อ่าน 25 นาที
อัลกอริทึมความคาดหวัง-การเพิ่มค่าสูงสุด
ในทางสถิติอัลกอริทึมการคาดการณ์-การเพิ่มค่าสูงสุด ( EM ) เป็นวิธีการวนซ้ำเพื่อค้นหา ค่าประมาณ ความน่าจะเป็นสูงสุด (เฉพาะที่) หรือ ค่าประมาณ ความน่าจะเป็นสูงสุดภายหลัง (MAP)
อัลกอริทึมความคาดหวัง-การเพิ่มค่าสูงสุด
| ส่วนหนึ่งของชุดบทความเกี่ยวกับ |
| การเรียนรู้ของเครื่องจักรและการขุดข้อมูล |
|---|
ในทางสถิติอัลกอริทึมการคาดการณ์-การเพิ่มค่าสูงสุด ( EM ) เป็นวิธีการวนซ้ำเพื่อค้นหา ค่าประมาณ ความน่าจะเป็นสูงสุด (เฉพาะที่) หรือ ค่าประมาณ ความน่าจะเป็นสูงสุดภายหลัง (MAP) ของพารามิเตอร์ในแบบจำลองทางสถิติโดยที่แบบจำลองขึ้นอยู่กับตัวแปรแฝง ที่ไม่สามารถสังเกตได้ [ 1 ]การวนซ้ำ EM จะสลับกันระหว่างการทำขั้นตอนการคาดการณ์ (E) ซึ่งสร้างฟังก์ชันสำหรับการคาดการณ์ของลอการิทึมความน่า จะ เป็นที่ประเมินโดยใช้ค่าประมาณปัจจุบันสำหรับพารามิเตอร์ และขั้นตอนการเพิ่มค่าสูงสุด (M) ซึ่งคำนวณพารามิเตอร์ที่เพิ่มค่าลอการิทึมความน่าจะเป็นที่คาดการณ์ไว้สูงสุดที่พบใน ขั้นตอน Eจากนั้นค่าประมาณพารามิเตอร์เหล่านี้จะถูกนำมาใช้เพื่อกำหนดการกระจายของตัวแปรแฝงในขั้นตอน E ถัดไป สามารถใช้เพื่อประมาณค่าผสมของเกาส์เซียนหรือเพื่อแก้ปัญหาการถดถอยเชิงเส้นหลายตัวแปรได้[ 2 ]

ประวัติศาสตร์
อัลกอริทึม EM ได้รับการอธิบายและตั้งชื่อในบทความคลาสสิกปี 1977 โดยArthur Dempster , Nan LairdและDonald Rubin [ 3 ] พวกเขาชี้ให้เห็นว่าวิธีการนี้ "ได้รับการเสนอหลายครั้งในสถานการณ์พิเศษ" โดยผู้เขียนก่อนหน้านี้ หนึ่งในวิธีแรกสุดคือวิธีการนับยีนเพื่อประมาณความถี่ของอัลลีลโดยCedric Smith [ 4 ] อีกวิธีหนึ่งได้รับการเสนอโดยHO Hartleyในปี 1958 และ Hartley และ Hocking ในปี 1977 ซึ่งเป็นที่มาของแนวคิดหลายอย่างในบทความของ Dempster–Laird–Rubin [ 5 ]อีกวิธีหนึ่งโดย SK Ng, Thriyambakam Krishnan และ GJ McLachlan ในปี 1977 [ 6 ]แนวคิดของ Hartley สามารถขยายไปสู่การแจกแจงแบบไม่ต่อเนื่องแบบกลุ่มใดๆ ก็ได้ Rolf Sundberg ได้ตีพิมพ์วิทยานิพนธ์และเอกสารหลายฉบับเกี่ยวกับการจัดการวิธี EM สำหรับตระกูลเลขชี้กำลังอย่างละเอียด[ 7 ] [ 8 ] [ 9 ]ซึ่งเป็นผลมาจากการทำงานร่วมกับPer Martin-LöfและAnders Martin-Löf [ 10 ] [ 11 ] [ 12 ] [ 13 ] [ 14 ] เอกสารของ Dempster–Laird–Rubin ในปี 1977 ได้ขยายวิธีการนี้และร่างการวิเคราะห์การลู่เข้าสำหรับปัญหาในวงกว้างขึ้น เอกสารของ Dempster–Laird–Rubin ได้กำหนดให้วิธี EM เป็นเครื่องมือสำคัญในการวิเคราะห์ทางสถิติ ดูเพิ่มเติมที่ Meng และ van Dyk (1997)
การวิเคราะห์การลู่เข้าของอัลกอริทึม Dempster–Laird–Rubin มีข้อบกพร่อง และการวิเคราะห์การลู่เข้าที่ถูกต้องได้รับการตีพิมพ์โดยCF Jeff Wuในปี 1983 [ 15 ] การพิสูจน์ของ Wu ยืนยันการลู่เข้าของวิธี EM นอกเหนือจากตระกูลเลขชี้กำลังตามที่ Dempster–Laird–Rubin อ้าง[ 15 ]
การแนะนำ
อัลกอริทึม EM ใช้เพื่อค้นหา พารามิเตอร์ ความน่าจะเป็นสูงสุด (เฉพาะที่) ของแบบจำลองทางสถิติในกรณีที่สมการไม่สามารถแก้ได้โดยตรง โดยทั่วไปแบบจำลองเหล่านี้เกี่ยวข้องกับตัวแปรแฝงนอกเหนือจากพารามิเตอร์ ที่ไม่ทราบค่า และข้อมูลที่ทราบแล้ว กล่าวคือ อาจ มี ค่าที่หายไปในข้อมูล หรือแบบจำลองสามารถกำหนดได้ง่ายขึ้นโดยการสมมติว่ามีจุดข้อมูลที่ไม่ถูกสังเกตเพิ่มเติม ตัวอย่างเช่นแบบจำลองแบบผสมสามารถอธิบายได้ง่ายขึ้นโดยการสมมติว่าแต่ละจุดข้อมูลที่สังเกตได้มีจุดข้อมูลที่ไม่ถูกสังเกตที่สอดคล้องกัน หรือตัวแปรแฝง ซึ่งระบุส่วนประกอบของการผสมที่แต่ละจุดข้อมูลเป็นของ
โดยทั่วไป การหาคำตอบที่มีความน่าจะเป็นสูงสุดนั้น จำเป็นต้องหาอนุพันธ์ของฟังก์ชันความน่าจะเป็นเทียบกับค่าที่ไม่ทราบค่าทั้งหมด ทั้งพารามิเตอร์และตัวแปรแฝง แล้วจึงแก้สมการที่ได้พร้อมกัน ในแบบจำลองทางสถิติที่มีตัวแปรแฝงนั้น วิธีนี้มักเป็นไปไม่ได้ ผลลัพธ์ที่ได้มักจะเป็นชุดสมการที่เกี่ยวพันกัน ซึ่งการหาคำตอบของพารามิเตอร์นั้นต้องการค่าของตัวแปรแฝง และในทางกลับกัน แต่การแทนค่าชุดสมการหนึ่งลงในอีกชุดสมการหนึ่งจะทำให้ได้สมการที่ไม่สามารถหาคำตอบได้
อัลกอริทึม EM ดำเนินไปจากการสังเกตว่ามีวิธีแก้สมการสองชุดนี้ในเชิงตัวเลขได้ เราสามารถเลือกค่าใดๆ สำหรับชุดตัวแปรที่ไม่ทราบค่าชุดใดชุดหนึ่ง ใช้ค่าเหล่านั้นเพื่อประมาณค่าชุดที่สอง จากนั้นใช้ค่าใหม่เหล่านี้เพื่อหาค่าประมาณที่ดีกว่าของชุดแรก แล้วสลับไปมาระหว่างสองชุดจนกว่าค่าที่ได้จะลู่เข้าสู่จุดคงที่ มันไม่ชัดเจนว่าวิธีนี้จะใช้ได้ผล แต่สามารถพิสูจน์ได้ในบริบทนี้ นอกจากนี้ ยังสามารถพิสูจน์ได้ว่าอนุพันธ์ของความน่าจะเป็นมีค่าเป็นศูนย์ (ใกล้เคียงศูนย์ตามอำเภอใจ) ณ จุดนั้น ซึ่งหมายความว่าจุดนั้นเป็นจุดสูงสุดเฉพาะที่หรือจุดอานม้า[ 15 ]โดยทั่วไป อาจมีจุดสูงสุดหลายจุดเกิดขึ้น โดยไม่มีการรับประกันว่าจะพบจุดสูงสุดทั่วโลก ความน่าจะเป็นบางอย่างยังมีจุดเอกฐานอยู่ด้วย เช่น จุดสูงสุดที่ไม่สมเหตุสมผล ตัวอย่างเช่น หนึ่งในวิธีแก้ปัญหาที่อาจพบได้โดย EM ในแบบจำลองผสม คือการกำหนดให้ส่วนประกอบหนึ่งมีค่าความแปรปรวนเป็นศูนย์ และกำหนดให้ค่าพารามิเตอร์เฉลี่ยของส่วนประกอบนั้นเท่ากับค่าของจุดข้อมูลจุดใดจุดหนึ่ง
คำอธิบาย
สัญลักษณ์
เมื่อกำหนดแบบจำลองทางสถิติที่สร้างชุดข้อมูลที่สังเกตได้ ชุดข้อมูลแฝงที่ไม่สามารถสังเกตได้หรือค่าที่หายไปและเวกเตอร์ของพารามิเตอร์ที่ไม่ทราบค่าพร้อมกับฟังก์ชันความน่าจะเป็นแล้วค่าประมาณความน่าจะเป็นสูงสุด (MLE) ของพารามิเตอร์ที่ไม่ทราบค่าจะถูกกำหนดโดยการเพิ่มค่าความน่าจะเป็นแบบมาร์จินัลของข้อมูลที่สังเกตได้ สูงสุด





อย่างไรก็ตาม ปริมาณนี้มักคำนวณได้ยาก เนื่องจากไม่สามารถสังเกตได้ และการกระจายตัวของก็ไม่เป็นที่ทราบก่อนที่จะถึงค่าที่กำหนด
อัลกอริทึม EM
อัลกอริทึม EM มุ่งค้นหาค่าประมาณความน่าจะเป็นสูงสุดของความน่าจะเป็นแบบมาร์จินัลโดยการประยุกต์ใช้สองขั้นตอนต่อไปนี้ซ้ำๆ:


ขั้นตอนการหาค่าสูงสุด (ขั้นตอน M) : ค้นหาพารามิเตอร์ที่ทำให้ปริมาณนี้มีค่าสูงสุด:
![{\displaystyle Q({\boldsymbol {\theta }}\mid {\boldsymbol {\theta }}^{(t)})=\operatorname {E} _{\mathbf {Z} \sim p(\cdot |\mathbf {X} ,{\boldsymbol {\theta }}^{(t)})}\left[\log p(\mathbf {X} ,\mathbf {Z} |{\boldsymbol {\theta }})\right]:=\int \log p(\mathbf {X} ,\mathbf {Z} |{\boldsymbol {\theta }})\,p(\mathbf {Z} |\mathbf {X} ,{\boldsymbol {\theta }}^{(t)})\,d\mathbf {Z} \,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6c377f1bac6a642a871448e818359fe59d531601)

กล่าวโดยสรุป เราสามารถเขียนได้ในรูปสมการเดียว:
![{\displaystyle {\boldsymbol {\theta }}^{(t+1)}=\mathop {\arg \max } _{\boldsymbol {\theta }}\operatorname {E} _{\mathbf {Z} \sim p(\cdot |\mathbf {X} ,{\boldsymbol {\theta }}^{(t)})}\left[\log p(\mathbf {X} ,\mathbf {Z} |{\boldsymbol {\theta }})\right]\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ec058e2b0ede250fb9126012988698cc33fca85)
การตีความตัวแปร
แบบจำลองทั่วไปที่นำ EM มาใช้ จะใช้ตัวแปรแฝงที่บ่งชี้การเป็นสมาชิกในกลุ่มใดกลุ่มหนึ่งจากชุดกลุ่มต่างๆ ดังนี้:
- จุดข้อมูลที่สังเกตได้อาจเป็นแบบไม่ต่อเนื่อง (มีค่าอยู่ในเซตจำกัดหรือเซตที่นับได้ไม่จำกัด) หรือแบบต่อเนื่อง (มีค่าอยู่ในเซตที่นับไม่ได้ไม่จำกัด) โดยแต่ละจุดข้อมูลอาจมีเวกเตอร์ของการสังเกตประกอบอยู่ด้วย
- ค่าที่หายไป (หรือเรียกอีกอย่างว่าตัวแปรแฝง ) เป็น ค่า ที่ไม่ต่อเนื่องสุ่มมาจากจำนวนค่าคงที่ และมีตัวแปรแฝงหนึ่งตัวต่อหน่วยที่สังเกตได้หนึ่งหน่วย
- พารามิเตอร์เป็นค่าต่อเนื่อง และมีอยู่สองประเภท ได้แก่ พารามิเตอร์ที่สัมพันธ์กับจุดข้อมูลทั้งหมด และพารามิเตอร์ที่สัมพันธ์กับค่าเฉพาะของตัวแปรแฝง (กล่าวคือ สัมพันธ์กับจุดข้อมูลทั้งหมดซึ่งตัวแปรแฝงที่สอดคล้องกันมีค่านั้น)
อย่างไรก็ตาม เป็นไปได้ที่จะนำ EM ไปประยุกต์ใช้กับแบบจำลองประเภทอื่นๆ
แรงจูงใจมีดังนี้ หากทราบค่าของพารามิเตอร์ โดยปกติแล้วค่าของตัวแปรแฝงสามารถหาได้โดยการเพิ่มค่าลอการิทึมความน่าจะเป็นสูงสุดเหนือค่าที่เป็นไปได้ทั้งหมดของ โดยอาจทำได้โดยการวนซ้ำหรือผ่านอัลกอริทึม เช่น อัลกอริทึม Viterbiสำหรับแบบจำลองมาร์คอฟที่ซ่อนอยู่ในทางกลับกัน หากเรารู้ค่าของตัวแปรแฝงเราสามารถหาค่าประมาณของพารามิเตอร์ได้ค่อนข้างง่าย โดยทั่วไปแล้วโดยการจัดกลุ่มจุดข้อมูลที่สังเกตได้ตามค่าของตัวแปรแฝงที่เกี่ยวข้อง และหาค่าเฉลี่ย หรือฟังก์ชันบางอย่างของค่าเหล่านั้น ของจุดในแต่ละกลุ่ม ซึ่งชี้ให้เห็นถึงอัลกอริทึมแบบวนซ้ำ ในกรณีที่ทั้งและไม่ทราบค่า:
- ขั้นแรก ให้กำหนดค่าเริ่มต้นให้กับพารามิเตอร์ด้วยค่าสุ่มบางค่า
- คำนวณความน่าจะเป็นของค่าที่เป็นไปได้แต่ละค่าของ โดยกำหนดให้
- จากนั้น นำค่าที่คำนวณได้ไปใช้ ในการ ประมาณค่าพารามิเตอร์ให้ดียิ่งขึ้น
- ทำซ้ำขั้นตอนที่ 2 และ 3 จนกว่าจะบรรจบกัน
อัลกอริทึมที่ได้อธิบายไปข้างต้นนั้นเข้าใกล้ค่าต่ำสุดเฉพาะที่ของฟังก์ชันต้นทุนอย่างต่อเนื่อง
คุณสมบัติ
แม้ว่าการวนซ้ำของ EM จะเพิ่มฟังก์ชันความน่าจะเป็นของข้อมูลที่สังเกตได้ (เช่น ฟังก์ชันความน่าจะเป็นส่วนย่อย) แต่ก็ไม่มีการรับประกันว่าลำดับจะลู่เข้าสู่ตัวประมาณค่าความน่าจะเป็นสูงสุดสำหรับการแจกแจงแบบหลายยอดหมายความว่าอัลกอริทึม EM อาจลู่เข้าสู่ค่าสูงสุดเฉพาะที่ ของฟังก์ชันความน่าจะเป็นของข้อมูลที่สังเกตได้ ขึ้นอยู่กับค่าเริ่มต้น มีวิธีการเชิงฮิวริสติกหรือ เมตาฮิวริสติกหลายวิธีเพื่อหลีกเลี่ยงค่าสูงสุดเฉพาะที่ เช่นการปีนเขา แบบเริ่มต้นใหม่แบบสุ่ม (เริ่มต้นด้วยค่าประมาณเริ่มต้นแบบสุ่มที่แตกต่างกันหลายค่า) หรือการใช้วิธี การจำลองการอบอ่อน
EM มีประโยชน์อย่างยิ่งเมื่อความน่าจะเป็นเป็นตระกูลเลขชี้กำลังดู Sundberg (2019, บทที่ 8) สำหรับการวิเคราะห์อย่างละเอียด: [ 16 ]ขั้นตอน E จะกลายเป็นผลรวมของความคาดหวังของสถิติที่เพียงพอและขั้นตอน M เกี่ยวข้องกับการเพิ่มค่าสูงสุดของฟังก์ชันเชิงเส้น ในกรณีเช่นนี้ โดยทั่วไปแล้วสามารถหา การอัปเดต นิพจน์แบบปิดสำหรับแต่ละขั้นตอนได้โดยใช้สูตรของ Sundberg [ 17 ] (พิสูจน์และเผยแพร่โดย Rolf Sundberg โดยอิงจากผลลัพธ์ที่ยังไม่ได้เผยแพร่ของPer Martin-LöfและAnders Martin-Löf ) [ 8 ] [ 9 ] [ 11 ] [ 12 ] [ 13 ] [ 14 ]
ในบทความต้นฉบับของ Dempster, Laird และ Rubin วิธีการ EM ได้รับการดัดแปลงเพื่อคำนวณ ค่า ประมาณสูงสุดภายหลัง (MAP) สำหรับการอนุมานแบบเบย์เซียน
ยังมีวิธีการอื่นๆ ที่ใช้ในการหาค่าประมาณความน่าจะเป็นสูงสุด เช่นการไล่ระดับความชัน (gradient descent) , การไล่ระดับความชันแบบสังยุค (conjugate gradient ) หรือรูปแบบต่างๆ ของอัลกอริทึมเกาส์-นิวตันซึ่งแตกต่างจาก EM ตรงที่วิธีการเหล่านี้มักต้องประเมินอนุพันธ์อันดับที่หนึ่งและ/หรืออันดับที่สองของฟังก์ชันความน่าจะเป็น
หลักฐานยืนยันความถูกต้อง
ความคาดหวัง-การเพิ่มค่าสูงสุดทำงานเพื่อปรับปรุงมากกว่าการปรับปรุงโดยตรงมีการแสดงให้เห็นว่าการปรับปรุงในส่วนแรกหมายถึงการปรับปรุงในส่วนหลัง[ 18 ]

สำหรับค่าใดๆที่มีความน่าจะเป็นไม่เป็นศูนย์เราสามารถเขียนได้ว่า เรา หาค่าเฉลี่ยของค่าที่เป็นไปได้ของข้อมูลที่ไม่ทราบค่าภายใต้การประมาณค่าพารามิเตอร์ปัจจุบันโดยการคูณทั้งสองข้างด้วยและบวก (หรืออินทิเกรต) เหนือด้านซ้ายมือคือค่าเฉลี่ยของค่าคงที่ ดังนั้นเราจะได้: โดยที่ถูกกำหนดโดยผลรวมที่เป็นลบที่มันแทนที่ สมการสุดท้ายนี้ใช้ได้กับทุกค่าของรวมถึงและ การลบสมการสุดท้ายนี้ออกจากสมการก่อนหน้าจะได้ อย่างไรก็ตามอสมการของกิบบส์บอกเราว่าดังนั้นเราจึงสรุปได้ว่า กล่าวคือ การเลือกที่จะปรับปรุง จะ ทำให้ปรับปรุงอย่างน้อยที่สุดเท่ากัน











เป็นกระบวนการเพิ่มค่าสูงสุด-เพิ่มค่าสูงสุด
อัลกอริทึม EM สามารถมองได้ว่าเป็นขั้นตอนการเพิ่มค่าสูงสุดสลับกันสองขั้นตอน นั่นคือ เป็นตัวอย่างของ การ ลดพิกัด[ 19 ] [ 20 ]พิจารณาฟังก์ชัน: โดยที่qเป็นการกระจายความน่าจะเป็นแบบใดก็ได้เหนือข้อมูลที่ไม่ถูกสังเกตzและH ( q )คือเอนโทรปีของการกระจายqฟังก์ชันนี้สามารถเขียนได้เป็น โดย ที่ เป็นการกระจายแบบมีเงื่อนไขของข้อมูลที่ไม่ถูกสังเกตเมื่อกำหนดข้อมูลที่สังเกตได้และคือความแตกต่างของ Kullback– Leibler
![{\displaystyle F(q,\theta ):=\operatorname {E} _{q}[\log L(\theta ;x,Z)]+H(q),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4e0798985f246154015deb375e1494dfa734922)




ดังนั้น ขั้นตอนในอัลกอริทึม EM อาจมองได้ดังนี้:
- ขั้นตอนการคาดการณ์ : เลือกเพื่อเพิ่มค่าสูงสุด :
- ขั้นตอนการเพิ่มค่าสูงสุด : เลือกที่จะเพิ่มค่าสูงสุด :





แอปพลิเคชัน
- EM มักใช้สำหรับการประมาณค่าพารามิเตอร์ของแบบจำลองผสม [ 21 ] [ 22 ]โดยเฉพาะอย่างยิ่งในพันธุศาสตร์เชิงปริมาณ[ 23 ]
- ในสาขาจิตวิทยาการวัดผล EM เป็นเครื่องมือสำคัญในการประมาณค่าพารามิเตอร์ของข้อสอบและความสามารถแฝงของแบบจำลองทฤษฎีการตอบสนองต่อข้อสอบ
- ด้วยความสามารถในการจัดการกับข้อมูลที่ขาดหายไปและการสังเกตตัวแปรที่ไม่ระบุ ทำให้ EM กำลังกลายเป็นเครื่องมือที่มีประโยชน์ในการกำหนดราคาและบริหารความเสี่ยงของพอร์ตโฟลิโอ
- อัลกอริทึม EM (และรูปแบบที่เร็วกว่าอย่าง การประมาณค่าสูงสุดของเซตย่อยแบบเรียงลำดับ ) ยังถูกนำมาใช้กันอย่างแพร่หลายใน การสร้าง ภาพทางการแพทย์โดยเฉพาะอย่างยิ่งในการถ่ายภาพด้วยโพซิตรอนอีมิสชันโทโมกราฟี การถ่ายภาพด้วยเอกซเรย์คอมพิวเตอร์แบบเอกซเรย์เดี่ยวและการถ่ายภาพด้วยเอกซเรย์คอมพิวเตอร์ดูรายละเอียดเพิ่มเติมเกี่ยวกับรูปแบบที่เร็วกว่าของ EM ด้านล่าง
- ในวิศวกรรมโครงสร้างอัลกอริทึม Structural Identification using Expectation Maximization (STRIDE) [ 24 ]เป็นวิธีการแบบเอาต์พุตเท่านั้นสำหรับการระบุคุณสมบัติการสั่นสะเทือนตามธรรมชาติของระบบโครงสร้างโดยใช้ข้อมูลเซ็นเซอร์ (ดูการวิเคราะห์โมดอลเชิงปฏิบัติการ )
- EM ยังใช้สำหรับการจัดกลุ่มข้อมูล อีกด้วย ในการประมวลผลภาษาธรรมชาติตัวอย่างที่โดดเด่นสองประการของอัลกอริธึมนี้ ได้แก่อัลกอริธึม Baum–Welchสำหรับแบบจำลองมาร์คอฟที่ซ่อนอยู่และ อัลกอริธึ มภายใน-ภายนอกสำหรับการเหนี่ยวนำไวยากรณ์แบบไร้บริบทเชิงความน่าจะ เป็นโดยไม่ใช้การกำกับดูแล
- ในการวิเคราะห์เวลาการรอคอย ระหว่างการค้า อัลกอริทึม EM ได้รับการพิสูจน์แล้วว่ามีประโยชน์มาก[ 25 ]
อัลกอริทึม EM สำหรับการกรองและการปรับให้เรียบ
โดยทั่วไปแล้ว ตัวกรอง Kalmanจะใช้สำหรับการประมาณค่าสถานะแบบออนไลน์ และอาจใช้ตัวปรับเรียบความแปรปรวนต่ำสุดสำหรับการประมาณค่าสถานะแบบออฟไลน์หรือแบบกลุ่ม อย่างไรก็ตาม วิธีแก้ปัญหาความแปรปรวนต่ำสุดเหล่านี้จำเป็นต้องมีการประมาณค่าพารามิเตอร์ของแบบจำลองปริภูมิสถานะ อัลกอริทึม EM สามารถใช้สำหรับการแก้ปัญหาการประมาณค่าสถานะและพารามิเตอร์ร่วมกันได้
อัลกอริทึม EM สำหรับการกรองและการปรับให้เรียบเกิดขึ้นจากการทำซ้ำขั้นตอนสองขั้นตอนดังนี้:
- อี-สเต็ป
- ใช้ตัวกรอง Kalman หรือตัวปรับเรียบความแปรปรวนต่ำสุดที่ออกแบบโดยใช้ค่าประมาณพารามิเตอร์ปัจจุบัน เพื่อให้ได้ค่าประมาณสถานะที่อัปเดตแล้ว
- เอ็ม-สเต็ป
- ใช้ค่าประมาณสถานะที่ผ่านการกรองหรือปรับให้เรียบแล้วในการคำนวณแบบความน่าจะเป็นสูงสุด เพื่อให้ได้ค่าประมาณพารามิเตอร์ที่อัปเดตแล้ว
สมมติว่าตัวกรอง Kalmanหรือตัวปรับเรียบความแปรปรวนต่ำสุดทำงานกับข้อมูลการวัดของระบบอินพุตเดียวเอาต์พุตเดียวที่มีสัญญาณรบกวนสีขาวแบบบวก การประมาณค่าความแปรปรวนของสัญญาณรบกวนการวัดที่ปรับปรุงแล้วสามารถหาได้จากการคำนวณ ความน่าจะเป็นสูงสุด

โดยที่ค่าประมาณเอาต์พุตแบบสเกลาร์คำนวณโดยตัวกรองหรือตัวปรับเรียบจากค่าการวัดแบบสเกลาร์ N ค่า การอัปเดตข้างต้นยังสามารถนำไปใช้กับการอัปเดตความเข้มของสัญญาณรบกวนการวัดแบบปัวซงได้อีกด้วย ในทำนองเดียวกัน สำหรับกระบวนการถดถอยอัตโนมัติอันดับแรก ค่าประมาณความแปรปรวนของสัญญาณรบกวนกระบวนการที่อัปเดตแล้วสามารถคำนวณได้โดย



โดยที่และคือค่าประมาณสถานะแบบสเกลาร์ที่คำนวณโดยตัวกรองหรือตัวปรับเรียบ ค่าประมาณสัมประสิทธิ์ของแบบจำลองที่อัปเดตแล้วได้มาจากการใช้


การบรรจบกันของการประมาณค่าพารามิเตอร์เช่นที่กล่าวมาข้างต้นได้รับการศึกษามาเป็นอย่างดี[ 26 ] [ 27 ] [ 28 ] [ 29 ]
ตัวแปร
มีการเสนอวิธีการหลายวิธีเพื่อเร่งการบรรจบกันที่บางครั้งช้าของอัลกอริธึม EM เช่น วิธีการไล่ระดับคอนจูเกตและวิธีการของนิวตัน ที่ดัดแปลง (นิวตัน-ราฟสัน) [ 30 ]นอกจากนี้ EM ยังสามารถใช้กับวิธีการประมาณค่าแบบมีข้อจำกัดได้
อัลกอริ ทึมการเพิ่มประสิทธิภาพความคาดหวังแบบขยายพารามิเตอร์ (PX-EM)มักจะเร่งความเร็วโดย "ใช้ 'การปรับความแปรปรวนร่วม' เพื่อแก้ไขการวิเคราะห์ขั้นตอน M โดยใช้ประโยชน์จากข้อมูลเพิ่มเติมที่บันทึกไว้ในข้อมูลที่สมบูรณ์ที่เติมเต็ม" [ 31 ]
การหาค่าสูงสุดแบบมีเงื่อนไขตามความคาดหวัง (ECM)จะแทนที่ขั้นตอน M แต่ละขั้นตอนด้วยลำดับของขั้นตอนการหาค่าสูงสุดแบบมีเงื่อนไข (CM) ซึ่งแต่ละพารามิเตอร์θ iจะถูกหาค่าสูงสุดทีละตัว โดยมีเงื่อนไขว่าพารามิเตอร์อื่นๆ ยังคงที่[ 32 ]ซึ่งสามารถขยายเป็นอัลกอริทึมการหาค่าสูงสุดแบบมีเงื่อนไขตามความคาดหวัง (ECME) ได้เช่นกัน[ 33 ]
แนวคิดนี้ได้รับการขยายเพิ่มเติมใน อัลกอริทึม การเพิ่มประสิทธิภาพความคาดหวังทั่วไป (GEM)ซึ่งมุ่งเน้นเพียงการเพิ่มขึ้นของฟังก์ชันวัตถุประสงค์Fสำหรับทั้งขั้นตอน E และขั้นตอน M ตามที่อธิบายไว้ในส่วนขั้นตอนการเพิ่มประสิทธิภาพสูงสุด[ 19 ] GEM ได้รับการพัฒนาเพิ่มเติมในสภาพแวดล้อมแบบกระจายและแสดงผลลัพธ์ที่น่าสนใจ[ 34 ]
นอกจากนี้ยังสามารถพิจารณาอัลกอริธึม EM เป็นคลาสย่อยของ อัลกอริธึม MM (Majorize/Minimize หรือ Minorize/Maximize ขึ้นอยู่กับบริบท) ได้อีกด้วย[ 35 ]และด้วยเหตุนี้จึงสามารถใช้กลไกใดๆ ที่พัฒนาขึ้นในกรณีทั่วไปได้
อัลกอริทึม α-EM
ฟังก์ชัน Q ที่ใช้ในอัลกอริทึม EM นั้นขึ้นอยู่กับลอการิทึมความน่าจะเป็น ดังนั้นจึงถือว่าเป็นอัลกอริทึม log-EM การใช้ลอการิทึมความน่าจะเป็นสามารถขยายไปสู่การใช้อัตราส่วนลอการิทึมความน่าจะเป็น α ได้ จากนั้น อัตราส่วนลอการิทึมความน่าจะเป็น α ของข้อมูลที่สังเกตได้สามารถแสดงได้อย่างแม่นยำในรูปของความเท่าเทียมกันโดยใช้ฟังก์ชัน Q ของอัตราส่วนลอการิทึมความน่าจะเป็น α และความแตกต่าง α การได้มาซึ่งฟังก์ชัน Q นี้เป็นขั้นตอน E ทั่วไป การหาค่าสูงสุดของมันคือขั้นตอน M ทั่วไป คู่ดังกล่าวเรียกว่าอัลกอริทึม α-EM [ 36 ] ซึ่งมีอัลกอริทึม log-EM เป็นคลาสย่อย ดังนั้น อัลกอริทึม α-EM โดยYasuo Matsuyama จึง เป็นการขยายอัลกอริทึม log-EM อย่างแม่นยำ ไม่จำเป็นต้องคำนวณเกรเดียนต์หรือเมทริกซ์ Hessian α-EM แสดงการลู่เข้าที่เร็วกว่าอัลกอริทึม log-EM โดยการเลือก α ที่เหมาะสม อัลกอริทึม α-EM นำไปสู่เวอร์ชันที่เร็วกว่าของอัลกอริทึมการประมาณค่าแบบจำลองมาร์คอฟที่ซ่อนอยู่ α-HMM [ 37 ]
ความสัมพันธ์กับวิธีการเบย์แบบแปรผัน
EM เป็นวิธีการหาค่าความน่าจะเป็นสูงสุดที่ไม่ใช่แบบเบย์เซียนบางส่วน ผลลัพธ์สุดท้ายจะให้การกระจายความน่าจะเป็นเหนือตัวแปรแฝง (ในรูปแบบเบย์เซียน) พร้อมกับค่าประมาณจุดสำหรับθ (ไม่ว่าจะเป็นค่าประมาณความน่าจะเป็นสูงสุดหรือค่าฐานนิยมภายหลัง) อาจต้องการเวอร์ชันแบบเบย์เซียนอย่างสมบูรณ์ ซึ่งให้การกระจายความน่าจะเป็นเหนือθและตัวแปรแฝง วิธีการอนุมานแบบเบย์เซียนนั้นง่ายๆ คือการพิจารณาθเป็นตัวแปรแฝงอีกตัวหนึ่ง ในแบบจำลองนี้ ความแตกต่างระหว่างขั้นตอน E และ M จะหายไป หากใช้การประมาณค่า Q แบบแยกส่วนตามที่อธิบายไว้ข้างต้น ( เบย์เซียนแบบแปรผัน ) การแก้ปัญหาสามารถวนซ้ำเหนือตัวแปรแฝงแต่ละตัว (รวมถึงθ ด้วย ) และปรับให้เหมาะสมทีละตัว ตอนนี้ต้องใช้k ขั้นตอนต่อการวนซ้ำ โดยที่ kคือจำนวนตัวแปรแฝง สำหรับแบบจำลองกราฟิกการทำเช่นนี้ทำได้ง่าย เนื่องจากQ ใหม่ของแต่ละตัวแปร ขึ้นอยู่กับMarkov blanket เท่านั้น ดังนั้นจึงสามารถใช้ การส่งข้อความ แบบโลคอลเพื่อการอนุมานที่มีประสิทธิภาพได้
การตีความทางเรขาคณิต
ในเรขาคณิตสารสนเทศขั้นตอน E และขั้นตอน M ถูกตีความว่าเป็นการฉายภาพภายใต้การเชื่อมต่อเชิงเส้น คู่ ซึ่งเรียกว่าการเชื่อมต่อ e และการเชื่อมต่อ m นอกจากนี้ ความแตกต่างของ Kullback–Leiblerก็สามารถเข้าใจได้ในแง่เหล่านี้เช่นกัน
ตัวอย่าง
ส่วนผสมเกาส์เซียน
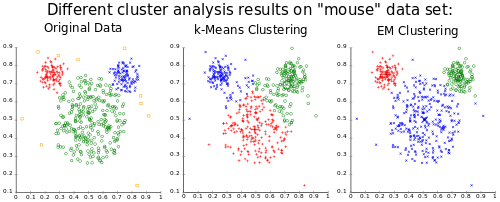

ให้เป็นตัวอย่างของการสังเกตอิสระจากส่วนผสม ของ การแจกแจงปกติหลายตัวแปรสองแบบที่มีมิติและให้เป็นตัวแปรแฝงที่กำหนดส่วนประกอบที่การสังเกตมาจาก[ 20 ] โดยที่






จุดมุ่งหมายคือการประมาณค่าพารามิเตอร์ที่ไม่ทราบค่า ซึ่งแสดงถึง ค่า การผสมระหว่างฟังก์ชันเกาส์เซียนและค่าเฉลี่ยและความแปรปรวนร่วมของแต่ละฟังก์ชัน โดยที่ฟังก์ชันความน่าจะเป็นของข้อมูลที่ไม่สมบูรณ์คือ


และฟังก์ชันความน่าจะเป็นของข้อมูลที่สมบูรณ์คือ
![{\displaystyle {\begin{aligned}L(\theta ;\mathbf {x} ,\mathbf {z} )&=p(\mathbf {x} ,\mathbf {z} \mid \theta )\\&=\prod _{i=1}^{n}\prod _{j=1}^{2}\left[f(\mathbf {x} _{i};{\boldสัญลักษณ์ {\mu }`{j},\Sigma _{j})\tau _{j}\right]^{\mathbb {I} (z_{i}=j)},\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87e3a064f9894202b88024c9e1fcc831c594e1df)
หรือ
![{\displaystyle \log L(\theta ;\mathbf {x} ,\mathbf {z} )=\sum _{i=1}^{n}\sum _{j=1}^{2}\mathbb {I} (z_{i}=j)\left[\log \tau _{j}-{\tfrac {1}{2}}\log |\Sigma _{j}|-{\tfrac {1}{2}}(\mathbf {x} _{i}-{\boldสัญลักษณ์ {\mu }__{j})^{\top }\Sigma _{j}^{-1}(\mathbf {x} _{i}-{\boldสัญลักษณ์ {\mu }__{j})-{\tfrac {d}{2}}\log(2\pi )\ขวา],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1d2d66d1463b7a075ee23a12cd5230d84913f46)
โดยที่เป็นฟังก์ชันบ่งชี้และเป็นฟังก์ชันความหนาแน่นความน่าจะเป็นของการแจกแจงปกติหลายตัวแปร


ในความเท่าเทียมกันครั้งสุดท้าย สำหรับแต่ละiตัวบ่งชี้หนึ่งตัวจะมีค่าเท่ากับศูนย์ และตัวบ่งชี้อีกตัวจะมีค่าเท่ากับหนึ่ง ดังนั้นผลรวมภายในจึงลดลงเหลือเพียงพจน์เดียว

ขั้นตอน E
เมื่อพิจารณาจากการประมาณค่าพารามิเตอร์θ ( t ) ในปัจจุบัน การแจกแจงแบบมีเงื่อนไขของZ iจะถูกกำหนดโดยทฤษฎีบทของเบย์สให้เป็นสัดส่วนความสูงของความหนาแน่น ปกติ ที่ถ่วงน้ำหนักด้วยτ :

สิ่งเหล่านี้เรียกว่า "ความน่าจะเป็นของการเป็นสมาชิก" ซึ่งโดยปกติจะถือว่าเป็นผลลัพธ์ของขั้นตอน E (แม้ว่านี่จะไม่ใช่ ฟังก์ชัน Qที่กล่าวถึงด้านล่างก็ตาม)
ขั้นตอน E นี้สอดคล้องกับการตั้งค่าฟังก์ชันนี้สำหรับQ : ค่าเฉลี่ยของภายในผลรวมจะถูกคำนวณโดยสัมพันธ์กับฟังก์ชันความหนาแน่นของความน่าจะเป็นซึ่งอาจแตกต่างกันสำหรับแต่ละ ชุดข้อมูลฝึกฝน ทุกอย่างในขั้นตอน E เป็นที่ทราบก่อนที่จะดำเนินการขั้นตอนนี้ ยกเว้นซึ่งคำนวณตามสมการที่อยู่ตอนต้นของส่วนขั้นตอน E
![{\displaystyle {\begin{aligned}Q(\theta \mid \theta ^{(t)})&=\operatorname {E} _{\mathbf {Z} \mid \mathbf {X} =\mathbf {x} ;\mathbf {\theta } ^{(t)}}\left[\log L(\theta ;\mathbf {x} ,\mathbf {Z} )\right]\\&=\operatorname {E} _{\mathbf {Z} \mid \mathbf {X} =\mathbf {x} ;\mathbf {\theta } ^{(t)}}\left[\log \prod _{i=1}^{n}L(\theta ;\mathbf {x} _{i},Z_{i})\right]\\&=\ชื่อผู้ดำเนินการ {E} _{\mathbf {Z} \mid \mathbf {X} =\mathbf {x} ;\mathbf {\theta } ^{(t)}}\left[\sum _{i=1}^{n}\log L(\theta ;\mathbf {x} _{i},Z_{i})\right]\\&=\sum _{i=1}^{n}\operatorname {E} _{Z_{i}\mid X_{i}=x_{i};\mathbf {\theta } ^{(t)}}\left[\log L(\theta ;\mathbf {x} _{i},Z_{i})\right]\\&=\sum _{i=1}^{n}\sum _{j=1}^{2}P(Z_{i}=j\mid X_{i}=\mathbf {x} _{i};\theta ^{(t)})\log L(\theta ;\mathbf {x} _{i},j)\\&=\sum _{i=1}^{n}\sum _{j=1}^{2}T_{j,i}^{(t)}\left[\log \tau _{j}-{\tfrac {1}{2}}\log |\Sigma _{j}|-{\tfrac {1}{2}}(\mathbf {x} _{i}-{\boldสัญลักษณ์ {\mu }__{j})^{\top }\Sigma _{j}^{-1}(\mathbf {x} _{i}-{\boldสัญลักษณ์ {\mu }`{j})-{\tfrac {d}{2}}\log(2\pi )\right].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74f28b1e17eafa9762ab585cc57c3bdacee00bc8)




ไม่จำเป็นต้องคำนวณค่าคาดหวังแบบมีเงื่อนไขทั้งหมดในขั้นตอนเดียว เนื่องจากτและμ / Σปรากฏในพจน์เชิงเส้นที่แยกจากกัน และสามารถหาค่าสูงสุดได้โดยอิสระ
ขั้นตอน M
เนื่องจากมีรูปแบบเป็นกำลังสอง การหาค่าสูงสุดของจึงค่อนข้างตรงไปตรงมา นอกจากนี้ , และยังสามารถหาค่าสูงสุดได้อย่างอิสระ เนื่องจากทั้งหมดปรากฏอยู่ในพจน์เชิงเส้นที่แยกจากกัน




เริ่มต้นด้วยการพิจารณาซึ่งมีข้อจำกัดดังนี้: ซึ่งมีรูปแบบเดียวกับการประมาณค่าความน่าจะเป็นสูงสุดสำหรับการแจกแจงทวินามดังนั้น

![{\displaystyle {\begin{aligned}{\boldsymbol {\tau }}^{(t+1)}&=\mathop {\arg \max } _{\boldsymbol {\tau }}Q{\left(\theta \mid \theta ^{(t)}\right)}\\&=\mathop {\arg \max } _{\boldsymbol {\tau }}\left\{\left[\sum _{i=1}^{n}T_{1,i}^{(t)}\right]\log \tau _{1}+\left[\sum _{i=1}^{n}T_{2,i}^{(t)}\right]\log \tau _{2}\right\}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/40d617495a3de15a08913b70515ab9fd6f752249)

สำหรับการประมาณค่าต่อไปนี้: ซึ่งมีรูปแบบเดียวกับการประมาณค่าความน่าจะเป็นสูงสุดแบบถ่วงน้ำหนักสำหรับการแจกแจงแบบปกติ ดังนั้น และโดยสมมาตร

![{\displaystyle {\begin{aligned}{\boldsymbol {\mu }}_{1}^{(t+1)}&={\frac {\sum \limits _{i=1}^{n}T_{1,i}^{(t)}\mathbf {x} _{i}}{\sum \limits _{i=1}^{n}T_{1,i}^{(t)}}},\\[1ex]\Sigma _{1}^{(t+1)}&={\frac {\sum \limits _{i=1}^{n}T_{1,i}^{(t)}\left(\mathbf {x} _{i}-{\boldsymbol {\mu }}_{1}^{(t+1)}\right)\left(\mathbf {x} _{i}-{\boldsymbol {\mu }}_{1}^{(t+1)}\right)^{\top }}{\sum \limits _{i=1}^{n}T_{1,i}^{(t)}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/780c09d4f7c975ba95ebae404ed6af4febb7462a)
![{\displaystyle {\begin{aligned}{\boldsymbol {\mu }}_{2}^{(t+1)}&={\frac {\sum \limits _{i=1}^{n}T_{2,i}^{(t)}\mathbf {x} _{i}}{\sum \limits _{i=1}^{n}T_{2,i}^{(t)}}},\\[1ex]\Sigma _{2}^{(t+1)}&={\frac {\sum \limits _{i=1}^{n}T_{2,i}^{(t)}\left(\mathbf {x} _{i}-{\boldsymbol {\mu }}_{2}^{(t+1)}\right)\left(\mathbf {x} _{i}-{\boldsymbol {\mu }}_{2}^{(t+1)}\right)^{\top }}{\sum \limits _{i=1}^{n}T_{2,i}^{(t)}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1aa48619ecacab26814ba81245b62264f62bff48)
การเลิกจ้าง
ยุติกระบวนการวนซ้ำหากการปรับปรุงค่าคาดหวังมีขนาดเล็กเพียงพอ กล่าวคือ หากต่ำกว่าเกณฑ์ที่กำหนดไว้ล่วงหน้า
![{\displaystyle \left|\operatorname {E} _{Z\mid \theta ^{(t)},\mathbf {x} }[\log L(\theta ^{(t)};\mathbf {x} ,\mathbf {Z} )]-\operatorname {E} _{Z\mid \theta ^{(t-1)},\mathbf {x} }[\log L(\theta ^{(t-1)};\mathbf {x} ,\mathbf {Z} )]\right|\leq \varepsilon }](https://wikimedia.org/api/rest_v1/media/math/render/svg/d689e4abae0aad58c60bee1cdd16131cfda68de6)

การสรุปทั่วไป
อัลกอริทึมที่แสดงไว้ข้างต้นสามารถนำไปประยุกต์ใช้กับส่วนผสมของ การแจกแจงปกติหลายตัวแปรมากกว่าสองแบบได้
การถดถอยแบบตัดทอนและเซ็นเซอร์
อัลกอริทึม EM ได้รับการนำไปใช้ในกรณีที่ มีแบบจำลอง การถดถอยเชิงเส้น พื้นฐาน ที่อธิบายความแปรผันของปริมาณบางอย่าง แต่ค่าที่สังเกตได้จริงเป็นเวอร์ชันที่ถูกตัดทอนหรือถูกจำกัดจากค่าที่แสดงในแบบจำลอง[ 38 ]กรณีพิเศษของแบบจำลองนี้รวมถึงการสังเกตที่ถูกตัดทอนหรือถูกจำกัดจากการกระจายแบบปกติหนึ่ง รายการ [ 38 ]
ทางเลือกอื่นๆ
โดยทั่วไป EM จะลู่เข้าสู่จุดเหมาะสมเฉพาะที่ ไม่จำเป็นต้องเป็นจุดเหมาะสมทั่วโลก และไม่มีข้อจำกัดเกี่ยวกับอัตราการลู่เข้าโดยทั่วไป เป็นไปได้ว่าอาจมีประสิทธิภาพต่ำมากในมิติสูง และอาจมีจำนวนจุดเหมาะสมเฉพาะที่แบบเลขชี้กำลัง ดังนั้นจึงมีความจำเป็นต้องมีวิธีการอื่นสำหรับการเรียนรู้ที่รับประกันได้ โดยเฉพาะอย่างยิ่งในการตั้งค่าที่มีมิติสูง มีทางเลือกอื่นนอกเหนือจาก EM ที่มีการรับประกันความสอดคล้องที่ดีกว่า ซึ่งเรียกว่าวิธีการตามโมเมนต์[ 39 ]หรือที่เรียกว่าเทคนิคสเปกตรัม[ 40 ] [ 41 ]วิธีการตามโมเมนต์ในการเรียนรู้พารามิเตอร์ของแบบจำลองความน่าจะเป็นนั้นมีการรับประกัน เช่น การลู่เข้าทั่วโลกภายใต้เงื่อนไขบางประการ ซึ่งแตกต่างจาก EM ที่มักประสบปัญหาการติดอยู่ในจุดเหมาะสมเฉพาะที่ สามารถพัฒนาอัลกอริธึมที่มีการรับประกันการเรียนรู้สำหรับแบบจำลองสำคัญหลายแบบ เช่น แบบจำลองผสม (mixture models) แบบจำลอง HMM เป็นต้น สำหรับวิธีการเชิงสเปกตรัมเหล่านี้ จะไม่มีจุดเหมาะสมเฉพาะที่ที่ไม่ถูกต้องเกิดขึ้น และสามารถประมาณค่าพารามิเตอร์ที่แท้จริงได้อย่างสม่ำเสมอภายใต้เงื่อนไขความสม่ำเสมอบางประการ
ดูเพิ่มเติม
- การกระจายส่วนผสม
- การกระจายสารประกอบ
- การประมาณความหนาแน่น
- การวิเคราะห์ส่วนประกอบหลัก
- สเปกโทรสโกปีการดูดกลืนรวม
- อัลกอริทึม EM สามารถมองได้ว่าเป็นกรณีพิเศษของอัลกอริทึม majorize-minimization (MM ) [ 42 ]
อ่านเพิ่มเติม
- Hogg, Robert; McKean, Joseph; Craig, Allen (2005). บทนำสู่สถิติทางคณิตศาสตร์ . Upper Saddle River, NJ: Pearson Prentice Hall. หน้า 359–364 .
- เดลลาเอิร์ต, แฟรงค์ (กุมภาพันธ์ 2545). อัลกอริทึมการเพิ่มประสิทธิภาพความคาดหวัง(PDF) (รายงานทางเทคนิคหมายเลข GIT-GVU-02-20). วิทยาลัยวิทยาการคอมพิวเตอร์ จอร์เจียเทค.ช่วยให้เข้าใจอัลกอริธึม EM ได้ง่ายขึ้นในแง่ของการเพิ่มค่าขอบล่างให้สูงสุด
- บิชอป, คริสโตเฟอร์ เอ็ม. (2006). การรู้จำรูปแบบและการเรียนรู้ของเครื่องจักร . สปริงเกอร์. ISBN 978-0-387-31073-2.
- Gupta, MR; Chen, Y. (2010). "ทฤษฎีและการใช้อัลกอริธึม EM". พื้นฐานและแนวโน้มในการประมวลผลสัญญาณ4 (3): 223– 296. CiteSeerX 10.1.1.219.6830 . doi : 10.1561/2000000034 .หนังสือขนาดสั้นที่เขียนได้ดีเกี่ยวกับ EM ซึ่งรวมถึงการพิสูจน์ EM อย่างละเอียดสำหรับ GMM, HMM และ Dirichlet
- Bilmes, Jeff (1997). บทแนะนำอย่างง่ายเกี่ยวกับอัลกอริธึม EM และการประยุกต์ใช้ในการประมาณค่าพารามิเตอร์สำหรับแบบจำลอง Gaussian Mixture และ Hidden Markov Models (รายงานทางเทคนิค TR-97-021). สถาบันวิทยาศาสตร์คอมพิวเตอร์นานาชาติรวมถึงการพิสูจน์อย่างง่ายของสมการ EM สำหรับส่วนผสมเกาส์เซียนและแบบจำลองมาร์คอฟที่ซ่อนอยู่ของส่วนผสมเกาส์เซียน
- McLachlan, Geoffrey J.; Krishnan, Thriyambakam (2008). อัลกอริทึม EM และส่วนขยาย (ฉบับที่ 2). โฮโบเคน: ไวลีย์. ISBN 978-0-471-20170-0.
ลิงก์ภายนอก
- มีการสาธิต EM ในรูปแบบ 1 มิติ 2 มิติ และ 3 มิติ ร่วมกับการสร้างแบบจำลองแบบผสม (Mixture Modeling) ซึ่งเป็นส่วนหนึ่งของ กิจกรรมและแอปพลิเคชัน SOCR ที่ให้มาคู่กัน แอปพลิเคชันและกิจกรรมเหล่านี้แสดงให้เห็นถึงคุณสมบัติของอัลกอริธึม EM สำหรับการประมาณค่าพารามิเตอร์ในบริบทต่างๆ อย่างเป็นรูปธรรม
- ลำดับชั้นของคลาสในC++ (GPL) รวมถึง Gaussian Mixtures
- ตำราเรียนออนไลน์เรื่อง "ทฤษฎีสารสนเทศ การอนุมาน และอัลกอริธึมการเรียนรู้"โดยDavid JC MacKayประกอบด้วยตัวอย่างง่ายๆ ของอัลกอริธึม EM เช่น การจัดกลุ่มโดยใช้ อัลกอริธึม k -means แบบอ่อน และเน้นมุมมองเชิงแปรผันของอัลกอริธึม EM ดังที่อธิบายไว้ในบทที่ 33.7 ของเวอร์ชัน 7.2 (ฉบับที่สี่)
- หนังสือ Variational Algorithms for Approximate Bayesian Inferenceโดย MJ Beal ประกอบด้วยการเปรียบเทียบ EM กับ Variational Bayesian EM และการหาอนุพันธ์ของแบบจำลองหลายแบบ รวมถึง Variational Bayesian HMMs ( บทต่างๆ )
- อัลกอริทึมการเพิ่มประสิทธิภาพความคาดหวัง: บทแนะนำสั้นๆการพิสูจน์อัลกอริทึม EM อย่างครบถ้วนโดย ฌอน บอร์แมน
- อัลกอริทึม EMโดย Xiaojin Zhu
- อัลกอริทึม EM และรูปแบบต่างๆ: คู่มือฉบับย่อโดย Alexis Roche คำอธิบายที่กระชับและชัดเจนมากเกี่ยวกับ EM และรูปแบบต่างๆ ที่น่าสนใจมากมาย
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ อัลกอริทึมความคาดหวัง-การเพิ่มค่าสูงสุด
ในทางสถิติอัลกอริทึมการคาดการณ์-การเพิ่มค่าสูงสุด ( EM ) เป็นวิธีการวนซ้ำเพื่อค้นหา ค่าประมาณ ความน่าจะเป็นสูงสุด (เฉพาะที่) หรือ ค่าประมาณ ความน่าจะเป็นสูงสุดภายหลัง (MAP)
ประวัติศาสตร์
อัลกอริทึม EM ได้รับการอธิบายและตั้งชื่อในบทความคลาสสิกปี 1977 โดย Arthur Dempster , Nan Laird และ Donald Rubin [ 3 ] พวก เขาชี้ให้เห็นว่าวิธีการนี้ "ได้รับการเสนอหลายครั้งในสถานการณ์พิเศษ" โดยผู้เขียนก่อนหน้านี้...
การแนะนำ
อัลกอริทึม EM ใช้เพื่อค้นหา พารามิเตอร์ ความน่าจะเป็นสูงสุด (เฉพาะที่) ของ แบบจำลองทางสถิติ ในกรณีที่สมการไม่สามารถแก้ได้โดยตรง โดยทั่วไปแบบจำลองเหล่านี้เกี่ยวข้องกับ ตัวแปรแฝง นอกเหนือจาก พารามิเตอร์ ที่ไม่ทราบค่า และข้อมูลที่ทราบแล้ว กล่าวคือ อาจ มี...
สัญลักษณ์
เมื่อกำหนด แบบจำลองทางสถิติ ที่สร้างชุดข้อมูลที่สังเกตได้ ชุดข้อมูลแฝงที่ไม่สามารถสังเกตได้หรือ ค่าที่หายไป และเวกเตอร์ของพารามิเตอร์ที่ไม่ทราบค่าพร้อมกับ ฟังก์ชันความน่าจะเป็นแล้ว ค่า ประมาณความน่าจะเป็นสูงสุด (MLE)...