 2 ร่วมมือกันในการจัดทำรายการอักขระในชุดอักขระรหัสสากล (Universal Coded Character Set หรือ UCS) ชุดอักขระรหัสสากล หรือที่เรียกกันทั่วไปว่าชุดอักขระสากล ( ย่อว่า UCS ชื่อทางการ: ISO / IEC 10646) เป็นมาตรฐานสากลที่ใช้ในการแปลงอักขระซึ่งเป็นสัญลักษณ์ที่ใช้ในภาษาธรรมชาติคณิตศาสตร์ดนตรีและโดเมนอื่นๆ ให้เป็น ค่า ข้อมูลที่เครื่องอ่านได้ ที่ไม่ซ้ำกัน ด้วยการสร้างแผนที่การแปลงนี้ UCS ช่วยให้ผู้ผลิตซอฟต์แวร์คอมพิวเตอร์สามารถทำงานร่วมกันและส่งต่อ— แลกเปลี่ยน — สตริงข้อความที่เข้ารหัส UCSระหว่างกันได้ เนื่องจากเป็น แผนที่ สากลจึงสามารถใช้เพื่อแสดงหลายภาษาพร้อมกันได้ ซึ่งจะช่วยหลีกเลี่ยงความสับสนจากการใช้การเข้ารหัสอักขระ แบบเก่าหลายแบบ ซึ่งอาจส่งผลให้ลำดับของรหัสเดียวกันมีการตีความหลายแบบขึ้นอยู่กับการเข้ารหัสอักขระที่ใช้ ส่งผลให้เกิดความผิดเพี้ยนของตัวอักษร(mojibake)หากเลือกผิด
UCS มีศักยภาพในการรองรับอักขระได้มากกว่า 1 ล้านตัว อักขระ UCS แต่ละตัวจะถูกแทนด้วยจุดรหัส (code point ) ซึ่งเป็นจำนวนเต็มระหว่าง 0 ถึง 1,114,111 (1,114,112 = 2²⁰ + 2¹⁶ หรือ17 × 2¹⁶ = 0 x 110000 จุดรหัส ) ใช้แทนอักขระแต่ละตัวภายในตรรกะของซอฟต์แวร์ประมวลผลข้อความ ณ Unicode 17.0 ซึ่งเผยแพร่ในเดือนกันยายน 2025 จุดรหัสเหล่านี้ 303,808 จุด (27%) ถูกจัดสรรแล้ว 159,866 จุด (14%) ถูกกำหนดให้เป็นอักขระ 137,468 จุด (12%) ถูกสงวนไว้สำหรับการใช้งานส่วนตัว 2,048 จุดใช้เพื่อเปิดใช้งานกลไกของอักขระทดแทน (surrogates ) และ 66 จุดถูกกำหนดให้เป็น อักขระ ที่ไม่ใช่อักขระเหลืออีก 810,304 จุด (73%) ที่ยังไม่ได้จัดสรร จำนวนอักขระที่เข้ารหัสประกอบด้วยดังนี้:
- อักขระกราฟิกจำนวน 159,629 ตัว (บางตัวไม่มีสัญลักษณ์ ที่มองเห็นได้ แต่ก็ยังนับรวมเป็นอักขระกราฟิก)
- อักขระพิเศษ 237 ตัว สำหรับการควบคุมและการจัดรูปแบบ
ISOรักษาการแมปพื้นฐานของอักขระจากชื่ออักขระไปยังรหัสจุด บ่อยครั้งที่คำว่าอักขระและรหัสจุดจะถูกใช้แทนกันได้ อย่างไรก็ตาม เมื่อมีการแยกความแตกต่างรหัสจุดจะหมายถึงจำนวนเต็มของอักขระ ซึ่งอาจนึกภาพได้ว่าเป็นที่อยู่ของอักขระนั้น ในขณะเดียวกันอักขระใน ISO/IEC 10646 ประกอบด้วยรหัสจุดและชื่อของอักขระนั้น ยูนิโค้ดเพิ่มคุณสมบัติที่ มีประโยชน์อื่นๆ อีกมากมาย ให้กับชุดอักขระ เช่นบล็อกหมวด หมู่สคริปต์และทิศทาง
นอกจาก UCS แล้วมาตรฐาน Unicode เสริม (ซึ่งไม่ใช่โครงการร่วมกับ ISO แต่เป็นเอกสารเผยแพร่ของ Unicode Consortium) ยังให้รายละเอียดการใช้งานอื่นๆ อีก เช่น:
- การจับคู่ระหว่าง UCS และชุดอักขระอื่นๆ
- การเรียงลำดับ ตัวอักษรและสตริงตัวอักษร ที่แตกต่างกันสำหรับภาษาต่างๆ
- อัลกอริทึมสำหรับการจัดวางข้อความแบบสองทิศทาง (" อัลกอริทึม BiDi ") ซึ่งข้อความในบรรทัดเดียวกันสามารถสลับระหว่างการเขียนจากซ้ายไปขวา ("LTR") และจากขวาไปซ้าย ("RTL") ได้
- อัลกอริทึมการพับเคส
ผู้ใช้งานซอฟต์แวร์คอมพิวเตอร์ป้อนอักขระเหล่านี้ลงในโปรแกรมผ่านวิธีการป้อนข้อมูล ต่างๆ เช่นแป้นพิมพ์ จริง หรือแถบอักขระเสมือนจริง
UCS สามารถแบ่งได้หลายวิธี เช่น ตามระนาบบล็อก ประเภทอักขระ หรือคุณสมบัติของอักขระ[ 1 ]
ภาพรวมข้อมูลอ้างอิงตัวละคร
การอ้างอิงอักขระตัวเลข ใน HTMLหรือXML จะอ้างอิงถึงอักขระโดยใช้รหัสจุดของชุดอักขระสากล /ยูนิโค้ด และใช้รูปแบบดังนี้
&#nnnn;
หรือ
&#xฮิฮิ;
โดยที่nnnnคือรหัสจุดใน รูปแบบ เลขฐานสิบและhhhhคือรหัสจุดในรูปแบบเลขฐานสิบหก ตัว xต้องเป็นตัวพิมพ์เล็กในเอกสาร XML nnnnหรือhhhhสามารถมีจำนวนหลักเท่าใดก็ได้และอาจมีเลขศูนย์นำหน้าได้hhhhอาจผสมตัวพิมพ์ใหญ่และตัวพิมพ์เล็กได้ แต่โดยทั่วไปมักใช้ตัวพิมพ์ใหญ่
ในทางตรงกันข้ามการอ้างอิงเอนทิตีอักขระจะอ้างถึงอักขระโดยใช้ชื่อของเอนทิตีที่มีอักขระที่ต้องการเป็นข้อความทดแทนเอนทิตีนั้นจะต้องถูกกำหนดไว้ล่วงหน้า (สร้างไว้ในภาษามาร์กอัป) หรือประกาศอย่างชัดเจนในคำจำกัดความประเภทเอกสาร (DTD) รูปแบบจะเหมือนกับการอ้างอิงเอนทิตีทั่วไป:
&ชื่อ;
โดยที่nameคือชื่อของเอนทิตีซึ่งต้องตรงตามตัวพิมพ์ใหญ่เล็ก และต้องมีเครื่องหมายเซมิโคลอนกำกับไว้ด้วย
เครื่องบิน
Unicode และ ISO แบ่งชุดรหัสอักขระออกเป็น 17 ระนาบ แต่ละระนาบสามารถบรรจุอักขระที่แตกต่างกันได้ 65,536 ตัว หรือรวมทั้งหมด 1,114,112 ตัว ณ ปี 2025 (Unicode 17.0) ISO และ Unicode Consortium ได้จัดสรรอักขระและบล็อกในเพียง 7 ระนาบจากทั้งหมด 17 ระนาบเท่านั้น ส่วนที่เหลือยังคงว่างเปล่าและสงวนไว้สำหรับการใช้งานในอนาคต
ปัจจุบันอักขระส่วนใหญ่ถูกกำหนดให้อยู่ในระนาบแรก: ระนาบหลายภาษาพื้นฐาน (Basic Multilingual Plane ) เพื่อช่วยให้การเปลี่ยนผ่านสำหรับซอฟต์แวร์รุ่นเก่าเป็นไปอย่างราบรื่น เนื่องจากระนาบหลายภาษาพื้นฐานสามารถระบุได้ด้วยไบต์เพียงสองไบต์ เท่านั้น อักขระที่อยู่นอกระนาบแรกมักมีการใช้งานเฉพาะทางหรือหายากมาก
แต่ละระนาบจะสอดคล้องกับค่าของตัวเลขฐานสิบหก หนึ่งหรือสอง หลัก (0-9, A-F) ที่อยู่หน้าเลขหนึ่งสี่หลักสุดท้าย: ดังนั้น U+24321 อยู่ในระนาบที่ 2, U+4321 อยู่ในระนาบที่ 0 (อ่านโดยปริยายว่า U+04321) และ U+10A200 จะอยู่ในระนาบที่ 16 (ฐานสิบหก 10 = ฐานสิบ 16) ภายในระนาบเดียวกัน ช่วงของรหัสจุดคือฐานสิบหก 0000-FFFF ทำให้ได้รหัสจุดสูงสุด 65536 จุด ระนาบต่างๆ จะจำกัดรหัสจุดให้อยู่ในส่วนย่อยของช่วงนั้น
บล็อก
Unicode เพิ่มคุณสมบัติบล็อกให้กับ UCS ซึ่งแบ่งแต่ละระนาบออกเป็นบล็อกย่อยๆ แต่ละบล็อกเป็นการจัดกลุ่มอักขระตามการใช้งาน เช่น "ตัวดำเนินการทางคณิตศาสตร์" หรือ "อักขระอักษรฮิบรู" เมื่อกำหนดอักขระให้กับรหัสจุดที่ยังไม่ได้กำหนดไว้ก่อนหน้านี้ โดยทั่วไปแล้ว Consortium จะจัดสรรบล็อกทั้งหมดของอักขระที่คล้ายกัน ตัวอย่างเช่น อักขระทั้งหมดที่อยู่ในอักษรเดียวกันหรือสัญลักษณ์ที่มีจุดประสงค์คล้ายกันทั้งหมดจะถูกกำหนดให้กับบล็อกเดียวกัน บล็อกอาจยังคงมีรหัสจุดที่ยังไม่ได้กำหนดหรือสงวนไว้เมื่อ Consortium คาดว่าบล็อกนั้นต้องการการกำหนดเพิ่มเติม
รหัสอักขระ 256 ตัวแรกใน UCS ตรงกับรหัสอักขระของISO 8859-1 ซึ่ง เป็นการเข้ารหัสอักขระ 8 บิตที่ได้รับความนิยมมากที่สุดในโลกตะวันตกดังนั้น อักขระ 128 ตัวแรกจึงเหมือนกับASCIIแม้ว่า Unicode จะเรียกสิ่งเหล่านี้ว่าบล็อกอักษรละติน แต่บล็อกทั้งสองนี้มีอักขระจำนวนมากที่ใช้ประโยชน์ได้ทั่วไปนอกเหนือจากอักษรละติน โดยทั่วไปแล้ว อักขระทั้งหมดในบล็อกที่กำหนดไม่จำเป็นต้องเป็นอักษรเดียวกัน และอักษรหนึ่งๆ อาจปรากฏอยู่ในหลายบล็อกที่แตกต่างกัน
หมวดหมู่
Unicode กำหนด หมวดหมู่ทั่วไป และหมวดหมู่ย่อย ให้กับอักขระ UCS ทุกตัวหมวดหมู่ทั่วไปได้แก่ ตัวอักษร เครื่องหมาย ตัวเลข เครื่องหมายวรรคตอน สัญลักษณ์ หรืออักขระควบคุม (กล่าวคือ อักขระจัดรูปแบบหรืออักขระที่ไม่ใช่กราฟิก)
ประเภทต่างๆ ได้แก่:
- อักษรสมัยใหม่ อักษรประวัติศาสตร์ และอักษรโบราณณ ปี 2025 (Unicode 17.0) UCS ระบุอักษร 172 แบบที่ใช้หรือเคยใช้ทั่วโลก และยังมีอีกมากที่อยู่ในขั้นตอนการอนุมัติต่างๆ เพื่อรวมเข้าใน UCS ในอนาคต[ 2 ]
- อักษรเสียงสากล (International Phonetic Alphabet ) ระบบ UCS จัดสรรพื้นที่หลายส่วน (มากกว่า 300 ตัวอักษร) สำหรับตัวอักษรของอักษรเสียงสากล
- การรวมเครื่องหมายกำกับเสียงความก้าวหน้าสำคัญที่ยูนิโค้ดคิดค้นขึ้นในการออกแบบ UCS และอัลกอริธึมที่เกี่ยวข้องสำหรับการจัดการข้อความ คือ การนำเครื่องหมายกำกับเสียงแบบรวมมาใช้ โดยการให้เครื่องหมายเน้นเสียงที่สามารถรวมกับตัวอักษรใดก็ได้ ยูนิโค้ดและ UCS จึงลดจำนวนอักขระที่จำเป็นลงอย่างมาก แม้ว่า UCS จะมีอักขระที่ประกอบขึ้นแล้ว แต่ส่วนใหญ่รวมไว้เพื่ออำนวยความสะดวกในการสนับสนุนระบบประมวลผลข้อความที่ไม่ใช่ยูนิโค้ดภายใน UCS
- เครื่องหมายวรรคตอนนอกจากการรวมเครื่องหมายกำกับเสียงแล้ว UCS ยังพยายามรวมเครื่องหมายวรรคตอนให้เป็นมาตรฐานเดียวกันในทุกอักษร อย่างไรก็ตาม อักษรหลายๆ อักษรก็มีเครื่องหมายวรรคตอนเช่นกัน แต่เครื่องหมายเหล่านั้นไม่มีความหมายที่คล้ายคลึงกันในอักษรอื่นๆ
- สัญลักษณ์ต่างๆ มากมายถูกรวมอยู่ในระบบพิกัดสากล (UCS) ซึ่งทำให้สัญลักษณ์แต่ละตัวมีรหัสหรืออักขระเฉพาะของตนเอง แทนที่จะต้องเปลี่ยนแบบอักษรเพื่อให้ได้สัญลักษณ์ที่แตกต่างกัน
- สกุลเงิน .
- สัญลักษณ์ คล้ายตัวอักษรสัญลักษณ์เหล่านี้ปรากฏเป็นการรวมกันของตัวอักษรละตินทั่วไปหลายตัว เช่น℅ยูนิโค้ดกำหนดให้สัญลักษณ์คล้ายตัวอักษรหลายตัวเป็นอักขระที่เข้ากันได้ โดยปกติเนื่องจากสามารถอยู่ในข้อความธรรมดาได้โดยการแทนที่สัญลักษณ์ด้วยลำดับตัวอักษรที่ประกอบขึ้น เช่น การแทนที่สัญลักษณ์℅ด้วยลำดับตัวอักษรที่ประกอบขึ้นc/ o
- รูปแบบตัวเลขรูปแบบตัวเลขส่วนใหญ่ประกอบด้วยเศษส่วนสำเร็จรูปและตัวเลขโรมัน เช่นเดียวกับด้านอื่นๆ ของการสร้างลำดับอักขระ วิธีการของยูนิโค้ดนั้นเน้นความยืดหยุ่นในการสร้างเศษส่วนโดยการรวมอักขระเข้าด้วยกัน ในกรณีนี้ การสร้างเศษส่วนจะทำโดยการรวมตัวเลขกับอักขระเศษส่วนทับ (U+2044) ตัวอย่างเช่น ความยืดหยุ่นที่วิธีการนี้มอบให้คือ มีอักขระเศษส่วนสำเร็จรูป 19 ตัวรวมอยู่ใน UCS อย่างไรก็ตาม มีเศษส่วนที่เป็นไปได้มากมายนับไม่ถ้วน การใช้ตัวอักขระประกอบช่วยจัดการกับเศษส่วนที่มากมายนับไม่ถ้วนได้ด้วยอักขระ 11 ตัว (0-9 และอักขระเศษส่วนทับ) ไม่มีชุดอักขระใดที่จะสามารถรวมจุดรหัสสำหรับเศษส่วนสำเร็จรูปทุกตัวได้ ในอุดมคติแล้ว ระบบข้อความควรแสดงสัญลักษณ์เดียวกันสำหรับเศษส่วน ไม่ว่าจะเป็นเศษส่วนสำเร็จรูป (เช่น⅓ ) หรือลำดับอักขระประกอบ (เช่น1⁄3 ) อย่างไรก็ตาม โดยทั่วไปแล้วเว็บเบราว์เซอร์ยังไม่ซับซ้อนมากนักในเรื่องยูนิโค้ดและการจัดการข้อความ การทำเช่นนี้จะช่วยให้เศษส่วนที่ประกอบไว้ล่วงหน้าและเศษส่วนลำดับการรวมปรากฏเข้ากันได้เมื่อวางอยู่ข้างกัน
- ลูกศร
- คณิตศาสตร์
- รูปทรงเรขาคณิต
- ระบบคอมพิวเตอร์แบบดั้งเดิม
- ภาพแสดงสัญลักษณ์ควบคุมต่างๆ ในรูปแบบกราฟิก
- ภาพวาดกล่อง
- ส่วนประกอบบล็อก
- รูปแบบอักษรเบรลล์
- การรู้จำอักขระด้วยแสง (Optical Character Recognition )
- ด้านเทคนิค
- ดิงแบตส์
- สัญลักษณ์เบ็ดเตล็ด
- อีโมติคอน
- สัญลักษณ์และภาพสัญลักษณ์
- สัญลักษณ์ทางเล่นแร่แปรธาตุ
- อุปกรณ์สำหรับเล่นเกม (หมากรุก หมากฮอส โกะ ลูกเต๋า โดมิโน มาจง ไพ่ และอื่นๆ อีกมากมาย)
- สัญลักษณ์หมากรุก
- ไท่ซวนจิง .
- สัญลักษณ์หกเหลี่ยมของอี้จิง
- CJKอุทิศให้กับการรวบรวมและสนับสนุนอักษรภาพและตัวอักษรอื่นๆ เพื่อใช้ในภาษาต่างๆ ของจีน ญี่ปุ่น เกาหลี (CJK) ไต้หวัน เวียดนาม และไทย
- รากที่สองและเส้นแบ่ง
- อักษรภาพส่วนใหญ่ของ UCS นั้นประกอบด้วยอักษรภาพที่ใช้ในภาษาของเอเชียตะวันออก แม้ว่าการแสดงอักษรภาพเหล่านี้จะแตกต่างกันไปในแต่ละภาษาที่ใช้ แต่ UCS ได้รวมอักษรฮั่น เหล่านี้เข้าด้วยกัน ในสิ่งที่ Unicode เรียกว่า Unihan (ย่อมาจาก Unified Han) ด้วย Unihan ซอฟต์แวร์การจัดวางข้อความจะต้องทำงานร่วมกับแบบอักษรที่มีอยู่และอักษร Unicode เหล่านี้เพื่อสร้างสัญลักษณ์ที่เหมาะสมสำหรับแต่ละภาษา ถึงแม้จะรวมอักษรเหล่านี้เข้าด้วยกันแล้ว แต่ UCS ก็ยังคงมีอักษรภาพ Unihan มากกว่า 101,000 ตัว
- สัญลักษณ์ทางดนตรี
- ระบบการเขียนย่อแบบดูพลิยาน
- บริการเขียนป้าย Sutton
- อักขระเพื่อความเข้ากันได้บล็อกหลายบล็อกใน UCS นั้นอุทิศให้กับอักขระเพื่อความเข้ากันได้เกือบทั้งหมด อักขระเพื่อความเข้ากันได้คืออักขระที่รวมไว้เพื่อรองรับระบบการจัดการข้อความแบบเก่าที่ไม่แยกความแตกต่างระหว่างอักขระและสัญลักษณ์ (glyph) ในแบบที่ Unicode ทำ ตัวอย่างเช่น ตัวอักษรอาหรับหลายตัวจะถูกแทนด้วยสัญลักษณ์ที่แตกต่างกันเมื่อตัวอักษรนั้นปรากฏที่ท้ายคำและเมื่อตัวอักษรนั้นปรากฏที่ต้นคำ แนวทางของ Unicode ต้องการให้ตัวอักษรเหล่านี้ถูกแมปไปยังอักขระเดียวกันเพื่อความสะดวกในการประมวลผลและจัดเก็บข้อความภายในเครื่อง เพื่อเสริมแนวทางนี้ ซอฟต์แวร์ข้อความต้องเลือกสัญลักษณ์ที่แตกต่างกันสำหรับการแสดงผลของอักขระตามบริบท มีอักขระมากกว่า 4,000 ตัวที่รวมไว้ด้วยเหตุผลด้านความเข้ากันได้ดังกล่าว
- ตัว ละครควบคุม
- รหัสแทน (Surrogates ) ระบบรหัสสากล (UCS) ประกอบด้วยจุดรหัส 2048 จุดในระนาบหลายภาษาพื้นฐาน (BMP) สำหรับคู่จุดรหัสแทน รหัสแทนเหล่านี้ช่วยให้สามารถระบุจุดรหัสใดๆ ในระนาบอีก 16 ระนาบได้โดยใช้จุดรหัสแทนสองจุด นี่เป็นวิธีการที่ง่ายและมีอยู่แล้วสำหรับการเข้ารหัส UCS 20.1 บิตภายในระบบเข้ารหัส 16 บิต เช่น UTF-16 ด้วยวิธีนี้ UTF-16 สามารถแทนอักขระใดๆ ภายใน BMP ด้วยคำ 16 บิตเพียงคำเดียว ส่วนอักขระที่อยู่นอก BMP จะถูกเข้ารหัสโดยใช้คำ 16 บิตสองคำ (รวม 4 ไบต์) โดยใช้คู่รหัสแทน
- การใช้งานส่วนตัวกลุ่มพันธมิตรได้จัดเตรียมบล็อกและระนาบสำหรับการใช้งานส่วนตัวหลายแบบ ซึ่งสามารถกำหนดอักขระให้กับชุมชนต่างๆ รวมถึงผู้จำหน่ายระบบปฏิบัติการและฟอนต์ได้
- อักขระที่ไม่ใช่อักขระกลุ่มพันธมิตรรับประกันว่าจุดรหัสบางจุดจะไม่ถูกกำหนดให้เป็นอักขระ และเรียกจุดรหัสเหล่านี้ว่าจุดรหัสที่ไม่ใช่อักขระ ซึ่งรวมถึงช่วง U+FDD0..U+FDEF และจุดรหัสสองจุดสุดท้ายของแต่ละระนาบ (ลงท้ายด้วยตัวเลขฐานสิบหก FFFE และ FFFF) [ 3 ]
อักขระพิเศษ
Unicode เข้ารหัสอักขระมากกว่าแสนตัว อักขระส่วนใหญ่เหล่านั้นแทนกราฟีมสำหรับการประมวลผลเป็นข้อความเชิงเส้น อย่างไรก็ตาม บางตัวก็ไม่ได้แทนกราฟีม หรือหากแทนกราฟีม ก็จำเป็นต้องได้รับการจัดการเป็นพิเศษ[ 4 ] [ 5 ]แตกต่างจากอักขระควบคุม ASCII และอักขระอื่นๆ ที่รวมไว้สำหรับความสามารถในการแปลงกลับแบบดั้งเดิม อักขระพิเศษเหล่านี้ทำให้ข้อความธรรมดามีความหมายที่สำคัญ
อักขระพิเศษบางตัวสามารถเปลี่ยนแปลงรูปแบบการจัดวางข้อความได้ เช่นอักขระเชื่อมข้อความที่มีความกว้างเป็นศูนย์ และอักขระไม่เชื่อมข้อความที่มีความกว้างเป็นศูนย์ในขณะที่อักขระพิเศษอื่นๆ ไม่ส่งผลต่อรูปแบบการจัดวางข้อความเลย แต่จะส่งผลต่อวิธีการเรียงลำดับ การจับคู่ หรือการประมวลผลข้อความอื่นๆ แทน อักขระพิเศษอื่นๆ เช่น อักขระที่มองไม่เห็นในทางคณิตศาสตร์โดยทั่วไปแล้วจะไม่มีผลต่อการแสดงผลข้อความ แม้ว่าซอฟต์แวร์จัดวางข้อความขั้นสูงอาจเลือกที่จะปรับระยะห่างรอบๆ อักขระเหล่านั้นอย่างละเอียดก็ตาม
Unicode ไม่ได้ระบุการแบ่งงานระหว่างซอฟต์แวร์ฟอนต์และซอฟต์แวร์จัดวางข้อความ (หรือ "เอนจิ้น") เมื่อแสดงผลข้อความ Unicode เนื่องจากรูปแบบฟอนต์ที่ซับซ้อนกว่า เช่นOpenTypeหรือApple Advanced Typographyอนุญาตให้มีการแทนที่และการจัดตำแหน่งของอักขระตามบริบท เอนจิ้นจัดวางข้อความแบบง่ายอาจอาศัยฟอนต์ทั้งหมดในการตัดสินใจเลือกและจัดวางอักขระ ในสถานการณ์เดียวกัน เอนจิ้นที่ซับซ้อนกว่าอาจรวมข้อมูลจากฟอนต์เข้ากับกฎของตนเองเพื่อให้ได้การแสดงผลที่ดีที่สุดตามที่ต้องการ เพื่อให้เป็นไปตามข้อแนะนำทั้งหมดของข้อกำหนด Unicode เอนจิ้นข้อความต้องพร้อมที่จะทำงานกับฟอนต์ทุกระดับความซับซ้อน เนื่องจากกฎการแทนที่และการจัดตำแหน่งตามบริบทไม่มีอยู่ในบางรูปแบบฟอนต์และเป็นทางเลือกในส่วนที่เหลือ เครื่องหมายทับเศษส่วนเป็นตัวอย่างหนึ่ง: ฟอนต์ที่ซับซ้อนอาจมีหรือไม่มีกฎการจัดตำแหน่งเมื่อมีอักขระเครื่องหมายทับเศษส่วนเพื่อสร้างเศษส่วน ในขณะที่ฟอนต์ในรูปแบบง่ายๆ ไม่สามารถทำได้
เครื่องหมายลำดับไบต์
เมื่อปรากฏที่ส่วนหัวของไฟล์ข้อความหรือสตรีม ข้อความU+FEFF ZERO WIDTH NO-BREAK SPACEจะบอกใบ้ถึงรูปแบบการเข้ารหัสและลำดับไบต์
หากไบต์แรกของสตรีมเป็น 0xFE และไบต์ที่สองเป็น 0xFF แสดงว่าข้อความในสตรีมนั้นไม่น่าจะถูกเข้ารหัสด้วยUTF-8เนื่องจากไบต์เหล่านั้นไม่ถูกต้องใน UTF-8 นอกจากนี้ยังไม่น่าจะเป็นUTF-16ใน ลำดับไบต์ แบบ little-endianเพราะ 0xFE, 0xFF เมื่ออ่านเป็นคำ little-endian 16 บิต จะได้เป็น U+FFFE ซึ่งไม่มีความหมาย ลำดับนี้ยังไม่มีความหมายในรูปแบบ การเข้ารหัส UTF-32 ใดๆ ดังนั้นโดยสรุปแล้ว มันจึงเป็นตัวบ่งชี้ที่ค่อนข้างน่าเชื่อถือว่าสตรีมข้อความนั้นถูกเข้ารหัสเป็น UTF-16 ใน ลำดับไบต์แบบ big-endianในทางกลับกัน หากสองไบต์แรกเป็น 0xFF, 0xFE แสดงว่าสตรีมข้อความนั้นอาจถูกเข้ารหัสเป็น UTF-16LE เพราะเมื่ออ่านเป็นค่า little-endian 16 บิต ไบต์เหล่านั้นจะให้เครื่องหมายลำดับไบต์ 0xFEFF ที่คาดไว้ อย่างไรก็ตาม ข้อสันนิษฐานนี้อาจเป็นที่น่าสงสัย หากไบต์สองไบต์ถัดไปเป็น 0x00 ทั้งคู่ กล่าวคือ ข้อความอาจเริ่มต้นด้วยอักขระว่าง (U+0000) หรือการเข้ารหัสที่ถูกต้องคือ UTF-32LE ซึ่งลำดับ 4 ไบต์เต็ม FF FE 00 00 ถือเป็นอักขระเดียว คือ BOM (Base of Method)
ลำดับ UTF-8 ที่ตรงกับ U+FEFF คือ 0xEF, 0xBB, 0xBF ลำดับนี้ไม่มีความหมายในรูปแบบการเข้ารหัส Unicode อื่นๆ ดังนั้นจึงอาจใช้เพื่อบ่งชี้ว่าสตรีมนั้นถูกเข้ารหัสเป็น UTF-8
ข้อกำหนดของ Unicode ไม่ได้กำหนดให้ต้องใช้เครื่องหมายลำดับไบต์ในสตรีมข้อความ นอกจากนี้ยังระบุว่าไม่ควรใช้ในกรณีที่มีการใช้วิธีอื่นในการระบุรูปแบบการเข้ารหัสอยู่แล้ว
ตัวแปรที่มองไม่เห็นทางคณิตศาสตร์
โดยหลักแล้วสำหรับวิชาคณิตศาสตร์ ตัวคั่นที่มองไม่เห็น (U+2063) ทำหน้าที่เป็นตัวคั่นระหว่างอักขระที่สามารถละเว้นเครื่องหมายวรรคตอนหรือช่องว่างได้ เช่น ในดัชนีสองมิติอย่าง ij ตัวคูณที่มองไม่เห็น (U+2062) และการประยุกต์ใช้ฟังก์ชันที่มองไม่เห็น (U+2061) มีประโยชน์ในข้อความคณิตศาสตร์ที่การคูณพจน์หรือการประยุกต์ใช้ฟังก์ชันนั้นมีความหมายโดยนัยโดยไม่มีสัญลักษณ์ใด ๆ ที่บ่งบอกถึงการดำเนินการ Unicode 5.1 ยังแนะนำอักขระบวกที่มองไม่เห็นทางคณิตศาสตร์ (U+2064) ซึ่งอาจบ่งชี้ว่าจำนวนเต็มที่ตามด้วยเศษส่วนควรแสดงถึงผลรวม ไม่ใช่ผลคูณ
เศษส่วน/
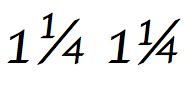

อักขระU+2044 ⁄ FRACTION SLASHมีพฤติกรรมพิเศษในมาตรฐาน Unicode: [ 6 ]
รูปแบบมาตรฐานของเศษส่วนที่สร้างโดยใช้เครื่องหมายทับเศษส่วนนั้นกำหนดไว้ดังนี้: ลำดับของตัวเลขทศนิยมหนึ่งตัวขึ้นไป (ประเภททั่วไป = Nd) ตามด้วยเครื่องหมายทับเศษส่วน ตามด้วยลำดับของตัวเลขทศนิยมหนึ่งตัวขึ้นไป เศษส่วนดังกล่าวควรแสดงเป็นหน่วย เช่น¾หากซอฟต์แวร์ที่แสดงผลไม่สามารถแปลงเศษส่วนเป็นหน่วยได้ ก็สามารถแสดงเป็นลำดับเชิงเส้นอย่างง่ายเป็นทางเลือกสำรองได้ (ตัวอย่างเช่น 3/4) หากต้องการแยกเศษส่วนออกจากตัวเลขก่อนหน้า สามารถใช้ช่องว่าง โดยเลือกความกว้างที่เหมาะสม (ปกติ บาง ความกว้างศูนย์ และอื่นๆ) ตัวอย่างเช่น 1 + ช่องว่างความกว้างศูนย์ + 3 + เครื่องหมายทับเศษส่วน + 4 จะ แสดงเป็น1¾
ด้วยการปฏิบัติตามคำแนะนำของ Unicode นี้ ระบบประมวลผลข้อความจะสร้างสัญลักษณ์ที่ซับซ้อนจากข้อความธรรมดาเพียงอย่างเดียว ในที่นี้ การมีอักขระเศษส่วนแบบสแลชจะสั่งให้เอนจิ้นการจัดวางสร้างเศษส่วนจากตัวเลขทั้งหมดที่ต่อเนื่องกันก่อนและหลังเครื่องหมายสแลช ในทางปฏิบัติ ผลลัพธ์จะแตกต่างกันไปเนื่องจากการทำงานร่วมกันที่ซับซ้อนระหว่างแบบอักษรและเอนจิ้นการจัดวาง เอนจิ้นการจัดวางข้อความแบบง่ายมักจะไม่สร้างเศษส่วนเลย แต่จะวาดสัญลักษณ์เป็นลำดับเชิงเส้นตามที่อธิบายไว้ในแผนการสำรองข้อมูลของ Unicode
โปรแกรมจัดวางตัวอักษรที่ซับซ้อนกว่านั้นมีทางเลือกในทางปฏิบัติสองทาง คือ ปฏิบัติตามคำแนะนำของ Unicode หรืออาศัยคำแนะนำของฟอนต์เองในการสร้างเศษส่วน การไม่ปฏิบัติตามคำแนะนำของฟอนต์จะช่วยให้โปรแกรมจัดวางตัวอักษรสามารถรับประกันพฤติกรรมที่ Unicode แนะนำได้ ในขณะที่การปฏิบัติตามคำแนะนำของฟอนต์จะช่วยให้ได้งานพิมพ์ ที่ดีกว่า เนื่องจากตำแหน่งและรูปร่างของตัวเลขจะถูกปรับให้เข้ากับฟอนต์และขนาดนั้นๆ
ปัญหาของการปฏิบัติตามคำแนะนำของฟอนต์คือ ฟอนต์รูปแบบง่ายๆ ไม่มีวิธีระบุพฤติกรรมการสังเคราะห์เศษส่วน ในขณะที่รูปแบบที่ซับซ้อนกว่านั้นไม่จำเป็นต้องให้ฟอนต์ระบุพฤติกรรมการสังเคราะห์เศษส่วน ดังนั้นฟอนต์จำนวนมากจึงไม่ได้ระบุไว้ ฟอนต์ส่วนใหญ่ที่มีรูปแบบซับซ้อนสามารถสั่งให้โปรแกรมจัดวางข้อความแทนที่ลำดับข้อความธรรมดา เช่น1⁄2ด้วย สัญลักษณ์ ½ ที่ประกอบขึ้นแล้ว แต่เนื่องจากฟอนต์จำนวนมากจะไม่ส่งคำสั่งให้สังเคราะห์เศษส่วน สตริงข้อความธรรมดา เช่น221⁄225อาจแสดงผลเป็น22½25 (โดยที่½เป็นเศษส่วนที่ประกอบขึ้นแล้ว ไม่ใช่เศษส่วนที่สังเคราะห์ขึ้น) เมื่อเผชิญกับปัญหาเช่นนี้ ผู้ที่ต้องการพึ่งพาพฤติกรรม Unicode ที่แนะนำควรเลือกฟอนต์ที่ทราบว่าสามารถสังเคราะห์เศษส่วนได้ หรือซอฟต์แวร์จัดวางข้อความที่ทราบว่าสร้างพฤติกรรมที่แนะนำของ Unicode โดยไม่คำนึงถึงฟอนต์
การจัดรูปแบบที่เป็นกลางแบบสองทิศทาง
ทิศทางการเขียนคือทิศทางที่สัญลักษณ์ตัวอักษรถูกจัดวางบนหน้ากระดาษโดยสัมพันธ์กับการเรียงลำดับตัวอักษรในสตริงยูนิโค้ด ภาษาอังกฤษและภาษาอื่นๆ ที่ใช้ตัวอักษรละตินมีทิศทางการเขียนจากซ้ายไปขวา ส่วนภาษาเขียนหลักๆ บางภาษา เช่นภาษาอาหรับและภาษาฮิบรูมีทิศทางการเขียนจากขวาไปซ้าย ข้อกำหนดของยูนิโค้ดจะกำหนดประเภททิศทางให้กับแต่ละตัวอักษรเพื่อแจ้งให้โปรแกรมประมวลผลข้อความทราบว่าลำดับของตัวอักษรควรเรียงลำดับอย่างไรบนหน้ากระดาษ
ในขณะที่ตัวอักษรทั่วไปมักจะใช้เฉพาะกับระบบการเขียนแบบเดียว แต่สัญลักษณ์และเครื่องหมายวรรคตอนบางอย่างก็ใช้กันในระบบการเขียนหลายแบบ ยูนิโค้ดอาจสร้างสัญลักษณ์ที่ซ้ำกันในชุดสัญลักษณ์โดยที่แตกต่างกันเฉพาะทิศทาง แต่เลือกที่จะรวมสัญลักษณ์เหล่านั้นเข้าด้วยกันและกำหนดทิศทางที่เป็นกลางให้แทน โดยสัญลักษณ์เหล่านั้นจะได้รับทิศทางจากตัวอักษรที่อยู่ติดกันในระหว่างการแสดงผล นอกจากนี้ สัญลักษณ์บางตัวยังมี คุณสมบัติ แบบสะท้อนสองด้านซึ่งบ่งชี้ว่าควรแสดงผลสัญลักษณ์นั้นในรูปแบบภาพสะท้อนเมื่อใช้ในข้อความที่เขียนจากขวาไปซ้าย
ประเภททิศทางการแสดงผลของอักขระที่เป็นกลางอาจยังคงคลุมเครือเมื่อวางเครื่องหมายไว้บนขอบเขตระหว่างการเปลี่ยนแปลงทิศทาง เพื่อแก้ไขปัญหานี้ Unicode จึงมีอักขระที่มีทิศทางชัดเจน ไม่มีสัญลักษณ์ใดๆ ที่เกี่ยวข้อง และระบบที่ไม่ประมวลผลข้อความสองทิศทางสามารถละเว้นอักขระเหล่านี้ได้:
- U+061C เครื่องหมายอักษรอาหรับ
- เครื่องหมายU+200E จากซ้ายไปขวา
- U+200Fเครื่องหมายจากขวาไปซ้าย
การล้อมกรอบอักขระที่เป็นกลางทั้งสองทิศทางด้วยเครื่องหมายจากซ้ายไปขวาจะบังคับให้อักขระนั้นทำงานเหมือนอักขระจากซ้ายไปขวา ในขณะที่การล้อมกรอบด้วยเครื่องหมายจากขวาไปซ้ายจะบังคับให้อักขระนั้นทำงานเหมือนอักขระจากขวาไปซ้าย ลักษณะการทำงานของอักขระเหล่านี้มีรายละเอียดอยู่ในอัลกอริธึมสองทิศทางของยูนิโค้ด
การจัดรูปแบบทั่วไปแบบสองทิศทาง
แม้ว่า Unicode จะได้รับการออกแบบมาเพื่อรองรับหลายภาษา หลายระบบการเขียน และแม้กระทั่งข้อความที่เขียนจากซ้ายไปขวาหรือขวาไปซ้ายโดยมีการแทรกแซงจากผู้เขียนน้อยที่สุด แต่ก็มีสถานการณ์พิเศษที่การผสมผสานข้อความสองทิศทางอาจซับซ้อนขึ้น ซึ่งต้องอาศัยการควบคุมจากผู้เขียนมากขึ้น สำหรับสถานการณ์เหล่านี้ Unicode จึงมีอักขระอีกห้าตัวเพื่อควบคุมการฝังข้อความจากซ้ายไปขวาภายในข้อความจากขวาไปซ้ายและในทางกลับกันอย่างซับซ้อน:
การจัดรูปแบบแบบสองทิศทาง
- U+202Aการฝังจากซ้ายไปขวา
- U+202Bการฝังจากขวาไปซ้าย
- U+202Cการจัดรูปแบบทิศทางป๊อป
- U+202Dการควบคุมจากซ้ายไปขวา
- U+202Eการควบคุมจากขวาไปซ้าย
- U+2066แยก จากซ้ายไปขวา
- U+2067แยก จากขวา
- U+2068แยกเดี่ยวที่แข็งแกร่ง ครั้งแรก
- U+2069 POP DIRECTIONAL ISOLATE
อักขระคำอธิบายประกอบระหว่างบรรทัด
- จุดยึดคำอธิบายประกอบแบบอินเทอร์ไลน์U+FFF9
- ตัวคั่นคำอธิบายประกอบแบบ U+FFFA INTERLINEAR
- U+FFFBตัวจบคำอธิบายประกอบแบบแทรกเส้น
เฉพาะสคริปต์
- การควบคุมรูปแบบคำนำหน้า
- U+0600 เครื่องหมายตัวเลขอาหรับ
- U+0601 ARABIC SIGN SANAH
- U+0602 เครื่องหมายเชิงอรรถภาษาอาหรับ
- U+0603 ARABIC SIGN SAFHA
- U+0604 ARABIC SIGN SAMVAT
- U+0605 ARABIC NUMBER MARK ABOVE
- U+06DD ภาษาอาหรับ จบอายะห์
- เครื่องหมายย่อภาษาซีเรียU+070F
- U+0890 เครื่องหมายเงินปอนด์อาหรับด้านบน
- U+0891 เครื่องหมายเงินปิอาสเตรอาหรับด้านบน
- ป้ายหมายเลขU+110BD KAITHI
- U+110CD ป้ายหมายเลข KAITHI ด้านบน
- อักษรภาพอียิปต์
- U+13430 ตัวเชื่อมต่อแนวตั้งอักษรภาพอียิปต์
- U+13431 ตัวเชื่อมต่อแนวนอนอักษรภาพอียิปต์
- U+13432 อักษรภาพอียิปต์ แทรกที่ด้านบน เริ่มต้น
- U+13433 อักษรภาพอียิปต์โบราณ แทรกที่ด้านล่าง เริ่ม
- U+13434 อักษรภาพอียิปต์โบราณแทรกอยู่ที่ส่วนบนสุด
- U+13435 อักษรภาพอียิปต์โบราณ สอดไว้ที่ปลายด้านล่าง
- U+13436 ภาพซ้อนอักษรฮีโรกลิฟอียิปต์ตรงกลาง
- U+13437 อักษรภาพอียิปต์โบราณ ส่วนเริ่มต้น
- U+13438 ส่วนท้ายของอักษรภาพอียิปต์
- U+13439 อักษรภาพอียิปต์แทรกตรงกลาง
- U+1343A อักษรภาพอียิปต์โบราณแทรกอยู่ด้านบน
- U+1343B อักษรภาพอียิปต์โบราณ (แทรกที่ด้านล่าง)
- U+1343C อักษรภาพอียิปต์โบราณ เริ่มล้อมรอบ
- U+1343D ตราประทับปลายอักษรภาพอียิปต์
- U+1343E อักษรภาพอียิปต์โบราณ เริ่มต้นกำแพงล้อมรอบ
- U+1343F กำแพงล้อมรอบด้านท้ายที่มีอักษรภาพอียิปต์โบราณ
- พราห์มี
- U+1107F 𑁿 BRAHMI NUMBER JOINER
อักขระเทียบกับรหัสจุด
คำว่า "ตัวอักษร" นั้นไม่มีนิยามที่ชัดเจน และโดยส่วนใหญ่แล้วเรามักหมายถึง " กราฟีม " กราฟีมนั้นถูกแสดงออกมาในรูปแบบภาพด้วยสัญลักษณ์ (glyph ) แบบอักษร (ซึ่งมักถูกเรียกผิดๆ ว่า"ฟอนต์ ") ที่ใช้สามารถแสดงตัวอักษรเดียวกันในรูปแบบต่างๆ ได้ เป็นไปได้ที่กราฟีมสองตัวที่แตกต่างกันจะมีสัญลักษณ์เหมือนกันทุกประการ หรือมีลักษณะคล้ายคลึงกันมากจนผู้อ่านทั่วไปแยกแยะไม่ออก
โดยทั่วไปแล้ว ตัวอักษรหนึ่งตัวจะถูกแทนด้วยรหัสจุดเพียงรหัสเดียว ตัวอย่างเช่นตัวอักษรละตินตัวพิมพ์ใหญ่ aจะถูกแทนด้วยรหัสจุด U+0041
กราฟีมU+00C4 Ä LATIN CAPITAL LETTER A WITH DIAERESISเป็นตัวอย่างหนึ่งที่แสดงให้เห็นว่าตัวอักษรหนึ่งตัวสามารถแทนด้วยรหัสจุดได้มากกว่าหนึ่งรหัส โดยสามารถแทนได้เป็น U+00C4 หรือเป็นลำดับU+0041 A LATIN CAPITAL LETTER AและU+0308 ◌̈ COMBINING DIAERESIS
เมื่อเครื่องหมายรวมอยู่ติดกับจุดรหัสเครื่องหมายไม่รวม แอปพลิเคชันการแสดงผลข้อความควรวางเครื่องหมายรวมทับลงบนสัญลักษณ์ที่แสดงโดยจุดรหัสอื่นเพื่อสร้างกราฟีมตามชุดกฎ[ 7 ]
ดังนั้น คำว่า BÄM จึงประกอบด้วยกราฟีมสามตัว อาจประกอบด้วยรหัสสามจุดหรือมากกว่านั้น ขึ้นอยู่กับวิธีการประกอบตัวอักษรในความเป็นจริง
ช่องว่าง ตัวเชื่อม และตัวคั่น
Unicode มีรายการอักขระที่ถือว่าเป็นอักขระเว้นวรรคเพื่อสนับสนุนการทำงานร่วมกัน การใช้งานซอฟต์แวร์และมาตรฐานอื่นๆ อาจใช้คำนี้เพื่อหมายถึงชุดอักขระที่แตกต่างกันเล็กน้อย ตัวอย่างเช่น Java ไม่ถือว่าU+00A0 เป็นอักขระเว้นวรรคแบบไม่ขึ้นบรรทัดใหม่ (NO-BREAK SPACE)หรือU+0085 เป็นอักขระ <control-0085> (บรรทัดถัดไป) จะเป็นช่องว่าง แม้ว่า Unicode จะกำหนดไว้ก็ตาม อักขระช่องว่างโดยทั่วไปถูกกำหนดไว้สำหรับสภาพแวดล้อมการเขียนโปรแกรม บ่อยครั้งที่อักขระเหล่านี้ไม่มีความหมายทางไวยากรณ์ในสภาพแวดล้อมการเขียนโปรแกรมดังกล่าว และจะถูกละเลยโดยตัวแปลภาษาของเครื่อง Unicode กำหนดให้ตัวอักขระควบคุมแบบดั้งเดิม U+0009 ถึง U+000D และ U+0085 เป็นอักขระช่องว่าง เช่นเดียวกับอักขระทั้งหมดที่มีค่าคุณสมบัติหมวดหมู่ทั่วไปเป็นตัวคั่น มีอักขระช่องว่างทั้งหมด 25 ตัว ณ Unicode 17.0
กราฟีมที่เชื่อมต่อและไม่เชื่อมต่อ
U+200D ZERO WIDTH JOINERและ U+200C ZERO WIDTH NON-JOINERควบคุมการเชื่อมต่อและการประสานตัวอักษร ตัวเชื่อมจะไม่ทำให้ตัวอักษรที่ปกติจะไม่เชื่อมต่อหรือประสานกันนั้นเชื่อมต่อหรือประสานกัน แต่เมื่อใช้ร่วมกับตัวไม่เชื่อม ตัวอักษรเหล่านี้สามารถใช้เพื่อควบคุมคุณสมบัติการเชื่อมต่อและการประสานของตัวอักษรสองตัวที่อยู่รอบข้างได้ U+034F ͏ COMBINING GRAPHEME JOINERใช้เพื่อแยกแยะตัวอักษรพื้นฐานสองตัวให้เป็นตัวอักษรพื้นฐานหรือไดกราฟตัวเดียวกัน ส่วนใหญ่ใช้สำหรับการประมวลผลข้อความพื้นฐาน การเรียงลำดับสตริง การพับตัวพิมพ์ใหญ่-เล็ก และอื่นๆ
ตัวเชื่อมและตัวคั่นคำ
ตัวคั่นคำที่พบบ่อยที่สุดคือU+0020 SPACEอย่างไรก็ตาม ยังมีตัวเชื่อมและตัวคั่นคำอื่นๆ ที่บ่งบอกถึงการเว้นวรรคระหว่างคำและมีส่วนร่วมในอัลกอริทึมการขึ้นบรรทัดใหม่ ด้วย U+00A0 NO-BREAK SPACEก็สร้างการเลื่อนเส้นฐานโดยไม่มีสัญลักษณ์ แต่จะยับยั้งการขึ้นบรรทัดใหม่แทนที่จะเปิดใช้งานU+200B ZERO WIDTH SPACEอนุญาตให้ขึ้นบรรทัดใหม่ได้ แต่ไม่มีช่องว่าง: ในแง่หนึ่งคือการเชื่อมคำเข้าด้วยกันแทนที่จะแยกคำสองคำออกจากกัน สุดท้ายU+2060 WORD JOINERจะยับยั้งการขึ้นบรรทัดใหม่และไม่มีช่องว่างใดๆ ที่เกิดจากการเลื่อนเส้นฐานด้วย
| ความก้าวหน้าขั้นพื้นฐาน | ไม่มีความก้าวหน้าขั้นพื้นฐาน | |
|---|---|---|
| อนุญาตให้ขึ้นบรรทัดใหม่ (ตัวคั่น) | U+0020อวกาศ | พื้นที่U+200B ความกว้างเป็นศูนย์ |
| ระงับการขึ้นบรรทัดใหม่ (ตัวเชื่อมต่อ) | พื้นที่ห้ามเว้นว่างU+00A0 | U+2060ตัวเชื่อมคำ |
ตัวคั่นอื่นๆ
- เส้นคั่น (U+2028)
- ตัวคั่นย่อหน้า (U+2029)
อักขระเหล่านี้ช่วยให้ Unicode มีตัวคั่นย่อหน้าและตัวคั่นบรรทัดแบบดั้งเดิม ซึ่งเป็นอิสระจากอักขระควบคุม ASCII ที่เข้ารหัสแบบเดิม เช่น ตัวขึ้นบรรทัดใหม่ (U+000A), ตัวขึ้นบรรทัดใหม่ (U+000D) และตัวขึ้นบรรทัดใหม่ถัดไป (U+0085) Unicode ไม่ได้จัดเตรียมอักขระควบคุมการจัดรูปแบบ ASCII อื่นๆ ซึ่งสันนิษฐานได้ว่าไม่ได้เป็นส่วนหนึ่งของแบบจำลองการประมวลผลข้อความธรรมดาของ Unicode อักขระควบคุมการจัดรูปแบบแบบเดิมเหล่านี้ ได้แก่U+0009 <control-0009>(แท็บ), U+000B <ควบคุม-000B>(แท็บแนวตั้ง) และ Form Feed (U+000C) ซึ่งถือได้ว่าเป็นตัวแบ่งหน้าเช่นกัน
พื้นที่
อักขระเว้นวรรค (U+0020) ซึ่งโดยทั่วไปป้อนโดยการกดแป้นเว้นวรรคบนแป้นพิมพ์ ทำหน้าที่ทางความหมายเป็นตัวคั่นคำในหลายภาษา ด้วยเหตุผลด้านความเข้ากันได้กับระบบเดิม UCS จึงรวมอักขระเว้นวรรคที่มีขนาดแตกต่างกันไว้ด้วย ซึ่งเป็นอักขระที่เทียบเท่ากับอักขระเว้นวรรค แม้ว่าอักขระเว้นวรรคที่มีความกว้างแตกต่างกันเหล่านี้จะมีความสำคัญในด้านการพิมพ์ แต่แบบจำลองการประมวลผลของ Unicode กำหนดให้เอฟเฟกต์ภาพดังกล่าวได้รับการจัดการโดยข้อความแบบ Rich Text, Markup และโปรโตคอลอื่นๆ อักขระเว้นวรรคเหล่านี้รวมอยู่ในชุดอักขระ Unicode เป็นหลักเพื่อจัดการการแปลงรหัสแบบไม่สูญเสียข้อมูลจากชุดอักขระอื่นๆ อักขระเว้นวรรคเหล่านี้ได้แก่:
- ยู+2000เอ็น ควอด
- U+2001 EM QUAD
- U+2002 EN SPACE
- U+2003 EM SPACE
- พื้นที่ U+2004สามต่อเอ็ม
- พื้นที่ U+2005สี่คนต่อหนึ่งเอ็มเอ็ม
- U+2006พื้นที่หกต่อเอ็ม
- U+2007ฟิกเกอร์ สเปซ
- U+2008เครื่องหมายวรรคตอน ช่องว่าง
- U+2009พื้นที่บาง
- พื้นที่สำหรับผมU+200A
- พื้นที่คณิตศาสตร์ระดับกลางU+205F
นอกเหนือจากช่องว่าง ASCII ดั้งเดิมแล้ว ช่องว่างอื่นๆ ทั้งหมดเป็นอักขระที่ใช้เพื่อความเข้ากันได้ ในบริบทนี้หมายความว่าอักขระเหล่านี้ไม่ได้เพิ่มความหมายใดๆ ให้กับข้อความ แต่ให้การควบคุมรูปแบบแทน ภายใน Unicode การควบคุมรูปแบบที่ไม่เกี่ยวกับความหมายนี้มักเรียกว่าข้อความที่สมบูรณ์ (rich text) และอยู่นอกเหนือเป้าหมายหลักของ Unicode แทนที่จะใช้ช่องว่างที่แตกต่างกันในบริบทที่แตกต่างกัน การจัดรูปแบบนี้ควรจัดการผ่านซอฟต์แวร์จัดวางข้อความอัจฉริยะแทน
ตัวคั่นคำเฉพาะระบบการเขียนอีกสามแบบ ได้แก่:
- U+180E ตัวคั่นสระมองโกล
- พื้นที่สัญลักษณ์U+3000 : ทำหน้าที่เป็นตัวคั่นสัญลักษณ์ และโดยทั่วไปจะแสดงผลเป็นพื้นที่ว่างสีขาวที่มีความกว้างเท่ากับสัญลักษณ์นั้นๆ
- U+1680เครื่องหมายช่องว่างอ็อกแฮม : อักขระนี้บางครั้งแสดงร่วมกับสัญลักษณ์อื่น และบางครั้งแสดงเป็นเพียงช่องว่างสีขาว
อักขระควบคุมการขึ้นบรรทัดใหม่
มีการออกแบบอักขระหลายตัวเพื่อช่วยควบคุมการขึ้นบรรทัดใหม่ ไม่ว่าจะเป็นการห้ามขึ้นบรรทัดใหม่ (อักขระห้ามขึ้นบรรทัดใหม่) หรือการแนะนำการขึ้นบรรทัดใหม่ เช่น เครื่องหมายยัติภังค์อ่อน (U+00AD) (บางครั้งเรียกว่า "ยัติภังค์ขี้อาย") อักขระเหล่านี้แม้จะออกแบบมาเพื่อการตกแต่ง แต่ก็อาจเป็นสิ่งจำเป็นอย่างยิ่งสำหรับการขึ้นบรรทัดใหม่ที่ซับซ้อนซึ่งเป็นไปได้
- การยับยั้งการแตกหัก
- U+2011 - เครื่องหมายยัติภังค์ที่ไม่เว้นวรรค
- พื้นที่ห้ามเว้นว่างU+00A0
- U+0F0C ༌ ตัวคั่นเครื่องหมายทิเบต TSHEG BSTAR
- U+202Fพื้นที่แคบไม่มีช่องว่าง
อักขระที่ป้องกันการขึ้นบรรทัดใหม่นั้นมีจุดประสงค์เพื่อให้เทียบเท่ากับลำดับอักขระที่ถูกห่อหุ้มด้วย Word Joiner U+2060 อย่างไรก็ตาม สามารถเพิ่ม Word Joiner ไว้ก่อนหรือหลังอักขระใดๆ ก็ได้ที่อนุญาตให้มีการขึ้นบรรทัดใหม่ เพื่อป้องกันการขึ้นบรรทัดใหม่ดังกล่าว
- การเปิดใช้งานการหยุด
- U+00ADซอฟต์ ไฮเฟน
- U+0F0B ་ เครื่องหมายระหว่างพยางค์ทิเบต TSHEG
- พื้นที่U+200B ความกว้างเป็นศูนย์
ทั้งอักขระที่ยับยั้งการแบ่งบรรทัดและอักขระที่อนุญาตให้แบ่งบรรทัดมีส่วนร่วมกับเครื่องหมายวรรคตอนและอักขระเว้นวรรคอื่นๆ เพื่อให้ระบบการสร้างภาพข้อความสามารถกำหนดการแบ่งบรรทัดภายในอัลกอริธึมการแบ่งบรรทัดของยูนิโค้ดได้[ 8 ]
ประเภทของจุดรหัส
รหัสจุดทั้งหมดที่มีวัตถุประสงค์หรือการใช้งานบางอย่าง ถือเป็นรหัสจุดที่กำหนดไว้แล้ว ในจำนวนนั้น รหัสจุดเหล่านั้นอาจถูกกำหนดให้กับอักขระนามธรรม หรือถูกกำหนดเพื่อวัตถุประสงค์อื่น ๆ
ตัวละครที่ได้รับมอบหมาย
รหัสอักขระส่วนใหญ่ที่ใช้จริงนั้นถูกกำหนดให้กับอักขระนามธรรม ซึ่งรวมถึงอักขระที่ใช้เฉพาะกลุ่ม ซึ่งแม้ว่าจะไม่ได้ถูกกำหนดอย่างเป็นทางการโดยมาตรฐานยูนิโค้ดสำหรับวัตถุประสงค์เฉพาะใดๆ แต่ผู้ส่งและผู้รับจะต้องตกลงกันล่วงหน้าว่าจะตีความอย่างไรเพื่อให้สามารถ แลกเปลี่ยนข้อมูล ที่มีความหมายได้
อักขระสำหรับใช้ส่วนตัว
UCS ประกอบด้วยอักขระใช้งานส่วนตัว 137,468 ตัว ซึ่งเป็นรหัสจุดสำหรับใช้งานส่วนตัวที่กระจายอยู่ทั่วสามบล็อกที่แตกต่างกัน โดยแต่ละบล็อกเรียกว่าพื้นที่ใช้งานส่วนตัว (PUA) มาตรฐาน Unicode ยอมรับรหัสจุดภายใน PUA ว่าเป็นรหัสอักขระ Unicode ที่ถูกต้อง แต่ไม่ได้กำหนดอักขระ (นามธรรม) ใดๆ ให้กับรหัสจุดเหล่านั้น ในทางกลับกัน บุคคล องค์กร ผู้จำหน่ายซอฟต์แวร์ ผู้จำหน่ายระบบปฏิบัติการ ผู้จำหน่ายฟอนต์ และชุมชนผู้ใช้ปลายทางมีอิสระที่จะใช้รหัสจุดเหล่านั้นตามที่เห็นสมควร ภายในระบบปิด อักขระใน PUA สามารถทำงานได้อย่างไม่คลุมเครือ ทำให้ระบบดังกล่าวสามารถแสดงอักขระหรือสัญลักษณ์ที่ไม่ได้กำหนดไว้ใน Unicode ได้[ 9 ]ในระบบสาธารณะ การใช้งานอักขระเหล่านี้เป็นปัญหามากกว่า เนื่องจากไม่มีการลงทะเบียนและไม่มีวิธีใดที่จะป้องกันไม่ให้หลายองค์กรนำรหัสจุดเดียวกันไปใช้เพื่อวัตถุประสงค์ที่แตกต่างกัน ตัวอย่างหนึ่งของความขัดแย้งดังกล่าวคือ การใช้ U+F8FFของAppleสำหรับโลโก้ Appleเทียบกับ การใช้ U+F8FF ของ ConScript Unicode Registryเป็นสัญลักษณ์การทำมัมมี่ของชาวคลิงอนในอักษรคลิงอน[ 10 ]
ระนาบภาษาพื้นฐาน (ระนาบ 0) ประกอบด้วยอักขระสำหรับผู้ใช้ส่วนตัว 6,400 ตัว ในพื้นที่ใช้งานส่วนตัว (PUA) ซึ่งมีช่วงรหัสตั้งแต่ U+E000 ถึง U+F8FF ระนาบการใช้งานส่วนตัวระนาบ 15 และระนาบ 16 แต่ละระนาบมีพื้นที่ใช้งานส่วนตัวของตนเองจำนวน 65,534 ตัว (โดยสองรหัสสุดท้ายของแต่ละระนาบเป็นอักขระที่ไม่ใช่ตัวอักขระ) ได้แก่พื้นที่ใช้งานส่วนตัวเสริม-Aซึ่งมีช่วงรหัสตั้งแต่ U+F0000 ถึง U+FFFFD และพื้นที่ใช้งานส่วนตัวเสริม-Bซึ่งมีช่วงรหัสตั้งแต่ U+100000 ถึง U+10FFFD
PUA (Private Use Area) เป็นแนวคิดที่สืบทอดมาจากระบบการเข้ารหัสบางระบบในเอเชีย ระบบเหล่านี้มีพื้นที่ใช้งานส่วนตัวเพื่อเข้ารหัสสิ่งที่ชาวญี่ปุ่นเรียกว่าไกจิ (อักขระหายากที่ไม่พบในฟอนต์ทั่วไป) ในลักษณะเฉพาะสำหรับการใช้งานนั้นๆ
ตัวแทน
UCS ใช้ตัวแทน (surrogates) เพื่อระบุอักขระที่อยู่นอกระนาบหลายภาษาพื้นฐาน เริ่มต้น โดยไม่ต้องใช้การแสดงคำที่มีมากกว่า 16 บิต[ 11 ]มีตัวแทน "สูง" 1024 ตัว (D800–DBFF) และตัวแทน "ต่ำ" 1024 ตัว (DC00–DFFF) โดยการรวมตัวแทนสองตัวเข้าด้วยกัน จะสามารถระบุอักขระที่เหลือในระนาบอื่นๆ ทั้งหมดได้ (1024 × 1024 = 1,048,576 จุดรหัสในระนาบอีก 16 ระนาบ) ในUTF-16ตัวแทนเหล่านี้จะต้องปรากฏเป็นคู่เสมอ โดยเป็นตัวแทนสูงตามด้วยตัวแทนต่ำ ดังนั้นจึงใช้ 32 บิตในการแสดงจุดรหัสหนึ่งจุด
คู่ตัวแทนแสดงถึงจุดรหัส
- 10,000 16 + ( สูง - D800 16 ) × 400 16 + ( ยาว - DC00 16 )
โดยที่HและLคือค่าตัวเลขของตัวแทนสูงและต่ำตามลำดับ[ 12 ]
เนื่องจากค่าตัวแทนสูงในช่วง DB80–DBFF จะสร้างค่าในระนาบการใช้งานส่วนตัวเสมอ ดังนั้นช่วงค่าตัวแทนสูงจึงสามารถแบ่งออกเป็นค่าตัวแทนสูง (ปกติ) (D800–DB7F) และ "ค่าตัวแทนสูงสำหรับการใช้งานส่วนตัว" (DB80–DBFF) ได้อีก
จุดรหัสตัวแทนที่แยกเดี่ยวไม่มีการตีความทั่วไป ดังนั้นจึงไม่มีแผนภูมิรหัสอักขระหรือรายการชื่อสำหรับช่วงนี้ ในภาษาการเขียนโปรแกรม Pythonรหัสตัวแทนแต่ละรหัสจะถูกใช้เพื่อฝังไบต์ที่ไม่สามารถถอดรหัสได้ในสตริง Unicode [ 13 ]
ตัวละครที่ไม่ใช่ตัวละครหลัก
คำว่า "noncharacter" ที่ไม่มีเครื่องหมายขีดคั่น หมายถึง รหัสจุด 66 รหัส (ที่มีป้ายกำกับ<not a character>) ที่สงวนไว้สำหรับการใช้งานภายในอย่างถาวร และรับประกันได้ว่าจะไม่ถูกกำหนดให้กับอักขระใดๆ[ 14 ]แต่ละระนาบทั้ง 17 ระนาบจะมีรหัสจุดสองรหัสสุดท้ายที่กันไว้เป็น noncharacter ดังนั้น noncharacter จึงได้แก่ U+FFFE และ U+FFFF บน BMP, U+1FFFE และ U+1FFFF บนระนาบที่ 1 และอื่นๆ ไปจนถึง U+10FFFE และ U+10FFFF บนระนาบที่ 16 รวมเป็นรหัสจุดทั้งหมด 34 รหัส นอกจากนี้ ยังมีช่วงต่อเนื่องของรหัสจุด noncharacter อีก 32 รหัสใน BMP ซึ่งตั้งอยู่ในรูปแบบการนำเสนอภาษาอาหรับ-A : U+FDD0..U+FDEF การใช้งานซอฟต์แวร์สามารถใช้รหัสจุดเหล่านี้สำหรับการใช้งานภายในได้อย่างอิสระ ตัวอย่างที่มีประโยชน์อย่างยิ่งของ noncharacter คือ รหัสจุด U+FFFE รหัสอักขระนี้มีลำดับไบต์แบบ UTF-16/UCS-2 ที่กลับด้านของเครื่องหมายลำดับไบต์ (U+FEFF) หากสตรีมข้อความมีอักขระที่ไม่ใช่ตัวอักขระนี้ แสดงว่าข้อความนั้นถูกตีความด้วยลำดับไบต์ ที่ ไม่ ถูกต้อง
มาตรฐาน Unicode เวอร์ชัน 3.1.0 ถึง 6.3.0 ระบุว่าอักขระที่ไม่ใช่ตัวอักษร "ไม่ควรใช้แทนกันได้" ต่อมา มีการแก้ไขเพิ่มเติมฉบับที่ 9ของมาตรฐานดังกล่าว โดยระบุว่าสิ่งนี้ทำให้เกิด "การปฏิเสธมากเกินไปอย่างไม่เหมาะสม" จึงชี้แจงว่าอักขระที่ไม่ใช่ตัวอักษร "ไม่ได้ผิดกฎหมายในการใช้แทนกัน และไม่ได้ทำให้ข้อความ Unicode ผิดรูปแบบ" และได้ลบข้อความเดิมออกไป
รหัสสงวน
รหัสอักขระอื่นๆ ทั้งหมด ซึ่งไม่ได้ถูกกำหนดไว้ จะเรียกว่า รหัสอักขระที่สงวนไว้ รหัสอักขระเหล่านี้อาจถูกกำหนดให้ใช้เฉพาะในมาตรฐานยูนิโค้ดเวอร์ชันในอนาคต
ตัวอักษร กลุ่มกราฟีม และสัญลักษณ์
ในขณะที่ชุดอักขระอื่นๆ จำนวนมากกำหนดอักขระให้กับทุกรูปแบบที่เป็นไปได้ของการแสดงอักขระนั้น ๆ แต่ยูนิโค้ดพยายามที่จะแยกอักขระออกจากรูปแบบสัญลักษณ์ ความแตกต่างนี้อาจไม่ชัดเจนเสมอไป อย่างไรก็ตาม ตัวอย่างบางส่วนจะช่วยให้เห็นภาพความแตกต่างได้ชัดเจนขึ้น บ่อยครั้งที่อักขระสองตัวอาจถูกรวมเข้าด้วยกันทางด้านการพิมพ์เพื่อปรับปรุงความอ่านง่ายของข้อความ ตัวอย่างเช่น ลำดับตัวอักษรสามตัว "ffi" อาจถูกมองว่าเป็นรูปแบบสัญลักษณ์เดียว ชุดอักขระอื่นๆ มักจะกำหนดรหัสจุดให้กับรูปแบบสัญลักษณ์นี้ นอกเหนือจากตัวอักษรแต่ละตัว: "f" และ "i"
นอกจากนี้ Unicode ยังมอง ตัวอักษรที่มีเครื่องหมายกำกับ เสียง (diaresis)เป็นอักขระแยกต่างหาก ซึ่งเมื่อแสดงผลแล้วจะกลายเป็นสัญลักษณ์เดียว ตัวอย่างเช่น ตัว "o" ที่มี เครื่องหมายกำกับ เสียงคือ " ö " โดยทั่วไปแล้ว ชุดอักขระอื่นๆ จะกำหนดรหัสอักขระเฉพาะสำหรับตัวอักษรที่มีเครื่องหมายกำกับเสียงแต่ละตัวที่ใช้ในแต่ละภาษา Unicode พยายามสร้างแนวทางที่ยืดหยุ่นกว่าโดยอนุญาตให้รวมอักขระกำกับเสียงเข้ากับตัวอักษรใดก็ได้ ซึ่งมีศักยภาพที่จะลดจำนวนรหัสอักขระที่จำเป็นสำหรับชุดอักขระลงอย่างมาก ตัวอย่างเช่น ลองพิจารณาภาษาที่ใช้ตัวอักษรละตินและรวมเครื่องหมายกำกับเสียงกับตัวอักษรพิมพ์ใหญ่และพิมพ์เล็ก "a", "o" และ "u" ด้วยแนวทางของ Unicode จะต้องเพิ่มเฉพาะอักขระกำกับเสียง "a" เท่านั้นลงในชุดอักขระเพื่อใช้กับตัวอักษรละติน ได้แก่ "a", "A", "o", "O", "u" และ "U" รวมทั้งหมดเจ็ดตัว ชุดอักขระแบบดั้งเดิมจำเป็นต้องเพิ่ม ตัวอักษร สำเร็จรูปที่มีเครื่องหมายไดแอรีซิสอีกหกตัว นอกเหนือจากรหัสอักขระหกตัวที่ใช้สำหรับตัวอักษรที่ไม่มีเครื่องหมายไดแอรีซิส รวมเป็นรหัสอักขระทั้งหมดสิบสองตัว
อักขระความเข้ากันได้
UCS ประกอบด้วยอักขระหลายพันตัวที่ Unicode กำหนดให้เป็นอักขระที่ใช้ร่วมกันได้ อักขระเหล่านี้ถูกรวมไว้ใน UCS เพื่อให้มีจุดรหัสที่แตกต่างกันสำหรับอักขระที่ชุดอักขระอื่น ๆ แยกแยะได้ แต่จะไม่ถูกแยกแยะในวิธีการของ Unicode
เหตุผลหลักที่ทำให้เกิดความแตกต่างนี้คือ Unicode แยกความแตกต่างระหว่างตัวอักษรและสัญลักษณ์ตัวอักษร ตัวอย่างเช่น เมื่อเขียนภาษาอังกฤษด้วยลายมือ แบบ หวัดตัวอักษร "i" อาจมีรูปแบบที่แตกต่างกันไป ขึ้นอยู่กับว่าปรากฏอยู่ต้นคำ ท้ายคำ กลางคำ หรืออยู่โดดเดี่ยว ภาษาอย่างเช่นภาษาอาหรับที่เขียนด้วยอักษรอาหรับจะเป็นแบบหวัดเสมอ ตัวอักษรแต่ละตัวมีหลายรูปแบบ UCS ประกอบด้วยอักขระรูปแบบอาหรับ 730 ตัว ซึ่งแยกย่อยเหลือเพียง 88 ตัวอักษรอาหรับที่ไม่ซ้ำกัน อย่างไรก็ตาม อักขระอาหรับเพิ่มเติมเหล่านี้ถูกรวมไว้เพื่อให้ซอฟต์แวร์ประมวลผลข้อความสามารถแปลงข้อความจากชุดอักขระอื่นเป็น UCS และกลับมาอีกครั้งได้โดยไม่สูญเสียข้อมูลสำคัญสำหรับซอฟต์แวร์ที่ไม่รองรับ Unicode
อย่างไรก็ตาม สำหรับ UCS และ Unicode โดยเฉพาะ วิธีการที่นิยมคือการเข้ารหัสหรือแมปตัวอักษรนั้นไปยังอักขระเดียวกันเสมอ ไม่ว่าตัวอักษรนั้นจะปรากฏอยู่ที่ใดในคำ จากนั้นรูปแบบที่แตกต่างกันของแต่ละตัวอักษรจะถูกกำหนดโดยวิธีการของซอฟต์แวร์แบบอักษรและการจัดวางข้อความ ด้วยวิธีนี้ หน่วยความจำภายในสำหรับอักขระจะยังคงเหมือนเดิมไม่ว่าอักขระนั้นจะปรากฏอยู่ที่ใดในคำ ซึ่งช่วยลดความซับซ้อนในการค้นหา การจัดเรียง และการประมวลผลข้อความอื่นๆ ได้อย่างมาก
คุณสมบัติของตัวละคร
อักขระทุกตัวใน Unicode ถูกกำหนดโดยชุดคุณสมบัติขนาดใหญ่และเพิ่มขึ้นเรื่อยๆ คุณสมบัติส่วนใหญ่เหล่านี้ไม่ได้เป็นส่วนหนึ่งของชุดอักขระสากล คุณสมบัติเหล่านี้อำนวยความสะดวกในการประมวลผลข้อความ รวมถึงการเรียงลำดับหรือจัดเรียงข้อความ การระบุคำ ประโยค และกราฟีม การแสดงผลหรือการสร้างภาพข้อความ และอื่นๆ ด้านล่างนี้คือรายการคุณสมบัติหลักบางส่วน ยังมีคุณสมบัติอื่นๆ อีกมากมายที่บันทึกไว้ในฐานข้อมูลอักขระ Unicode [ 15 ]
| คุณสมบัติ | ตัวอย่าง | รายละเอียด |
|---|---|---|
| ชื่อ | อักษรละตินตัวพิมพ์ใหญ่ A | นี่คือชื่อถาวรที่กำหนดโดยความร่วมมือระหว่าง Unicode และ ISO UCS มีชื่อที่เลือกไม่ดีอยู่บ้างและได้รับการยอมรับ (เช่น U+FE18 PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET ซึ่งสะกดผิด – ควรเป็น BRACKET) แต่จะไม่เปลี่ยนแปลง เพื่อให้มั่นใจถึงความเสถียรของข้อกำหนด[ 16 ] |
| โค้ดพอยต์ | ยู+0041 | รหัสจุด Unicode เป็นตัวเลขที่ถูกกำหนดอย่างถาวรเช่นเดียวกับคุณสมบัติ "ชื่อ" และรวมอยู่ใน UCS ด้วย โดยปกติแล้วจะใช้เลขฐานสิบหกแทนรหัสจุดโดยมีคำนำหน้า "U+" |
| สัญลักษณ์ตัวแทน | สัญลักษณ์ตัวแทนมีให้ในแผนภูมิรหัส[ 18 ] | |
| สคริปต์ | ละติน (Latn) | อักษรแต่ละตัวเป็นส่วนหนึ่งของอักษรชุด ใดชุดหนึ่ง อักษรแต่ละชุดจะถูกกำหนดรหัส 4 ตัวอักษร ในกรณีนี้คือ "Latn" สำหรับ Latin นอกจากนี้ยังมีอักษรพิเศษอีกสามชุด ได้แก่ อักษรที่ไม่รู้จัก (Zyyy) และอักษรที่สืบทอดมาอีกสองชุด (Zinh และ Qaai) |
| หมวดหมู่ทั่วไป | ลู่ (ตัวอักษรพิมพ์ใหญ่) | หมวดหมู่ทั่วไป[ 19 ]จะแสดงเป็นลำดับตัวอักษรสองตัว เช่น "Lu" สำหรับตัวอักษรพิมพ์ใหญ่ หรือ "Nd" สำหรับตัวเลขทศนิยม |
| การรวมคลาส | ไม่ได้เรียงลำดับใหม่ (0) | เนื่องจากเครื่องหมายกำกับเสียงและเครื่องหมายรวมอื่นๆ สามารถแสดงได้ด้วยอักขระหลายตัวใน Unicode คุณสมบัติ "Combining Class" จึงช่วยให้สามารถแยกแยะอักขระตามประเภทของอักขระรวมที่แสดงได้ Combining Class สามารถแสดงเป็นจำนวนเต็มระหว่าง 0 ถึง 255 หรือเป็นค่าที่กำหนดชื่อได้ ค่าจำนวนเต็มช่วยให้สามารถจัดเรียงเครื่องหมายรวมใหม่ให้อยู่ในลำดับมาตรฐานเพื่อให้สามารถเปรียบเทียบสตริงที่เหมือนกันได้ |
| หมวดหมู่แบบสองทิศทาง | จากซ้ายไปขวา | ระบุประเภทของอักขระที่จะใช้กับอัลกอริทึมแบบสองทิศทางของยูนิโค้ด |
| การสะท้อนแบบสองทิศทาง | เลขที่ | ระบุว่าสัญลักษณ์ของตัวอักษรจะต้องถูกกลับด้านหรือสะท้อนภายในอัลกอริทึมแบบสองทิศทาง สัญลักษณ์ที่สะท้อนแล้วสามารถจัดหาโดยผู้สร้างฟอนต์ สกัดจากตัวอักษรอื่นๆ ที่เกี่ยวข้องผ่านคุณสมบัติ "สัญลักษณ์สะท้อนแบบสองทิศทาง" หรือสร้างขึ้นโดยระบบการแสดงผลข้อความ |
| สัญลักษณ์การสะท้อนแบบสองทิศทาง | ไม่มีข้อมูล | คุณสมบัตินี้ระบุรหัสจุดของอักขระอื่นที่มีรูปสัญลักษณ์ที่สามารถใช้เป็นรูปสัญลักษณ์สะท้อนสำหรับอักขระปัจจุบันเมื่อทำการสะท้อนภายในอัลกอริทึมแบบสองทิศทาง |
| ค่าตัวเลขทศนิยม | นาเอ็น | สำหรับตัวเลข คุณสมบัตินี้ระบุค่าตัวเลขของตัวอักษร ตัวเลขทศนิยมจะมีค่าทั้งสามค่าตั้งไว้เป็นค่าเดียวกัน ตัวเลขที่ใช้สำหรับการแสดงผลข้อความแบบ Rich Text และตัวเลขอื่นๆ ที่ไม่ใช่ตัวเลขทศนิยมในกลุ่มตัวเลขอาหรับ-อินเดีย โดยทั่วไปจะมีเพียงสองคุณสมบัติหลังเท่านั้นที่ตั้งไว้เป็นค่าตัวเลขของตัวอักษร ในขณะที่ตัวเลขที่ไม่เกี่ยวข้องกับตัวเลขอาหรับ-อินเดีย เช่น ตัวเลขโรมัน หรือตัวเลขฮั่นโจว/ซูโจว โดยทั่วไปจะมีเพียง "ค่าตัวเลข" เท่านั้นที่ระบุไว้ |
| ค่าตัวเลข | นาเอ็น | |
| ค่าตัวเลข | นาเอ็น | |
| อักษรภาพ | เท็จ | ระบุว่าตัวอักษรนั้นเป็นอักษรภาพ CJK : อักษรภาพในอักษรฮั่น[ 20 ] |
| ค่าเริ่มต้นที่ละเลยได้ | เท็จ | ระบุว่าอักขระนี้สามารถละเว้นได้สำหรับการใช้งาน และไม่จำเป็นต้องแสดงสัญลักษณ์ใดๆ ไม่ว่าจะเป็นสัญลักษณ์สำรอง สัญลักษณ์ทดแทน หรืออักขระใดๆ ก็ตาม |
| เลิกใช้แล้ว | เท็จ | Unicode ไม่เคยลบอักขระออกจากชุดอักขระ แต่บางครั้ง Unicode อาจยกเลิกการใช้งานอักขระจำนวนเล็กน้อย |
Unicode มีฐานข้อมูลออนไลน์[ 21 ]เพื่อสอบถามชุดอักขระ Unicode ทั้งหมดแบบโต้ตอบตามคุณสมบัติต่างๆ
ดูเพิ่มเติม
ลิงก์ภายนอก
- สมาคมยูนิโค้ด
- decodeunicode.orgวิกิ Unicode ที่รวบรวมอักขระกราฟิกทั้ง 98884 ตัวของ Unicode 5.0 ในรูปแบบไฟล์ GIF พร้อมระบบค้นหาข้อความเต็มรูปแบบ
- อักขระยูนิโค้ดตามคุณสมบัติ
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ อักขระชุดอักขระสากล
สมาคมยูนิโค้ด ( Unicode Consortium) และ คณะทำงานร่วม ISO/IEC JTC 1/SC 2 / WG 2 ร่วมมือกันในการจัดทำรายการอักขระ ในชุดอักขระรหัสสากล (Universal Coded Character Set หรือ UCS)...
ภาพรวมข้อมูลอ้างอิงตัวละคร
การอ้างอิงอักขระตัวเลข ใน HTML หรือXML จะ อ้างอิงถึงอักขระโดยใช้รหัสจุดของ ชุดอักขระสากล /ยูนิโค้ด และใช้รูปแบบดังนี้
เครื่องบิน
Unicode และ ISO แบ่งชุดรหัสอักขระออกเป็น 17 ระนาบ แต่ละระนาบสามารถบรรจุอักขระที่แตกต่างกันได้ 65,536 ตัว หรือรวมทั้งหมด 1,114,112 ตัว ณ ปี 2025 (Unicode 17.
บล็อก
Unicode เพิ่มคุณสมบัติบล็อกให้กับ UCS ซึ่งแบ่งแต่ละระนาบออกเป็นบล็อกย่อยๆ แต่ละบล็อกเป็นการจัดกลุ่มอักขระตามการใช้งาน เช่น "ตัวดำเนินการทางคณิตศาสตร์" หรือ "อักขระอักษรฮิบรู" เมื่อกำหนดอักขระให้กับรหัสจุดที่ยังไม่ได้กำหนดไว้ก่อนหน้านี้ โดยทั่วไปแล้ว...