อ่าน 9 นาที
แบบจำลองผสม
แบบ จำลองผสม ( Mixed model) หรือแบบ จำลองผลกระทบผสม (Mixed-effects model) หรือ แบบจำลององค์ประกอบข้อผิดพลาดผสม (Mixed error-component model ) เป็น แบบจำลองทางสถิติ ที่มีทั้ง...
แบบจำลองผสม
| ส่วนหนึ่งของชุดบทความเกี่ยวกับ |
| การวิเคราะห์การถดถอย |
|---|
| นางแบบ |
| การประมาณการ |
| พื้นหลัง |
|
แบบจำลองผสม ( Mixed model) หรือแบบ จำลองผลกระทบผสม (Mixed-effects model)หรือแบบจำลององค์ประกอบข้อผิดพลาดผสม (Mixed error-component model ) เป็นแบบจำลองทางสถิติที่มีทั้งผลกระทบคงที่และผลกระทบสุ่ม[ 1 ] [ 2 ] แบบจำลองเหล่านี้มีประโยชน์ในหลากหลายสาขาวิชาในวิทยาศาสตร์กายภาพ ชีววิทยา และสังคมศาสตร์ โดยเฉพาะอย่างยิ่งมีประโยชน์ในกรณีที่ มี การวัดซ้ำ ใน หน่วยทางสถิติเดียวกัน(ดูเพิ่มเติมที่การศึกษาตามยาว ) หรือในกรณีที่มีการวัดในกลุ่มของหน่วยทางสถิติที่เกี่ยวข้องกัน[ 2 ]แบบจำลองผสมมักเป็นที่นิยมมากกว่า แบบจำลอง การถดถอยการวิเคราะห์ความแปรปรวน แบบดั้งเดิม เนื่องจากไม่ขึ้นอยู่กับสมมติฐานการสังเกตที่เป็นอิสระ นอกจากนี้ ยังมีความยืดหยุ่นในการจัดการกับค่าที่หายไปและการเว้นระยะที่ไม่สม่ำเสมอของการวัดซ้ำ[ 3 ] การวิเคราะห์แบบจำลองผสมช่วยให้สามารถจำลองการวัดได้อย่างชัดเจนใน โครงสร้าง ความสัมพันธ์และความแปรปรวนร่วมที่หลากหลายมากขึ้น หลีกเลี่ยง การประมาณค่าที่ลำเอียง
หน้านี้จะกล่าวถึงโมเดลผสมเชิงเส้น เป็นหลัก มากกว่าโมเดลผสมเชิงเส้นทั่วไปหรือโมเดลผสมที่ไม่เป็นเชิงเส้น[ 4 ]
คำอธิบายเชิงคุณภาพ
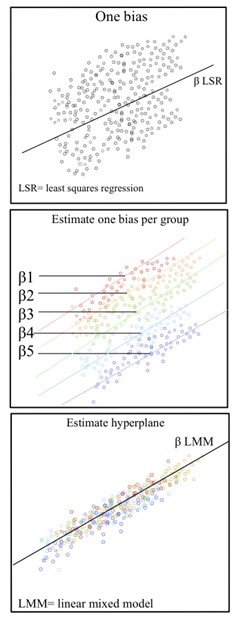
แบบจำลองผสมเชิงเส้น (LMM) เป็นแบบจำลองทางสถิติที่รวมผลกระทบแบบคงที่และ แบบสุ่ม เพื่อแสดงโครงสร้างข้อมูลที่ไม่เป็นอิสระได้อย่างแม่นยำ LMM เป็นทางเลือกแทนการวิเคราะห์ความแปรปรวน (ANOVA) โดยทั่วไป ANOVA จะถือว่า การสังเกตภายในแต่ละกลุ่ม เป็นอิสระทางสถิติแต่ข้อสมมตินี้อาจไม่เป็นจริงในข้อมูลที่ไม่เป็นอิสระ เช่น ข้อมูลหลายระดับ/ ลำดับชั้น ข้อมูล ตามยาวหรือข้อมูล ที่มีความสัมพันธ์กัน
ชุดข้อมูลที่ไม่เป็นอิสระต่อกัน คือชุดข้อมูลที่ความแปรปรวนระหว่างผลลัพธ์เกิดจากความสัมพันธ์ภายในกลุ่มหรือระหว่างกลุ่ม แบบจำลองผสม (Mixed Models) สามารถอธิบาย โครงสร้าง แบบซ้อนกัน /โครงสร้างข้อมูลแบบลำดับชั้นได้อย่างเหมาะสม โดยที่การสังเกตการณ์ได้รับอิทธิพลจากความสัมพันธ์แบบซ้อนกัน ตัวอย่างเช่น เมื่อศึกษาเกี่ยวกับวิธีการจัดการศึกษาที่เกี่ยวข้องกับหลายโรงเรียน จะมีตัวแปรหลายระดับที่ต้องพิจารณา ระดับบุคคล/ระดับล่างสุดประกอบด้วยนักเรียนหรือครูแต่ละคนภายในโรงเรียน การสังเกตการณ์ที่ได้จากนักเรียน/ครูคนนี้จะซ้อนอยู่ภายในโรงเรียนของพวกเขา ตัวอย่างเช่น นักเรียน A เป็นหน่วยหนึ่งในโรงเรียน A ระดับที่สูงขึ้นถัดไปคือโรงเรียน ในระดับที่สูงขึ้น โรงเรียนประกอบด้วยนักเรียนและครูหลายคน ระดับโรงเรียนมีอิทธิพลต่อการสังเกตการณ์ที่ได้จากนักเรียนและครู ตัวอย่างเช่น โรงเรียน A และโรงเรียน B เป็นระดับที่สูงขึ้น โดยแต่ละแห่งมีชุดของนักเรียน A และนักเรียน B ตามลำดับ นี่แสดงถึงแผนผังข้อมูลแบบลำดับชั้น วิธีแก้ปัญหาในการสร้างแบบจำลองข้อมูลแบบลำดับชั้นคือการใช้แบบจำลองผสมเชิงเส้น (Linear Mixed Models)

LMM ช่วยให้เราเข้าใจผลกระทบที่สำคัญระหว่างและภายในระดับต่างๆ ในขณะที่รวมการแก้ไขสำหรับข้อผิดพลาดมาตรฐานสำหรับความไม่เป็นอิสระที่ฝังอยู่ในโครงสร้างข้อมูล[ 4 ] [ 5 ]ในสาขาการทดลอง เช่น จิตวิทยาสังคม จิตวิทยาภาษา จิตวิทยาการรู้คิด (และประสาทวิทยาศาสตร์) ซึ่งการศึกษาต่างๆ มักเกี่ยวข้องกับตัวแปรการจัดกลุ่มหลายตัว การไม่คำนึงถึงผลกระทบแบบสุ่มอาจนำไปสู่อัตราความผิดพลาดประเภทที่ 1 ที่สูงเกินไปและข้อสรุปที่ไม่น่าเชื่อถือ[ 6 ] [ 7 ]ตัวอย่างเช่น เมื่อวิเคราะห์ข้อมูลจากการทดลองที่เกี่ยวข้องกับทั้งกลุ่มตัวอย่างของผู้เข้าร่วมและกลุ่มตัวอย่างของสิ่งเร้า (เช่น ภาพ สถานการณ์ ฯลฯ) การละเลยความแปรปรวนในตัวแปรการจัดกลุ่มใดๆ เหล่านี้ (เช่น โดยการหาค่าเฉลี่ยของสิ่งเร้า) อาจส่งผลให้ได้ข้อสรุปที่ทำให้เข้าใจผิด ในกรณีเช่นนี้ นักวิจัยสามารถปฏิบัติต่อทั้งผู้เข้าร่วมและสิ่งเร้าเป็นผลกระทบแบบสุ่มด้วย LMM และในการทำเช่นนั้น พวกเขาสามารถคำนึงถึงความแปรปรวนในข้อมูลของพวกเขาได้อย่างถูกต้องในตัวแปรการจัดกลุ่มหลายตัว ในทำนองเดียวกัน เมื่อวิเคราะห์ข้อมูลจากการสำรวจระยะยาวเชิงเปรียบเทียบ การไม่รวมผลกระทบแบบสุ่มในทุกระดับที่เกี่ยวข้อง เช่น ประเทศและประเทศ-ปี อาจทำให้ผลลัพธ์ผิดเพี้ยนไปอย่างมาก[ 8 ]
เอฟเฟกต์คงที่
ผลกระทบแบบคงที่ครอบคลุมแนวโน้ม/ทิศทางที่สอดคล้องกันในระดับความสนใจหลัก ผลกระทบเหล่านี้ถือว่าคงที่เนื่องจากไม่ใช่แบบสุ่มและถือว่าคงที่สำหรับประชากรที่กำลังศึกษา[ 5 ]ตัวอย่างเช่น เมื่อศึกษาด้านการศึกษา ผลกระทบแบบคงที่อาจแสดงถึงผลกระทบระดับโรงเรียนโดยรวมที่สอดคล้องกันในทุกโรงเรียน
แม้ว่าลำดับชั้นของชุดข้อมูลจะชัดเจนโดยทั่วไป แต่ผลกระทบคงที่เฉพาะที่ส่งผลต่อการตอบสนองเฉลี่ยของทุกกลุ่มตัวอย่างจะต้องระบุให้ชัดเจน สัมประสิทธิ์ผลกระทบคงที่บางส่วนเพียงพอโดยไม่ต้องมีผลกระทบสุ่มที่สอดคล้องกัน ในขณะที่สัมประสิทธิ์คงที่อื่นๆ เป็นเพียงตัวแทนของค่าเฉลี่ยในกรณีที่หน่วยแต่ละหน่วยเป็นแบบสุ่ม สิ่งเหล่านี้อาจถูกกำหนดโดยการรวมจุดตัดและค่าความชันแบบ สุ่ม [ 9 ] [ 10 ] [ 11 ]
ในสถานการณ์ส่วนใหญ่ จะมีการพิจารณาแบบจำลองที่เกี่ยวข้องหลายแบบ และจะนำแบบจำลองที่แสดงถึงแบบจำลองสากลได้ดีที่สุดมาใช้
ผลกระทบแบบสุ่ม, ε
องค์ประกอบสำคัญของแบบจำลองผสมคือการรวมผลกระทบแบบสุ่มเข้ากับผลกระทบแบบคงที่ ผลกระทบแบบคงที่มักถูกนำมาใช้เพื่อแสดงถึงแบบจำลองพื้นฐาน ในแบบจำลองผสมเชิงเส้นการถดถอย ที่แท้จริง ของประชากรเป็นเชิงเส้น β ข้อมูลคงที่ถูกนำมาใช้ในระดับสูงสุด ผลกระทบแบบสุ่มนำความแปรปรวนทางสถิติในระดับต่างๆ ของลำดับชั้นข้อมูล สิ่งเหล่านี้อธิบายถึงแหล่งที่มาของความแปรปรวนที่ไม่ได้วัดซึ่งส่งผลกระทบต่อกลุ่มบางกลุ่มในข้อมูล ตัวอย่างเช่น ความแตกต่างระหว่างนักเรียน 1 และนักเรียน 2 ในชั้นเรียนเดียวกัน หรือความแตกต่างระหว่างชั้นเรียน 1 และชั้นเรียน 2 ในโรงเรียนเดียวกัน[ 9 ] [ 10 ] [ 11 ]
ประวัติและสถานะปัจจุบัน
โรนัลด์ ฟิชเชอร์ได้นำแบบจำลองผลกระทบแบบสุ่มมาใช้เพื่อศึกษาความสัมพันธ์ของค่าลักษณะระหว่างญาติ[ 12 ] ในช่วงทศวรรษ 1950 ชาร์ลส์ รอย เฮนเดอร์สัน ได้ให้ค่าประมาณเชิงเส้นที่ดีที่สุดที่ไม่เอนเอียงของผลกระทบแบบคงที่และการคาดการณ์เชิงเส้นที่ดีที่สุด ที่ไม่เอนเอียง ของผลกระทบแบบสุ่ม[ 13 ] [ 14 ] [ 15 ] [ 16 ] ต่อมา การสร้างแบบจำลองแบบผสมได้กลายเป็นสาขาหลักของการวิจัยทางสถิติ รวมถึงงานเกี่ยวกับการคำนวณค่าประมาณความน่าจะเป็นสูงสุด แบบจำลองผลกระทบแบบผสมที่ไม่เป็นเชิงเส้น ข้อมูลที่หายไปในแบบจำลองผลกระทบแบบผสม และ การประมาณค่าแบบ เบย์เซียนของแบบจำลองผลกระทบแบบผสม แบบจำลองแบบผสมถูกนำไปใช้ในหลายสาขาวิชาที่มีการวัดที่สัมพันธ์กันหลายครั้งในแต่ละหน่วยที่สนใจ มีการใช้แบบจำลองเหล่านี้อย่างเด่นชัดในการวิจัยที่เกี่ยวข้องกับมนุษย์และสัตว์ในสาขาต่างๆ ตั้งแต่พันธุศาสตร์ไปจนถึงการตลาด และยังถูกนำมาใช้ในเบสบอล[ 17 ]และสถิติอุตสาหกรรม[ 18 ] ความสัมพันธ์ของแบบจำลองเชิงเส้นแบบผสมได้ปรับปรุงการป้องกันความสัมพันธ์ที่เป็นบวกเท็จ ประชากรมีความเชื่อมโยงกันอย่างลึกซึ้ง และโครงสร้างความสัมพันธ์ของพลวัตประชากรนั้นยากที่จะสร้างแบบจำลองได้หากไม่ใช้แบบจำลองผสม อย่างไรก็ตาม แบบจำลองผสมเชิงเส้นอาจไม่ใช่ทางออกเดียว LMM มี ข้อสมมติฐานเกี่ยวกับ ความแปรปรวนตกค้าง คง ที่ ซึ่งบางครั้งอาจถูกละเมิดเมื่อพิจารณา ลักษณะ ต่อเนื่องและลักษณะไบนารี ที่มีความสัมพันธ์กันอย่างลึกซึ้ง [ 19 ]
คำนิยาม
ในสัญลักษณ์เมทริกซ์แบบจำลองผสมเชิงเส้นสามารถแสดงได้ดังนี้

ที่ไหน
- เป็นเวกเตอร์ของการสังเกตที่ทราบแล้ว โดยมีค่าเฉลี่ย;
- เป็นเวกเตอร์ที่ไม่ทราบค่าของผลกระทบคงที่
- เป็นเวกเตอร์ที่ไม่ทราบค่าของผลกระทบแบบสุ่ม โดยมีค่าเฉลี่ยและเมทริกซ์ความแปรปรวนร่วม
- เป็นเวกเตอร์ที่ไม่ทราบค่าของข้อผิดพลาดแบบสุ่ม โดยมีค่าเฉลี่ยและความแปรปรวน;
- คือเมทริกซ์การออกแบบ ที่ทราบแล้ว สำหรับผลกระทบแบบคงที่ซึ่งเชื่อมโยงการสังเกตกับตามลำดับ
- คือเมทริกซ์การออกแบบ ที่ทราบแล้ว สำหรับผลกระทบแบบสุ่มที่เชื่อมโยงการสังเกตกับตามลำดับ











ตัวอย่างเช่น หากแต่ละค่าสังเกตสามารถอยู่ในหมวดหมู่ใดก็ได้ตั้งแต่ศูนย์หมวดหมู่ขึ้นไปจากkหมวดหมู่ เมทริกซ์Zซึ่งมีหนึ่งแถวต่อหนึ่งค่าสังเกต สามารถเลือกให้มีkคอลัมน์ได้ โดยค่า1สำหรับองค์ประกอบเมทริกซ์ของZบ่งชี้ว่าค่าสังเกตนั้นทราบว่าอยู่ในหมวดหมู่ และค่า0บ่งชี้ว่าค่าสังเกตนั้นทราบว่าไม่ได้อยู่ในหมวดหมู่ ค่าที่อนุมานได้ของu สำหรับแต่ละหมวดหมู่จะเป็น ค่าคงที่เฉพาะหมวดหมู่หากZมีคอลัมน์เพิ่มเติม โดยที่ค่าที่ไม่เป็นศูนย์จะเป็นค่าของตัวแปรอิสระสำหรับค่าสังเกต ค่าที่อนุมานได้ของu ที่สอดคล้องกันจะเป็นค่า ความชันเฉพาะหมวดหมู่ สำหรับตัวแปรอิสระนั้น การแจกแจงแบบก่อนหน้าสำหรับ ค่า คงที่และค่าความชันของหมวดหมู่จะอธิบายโดยเมทริกซ์ความแปรปรวนร่วมG
การประมาณการ
ความหนาแน่นร่วมของและสามารถเขียนได้ดังนี้: สมมติว่าเป็นแบบปกติ , และ, และเพิ่มความหนาแน่นร่วมสูงสุดเหนือและ, จะได้ "สมการแบบจำลองผสม" (MME) ของเฮนเดอร์สันสำหรับแบบจำลองผสมเชิงเส้น: [ 13 ] [ 15 ] [ 20 ]





โดยที่X′คือเมทริกซ์ทรานสโพสของXและR −1คือเมทริกซ์ผกผันของRเป็นต้น
การเรียบเรียงข้อความข้างต้นให้กระชับยิ่งขึ้นคือ
![{\displaystyle ([XZ]'R^{-1}[XZ]+G^{-1})[{\hat {\boldsymbol {\beta }}}{\hat {\boldsymbol {u}}}]'=[XZ]'R^{-1}{\boldsymbol {y}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/570705f983d99796bca06c34053fd46465709460)
หรือด้วย,
![{\displaystyle [XZ]=W}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0840d934712944b31e1bc3068333c68c2bf96c81)
![{\displaystyle (W'R^{-1}W+G^{-1})[{\hat {\boldสัญลักษณ์ {\beta }}}{\hat {\boldสัญลักษณ์ {u}}}]'=W'R^{-1}{\boldสัญลักษณ์ {y}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/572eedc93d7f3fde70b2db3e0561573aad021412)
โดยที่G −1กลายเป็น

คำตอบของ MME คือค่าประมาณเชิงเส้นที่ไม่เอนเอียงที่ดีที่สุด และตัวทำนายสำหรับและตามลำดับ นี่เป็นผลมาจากทฤษฎีบทเกาส์-มาร์คอฟเมื่อความแปรปรวนแบบมีเงื่อนไขของผลลัพธ์ไม่สามารถปรับขนาดให้เข้ากับเมทริกซ์เอกลักษณ์ได้ เมื่อทราบความแปรปรวนแบบมีเงื่อนไขแล้ว ค่าประมาณกำลังสองน้อยที่สุดถ่วงน้ำหนักด้วยส่วนกลับของความแปรปรวนจะเป็นค่าประมาณเชิงเส้นที่ไม่เอนเอียงที่ดีที่สุด อย่างไรก็ตาม ความแปรปรวนแบบมีเงื่อนไขนั้นแทบจะไม่ทราบเลย ดังนั้นจึงควรประมาณค่าความแปรปรวนและค่าประมาณพารามิเตอร์ถ่วงน้ำหนักร่วมกันเมื่อแก้ปัญหา MME


การเลือกโครงสร้างผลกระทบแบบสุ่ม
หนึ่งในทางเลือกที่นักวิเคราะห์ต้องเผชิญเมื่อใช้โมเดลแบบผสมคือการเลือกผลกระทบแบบสุ่ม (เช่น ตัวแปรการจัดกลุ่ม จุดตัดแบบสุ่ม และความชันแบบสุ่ม) ที่จะรวมไว้ คำแนะนำที่โดดเด่นประการหนึ่งในบริบทของการทดสอบสมมติฐานแบบยืนยัน[ 21 ]คือการใช้โครงสร้างผลกระทบแบบสุ่ม "สูงสุด" ซึ่งรวมถึงผลกระทบแบบสุ่มที่เป็นไปได้ทั้งหมดที่สมเหตุสมผลโดยการออกแบบการทดลอง เพื่อเป็นวิธีการควบคุมอัตราความผิดพลาดประเภทที่ 1
ซอฟต์แวร์
วิธีหนึ่งที่ใช้ในการปรับโมเดลแบบผสมดังกล่าวคืออัลกอริทึมการคาดการณ์-การทำให้สูงสุด (EM) โดยที่ส่วนประกอบความแปรปรวนถือเป็นพารามิเตอร์รบกวน ที่ไม่สามารถสังเกตได้ ในความน่าจะเป็นร่วม[ 22 ]ปัจจุบัน วิธีนี้เป็นวิธีการที่ใช้ในซอฟต์แวร์ทางสถิติ เช่นPython (แพ็คเกจ statsmodels) และเป็นขั้นตอนเริ่มต้นเท่านั้นในแพ็คเกจ nlme() ของR คำตอบของสมการโมเดลแบบผสมคือ การประมาณค่าความน่าจะเป็นสูงสุดเมื่อการกระจายของข้อผิดพลาดเป็นแบบปกติ[ 23 ] [ 24 ]

มีวิธีการอื่นๆ อีกหลายวิธีในการปรับโมเดลแบบผสม รวมถึงการใช้โมเดลแบบผสม (MEM) ในขั้นต้น จากนั้นใช้ Newton-Raphson (ใช้โดย แพ็กเกจ R nlme [ 25 ] 's lme(), SAS MIXED และ SPSS MIXED) การกำลังสองน้อยที่สุดแบบมีค่าปรับเพื่อให้ได้ค่าความน่าจะเป็นล็อกแบบโปรไฟล์โดยขึ้นอยู่กับพารามิเตอร์ความแปรปรวนร่วม (มิติที่ต่ำ) ของเช่น เมทริกซ์ความแปรปรวนร่วมจากนั้นใช้การเพิ่มประสิทธิภาพโดยตรงแบบสมัยใหม่สำหรับฟังก์ชันวัตถุประสงค์ที่ลดลงนั้น (ใช้โดย แพ็กเกจ R 's lme4 [ 26 ] lmer() และ แพ็กเกจ Julia MixedModels.jl) และการเพิ่มประสิทธิภาพโดยตรงของความน่าจะเป็น (ใช้โดยเช่นR 's glmmTMB) ที่น่าสังเกตคือ ในขณะที่รูปแบบมาตรฐานที่เสนอโดย Henderson มีประโยชน์สำหรับทฤษฎี แต่ซอฟต์แวร์ยอดนิยมหลายแพ็กเกจใช้สูตรที่แตกต่างกันสำหรับการคำนวณเชิงตัวเลขเพื่อใช้ประโยชน์จากวิธีการเมทริกซ์แบบเบาบาง (เช่น lme4 และ MixedModels.jl)

ในบริบทของวิธีการแบบเบย์เซียน แพ็กเกจ brms มีอินเทอร์เฟซที่ใช้งานง่ายสำหรับการปรับโมเดลแบบผสมใน R โดยใช้ Stan ซึ่งช่วยให้สามารถรวมการแจกแจงก่อนหน้าและการประมาณการแจกแจงภายหลังได้[ 27 ] [ 28 ]ใน Python Bambi มีแนวทางที่คล่องตัวคล้ายกันสำหรับการปรับโมเดลแบบผสมโดยใช้ PyMC [ 29 ]
ดูเพิ่มเติม
- แบบจำลองผลกระทบผสมแบบไม่เชิงเส้น
- แบบจำลองผลกระทบคงที่
- แบบจำลองเชิงเส้นผสมทั่วไป
- การถดถอยเชิงเส้น
- การวิเคราะห์ความแปรปรวนแบบการออกแบบผสม
- แบบจำลองหลายระดับ
- แบบจำลองผลกระทบแบบสุ่ม
- การออกแบบการวัดซ้ำ
- วิธีการเบย์เชิงประจักษ์
อ่านเพิ่มเติม
- Gałecki, Andrzej; Burzykowski, Tomasz (2013). แบบจำลองเชิงเส้นแบบผสมโดยใช้ R: วิธีการทีละขั้นตอน . นิวยอร์ก: Springer. ISBN 978-1-4614-3900-4.
- Milliken, GA; Johnson, DE (1992). การวิเคราะห์ข้อมูลที่ไม่เป็นระเบียบ: เล่มที่ 1 การทดลองที่ออกแบบไว้ . นิวยอร์ก: Chapman & Hall.
- West, BT; Welch, KB; Galecki, AT (2007). แบบจำลองผสมเชิงเส้น: คู่มือปฏิบัติโดยใช้ซอฟต์แวร์ทางสถิติ . นิวยอร์ก: Chapman & Hall/CRC.
สรุปเนื้อหา
ข้อมูลสำคัญจากบทความ
ข้อมูลสำคัญเกี่ยวกับ แบบจำลองผสม
แบบ จำลองผสม ( Mixed model) หรือแบบ จำลองผลกระทบผสม (Mixed-effects model) หรือ แบบจำลององค์ประกอบข้อผิดพลาดผสม (Mixed error-component model ) เป็น แบบจำลองทางสถิติ ที่มีทั้ง...
คำอธิบายเชิงคุณภาพ
แบบจำลองผสมเชิงเส้น (LMM) เป็น แบบจำลองทางสถิติ ที่รวม ผลกระทบ แบบคงที่ และ แบบสุ่ม เพื่อแสดงโครงสร้างข้อมูลที่ไม่เป็นอิสระได้อย่างแม่นยำ LMM เป็นทางเลือกแทน การวิเคราะห์ความแปรปรวน (ANOVA) โดยทั่วไป ANOVA จะถือว่า การสังเกตภายในแต่ละกลุ่ม เป็นอิสระทางสถิติ...
เอฟเฟกต์คงที่
ผลกระทบแบบคงที่ครอบคลุมแนวโน้ม/ทิศทางที่สอดคล้องกันในระดับความสนใจหลัก ผลกระทบเหล่านี้ถือว่าคงที่เนื่องจากไม่ใช่แบบสุ่มและถือว่าคงที่สำหรับประชากรที่กำลังศึกษา [ 5 ] ตัวอย่างเช่น เมื่อศึกษาด้านการศึกษา...
ผลกระทบแบบสุ่ม, ε
องค์ประกอบสำคัญของแบบจำลองผสมคือการรวมผลกระทบแบบสุ่มเข้ากับผลกระทบแบบคงที่ ผลกระทบแบบคงที่มักถูกนำมาใช้เพื่อแสดงถึงแบบจำลองพื้นฐาน ในแบบจำลองผสมเชิงเส้น การถดถอย ที่แท้จริง ของประชากรเป็นเชิงเส้น β ข้อมูลคงที่ถูกนำมาใช้ในระดับสูงสุด ผลกระทบแบบสุ่มนำ...