อ่าน 14 นาที
การลดมิติแบบไม่เชิงเส้น
การลดมิติแบบไม่เชิงเส้น (NLDR) หรือที่รู้จักกันในชื่อการเรียนรู้แมนิโฟลด์คือเทคนิคต่างๆ ที่เกี่ยวข้องซึ่งมีเป้าหมายเพื่อฉายภาพข้อมูลที่มีมิติสูง...
การลดมิติแบบไม่เชิงเส้น

การลดมิติแบบไม่เชิงเส้น (NLDR) หรือที่รู้จักกันในชื่อการเรียนรู้แมนิโฟลด์คือเทคนิคต่างๆ ที่เกี่ยวข้องซึ่งมีเป้าหมายเพื่อฉายภาพข้อมูลที่มีมิติสูง ซึ่งอาจมีอยู่บนแมนิโฟลด์แบบไม่เชิงเส้น ( พื้นที่ย่อยที่ไม่เป็นเชิงเส้น ) ซึ่งไม่สามารถจับภาพได้อย่างเพียงพอด้วยวิธีการแยกส่วนเชิงเส้น ไปยังแมนิโฟลด์แฝงที่มี มิติต่ำกว่า โดยมีเป้าหมายเพื่อแสดงภาพข้อมูลในพื้นที่ที่มีมิติต่ำ หรือเรียนรู้การแมป (จากพื้นที่ที่มีมิติสูงไปยังการฝังตัวที่มีมิติต่ำ หรือในทางกลับกัน) [ 1 ] [ 2 ]เทคนิคที่อธิบายไว้ด้านล่างนี้สามารถเข้าใจได้ว่าเป็นการวางนัยทั่วไปของวิธีการแยกส่วนเชิงเส้นที่ใช้สำหรับการลดมิติเช่นการแยกส่วนค่าเอกพจน์และ การ วิเคราะห์ ส่วนประกอบหลัก
การประยุกต์ใช้ NLDR
ข้อมูลที่มีมิติสูงอาจเป็นเรื่องยากสำหรับเครื่องจักรในการประมวลผล เนื่องจากต้องใช้เวลาและพื้นที่ในการวิเคราะห์จำนวนมาก นอกจากนี้ยังเป็นความท้าทายสำหรับมนุษย์ด้วย เพราะเป็นการยากที่จะมองเห็นหรือทำความเข้าใจข้อมูลที่มีมากกว่าสามมิติ การลดมิติของชุดข้อมูลในขณะที่ยังคงรักษาคุณลักษณะที่สำคัญเอาไว้ได้ค่อนข้างครบถ้วน จะช่วยให้ขั้นตอนวิธีมีประสิทธิภาพมากขึ้นและช่วยให้นักวิเคราะห์สามารถมองเห็นแนวโน้มและรูปแบบต่างๆ ได้ชัดเจนยิ่งขึ้น
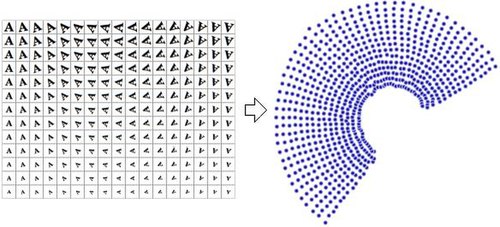
การลดมิติของข้อมูลมักถูกเรียกว่า "ตัวแปรภายใน" (intrinsic variables) คำอธิบายนี้หมายความว่าตัวแปรเหล่านี้เป็นค่าที่ใช้ในการสร้างข้อมูล ตัวอย่างเช่น พิจารณาชุดข้อมูลที่มีภาพตัวอักษร 'A' ซึ่งถูกปรับขนาดและหมุนในปริมาณที่แตกต่างกัน ภาพแต่ละภาพมีขนาด 32×32 พิกเซล แต่ละภาพสามารถแสดงเป็นเวกเตอร์ของค่าพิกเซล 1024 ค่า แต่ละแถวเป็นตัวอย่างบนแมนิโฟลด์สองมิติในปริภูมิ 1024 มิติ ( ปริภูมิแฮมมิง ) มิติภายในคือสอง เนื่องจากมีการเปลี่ยนแปลงตัวแปรสองตัว (การหมุนและการปรับขนาด) เพื่อสร้างข้อมูล ข้อมูลเกี่ยวกับรูปร่างหรือลักษณะของตัวอักษร 'A' ไม่ใช่ส่วนหนึ่งของตัวแปรภายใน เพราะมันเหมือนกันในทุกกรณี การลดมิติแบบไม่เชิงเส้นจะทิ้งข้อมูลที่สัมพันธ์กัน (ตัวอักษร 'A') และกู้คืนเฉพาะข้อมูลที่เปลี่ยนแปลง (การหมุนและการปรับขนาด) เท่านั้น

ในทางตรงกันข้าม หาก ใช้ การวิเคราะห์ส่วนประกอบหลัก (Principal Component Analysis : PCA) ซึ่งเป็นอัลกอริธึมลดมิติเชิงเส้น เพื่อลดชุดข้อมูลเดียวกันนี้ให้เหลือสองมิติ ค่าที่ได้จะไม่เป็นระเบียบเรียบร้อยเท่าที่ควร ซึ่งแสดงให้เห็นว่าเวกเตอร์มิติสูง (แต่ละเวกเตอร์แทนตัวอักษร 'A') ที่สุ่มตัวอย่างจากแมนิโฟลด์นี้มีการเปลี่ยนแปลงในลักษณะที่ไม่เป็นเชิงเส้น
ดังนั้น จึงเห็นได้ชัดว่า NLDR มีการประยุกต์ใช้หลายอย่างในสาขาวิทยาการคอมพิวเตอร์ด้านการมองเห็น ตัวอย่างเช่น ลองพิจารณาหุ่นยนต์ที่ใช้กล้องในการนำทางในสภาพแวดล้อมคงที่แบบปิด ภาพที่ได้จากกล้องนั้นสามารถถือได้ว่าเป็นตัวอย่างบนแมนิโฟลด์ในปริภูมิหลายมิติ และตัวแปรภายในของแมนิโฟลด์นั้นจะแสดงถึงตำแหน่งและการวางแนวของหุ่นยนต์
แมนิโฟลด์ไม่แปรเปลี่ยนมีความน่าสนใจโดยทั่วไปสำหรับการลดลำดับแบบจำลองในระบบพลวัต โดยเฉพาะอย่างยิ่ง หากมีแมนิโฟลด์ไม่แปรเปลี่ยนที่ดึงดูดอยู่ในปริภูมิเฟส วิถีใกล้เคียงจะลู่เข้าสู่แมนิโฟลด์นั้นและคงอยู่บนนั้นอย่างไม่มีกำหนด ทำให้แมนิโฟลด์นั้นเป็นตัวเลือกสำหรับการลดมิติของระบบพลวัต แม้ว่าแมนิโฟลด์ดังกล่าวจะไม่รับประกันว่าจะมีอยู่โดยทั่วไป แต่ทฤษฎีของซับแมนิโฟลด์สเปกตรัม (SSM)ให้เงื่อนไขสำหรับการมีอยู่ของวัตถุไม่แปรเปลี่ยนที่ดึงดูดที่ไม่ซ้ำกันในระบบพลวัตประเภทกว้าง[ 3 ] การวิจัยเชิงรุกใน NLDR มุ่งที่จะเปิดเผยแมนิโฟลด์การสังเกตที่เกี่ยวข้องกับระบบพลวัตเพื่อพัฒนาเทคนิคการสร้างแบบจำลอง[ 4 ]
เทคนิค การลดมิติแบบไม่เชิงเส้นที่โดดเด่นบางส่วน มีดังต่อไปนี้
แนวคิดสำคัญ
การทำแผนที่ของแซมมอน
การทำแผนที่ของ Sammonเป็นหนึ่งในเทคนิค NLDR ที่เก่าแก่และได้รับความนิยมมากที่สุด

แผนที่จัดระเบียบตนเอง
แผนที่จัดระเบียบตัวเอง (SOM หรือเรียกอีกอย่างว่าแผนที่โคโฮเนน ) และรูปแบบความน่าจะเป็นของ แผนที่ดังกล่าวคือการสร้าง แผนที่ภูมิประเทศ (GTM) ใช้การแสดงจุดในพื้นที่ฝังตัวเพื่อสร้างแบบจำลองตัวแปรแฝงโดยอาศัยการแมปแบบไม่เชิงเส้นจากพื้นที่ฝังตัวไปยังพื้นที่มิติสูง[ 6 ]เทคนิคเหล่านี้เกี่ยวข้องกับงานบนเครือข่ายความหนาแน่นซึ่งก็ใช้แบบจำลองความน่าจะเป็นแบบเดียวกัน
การวิเคราะห์ส่วนประกอบหลักของเคอร์เนล
อัลกอริทึมที่ใช้กันอย่างแพร่หลายที่สุดสำหรับการลดมิติอาจเป็นKernel PCA [ 7 ] PCAเริ่มต้นด้วยการคำนวณเมทริกซ์ความแปรปรวนร่วมของเมทริกซ์



จากนั้นจึงฉายข้อมูลลงบน เวกเตอร์ลักษณะเฉพาะ k ตัวแรก ของเมทริกซ์นั้น ในทางตรงกันข้าม KPCA เริ่มต้นด้วยการคำนวณเมทริกซ์ความแปรปรวนร่วมของข้อมูลหลังจากที่ถูกแปลงไปอยู่ในพื้นที่มิติที่สูงกว่า

จากนั้นจะฉายข้อมูลที่แปลงแล้วลงบน เวกเตอร์ลักษณะเฉพาะ k ตัวแรก ของเมทริกซ์นั้น เช่นเดียวกับ PCA โดยใช้เทคนิคเคอร์เนลเพื่อแยกการคำนวณส่วนใหญ่ออกไป ทำให้สามารถดำเนินการกระบวนการทั้งหมดได้โดยไม่ต้องคำนวณจริงแน่นอนว่าต้องเลือกให้มีเคอร์เนลที่สอดคล้องกันที่ทราบ น่าเสียดายที่การหาเคอร์เนลที่ดีสำหรับปัญหาที่กำหนดนั้นไม่ใช่เรื่องง่าย ดังนั้น KPCA จึงไม่ได้ผลลัพธ์ที่ดีกับบางปัญหาเมื่อใช้เคอร์เนลมาตรฐาน ตัวอย่างเช่น เป็นที่ทราบกันดีว่าทำงานได้ไม่ดีกับเคอร์เนลเหล่านี้บน แมนิโฟลด์ แบบม้วนสวิสอย่างไรก็ตาม เราสามารถมองวิธีการอื่น ๆ ที่ทำงานได้ดีในสถานการณ์ดังกล่าว (เช่น Laplacian Eigenmaps, LLE) เป็นกรณีพิเศษของ PCA แบบเคอร์เนลโดยการสร้างเมทริกซ์เคอร์เนลที่ขึ้นอยู่กับข้อมูล[ 8 ]


KPCA มีโมเดลภายใน จึงสามารถใช้ในการแมปจุดต่างๆ ลงบนเวกเตอร์ฝังตัว (embedding) ที่ไม่มีอยู่ในระหว่างการฝึกอบรมได้
เส้นโค้งหลักและแมนิโฟลด์

เส้นโค้งหลักและแมนิโฟลด์ให้กรอบเรขาคณิตตามธรรมชาติสำหรับการลดมิติแบบไม่เชิงเส้น และขยายการตีความทางเรขาคณิตของ PCA โดยการสร้างแมนิโฟลด์ฝังตัวอย่างชัดเจน และโดยการเข้ารหัสโดยใช้การฉายภาพทางเรขาคณิตมาตรฐานลงบนแมนิโฟลด์ แนวทางนี้ได้รับการเสนอครั้งแรกโดย Trevor Hastieในวิทยานิพนธ์ปี 1984 ของเขา [ 11 ]ซึ่งเขาได้นำเสนออย่างเป็นทางการในปี 1989 [ 12 ]แนวคิดนี้ได้รับการสำรวจเพิ่มเติมโดยผู้เขียนหลายคน [ 13 ] วิธีการกำหนด "ความเรียบง่าย" ของแมนิโฟลด์นั้นขึ้นอยู่กับปัญหา อย่างไรก็ตาม โดยทั่วไปจะวัดจากมิติที่แท้จริงและ/หรือความเรียบของแมนิโฟลด์ โดยปกติ แมนิโฟลด์หลักจะถูกกำหนดให้เป็นคำตอบของปัญหาการเพิ่มประสิทธิภาพ ฟังก์ชันวัตถุประสงค์ประกอบด้วยคุณภาพของการประมาณข้อมูลและเงื่อนไขการลงโทษบางอย่างสำหรับการโค้งงอของแมนิโฟลด์ การประมาณค่าเริ่มต้นที่นิยมนั้นสร้างขึ้นโดย PCA เชิงเส้นและ SOM ของ Kohonen
แผนที่ค่าลักษณะเฉพาะของลาปลาเซียน
แผนที่ไอเกนลาปลาเซียนใช้เทคนิคสเปกตรัมในการลดมิติ[ 14 ]เทคนิคนี้อาศัยสมมติฐานพื้นฐานที่ว่าข้อมูลอยู่ในแมนิโฟลด์มิติต่ำในพื้นที่มิติสูง[ 15 ] อัลกอริทึมนี้ไม่สามารถฝังจุดนอกตัวอย่างได้ แต่มีเทคนิคที่ใช้ การปรับค่า พื้นที่ฮิลเบิร์ตเคอร์เนลแบบสร้างซ้ำเพื่อเพิ่มความสามารถนี้[ 16 ] เทคนิคดังกล่าวสามารถนำไปใช้กับอัลกอริทึมการลดมิติแบบไม่เชิงเส้นอื่นๆ ได้เช่นกัน
เทคนิคแบบดั้งเดิม เช่น การวิเคราะห์ส่วนประกอบหลัก (Principal Component Analysis: PMC) ไม่ได้พิจารณาเรขาคณิตที่แท้จริงของข้อมูล แผนที่ค่าลักษณะเฉพาะของลาปลาเซียน (Laplacian eigenmaps) สร้างกราฟจากข้อมูลบริเวณใกล้เคียงของชุดข้อมูล จุดข้อมูลแต่ละจุดทำหน้าที่เป็นโหนดบนกราฟ และการเชื่อมต่อระหว่างโหนดถูกควบคุมโดยความใกล้เคียงของจุดข้างเคียง (เช่น โดยใช้อัลกอริธึมเพื่อนบ้านที่ใกล้ที่สุด k ตัว ) กราฟที่สร้างขึ้นนี้สามารถพิจารณาได้ว่าเป็นค่าประมาณแบบไม่ต่อเนื่องของแมนิโฟลด์มิติที่ต่ำกว่าในพื้นที่มิติสูง การลดค่าฟังก์ชันต้นทุนโดยอิงจากกราฟทำให้มั่นใจได้ว่าจุดที่อยู่ใกล้กันบนแมนิโฟลด์จะถูกแมปให้ใกล้กันในพื้นที่มิติที่ต่ำกว่า โดยรักษาระยะทางเฉพาะที่ไว้ ฟังก์ชันลักษณะเฉพาะของตัวดำเนินการลาปลาเซียน-เบลตรามีบนแมนิโฟลด์ทำหน้าที่เป็นมิติการฝังตัว เนื่องจากภายใต้เงื่อนไขที่ไม่รุนแรง ตัวดำเนินการนี้มีสเปกตรัมที่นับได้ซึ่งเป็นพื้นฐานสำหรับฟังก์ชันที่สามารถหาปริพันธ์กำลังสองได้บนแมนิโฟลด์ (เปรียบเทียบกับอนุกรมฟูริเยร์บน แมนิโฟลด์ วงกลมหน่วย ) ความพยายามที่จะวางแผนที่ไอเกนลาปลาเซียนบนพื้นฐานทฤษฎีที่มั่นคงประสบความสำเร็จบ้าง เนื่องจากภายใต้สมมติฐานที่ไม่จำกัดบางประการ เมทริกซ์ลาปลาเซียน กราฟ ได้รับการแสดงให้เห็นว่าลู่เข้าสู่ตัวดำเนินการลาปลาเซียน-เบลทรามีเมื่อจำนวนจุดเข้าสู่อนันต์[ 15 ]
ไอโซแมป
Isomap [ 17 ]เป็นการผสมผสานระหว่างอัลกอริทึม Floyd–WarshallกับMultidimensional Scaling (MDS) แบบคลาสสิก MDS แบบคลาสสิกใช้เมทริกซ์ระยะทางแบบคู่ระหว่างจุดทั้งหมดและคำนวณตำแหน่งสำหรับแต่ละจุด Isomap สมมติว่าระยะทางแบบคู่เป็นที่ทราบเฉพาะระหว่างจุดที่อยู่ใกล้เคียงกันเท่านั้น และใช้อัลกอริทึม Floyd–Warshall เพื่อคำนวณระยะทางแบบคู่ระหว่างจุดอื่นๆ ทั้งหมด ซึ่งเป็นการประมาณเมทริกซ์ระยะทางแบบ geodesic แบบคู่ ระหว่างจุดทั้งหมดอย่างมีประสิทธิภาพ จากนั้น Isomap จะใช้ MDS แบบคลาสสิกเพื่อคำนวณตำแหน่งมิติที่ลดลงของจุดทั้งหมด Landmark-Isomap เป็นรูปแบบหนึ่งของอัลกอริทึมนี้ที่ใช้แลนด์มาร์คเพื่อเพิ่มความเร็วโดยแลกกับความแม่นยำที่ลดลง
ในการเรียนรู้แบบแมนิโฟลด์ ข้อมูลอินพุตจะถูกสมมติว่าได้มาจากการสุ่มตัวอย่างจากแมนิโฟลด์ มิติที่ต่ำกว่า ซึ่งฝังอยู่ภายในปริภูมิเวกเตอร์มิติที่สูงกว่า แนวคิดหลักเบื้องหลัง MVU คือการใช้ประโยชน์จากความเป็นเส้นตรงเฉพาะที่ของแมนิโฟลด์ และสร้างการแมปที่รักษาความสัมพันธ์ในบริเวณใกล้เคียงเฉพาะที่ในทุกจุดของแมนิโฟลด์พื้นฐาน
การฝังเชิงเส้นเฉพาะที่
การฝังเชิงเส้นเฉพาะที่ (Locally-linear Embeddingหรือ LLE) ได้รับการนำเสนอในเวลาใกล้เคียงกับ Isomap [ 18 ] LLE มีข้อดีหลายประการเหนือ Isomap รวมถึงการเพิ่มประสิทธิภาพที่เร็วกว่าเมื่อนำไปใช้เพื่อใช้ประโยชน์จาก อัลกอริธึม เมทริกซ์แบบเบาบางและผลลัพธ์ที่ดีกว่าสำหรับปัญหาหลายอย่าง LLE เริ่มต้นด้วยการค้นหาชุดของเพื่อนบ้านที่ใกล้ที่สุดของแต่ละจุด จากนั้นคำนวณชุดของน้ำหนักสำหรับแต่ละจุดที่อธิบายจุดนั้นได้ดีที่สุดในรูปแบบของการรวมเชิงเส้นของเพื่อนบ้าน สุดท้าย ใช้เทคนิคการเพิ่มประสิทธิภาพตามเวกเตอร์ลักษณะเฉพาะเพื่อค้นหาการฝังจุดในมิติที่ต่ำกว่า เพื่อให้แต่ละจุดยังคงถูกอธิบายด้วยการรวมเชิงเส้นของเพื่อนบ้านแบบเดียวกัน LLE มีแนวโน้มที่จะจัดการกับความหนาแน่นของตัวอย่างที่ไม่สม่ำเสมอได้ไม่ดี เนื่องจากไม่มีหน่วยคงที่ที่จะป้องกันไม่ให้น้ำหนักเปลี่ยนแปลงไปตามความหนาแน่นของตัวอย่างที่แตกต่างกันในแต่ละภูมิภาค LLE ไม่มีแบบจำลองภายใน
จุดข้อมูลดั้งเดิมและเป้าหมายของ LLE คือการฝังแต่ละจุดลงในจุดที่มีมิติต่ำกว่าโดย ที่




LLE ประกอบด้วยสองขั้นตอน ใน ขั้นตอน แรกจะคำนวณค่าประมาณที่ดีที่สุดของX i สำหรับแต่ละจุด X iโดยอิงจากพิกัดแบรีเซนทริกของจุดข้างเคียงX jจุดเดิมจะถูกสร้างขึ้นใหม่โดยประมาณด้วยการรวมเชิงเส้น ซึ่งกำหนดโดยเมทริกซ์น้ำหนักW ijของจุดข้างเคียง ข้อผิดพลาดในการสร้างใหม่คือ:

ค่าน้ำหนักW ijหมายถึงปริมาณการมีส่วนร่วมของจุดX jในการสร้างจุดX i ขึ้นใหม่ ฟังก์ชันต้นทุนจะถูกทำให้มีค่าน้อยที่สุดภายใต้ข้อจำกัดสองประการ:
- จุดข้อมูลX i แต่ละจุด จะถูกสร้างขึ้นใหม่จากจุดข้างเคียงเท่านั้น กล่าวคือถ้าจุดX jไม่ใช่จุดข้างเคียงของจุดX i
- ผลรวมของทุกแถวในเมทริกซ์น้ำหนักเท่ากับ 1 นั่นคือ.


ข้อจำกัดทั้งสองนี้ทำให้มั่นใจได้ว่าค่าจะไม่ได้รับผลกระทบจากการหมุนและการเลื่อน

ใน ขั้นตอน ที่สองจะสร้างแผนที่อนุรักษ์พื้นที่ใกล้เคียงโดยอิงจากค่าน้ำหนัก โดยแต่ละจุดจะถูกแมปไปยังจุดอื่นโดยลดต้นทุนอีกส่วนหนึ่งให้เหลือน้อยที่สุด:

แตกต่างจากฟังก์ชันต้นทุนก่อนหน้านี้ น้ำหนัก W ijจะคงที่ และการหาค่าต่ำสุดจะทำที่จุด Y iเพื่อปรับพิกัดให้เหมาะสม ปัญหาการหาค่าต่ำสุดนี้สามารถแก้ไขได้โดยการแก้ปัญหาค่าลักษณะเฉพาะ แบบเบาบาง N x N ( โดยที่ Nคือจำนวนจุดข้อมูล) ซึ่ง เวกเตอร์ลักษณะเฉพาะที่ไม่เป็นศูนย์ d ตัวล่าง สุดจะให้ชุดพิกัดแบบตั้งฉาก
พารามิเตอร์เดียวในอัลกอริทึมคือสิ่งที่นับว่าเป็น "เพื่อนบ้าน" ของจุด โดยทั่วไปแล้ว จุดข้อมูลจะถูกสร้างขึ้นใหม่จาก เพื่อนบ้านที่ใกล้ที่สุด K จุด ซึ่งวัดโดยระยะทางแบบยูคลิดในกรณีนี้ อัลกอริทึมมีพารามิเตอร์ค่าจำนวนเต็มเพียงค่าเดียวคือKซึ่งสามารถเลือกได้โดยการตรวจสอบแบบไขว้ (cross validation)
การฝังเชิงเส้นเฉพาะที่ของเมทริกซ์เฮสเซียน (Hessian LLE)
เช่นเดียวกับ LLE, Hessian LLEก็ใช้เทคนิคเมทริกซ์แบบเบาบางเช่นกัน[ 19 ]มีแนวโน้มที่จะให้ผลลัพธ์ที่มีคุณภาพสูงกว่า LLE มาก น่าเสียดายที่มีความซับซ้อนในการคำนวณสูงมาก ดังนั้นจึงไม่เหมาะสำหรับแมนิโฟลด์ที่มีการสุ่มตัวอย่างจำนวนมาก และไม่มีแบบจำลองภายใน
การฝังเชิงเส้นเฉพาะที่แบบดัดแปลง (MLLE)
LLE ที่ได้รับการดัดแปลง (MLLE) [ 20 ]เป็น LLE รูปแบบอื่นที่ใช้น้ำหนักหลายตัวในแต่ละบริเวณใกล้เคียงเพื่อแก้ไขปัญหาการปรับสภาพเมทริกซ์น้ำหนักเฉพาะที่ซึ่งนำไปสู่การบิดเบือนในแผนที่ LLE กล่าวโดยคร่าวๆ น้ำหนักหลายตัวคือการฉายภาพเชิงตั้งฉาก เฉพาะที่ ของน้ำหนักดั้งเดิมที่สร้างโดย LLE ผู้สร้างรูปแบบที่มีการควบคุมนี้ยังเป็นผู้เขียน Local Tangent Space Alignment (LTSA) ซึ่งแฝงอยู่ในสูตร MLLE เมื่อตระหนักว่าการปรับให้เหมาะสมทั่วโลกของการฉายภาพเชิงตั้งฉากของเวกเตอร์น้ำหนักแต่ละตัวนั้น โดยพื้นฐานแล้วจะจัดเรียงพื้นที่สัมผัสเฉพาะที่ของจุดข้อมูลทุกจุด ผลกระทบทางทฤษฎีและเชิงประจักษ์จากการประยุกต์ใช้อัลกอริทึมนี้อย่างถูกต้องนั้นกว้างขวางมาก[ 21 ]
การจัดเรียงพื้นที่สัมผัสเฉพาะที่
LTSA [ 22 ]อิงตามสัญชาตญาณที่ว่าเมื่อแมนิโฟลด์ถูกคลี่ออกอย่างถูกต้อง ไฮเปอร์เพลนสัมผัสทั้งหมดของแมนิโฟลด์จะเรียงตัวกัน โดยเริ่มจากการคำนวณ เพื่อนบ้านที่ใกล้ที่สุด kตัวของทุกจุด จากนั้นคำนวณปริภูมิสัมผัสที่ทุกจุดโดยการคำนวณ ส่วนประกอบหลัก dตัวแรกในแต่ละบริเวณใกล้เคียง จากนั้นจึงปรับให้เหมาะสมเพื่อค้นหาการฝังตัวที่จัดเรียงปริภูมิสัมผัส
การคลี่คลายความแปรปรวนสูงสุด
Maximum Variance Unfolding , Isomap และ Locally Linear Embedding มีหลักการพื้นฐานร่วมกัน โดยอาศัยแนวคิดที่ว่า หากแมนิโฟลด์ถูกคลี่ออกอย่างเหมาะสม ความแปรปรวนของจุดต่างๆ จะมีค่าสูงสุด ขั้นตอนแรกของมัน เช่นเดียวกับ Isomap และ Locally Linear Embedding คือการหา เพื่อนบ้านที่ใกล้ที่สุด kจุดของทุกจุด จากนั้นจึงพยายามแก้ปัญหาการเพิ่มระยะห่างระหว่างจุดที่ไม่ใช่เพื่อนบ้านทั้งหมดให้สูงสุด โดยมีข้อจำกัดว่าระยะห่างระหว่างเพื่อนบ้านจะต้องคงที่ ส่วนสำคัญที่สุดของอัลกอริทึมนี้คือเทคนิคในการแปลงปัญหานี้ให้เป็น ปัญหา การเขียนโปรแกรมเชิงกึ่งกำหนด (semidefinite programming ) แต่โชคร้ายที่ตัวแก้ปัญหาการเขียนโปรแกรมเชิงกึ่งกำหนดนั้นมีต้นทุนการคำนวณสูง เช่นเดียวกับ Locally Linear Embedding มันไม่มีแบบจำลองภายใน
ตัวเข้ารหัสอัตโนมัติ
ออโตเอนโคเดอร์ เป็น โครงข่ายประสาทแบบฟีดฟอร์เวิร์ดที่ได้รับการฝึกฝนให้ประมาณฟังก์ชันเอกลักษณ์ กล่าวคือ ได้รับการฝึกฝนให้แมปจากเวกเตอร์ของค่าไปยังเวกเตอร์เดียวกัน เมื่อใช้เพื่อวัตถุประสงค์ในการลดมิติ หนึ่งในเลเยอร์ที่ซ่อนอยู่ของโครงข่ายจะถูกจำกัดให้มีหน่วยโครงข่ายเพียงจำนวนเล็กน้อย ดังนั้น โครงข่ายจะต้องเรียนรู้ที่จะเข้ารหัสเวกเตอร์เป็นมิติจำนวนเล็กน้อยแล้วถอดรหัสกลับไปยังพื้นที่เดิม ดังนั้น ครึ่งแรกของโครงข่ายจึงเป็นแบบจำลองที่แมปจากพื้นที่มิติสูงไปยังพื้นที่มิติต่ำ และครึ่งหลังแมปจากพื้นที่มิติต่ำไปยังพื้นที่มิติสูง แม้ว่าแนวคิดของออโตเอนโคเดอร์จะค่อนข้างเก่า[ 23 ] แต่ การฝึกฝนออโตเอนโคเดอร์เชิงลึกเพิ่งเป็นไปได้เมื่อไม่นานมานี้ผ่านการใช้เครื่องจักร Boltzmann ที่จำกัด และออโตเอนโคเดอร์ลดสัญญาณรบกวนแบบเรียงซ้อน อัลกอริทึม NeuroScaleที่เกี่ยวข้องกับออโตเอนโคเดอร์ ใช้ฟังก์ชันความเครียดที่ได้รับแรงบันดาลใจจากการปรับขนาดหลายมิติและการแมป Sammon (ดูด้านบน) เพื่อเรียนรู้การแมปแบบไม่เชิงเส้นจากมิติสูงไปยังพื้นที่ฝังตัว การแมปใน NeuroScale นั้นอิงตามเครือข่ายฟังก์ชันฐานรัศมี (radial basis function networks )
แบบจำลองตัวแปรแฝงกระบวนการเกาส์เซียน
แบบจำลองตัวแปรแฝงกระบวนการเกาส์เซียน (GPLVM) [ 24 ]เป็นวิธีการลดมิติเชิงความน่าจะเป็นที่ใช้กระบวนการเกาส์เซียน (GP) เพื่อค้นหาการฝังแบบไม่เชิงเส้นที่มีมิติต่ำกว่าของข้อมูลที่มีมิติสูง เป็นส่วนขยายของการกำหนดสูตรเชิงความน่าจะเป็นของ PCA แบบจำลองถูกกำหนดในเชิงความน่าจะเป็น จากนั้นตัวแปรแฝงจะถูกหาค่าเฉลี่ยและพารามิเตอร์จะได้รับโดยการเพิ่มความน่าจะเป็นสูงสุด เช่นเดียวกับ PCA แบบเคอร์เนล พวกมันใช้ฟังก์ชันเคอร์เนลเพื่อสร้างการแมปแบบไม่เชิงเส้น (ในรูปแบบของกระบวนการเกาส์เซียน ) อย่างไรก็ตาม ใน GPLVM การแมปจะมาจากพื้นที่ฝังตัว (แฝง) ไปยังพื้นที่ข้อมูล (เช่น เครือข่ายความหนาแน่นและ GTM) ในขณะที่ใน PCA แบบเคอร์เนลจะเป็นไปในทิศทางตรงกันข้าม เดิมทีเสนอขึ้นเพื่อการแสดงภาพข้อมูลที่มีมิติสูง แต่ได้ขยายเพื่อสร้างแบบจำลองแมนิโฟลด์ร่วมระหว่างพื้นที่การสังเกตสองพื้นที่ GPLVM และรูปแบบต่างๆ มากมายได้รับการเสนอขึ้นโดยเฉพาะสำหรับการสร้างแบบจำลองการเคลื่อนไหวของมนุษย์ เช่น GPLVM ที่ถูกจำกัดด้านหลัง, แบบจำลองไดนามิก GP (GPDM), GPDM ที่สมดุล (B-GPDM) และ GPDM ที่ถูกจำกัดทางโทโพโลยี เพื่อจับภาพผลกระทบของการเชื่อมโยงของแมนิโฟลด์ท่าทางและการเดินในการวิเคราะห์การเดิน จึงมีการเสนอแมนิโฟลด์ท่าทางและการเดินร่วมหลายชั้น[ 25 ]
อัลกอริทึมอื่นๆ
แผนที่มุมมองเชิงสัมพันธ์
แผนที่มุมมองเชิงสัมพันธ์ (Relational perspective map) เป็น อัลกอริธึม การปรับขนาดหลายมิติ (Multidimensional scaling algorithm) อัลกอริธึมนี้ค้นหาการจัดเรียงจุดข้อมูลบนแมนิโฟลด์โดยการจำลองระบบไดนามิกหลายอนุภาคบนแมนิโฟลด์ปิด ซึ่งจุดข้อมูลจะถูกแมปไปยังอนุภาค และระยะทาง (หรือความแตกต่าง) ระหว่างจุดข้อมูลแสดงถึงแรงผลัก เมื่อแมนิโฟลด์ค่อยๆ ขยายขนาด ระบบหลายอนุภาคจะค่อยๆ เย็นลงและลู่เข้าสู่การจัดเรียงที่สะท้อนข้อมูลระยะทางของจุดข้อมูล
แผนผังมุมมองเชิงสัมพันธ์ได้รับแรงบันดาลใจจากแบบจำลองทางฟิสิกส์ที่อนุภาคประจุบวกเคลื่อนที่อย่างอิสระบนพื้นผิวของลูกบอล โดยอาศัยแรงคูลอมบ์ ระหว่างอนุภาค การจัดเรียงพลังงานต่ำสุดของอนุภาคจะสะท้อนถึงความแรงของแรงผลักระหว่างอนุภาค
แผนที่มุมมองเชิงสัมพันธ์ได้รับการแนะนำใน[ 26 ] อัลกอริทึมนี้ใช้ทอรัสแบนเป็นแมนิโฟลด์ภาพก่อน จากนั้นจึงได้รับการขยาย (ในซอฟต์แวร์VisuMap)ให้ใช้แมนิโฟลด์ปิดประเภทอื่น เช่นทรงกลมพื้นที่ฉายและขวดไคลน์เป็นแมนิโฟลด์ภาพ
แผนที่แสดงการแพร่ระบาด
แผนที่การแพร่กระจายใช้การแพร่กระจายหลายครั้งบนเครือข่ายเพื่อแมปโหนดเป็นกลุ่มจุด[ 27 ]ในกรณีของแบบจำลองการแพร่กระจายทั่วโลกความเร็วของการแพร่กระจายสามารถปรับได้ด้วยพารามิเตอร์เกณฑ์สำหรับแผนที่การแพร่กระจายนั้นเทียบเท่ากับอัลกอริธึม Isomap
![{\displaystyle t\in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31a5c18739ff04858eecc8fec2f53912c348e0e5)

การวิเคราะห์ส่วนประกอบโค้ง
การวิเคราะห์ส่วนประกอบแบบโค้ง (CCA) จะมองหาการกำหนดค่าของจุดในพื้นที่เอาต์พุตที่รักษาระยะทางเดิมไว้ให้มากที่สุดเท่าที่จะเป็นไปได้ โดยเน้นที่ระยะทางเล็กๆ ในพื้นที่เอาต์พุต (ตรงกันข้ามกับการแมปของ Sammonซึ่งเน้นที่ระยะทางเล็กๆ ในพื้นที่เดิม) [ 28 ]
ควรสังเกตว่า CCA ซึ่งเป็นอัลกอริธึมการเรียนรู้แบบวนซ้ำ เริ่มต้นด้วยการเน้นที่ระยะทางไกลๆ (เช่นเดียวกับอัลกอริธึม Sammon) จากนั้นค่อยๆ เปลี่ยนไปเน้นที่ระยะทางสั้นๆ ข้อมูลระยะทางสั้นๆ จะเขียนทับข้อมูลระยะทางไกลๆ หากจำเป็นต้องมีการประนีประนอมระหว่างทั้งสอง
ฟังก์ชันความเครียดของ CCA เกี่ยวข้องกับผลรวมของความแตกต่าง Bregman ด้านขวา[ 29 ]
การวิเคราะห์ระยะทางโค้ง
CDA [ 28 ]ฝึกเครือข่ายประสาทแบบจัดระเบียบตนเองให้เข้ากับแมนิโฟลด์และพยายามรักษาระยะทางจีโอเดสิกในการฝังตัว โดยอิงจากการวิเคราะห์ส่วนประกอบโค้ง (ซึ่งขยายการแมปของ Sammon) แต่ใช้ระยะทางจีโอเดสิกแทน
การลดมิติแบบดิฟฟีโอเมอร์ฟิก
การลดมิติแบบ ดิฟฟีโอเมอร์ฟิกหรือดิฟฟีโอแมป[ 30 ]เรียนรู้การแมปแบบดิฟฟีโอเมอร์ฟิกที่ราบเรียบซึ่งถ่ายโอนข้อมูลไปยังพื้นที่ย่อยเชิงเส้นที่มีมิติต่ำกว่า วิธีการนี้แก้ปัญหาสำหรับฟิลด์เวกเตอร์ดัชนีเวลาที่ราบเรียบ โดยที่การไหลตามฟิลด์ซึ่งเริ่มต้นที่จุดข้อมูลจะสิ้นสุดที่พื้นที่ย่อยเชิงเส้นที่มีมิติต่ำกว่า จึงพยายามรักษาความแตกต่างระหว่างคู่ภายใต้การแมปทั้งแบบไปข้างหน้าและแบบย้อนกลับ
การจัดเรียงท่อร่วม
การจัดเรียงแมนิโฟลด์ใช้ประโยชน์จากสมมติฐานที่ว่าชุดข้อมูลที่แตกต่างกันซึ่งสร้างขึ้นโดยกระบวนการสร้างที่คล้ายกันจะมีการแสดงแมนิโฟลด์พื้นฐานที่คล้ายกัน โดยการเรียนรู้การฉายภาพจากพื้นที่ดั้งเดิมแต่ละแห่งไปยังแมนิโฟลด์ที่ใช้ร่วมกัน จะสามารถกู้คืนการจับคู่ได้ และความรู้จากโดเมนหนึ่งสามารถถ่ายโอนไปยังอีกโดเมนหนึ่งได้ เทคนิคการจัดเรียงแมนิโฟลด์ส่วนใหญ่พิจารณาเพียงสองชุดข้อมูล แต่แนวคิดนี้ขยายไปถึงชุดข้อมูลเริ่มต้นจำนวนมากได้ตามต้องการ[ 31 ]
แผนที่การแพร่กระจาย
แผนที่การแพร่กระจายใช้ประโยชน์จากความสัมพันธ์ระหว่างการแพร่กระจาย ความร้อน และการเดินแบบสุ่ม ( ห่วงโซ่มาร์คอฟ ) โดยมีการเปรียบเทียบระหว่างตัวดำเนินการการแพร่กระจายบนแมนิโฟลด์และเมทริกซ์การเปลี่ยนผ่านของมาร์คอฟที่ดำเนินการกับฟังก์ชันที่กำหนดบนกราฟซึ่งโหนดถูกสุ่มตัวอย่างจากแมนิโฟลด์[ 32 ]โดยเฉพาะอย่างยิ่ง ให้ชุดข้อมูลแทนด้วย สมมติฐานพื้นฐานของแผนที่การแพร่กระจายคือข้อมูลมิติสูงอยู่บนแมนิโฟลด์มิติต่ำที่มีมิติให้Xแทนชุดข้อมูลและแทนการกระจายของจุดข้อมูลบนXนอกจากนี้ ให้กำหนดเคอร์เนลซึ่งแสดงถึงแนวคิดบางอย่างของความสัมพันธ์ของจุดในXเคอร์เนลมีคุณสมบัติดังต่อไปนี้[ 33 ]
![{\displaystyle \mathbf {X} =[x_{1},x_{2},\ldots ,x_{n}]\in \Omega \subset \mathbf {R^{D}} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/27767b00cc5714632b393ff3d9173e6eece42867)




kมีสมมาตร

kคือค่าที่รักษาความเป็นบวก
ดังนั้น เราอาจมองว่าจุดข้อมูลแต่ละจุดเป็นโหนดของกราฟ และเคอร์เนลkเป็นตัวกำหนดความสัมพันธ์บางอย่างบนกราฟนั้น กราฟมีความสมมาตรโดยโครงสร้าง เนื่องจากเคอร์เนลมีความสมมาตร จะเห็นได้ง่ายว่าจากคู่ ( X , k ) เราสามารถสร้างห่วงโซ่มาร์คอฟ แบบย้อนกลับได้ เทคนิคนี้พบได้ทั่วไปในหลายสาขาและเรียกว่า ลาปลาเซียนกราฟ
ตัวอย่างเช่น กราฟK = ( X , E ) สามารถสร้างขึ้นได้โดยใช้เคอร์เนลแบบเกาส์เซียน

ในสมการข้างต้นแสดงว่าเป็นเพื่อนบ้านที่ใกล้ที่สุดของตามหลักการแล้วควรใช้ระยะทางจี โอเดสิกในการวัดระยะทางบน แมนิโฟลด์เนื่องจากโครงสร้างที่แน่นอนของแมนิโฟลด์นั้นไม่มีอยู่ สำหรับเพื่อนบ้านที่ใกล้ที่สุด ระยะทางจีโอเดสิกจะถูกประมาณด้วยระยะทางยุคลิด การเลือกนี้ปรับเปลี่ยนแนวคิดเรื่องความใกล้ชิดของเราในแง่ที่ว่า ถ้าแล้วและถ้าแล้วแบบแรกหมายความว่าการแพร่กระจายเกิดขึ้นน้อยมาก ในขณะที่แบบหลังหมายความว่ากระบวนการแพร่กระจายเกือบสมบูรณ์ กลยุทธ์ที่แตกต่างกันในการเลือกสามารถพบได้ใน[ 34 ]








เพื่อให้สามารถแสดงเมทริกซ์มาร์คอฟได้อย่างถูกต้อง เมทริกซ์นั้นจะต้องถูกทำให้เป็นมาตรฐานโดยใช้เมทริกซ์ดีกรี ที่สอดคล้องกัน :



ในที่นี้แสดงถึงห่วงโซ่มาร์คอฟคือความน่าจะเป็นของการเปลี่ยนสถานะจากไปในหนึ่งช่วงเวลา ในทำนองเดียวกัน ความน่าจะเป็นของการเปลี่ยนสถานะจากไปในtช่วงเวลา จะกำหนดโดย โดยที่คือเมทริกซ์ที่คูณตัวเองtครั้ง




เมทริกซ์มาร์คอฟแสดงถึงแนวคิดเกี่ยวกับเรขาคณิตเฉพาะที่ของชุดข้อมูลXความแตกต่างที่สำคัญระหว่างแผนที่การแพร่กระจายและการวิเคราะห์ส่วนประกอบหลักคือ แผนที่การแพร่กระจายจะพิจารณาเฉพาะคุณลักษณะเฉพาะที่ของข้อมูลเท่านั้น ในขณะที่การวิเคราะห์ส่วนประกอบหลักจะพิจารณาความสัมพันธ์ของชุดข้อมูลทั้งหมด
กำหนดการเดินแบบสุ่มบนชุดข้อมูล ซึ่งหมายความว่าเคอร์เนลจะจับเรขาคณิตเฉพาะที่ของชุดข้อมูล ห่วงโซ่มาร์คอฟกำหนดทิศทางการแพร่กระจายอย่างรวดเร็วและช้าผ่านค่าเคอร์เนล เมื่อการเดินแพร่กระจายไปข้างหน้าตามเวลา ข้อมูลเรขาคณิตเฉพาะที่จะถูกรวบรวมในลักษณะเดียวกับการเปลี่ยนผ่านเฉพาะที่ (กำหนดโดยสมการเชิงอนุพันธ์) ของระบบไดนามิก[ 33 ]อุปมาอุปไมยของการแพร่กระจายเกิดขึ้นจากคำจำกัดความของระยะการแพร่กระจายของครอบครัว


สำหรับค่า t ที่กำหนดไว้ ค่านี้ จะกำหนดระยะห่างระหว่างจุดสองจุดใดๆ ในชุดข้อมูลโดยพิจารณาจากการเชื่อมต่อของเส้นทาง: ค่าของมันจะเล็กลงเมื่อมีเส้นทางเชื่อมต่อxกับy มากขึ้น และในทางกลับกัน เนื่องจากปริมาณนี้เกี่ยวข้องกับผลรวมของเส้นทางทั้งหมดที่มีความยาว t จึงมีความทนทานต่อสัญญาณรบกวนในข้อมูลมากกว่าระยะทางแบบจีโอเดสิก ค่านี้จะคำนึงถึงความสัมพันธ์ทั้งหมดระหว่างจุด x และ y ในการคำนวณระยะทาง และให้แนวคิดเรื่องความใกล้เคียงที่ดีกว่าระยะทางแบบยูคลิดหรือแม้แต่ระยะทางแบบจีโอเดสิก


การปรับขนาดหลายมิติในระดับท้องถิ่น
การปรับขนาดหลายมิติแบบท้องถิ่นจะทำการปรับขนาดหลายมิติในบริเวณท้องถิ่น จากนั้นใช้การปรับให้เหมาะสมแบบนูนเพื่อประกอบชิ้นส่วนทั้งหมดเข้าด้วยกัน[ 35 ]
PCA แบบไม่เชิงเส้น
Nonlinear PCA (NLPCA) ใช้backpropagationเพื่อฝึก perceptron หลายชั้น (MLP) ให้เข้ากับ manifold [ 36 ]แตกต่างจากการฝึก MLP ทั่วไปซึ่งอัปเดตเฉพาะน้ำหนักเท่านั้น NLPCA จะอัปเดตทั้งน้ำหนักและอินพุต กล่าวคือ ทั้งน้ำหนักและอินพุตถือเป็นค่าแฝง หลังจากฝึกแล้ว อินพุตแฝงจะเป็นการแสดงเวกเตอร์ที่สังเกตได้ในมิติที่ต่ำกว่า และ MLP จะแมปจากการแสดงในมิติที่ต่ำกว่านั้นไปยังพื้นที่การสังเกตในมิติที่สูงกว่า
การปรับขนาดมิติสูงที่ขับเคลื่อนด้วยข้อมูล
การปรับขนาดมิติสูงที่ขับเคลื่อนด้วยข้อมูล (DD-HDS) [ 37 ]มีความเกี่ยวข้องอย่างใกล้ชิดกับการทำแผนที่ของ Sammonและการวิเคราะห์ส่วนประกอบโค้ง ยกเว้นว่า (1) จะลงโทษเพื่อนบ้านที่ผิดพลาดและรอยฉีกขาดพร้อมกันโดยเน้นที่ระยะทางเล็กๆ ทั้งในพื้นที่ดั้งเดิมและพื้นที่เอาต์พุต และ (2) จะคำนึงถึง ปรากฏการณ์ ความเข้มข้นของการวัดโดยการปรับฟังก์ชันการถ่วงน้ำหนักให้เข้ากับการกระจายระยะทาง
การแกะสลักหลายชั้น
Manifold Sculpting [ 38 ]ใช้การปรับให้เหมาะสมแบบไล่ระดับเพื่อค้นหาการฝังตัว เช่นเดียวกับอัลกอริทึมอื่นๆ มันคำนวณ เพื่อนบ้านที่ใกล้ที่สุด kตัวและพยายามค้นหาการฝังตัวที่รักษาความสัมพันธ์ในละแวกใกล้เคียง มันค่อยๆ ปรับขนาดความแปรปรวนออกจากมิติที่สูงกว่า ในขณะเดียวกันก็ปรับจุดในมิติที่ต่ำกว่าเพื่อรักษาความสัมพันธ์เหล่านั้น หากอัตราการปรับขนาดมีขนาดเล็ก มันสามารถค้นหาการฝังตัวที่แม่นยำมากได้ มันมีความแม่นยำเชิงประจักษ์สูงกว่าอัลกอริทึมอื่นๆ ในหลายๆ ปัญหา นอกจากนี้ยังสามารถใช้เพื่อปรับปรุงผลลัพธ์จากอัลกอริทึมการเรียนรู้แมนิโฟลด์อื่นๆ ได้อีกด้วย อย่างไรก็ตาม มันมีปัญหาในการคลี่แมนิโฟลด์บางประเภท เว้นแต่จะใช้อัตราการปรับขนาดที่ช้ามาก มันไม่มีแบบจำลอง
อันดับวิสุ
RankVisu [ 39 ]ออกแบบมาเพื่อรักษาระดับของเพื่อนบ้านมากกว่าระยะทาง RankVisu มีประโยชน์อย่างยิ่งในงานที่ยาก (เมื่อไม่สามารถรักษาระยะทางได้อย่างน่าพอใจ) อันที่จริง ระดับของเพื่อนบ้านมีข้อมูลน้อยกว่าระยะทาง (สามารถอนุมานระดับจากระยะทางได้ แต่ไม่สามารถอนุมานระยะทางจากระดับได้) ดังนั้นการรักษาระดับจึงง่ายกว่า
การฝังไอโซเมตริกที่ถูกจำกัดทางโทโพโลยี
การฝังไอโซเมตริกที่ถูกจำกัดทางโทโพโลยี (TCIE) [ 40 ]เป็นอัลกอริทึมที่ใช้การประมาณระยะทางจีโอเดสิกหลังจากกรองจีโอเดสิกที่ไม่สอดคล้องกับเมตริกยูคลิด TCIE มุ่งแก้ไขความผิดเพี้ยนที่เกิดจากการใช้ Isomap ในการแมปข้อมูลที่ไม่นูนโดยเนื้อแท้ โดยใช้ MDS แบบกำลังสองน้อยที่สุดแบบถ่วงน้ำหนักเพื่อให้ได้การแมปที่แม่นยำยิ่งขึ้น อัลกอริทึม TCIE จะตรวจจับจุดขอบเขตที่เป็นไปได้ในข้อมูลก่อน และในระหว่างการคำนวณความยาวจีโอเดสิก จะทำเครื่องหมายจีโอเดสิกที่ไม่สอดคล้องกัน เพื่อกำหนดน้ำหนักเล็กน้อยในการเพิ่มความเครียด แบบถ่วงน้ำหนัก ที่ตามมา
การฝังเพื่อนบ้านแบบสุ่มที่กระจายแบบ t
การฝังเพื่อนบ้านแบบสุ่มที่กระจายแบบ t (t-SNE) [ 41 ]ถูกนำมาใช้กันอย่างแพร่หลาย เป็นหนึ่งในตระกูลของวิธีการฝังเพื่อนบ้านแบบสุ่ม อัลกอริทึมจะคำนวณความน่าจะเป็นที่คู่ของจุดข้อมูลในพื้นที่มิติสูงมีความสัมพันธ์กัน จากนั้นเลือกการฝังมิติที่ต่ำกว่าซึ่งสร้างการกระจายที่คล้ายกัน
การประมาณและการฉายภาพแมนิโฟลด์สม่ำเสมอ
การประมาณและการฉายภาพแมนิโฟลด์แบบสม่ำเสมอ (UMAP) เป็นเทคนิคการลดมิติแบบไม่เชิงเส้น[ 42 ]มันทำงานในลักษณะที่คล้ายกับ t-SNE [ 43 ] [ 44 ]โดยมีความแตกต่างหลักคือการเพิ่มเทอมผลักดันเพื่อย้ายจุดที่อยู่ห่างไกลออกจากกัน
วิธีการที่อิงตามเมทริกซ์ความใกล้เคียง
วิธีการที่ใช้เมทริกซ์ความใกล้เคียง คือวิธีการที่นำเสนอข้อมูลให้กับอัลกอริทึมในรูปแบบของเมทริกซ์ความคล้ายคลึงหรือเมทริกซ์ระยะทางวิธีการเหล่านี้ทั้งหมดจัดอยู่ในกลุ่มที่กว้างกว่าของการปรับขนาดหลายมิติเชิงเมตริกความแตกต่างมักอยู่ที่วิธีการคำนวณข้อมูลความใกล้เคียง ตัวอย่างเช่นisomap , การฝังเชิงเส้นเฉพาะที่ , การคลี่คลายความแปรปรวนสูงสุดและการทำแผนที่แซมมอน (ซึ่งไม่ใช่การทำแผนที่จริงๆ) เป็นตัวอย่างของวิธีการปรับขนาดหลายมิติเชิงเมตริก
ซอฟต์แวร์
- Wafflesเป็นไลบรารี C++ แบบโอเพนซอร์สที่ประกอบด้วยการใช้งาน LLE, Manifold Sculpting และอัลกอริธึมการเรียนรู้แมนิโฟลด์อื่นๆ
- UMAP.jlเป็นไลบรารีที่ใช้เมธอดนี้ในภาษาโปรแกรมJulia นอกจากนี้ยัง มีการพัฒนาเมธอดนี้ในภาษา Python ด้วย (โค้ดมีให้ดูได้ที่GitHub )
ดูเพิ่มเติม
- สมมติฐานหลายมิติ
- สเปกตรัมย่อย
- ทฤษฎีบทของทาเกน
- ทฤษฎีบทการฝังตัวของวิทนีย์
- การวิเคราะห์จำแนก
- แผนที่ยืดหยุ่น
- การเรียนรู้คุณลักษณะ
- แผนที่จัดระเบียบตนเองแบบเติบโต (GSOM)
- แผนที่จัดระเบียบตนเอง (SOM)
อ่านเพิ่มเติม
- Murphy, Kevin P. ( 2022). "การเรียนรู้แบบแมนิโฟลด์"การเรียนรู้ของเครื่องจักรเชิงความน่าจะเป็นสำนักพิมพ์ MIT หน้า 682–699 ISBN 978-0-262-04682-4.
ลิงก์ภายนอก
- ไอโซแมป
- การสร้างแผนที่ภูมิประเทศแบบสร้างสรรค์
- วิทยานิพนธ์ของไมค์ ทิปปิ้ง
- แบบจำลองตัวแปรแฝงกระบวนการเกาส์เซียน
- การฝังเชิงเส้นเฉพาะที่
- แผนที่มุมมองเชิงสัมพันธ์
- หน้าแรกของ DD-HDS
- หน้าแรกของ RankVisu
- บทสรุปสั้น ๆ เกี่ยวกับแผนที่การแพร่กระจาย
- PCA แบบไม่เชิงเส้นโดยเครือข่ายประสาทเข้ารหัสอัตโนมัติ
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ การลดมิติแบบไม่เชิงเส้น
การลดมิติแบบไม่เชิงเส้น (NLDR) หรือที่รู้จักกันในชื่อการเรียนรู้แมนิโฟลด์คือเทคนิคต่างๆ ที่เกี่ยวข้องซึ่งมีเป้าหมายเพื่อฉายภาพข้อมูลที่มีมิติสูง...
การประยุกต์ใช้ NLDR
ข้อมูลที่มีมิติสูงอาจเป็นเรื่องยากสำหรับเครื่องจักรในการประมวลผล เนื่องจากต้องใช้เวลาและพื้นที่ในการวิเคราะห์จำนวนมาก นอกจากนี้ยังเป็นความท้าทายสำหรับมนุษย์ด้วย เพราะเป็นการยากที่จะมองเห็นหรือทำความเข้าใจข้อมูลที่มีมากกว่าสามมิติ...
การทำแผนที่ของแซมมอน
การทำแผนที่ของ Sammon เป็นหนึ่งในเทคนิค NLDR ที่เก่าแก่และได้รับความนิยมมากที่สุด
แผนที่จัดระเบียบตนเอง
แผนที่ จัดระเบียบตัวเอง (SOM หรือเรียกอีกอย่างว่า แผนที่โคโฮเนน ) และรูปแบบความน่าจะเป็นของ แผนที่ดังกล่าวคือการสร้าง แผนที่ภูมิประเทศ (GTM) ใช้การแสดงจุดในพื้นที่ฝังตัวเพื่อสร้าง แบบจำลองตัวแปรแฝง...